深入理解BERT Transformer ,不仅仅是注意力机制
 大数据文摘与百度NLP联合出品
大数据文摘与百度NLP联合出品
作者:Damien Sileo
编译:张驰、毅航、龙心尘
BERT是google最近提出的一个自然语言处理模型,它在许多任务检测上表现非常好。如:问答、自然语言推断和释义而且它是开源的。因此在社区中非常流行。
下图展示了不同模型的GLUE基准测试分数(不同NLP评估任务的平均得分)变化过程。

尽管目前还不清楚是否所有的GLUE任务都非常有意义,但是基于Trandformer编码器的通用模型(Open-GPT、BERT、BigBird),在一年内缩小了任务专用模型和人类的差距。
但是,正如Yoav Goldberg所说,我们并不能完全理解Transformer模型是如何编码句子的:
Transformer和RNN模型不同,它只依赖于注意力机制。除了标志每个单词的绝对位置嵌入,它没有明确的单词顺序标记。对注意力的依赖可能会导致Transformer模型在处理语法敏感的任务中相对于RNN(LSTM)模型性能表现较差——因为RNN模型是直接根据词序训练模型,并且明确地追踪句子的状态。
一些文章深入地研究了BERT的技术细节。这里,我们将尝试提出一些新的观点和假设来解释BERT的强大功能。
一种语言理解的框架:句法解析/语义合成
人类能够理解语言的方式是一个由来已久的哲学问题。在20世纪,两个互补的原理阐明了这个问题:
“语义合成性原理”表明复合词的含义来源于单个词的含义以及这些单词的组合方式。根据这个原理,名词短语“carnivorous plants” (食肉植物)的含义可以通过 “carnivorous” (食肉的)这个词的含义和“plant” (植物)这个词的含义组合得到。
另一个原理是“语言的层次结构”。它表明通过句法解析,句子可以分解为简单的结构——比如从句。从句又可以分解为动词短语和名词短语等等。
句法解析层次结构以及递归是从组成成分中提取含义,直到达到句子级别,这对于语言理解是一个很有吸引力的方法。考虑到这个句子“Bart watched a squirrel with binoculars” (Bart用双筒望远镜观察松鼠),一个好的句法解析会返回以下句法解析树:
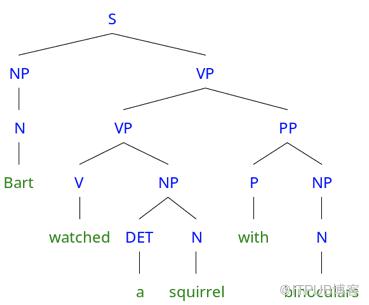
“Bart watched a squirrel with binoculars”基于结构的句法解析树
这个句子的含义可根据连续的语义合成推导出来(将“a” 和 “squirrel” 语义合成, “watched” 和“a squirrel” 语义合成, “watched a squirrel” 和“ with binoculars” 语义合成),直到句子的含义完全得到。
向量空间可以用来表示一个单词、短语和其他成分。语义合成的过程可以被构造为一个函数f,f将(“a”,”squirrel”) 语义合成为 “a squirrel” 的一个有意义向量,表示为“a squirrel” = f(“a”,”squirrel”)。
相关链接:
http://csli-lilt.stanford.edu/ojs/index.php/LiLT/article/view/6
但是,语义合成和句法解析都是很难的任务,而且它们互相需要。
显然,语义合成依赖句法解析的结果来决定哪些应该被语义合成。但是即使有正确的输入,语义合成也是一个困难的问题。例如,形容词的含义会随着单词的不同而变化:“white wine” (白葡萄酒)的颜色实际上是黄色的,但是一只白猫(white cat)就是白色的。这种现象被称作联合语义合成(co-composition)。
相关链接:
http://gl-tutorials.org/wp-content/uploads/2017/07/Pustejovsky-Cocompositionality-2012.pdf
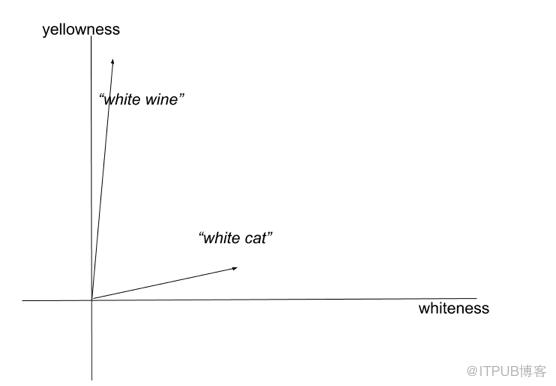
“white wine” (白葡萄酒)和 “white cat” (白猫)在二维语义空间中的表征(空间的维度是颜色)
对于语义合成,还需要更广泛的上下文。举个例子, “green light”(绿灯)单词的语义合成要根据语境来定。 “green light”可以表示授权或者实际的绿灯。一些习惯用语需要经验记忆而不是简单地组合它们。因此,在向量空间中进行语义合成需要强大的非线性函数,例如深度神经网络,也具有记忆功能。
相关链接:
https://arxiv.org/abs/1706.05394
相反,为了在一些特定情形下奏效,句法解析操作可能需要语义合成。考虑下面这个句子的句法解析树(和之前相同的句子) “Bart watched a squirrel with binoculars”
另一个"Bart watched a squirrel with binoculars"的基于结构的句法解析树
尽管它在语法上有效,但是句法解析操作导致了句子的畸形翻译,Bart watches (with his bare eyes) a squirrel holding binoculars(Bart(用他的裸眼)看到一个举着望远镜的小松鼠)。
因此,需要进行一些单词语义合成才能判断“松鼠举着望远镜”是不可能的!一般地说,在获得句子正确结构前,必须要一些消除歧义的操作和背景知识的整合。但是这种操作也可以通过一些句法解析和语义合成的形式完成。
一些模型尝试将句法解析和语义合成的操作同时结合应用到实践中。
相关链接:
https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf
然而,它们依赖于受限制的人工注释的标准句法解析树设置,并且性能还没有一些更简单的模型好。
BERT是如何实现句法解析/语义合成操作的
我们假设Transformer创新地依赖这两个操作(句法解析/语义合成):由于语义合成需要句法解析,句法解析需要语义合成,Transformer便迭代地使用句法解析和语义合成的步骤,来解决它们相互依赖的问题。
实际上,Transformer由一些堆叠层组成(也叫做block)。每个block块由一个注意力层以及一个应用在每个输入元素的非线性函数组成。
我们试着展示Transformer的这些组件与句法解析/语义合成框架之间的联系:
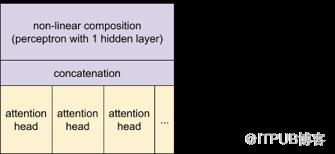
一个视为连续的句法解析和语义合成步骤
将注意力视为一个句法解析步骤
在BERT中,一个注意力机制让输入序列(比如:由单词或子单词组成的元素)中的每个元素聚焦到其它的元素上。
出于解释的目的,我们根据这篇文章(https://medium.com/dissecting-bert/dissecting-bert-part2-335ff2ed9c73)使用的可视化工具来深入研究注意力头,并在预训练的的BERT模型上验证我们的假设。在下面对注意力头的解释中,单词“it”参与到其它所有元素中,看起来它会关注 “street” 和 “animal”这两个单词。

可视化第0层1号注意力头上的注意力值,用于标记“it”
BERT为每一层使用12个独立的注意力机制。因此,在每一层,每个token可以专注于其他标记的12个不同侧面。由于Transformers使用许多不同的注意力头(12 * 12 = 144用于基础BERT模型),每个头部可以专注于不同类型的成分组合。
我们忽略了与“[CLS]”和“[SEP]”标记相关的注意力值。我们尝试使用了几个句子,发现想不过度解释它们的结果很难。所以你可以随意用几个句子在这个colab notebook上测试我们的假设。请注意,在图中,左侧序列“注意”右侧序列。
相关链接:
https://colab.research.google.com/drive/1Nlhh2vwlQdKleNMqpmLDBsAwrv_7NnrB
第2层1号注意力头似乎基于相关性来生成成分

可视化第2层1号头上的注意力值
更有趣的是,在第3层中,9号头似乎显示出更高级别的成分:一些token注意到相同的中心词(if,keep,have)。

第3层11号头的注意力值的可视化,一些标记似乎注意到特定的中心词(例如,have,keep)
在第5层中,由6号注意力头执行的匹配似乎集中于特定组合,特别是涉及动词的组合。像[SEP]这样的特殊标记似乎用于表示没有匹配。这可以使注意力头能够检测适合该语义合成的特定结构。这种一致的结构可以用于语义合成函数。

可视化第5层6号头注意力值,更关注组合(we,have),(if,we),(keep,up)(get,angry)
可以用连续的浅层的句法解析层表示解析树,如下图所示:
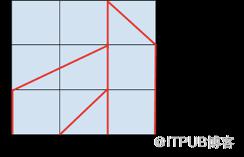
若干注意力层如何表示成树结构
在检查BERT注意力头时,我们没有找到这种清晰的树结构。但是Transformers仍有可能表示它们。
我们注意到,由于编码是在所有层上同时执行的,因此很难正确解释BERT正在做什么。对指定层的分析只是对它自己的下一层和前一层才有意义。句法解析也分布在各注意力头上。
下图展示了两个注意力头的情况下,BERT注意力更为实际的样子:
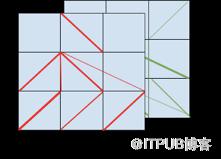
BERT中注意力值更实际的展现
然而,正如我们之前所见,句法解析树是一种高级别的展示,它可能建立在更复杂的“根茎”结构上。例如,我们可能需要找出代词所引用的内容,以便对输入进行编码(共指消解)。在其他情况下,消除歧义也可能需要全文背景。
令人惊讶的是,我们发现一个注意力头(第6层0号头)似乎实际上执行了共指消解。
相关链接:
https://medium.com/dissecting-bert/dissecting-bert-part2-335ff2ed9c73
一些注意力头似乎为每一个单词(第0层0号头)都提供全文信息。

在第6层的头0号头中发生的共指消解

每个单词都会注意句子中的所有其它单词。这可能允许对每个单词建立一个粗略的语境。
语义合成阶段
在每一层中,所有注意力头的输出被拼接并被送到可以表示复杂非线性函数(表达语义合成所需要的)的神经网络。
依靠来自注意力头的结构化输入,该神经网络可以执行各种语义合成。 在先前显示的第5层中,6号注意力头可以引导模型执行以下语义合成:(we,have),(if,we),(keep,up)(get,angry)。该模型可以非线性地组合它们并返回语义合成表示。因此,多注意力头可以作为辅助语义合成的工具。

注意力头如何辅助特定的语义合成,例如形容词/名词语义合成
虽然我们没有发现注意力头集中关注形容词/名词等更一致的组合,但是动词/副词的语义合成与模型所衍生的其它语义合成之间可能存在一些共同点。
有许多可能的相关语义合成(单词-子词,形容词-名词,动词-介词,子句-子句)。更进一步,我们可以将消歧看作把一个歧义词(如 bank)与其相关的上下文单词(如 river 或 cashier)语义合成的过程。在语义合成期间也可以执行与给定上下文的概念相关的背景常识知识的集成。这种消歧也可能发生在其它层面(例如句子层面、子句层面)。
此外,语义合成也可能涉及词序推理。有人认为,位置编码可能不足以正确编码单词的顺序,然而位置编码被设计为编码每个token的粗略、精细和可能精确的位置。(位置编码是与输入嵌入平均求和的向量,以为输入序列中的每个 token 生成能够感知位置的表征)。因此,基于两个位置编码,非线性合成理论上可以基于单词相对位置执行一些关系推理。
我们假设语义合成阶段也在BERT自然语言理解中起到了重要作用:并不只需要注意力。
总结
我们提出了对Transformers的归纳偏差的见解。但我们的解释对Transformer的功能持乐观态度。作为提醒,LSTM显示能够隐性地处理树结构和语义合成。由于LSTM仍存在一些局限性,部分是因为梯度消失造成的。因此,需要进一步的研究来阐明Transformer的局限性。
引用:
Bowman, S., Manning, C. and Potts, C. (2015). Tree-structured composition in neural networks without tree-structured architectures.
Hochreiter, S. (1998). The Vanishing Gradient Problem During Learning Recurrent Neural Nets and Problem Solutions. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 06(02), pp.107-116。
Tai, K., Socher, R. and Manning, C. (2015). Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks.
相关报道:
https://medium.com/synapse-dev/understanding-bert-transformer-attention-isnt-all-you-need-5839ebd396db
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31562039/viewspace-2638791/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31562039/viewspace-2638791/