【DBAplus】深入Oracle优化器:一条诡异执行计划的解决之道
-
深入Oracle优化器:一条诡异执行计划的解决之道
DBAplus社群 | 2016-05-05 19:51
CBO计算成本并选择最佳执行计划的至关重要输入物就是表和索引的统计信息,过旧或错误的统计信息则可能导致一个性能极差的执行计划被错误地选中。本文将以一个案例展示诡异的统计信息如何影响执行计划的生成。
1案例介绍
这是一个简单的sql,近两个月来对于告警明细表(分区)做月度汇总查询时,总是出现了异常缓慢的情况。
测试SQL:

字段NEALARM_TIME是固定条件,字段RELATED_EMS_CUID是不固定的(这些不固定条件的选择性都不强),分区裁剪到的分区有着1~3月份的数据。
关于HISTORY_ALARM表, 存放20150301至今的数据,每天大约150w数据,有按1天1分区、1个月1分区,第41个分区比较特殊,这是一个有着2016年1月~3月份数据的分区;相信各位了解到这个sql的数据分区情况,第一联系到的访问路径就是分区全表扫描或访问复合索引,毕竟访问的数据占据着1/3个分区的数据。
下面是执行计划:

该表最新收集了表和索引的统计信息,采样比为auto,没有收集直方图,请看执行计划可以注意到其中一些奇怪的细节:
1.索引HIS_ALARM_INDEX1预估基数比父节点回表的基数还小,而且小很多;
2.索引HIS_ALARM_INDEX1是一个复合索引(NEALARM_TIME,NEEND_TIME),访问的字段只是日期(NEALARM_TIME)
正常情况下,索引选择率>=单表选择率,通过rowid回表后filter所返回的行数要小于索引扫描返回的行数;而如果访问索引只是单纯靠日期(NEALARM_TIME)过滤数据,还要再回表,对于1/3分区数据多达1500w行,其成本代价是远高于分区全表扫描的,这也难怪查询如此缓慢。
从执行计划上可以看到问题入手点:即id 3的索引预估返回值远小于id 4单表预估返回值,这是不合理的;再者即便要访问索引,为什么选择了复合索引,而不是前导列同样为NEALARM_TIME的单字段索引?
210053看问题
为了弄清楚上一步分析后的疑问,我们收集10053 trace帮助解析CBO是如何根据统计信息选择执行计划。
1. 首先计算单表基数

分区裁剪为Part#:40,统计信息来自分区统计信息
单表选择率,没有直方图:
选择率

CBO计算得到的单表选择率,我们可以逆推出来:

以上证明单表选择率是相对准确的。
2.访问路径及成本计算



从上述成本计算看到,CBO确实选择了表面上成本更小的索引范围扫描Index: HIS_ALARM_INDEX1,可看出了一些有用信息:
1.单字段索引HISALARM_PART_IDX_0(NEALARM_TIME)在分区Part#:40选择率1/3是正确的
2.访问本地分区索引HISALARM_PART_IDX_0(NEALARM_TIME)的成本确实比全表扫描高,13537358>2982164,最佳的访问路径应该是分区全表扫描
3.理论上,访问单字段的本地分区索引HISALARM_PART_IDX_0的成本应小于多字段的全局索引 HIS_ALARM_INDEX1,而10053中与之相反
4.访问全局索引HIS_ALARM_INDEX1(NEALARM_TIME,NEEND_TIME),从执行计划"Predicate Information"中可以看到访问字段只有NEALARM_TIME,其选择率出奇的低仅有0.000041
HIS_ALARM_INDEX1索引选择率ix_sel: 0.000041出奇的低,也导致了基数估算过小,COST仅有5562.83;一切表明着,全局索引HIS_ALARM_INDEX1使用的全局统计信息很可能有问题:
推算索引选择率
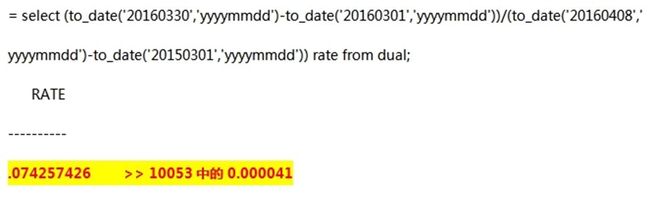
推算的索引选择率和10053中显示的索引选择率想去甚远,下面从视图dba_tab_col_statistics检查字段NEALARM_TIME的最大最小值:
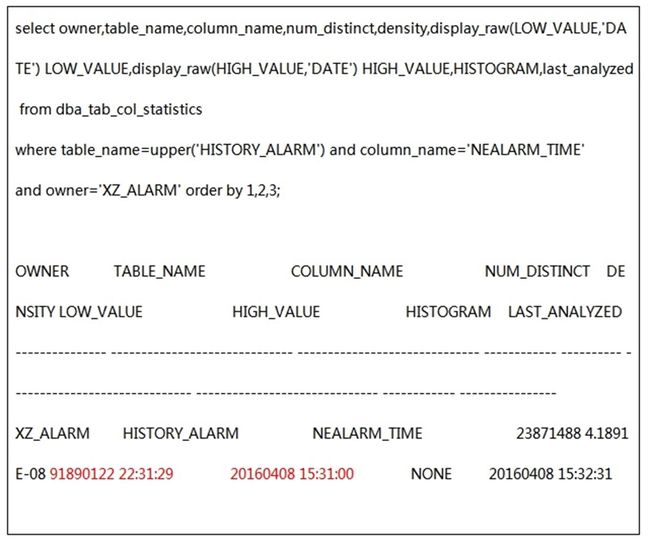
全局统计信息的字段NEALARM_TIME最小值居然是"91890122",而不是真实的20150301,导致全局统计信息的最小值远不同于真实日期(之后查明表中存在极其少量异常数据),这使得对NEALARM_TIME进行范围匹配时选择率偏低。上一步疑问已经找到原因:即便是sql语句写法已经使用了分区裁剪(使用分区统计信息),但CBO考虑访问全局索引是要根据全局统计信息进行成本计算的,而全局统计信息有误才出现了执行计划中一系列不合理的地方。
3小结与解决方法
CBO在对访问路径及其成本计算时会考虑所有可访问的索引,而进行全局索引访问方式的成本计算时使用的是全局统计信息。案例中执行计划的单表返回行数是根据分区统计信息估算(855K 准确),而索引返回行数是根据全局统计信息估算(5964 远远偏小),这是因为全局统计信息的字段最小值异常,导致进行范围匹配时选择率估算严重偏小,返回行数估算偏小,这也就是为什么执行计划中的索引返回行数远小于单表返回行数。
问题的根本原因是使用了错误的全局统计信息,解决方法就是纠正或不使用全局统计信息。
解决方法:找出异常数据删之,并重新收集统计信息。
workround:
1.drop该全局索引或重建为本地分区索引
2.将该全局索引设置为不可见"invisible" ,这样就不会使用到全局统计信息 <<后面介绍这种方法
3.对该字段收集直方图
下面是将问题索引"XZ_ALARM.HIS_ALARM_INDEX1"设置为 invisible后的优化效果,可以看到最佳执行计划已经不再考虑访问索引,因为访问本地分区索引HISALARM_PART_IDX_0(NEALARM_TIME)的成本比全表扫描高,13537358>2982164,在新的10053中是可以看到这一点的。

作者介绍 王培中
新炬网络资深DBA
About Me
...............................................................................................................................................................................
本文来自于微信公众号转载文章,若有侵权,请联系小麦苗及时删除
ITPUB BLOG:http://blog.itpub.net/26736162
QQ:642808185 若加QQ请注明您所正在读的文章标题
【版权所有,文章允许转载,但须以链接方式注明源地址,否则追究法律责任】
...............................................................................................................................................................................
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/26736162/viewspace-2095973/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/26736162/viewspace-2095973/