一个复杂的数据需求的MySQL方案
前些天处理了一个需求,当时的数据库环境是Oracle,我算是想尽了Oracle相关的方案,而且在问题的处理过程中,还在不断的琢磨,如果失败了还有什么其他的方案。
所以尽管Oracle这么一个成熟的商业数据库,做起来还是有些难度,需要一些额外的技巧,比如规避bug,间接实现需求等。
但是换个角度,2亿多数据的表,其实MySQL也不是新鲜事儿了。如果MySQL碰到了这种情况,该怎么处理呢。
梳理业务需求
假设业务需求还是不变,如下:
业务同学反馈,数据库中有一个表数据量很大,因为要做一期活动,需要近期的数据,以前的旧数据可以考虑清理。清理多少旧数据呢,差不多是99%的量,数据量有多大呢,差不多两个亿。所以这个需求听起来蛮简单,但是业务同学明确希望能够保持业务的可持续性,这样一来就对实现方案有了一些选择。
这个看起来简单的需求,有下面的一些补充信息,数据库为MySQL 5.6,数据量有2亿,数据查询效率非常差,99%以上都是脏数据,需要清理,开发同学是根据时间范围来进行查询;表里的数据只有insert,没有update和delete。
总结下来,要做4件事情:
-
优化查询,目前是基于时间范围来查询,经过评估需要给这个表添加索引
-
清理数据,表里有两亿数据,但是要清理绝大部分数据。
-
保证业务的可持续性,每10分钟会做一次统计分析,数据会实时录入系统
-
把表修改为分区表,把旧数据放入一个分区,新数据放入另一个分区,变更之后删除就分区即可
梳理需求优先级
如此一来,给这个表添加索引就是亟待解决的关键问题。
MySQL里面的online DDL功能还是很不错的,对于索引的操作,5.6版本支持还是很全的。

所以MySQL online DDL原生的方案就很不错,如果是5.5也没关系还有pt-osc工具等可以实现。
大道至简,思路相通
而对此的一个解决方案如下,数据流和之前Oracle的方案如出一辙,但是实现原理和细节有所差别。
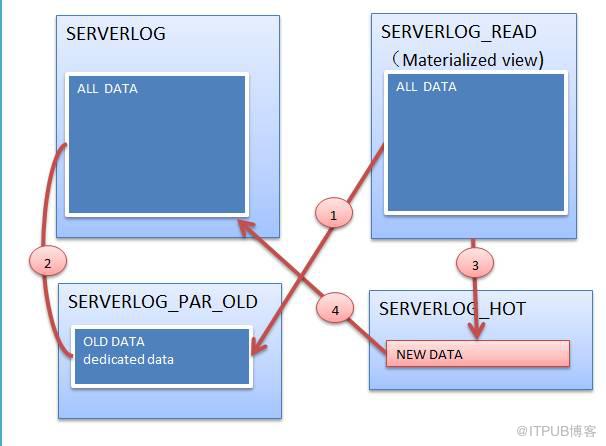
首先需要做得就是生成一个影子表serverlog_read,对于源库的表数据变更都能够同步到这个表里。
MySQL里面是不支持物化视图的,所以增量刷新等等方案就会受限,但是办法总比困难多,MySQL里面要实现物化视图还是有一些其他的方法的,比如说Flexviews,或者是自己实现,通过触发器的形式来实现需求,这里insert,delete,update都需要有触发条件,所以pt工具默认会创建的也是3个触发器,原理很相似。
有了这个物化视图,缓存增量数据就有了基本保证,所以我们还需要两个辅助的表,一个是serverlog_par_old,这是个分区表,只保留一个分区,里面会存放物化视图里查到的刷新数据,另外一个是serverlog_host,这里面存放的是增量数据和实时录入系统的数据。
这个时候其实有三种类别的数据处理需要考虑,第一类是旧数据,也可以理解为冷数据,第二类是增量数据,比如指定近一个月的数据需要保留,那么这个时间范围内的数据就是增量数据,第三类是实时数据,数据会实时录入系统,这个数据近乎是实时的。所以说上面的方案就是对冷数据能够归档,对增量数据能够合理截取,对实时数据产生尽可能小的影响。
2亿的数据怎么合1千万的数据进行切换呢,MySQL 5.6也是支持exchange partition的。所以这个操作支持起来是没有问题的,毕竟分区的操作就是这么几种玩法。MySQL因为其自身存储的特性,实现这个需求其实更纯粹。
最后就是增量,实时数据的补录,利用serverlog_hot来补数据就行。
方案之外的两点补充
额外补充两点,也是MySQL在这个实现过程的两个亮点。
第一个亮点就是MySQL复制表结构有着得天独厚的优势,大家知道在MySQL 5.6中是不支持create table xxxx as select xx这种方式的,但是有很多更绝的方法。
我们可以改写为下面的方式来做:
1.create table test1 like test; --这种方式能够完整的复制DDL信息。
或者使用show create table来做,当然这个略有些不方面,或者是使用mysqldump --no-date的方式来导出语句也可以。
2.插入数据,比如insert into test1 select *from test;
第二个亮点部分就是对于数据的备份归档,说简单简单,说复杂复杂,比如我们严格限定数据的有效性,不需要的旧数据就不在当前的数据库中保留,但是为了实现基本的备份需求,我们可以使用rename user的方式来做。Oracle实现rename user还是有些复杂的,而MySQL实现起来就很轻巧。说得通俗一些,就是把里面的数据挪到另外一个目录下了。
要处理这样一个需求,毫无疑问尽管我信息满满,但是在实践的时候还是是困难重重,碰到了问题多思考和总结,就会形成自己的认知体系,会少走很多弯路。

来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/23718752/viewspace-2141155/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/23718752/viewspace-2141155/