Pinot架构介绍
1. High Level Architecture

1. 目的:对给定数据集提供分析服务
2. 输入数据:Hadoop & Kafka
3. 索引技术:为了提供快速的查询,Pinot 采用列式存储以及各种索引技术(bitmap,inverted index)
2. 输入数据:Hadoop & Kafka
3. 索引技术:为了提供快速的查询,Pinot 采用列式存储以及各种索引技术(bitmap,inverted index)
2. Data Flow
2.1 Hadoop (Historical)

1. 输入数据:AVRO, CSV, JSON等;
2. 处理流程:在HDFS上的文件通过MR任务将数据变成有索引的Segment,然后推送到Pinot的集群的历史节点,去提供Query的能力;
3. 数据失效:有索引的Segment可以配置保留日期,在预先配置的失效日期之后被自动的删除;
2. 处理流程:在HDFS上的文件通过MR任务将数据变成有索引的Segment,然后推送到Pinot的集群的历史节点,去提供Query的能力;
3. 数据失效:有索引的Segment可以配置保留日期,在预先配置的失效日期之后被自动的删除;
2.2 Realtime
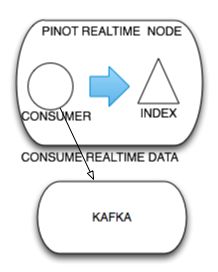
1. 输入数据:Kafka stream
2. 处理流程:实时数据节点通过消费 Kafka 的数据,在内存中生成带有索引的 Segment,并周期性的 flush 到磁盘,然后提供查询的功能;
3. 数据失效:实时节点的数据的保留日期会相对比较短,比如保留3天的数据,实时节点的数据在时效前会存储到历史节点中;
2. 处理流程:实时数据节点通过消费 Kafka 的数据,在内存中生成带有索引的 Segment,并周期性的 flush 到磁盘,然后提供查询的功能;
3. 数据失效:实时节点的数据的保留日期会相对比较短,比如保留3天的数据,实时节点的数据在时效前会存储到历史节点中;
2.3 Query routing
这条查询语句:select count(*) from table where time > T
转化为下面两跳查询语句:
1. historical node: select count(*) from table where time > T and time < T1
2. realtime node: select count(*) from table where time > T1
1. historical node: select count(*) from table where time > T and time < T1
2. realtime node: select count(*) from table where time > T1
note:
1. 用户的所有的查询会发送到 Pinot Broker;
2. 用户并不需要关心查询是被发往实时还是历史节点;
3. Pinot Broker 会根据 Query 的情况自动的将请求切分然后按照需要发送给实时节点和历史节点;
4. 最后能够将结果进行自动的合并;
2. 用户并不需要关心查询是被发往实时还是历史节点;
3. Pinot Broker 会根据 Query 的情况自动的将请求切分然后按照需要发送给实时节点和历史节点;
4. 最后能够将结果进行自动的合并;
3. Pinot Components Architecture

note:
1. 整个系统利用 Apache Helix 作为集群的管理;
2. 利用 Zookeeper 存储集群的状态,同时保存 Helix 和 Pinot 的配置;
3. Pinot 利用 NFS 来将在 HDFS 上用 MR 产生的 Segment 推到 PinotServer。
2. 利用 Zookeeper 存储集群的状态,同时保存 Helix 和 Pinot 的配置;
3. Pinot 利用 NFS 来将在 HDFS 上用 MR 产生的 Segment 推到 PinotServer。
3.1 Historical Node

3.1.1 Data Preparation
1. 带有索引的 Segment 在 Hadoop 中被创建
2. Pinot 团队提供了生成 Segment 的 Library
3. 数据格式可以是AVRO, CSV, JSON
2. Pinot 团队提供了生成 Segment 的 Library
3. 数据格式可以是AVRO, CSV, JSON
3.1.2 Segment creation on Hadoop
1. HDFS 中的数据被分成256/512MB 的分片
2. 每一个 mapper 将一个分片生成一个新的带有索引的 Segment
2. 每一个 mapper 将一个分片生成一个新的带有索引的 Segment
3.1.3 Segment move from HDFS to NFS
1. 从 HDFS 读取数据,通过 httppost 送到 Pinot Controller 节点
2. PinotController 会将 Segment 存储在 mount 在Pinot Controller 节点上的 NFS 中
3. 然后 Pinot Controller 会将 Segment 分配给一个 Pinot Server
4. 分配的相关信息则是由 Helix 来维护和管理
2. PinotController 会将 Segment 存储在 mount 在Pinot Controller 节点上的 NFS 中
3. 然后 Pinot Controller 会将 Segment 分配给一个 Pinot Server
4. 分配的相关信息则是由 Helix 来维护和管理
3.1.4 Segment move from NFS to Historical Node
1. Helix会监控 Pinot Server 的存活状态
2. 当一个 Server 启动时,Helix 会通知 Pinot Server 分配给该 Server 的Segment
3. Pinot Server 从Controller Server 下载 Segment 并且装入到本地的磁盘中
2. 当一个 Server 启动时,Helix 会通知 Pinot Server 分配给该 Server 的Segment
3. Pinot Server 从Controller Server 下载 Segment 并且装入到本地的磁盘中
3.1.5 Segment Loading
1. 解压缩的 Segment 中包含元数据以及每列的正排和倒排索引
2. 然后根据装载模式(memory, mmap),装载到内存或是被mmap到服务器
3. 装载完成之后,Helix 会通知 Broker 节点该 Segment 可以在该服务器被使用,Broker 会在查询时将查询路由到该服务器
2. 然后根据装载模式(memory, mmap),装载到内存或是被mmap到服务器
3. 装载完成之后,Helix 会通知 Broker 节点该 Segment 可以在该服务器被使用,Broker 会在查询时将查询路由到该服务器
3.1.6 Segment Expiry
1. Pinot 控制服务有一个后台清理线程去根据元数据删除过期的 Segment
2. 删除 Segment 会清理掉 Controller 服务中 NFS 上的数据,以及 Helix 服务上的元数据信息
3. Helix 会通知 Pinot Server 对 Segment 进行在线离线切换,将 Segment 变为离线状态,然后变为删除状态,从本地磁盘删掉数据
2. 删除 Segment 会清理掉 Controller 服务中 NFS 上的数据,以及 Helix 服务上的元数据信息
3. Helix 会通知 Pinot Server 对 Segment 进行在线离线切换,将 Segment 变为离线状态,然后变为删除状态,从本地磁盘删掉数据
note:
1. hadoop jar pinot-hadoop-0.016.jar SegmentCreation job.properties
2. hadoop jar pinot-hadoop-0.016.jar SegmentTarPush job.properties
2. hadoop jar pinot-hadoop-0.016.jar SegmentTarPush job.properties
3. Segment 装载过程是由 Helix 触发的离线在线切换
3.2 Real time Node

3.2.1 Kafka consumption
1. Pinot 创建一个 resource,Pinot 会分配一组实例从Kafka topic 消费数据
2. 如果 Pinot Server 挂掉,这个消费会被从新分布到其他的节点
2. 如果 Pinot Server 挂掉,这个消费会被从新分布到其他的节点
3.2.2 Segment creation
1. 当 Pinot Server 消费了预先配置好数量的事件后,会在内存中将数据转变为离线 Segment
2. 当 Segment 创建成功后,Pinot 提交 offset 到 Kafka,如果失败,Pinot 会从上次的 checkpoint 重新生成 Segment
2. 当 Segment 创建成功后,Pinot 提交 offset 到 Kafka,如果失败,Pinot 会从上次的 checkpoint 重新生成 Segment
3.2.3 Segment Expiry
1. 只能配置到天,失效之后 Segment 从实时节点分发到历史节点
note:
实时节点生成的 Segment 的格式和历史节点生成 Segment 格式相同,从而方便 segment 从实时节点到历史节点的重新分发。
3.3 Pinot Cluster Management

3.3.1 概述
1. 所有的管理命令都需要通过 Pinot Controller,比如这些命令:allocating Pinot Server and Brokers, Creating New Table, Uploading New Segments
2. 所有的 Pinot admin cmd 都需要在内部通过 Helix Admin Api 翻译成 Helix cmd,然后 Helix cmd 修改 Zookeeper 中的元数据
3. Helix Controller 作为系统的大脑,将元数据的变化转义成一个 action set,并在对应的 participant 上执行相应的 action
4. Helix Controller 还负责监控 Pinot Server,当 Pinot Server 启动或是挂掉的时候,Helix Controller 发现并修改对应的 external view,Pinot Broker 观察到观察这些变化,并随之动态更改 table 的路由
2. 所有的 Pinot admin cmd 都需要在内部通过 Helix Admin Api 翻译成 Helix cmd,然后 Helix cmd 修改 Zookeeper 中的元数据
3. Helix Controller 作为系统的大脑,将元数据的变化转义成一个 action set,并在对应的 participant 上执行相应的 action
4. Helix Controller 还负责监控 Pinot Server,当 Pinot Server 启动或是挂掉的时候,Helix Controller 发现并修改对应的 external view,Pinot Broker 观察到观察这些变化,并随之动态更改 table 的路由
3.3.2 术语对应
1. Pinot Segment:对应 Helix Partition,每一个 Segment 都有多分拷贝
2. Pinot Table:由多个 Segment 组成,隶属于同一个 Table 的 Segment 具有同一个 Schema
3. Pinot Server:对应 Helix Participant,主要用于保存 Segment
4. Pinot Broker:对应 Helix Spectator,用于观察 Segment 和 Pinot Server 的状态的变化。为了支持多租户,Pinot Broker 也作为 Helix Participant
2. Pinot Table:由多个 Segment 组成,隶属于同一个 Table 的 Segment 具有同一个 Schema
3. Pinot Server:对应 Helix Participant,主要用于保存 Segment
4. Pinot Broker:对应 Helix Spectator,用于观察 Segment 和 Pinot Server 的状态的变化。为了支持多租户,Pinot Broker 也作为 Helix Participant
3.3.3 Zookeeper
主要用于存储集群的状态,同时也用于存储 Helix 和 Pinot 的一些配置
3.3.4 Broker Node
主要负责将客户端请求的 query 路由到 Pinot Server 实例上,收集 Pinot Server 的返回结果,最后合并成最终结果,返回给客户端。功能有:
1. service discovery:感知 Server、Table、Segment、Time range,计算 query 的执行路由
2. Scatter gather:将 query 分发到对应的 Server,将每个 Server 返回的结果合并成,返回给客户端
Pinot Broker 实现了多种选择 Pinot Server 的策略:Segment 均匀分布策略、贪心算法策略(最大/小 Pinot Server 参与)、随机选择 segment 的 Server。如果 Pinot Server 执行失败或超时,Pinot Broker 只能返回部分结果,未来通过支持其他的方式,比如 re-try 或者将相同的执行计划发给多个 segment 副本
4. Pinot Index Segment
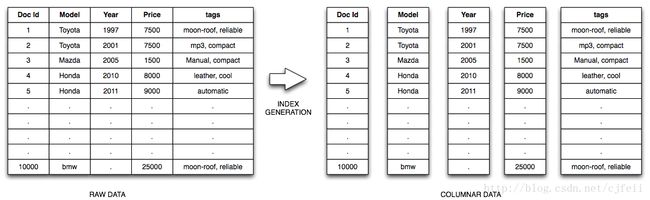
4.1 行式存储和列式存储的区别
4.1.1 行式存储特点
1. OLTP
2. 一整行数据被保存在一起
3. INSERT/UPDATE容易
4.1.2 列式存储特点
1. OLAP2. 查询时只有涉及到的列会被读取
3. 任何列都能作为索引:fixed length index、sparse index等
4. 易于压缩
5. 配合 bitmap 可以提高查询执行性能
4.2 Anatomy of Index Segment
4.2.1 Segment Entities
1. Segment Metadata :主要定义 Segment 的元数据信息,包括:
segment.name
segment.table.name
segment.dimension.column.names
segment.metric.column.names
segment.time.column.name
segment.time.interval
segment.start.time/segment.end.time
segment.time.unit
......
segment.table.name
segment.dimension.column.names
segment.metric.column.names
segment.time.column.name
segment.time.interval
segment.start.time/segment.end.time
segment.time.unit
......
2. Column Metadata,包括:
column..cardinality
column..totalDocs
column..dataType: INT/FLOAT/STRING
column..lengthOfEachEntry
column..columnType: Dimension/Metric/Time
column..isSorted
column..hasDictionary
column..isSingleValues
......
column..totalDocs
column..dataType: INT/FLOAT/STRING
column..lengthOfEachEntry
column..columnType: Dimension/Metric/Time
column..isSorted
column..hasDictionary
column..isSingleValues
......
3. Creation Metadata (creation.meta),包括:
Dictionary (.dict):列的编码字典
Forward Index (.sv.sorted.fwd): Single Value Sorted Forward Index,前缀压缩索引
Forward Index (.sv.sorted.fwd): Single Value Sorted Forward Index,前缀压缩索引
5. Query Processing


5.1 Query Execution Phases
5.1.1 Query Parsing
采用 Antlr 做语法解析器将 PQL 转化成 query parse tree
5.1.2 Logical Plan Phase
通过查询元数据信息,将 query parse tree 转化成 Logical Plan Tree
5.1.3 Physical Plan Phase
根据 Segment 的信息进一步优化、具体执行计划
5.1.4 Executor Service
在相应的 Segment 上执行 physical operator tree
5.2 PQL
PQL 是 SQL 的一个子集,不支持 join,不支持子查询
ref: https://github.com/linkedin/pinot/wiki/Architecture