EXT4 之 Android 文件系统剖析
- 基础文件系统架构
- 文件系统是什么
- 挂载mouting
- 文件系统架构
- 文件系统架构
- 主要结构
- 虚拟文件系统层
- superblock
- inode and dentry
- Buffer cache
基础文件系统架构
Linux文件系统架构有趣、抽象、并且复杂。有超级多的API接口可供我们调用,而且这些API接口向我们提供了大量的我们所希望的对存储设备的操作。如:读取功能,可以让我们从指定的file descriptor的指定位置读取指定的比特。但是读取功能本身并不用去关注文件系统的诸如NTFS、EXT4等。同时也不用去关注具体的存储设备,例如:AT Attachment Packet Interface(ATAPI)disk、Serial-Attach SCSI(SAS)disk、Serial Advanced Technology Attachment(SATA)disk。是的,当我们使用读取方法的时候,他就能够返回给我们想要的数据。本文将介绍下Linux文件系,并着重从系统层面介绍下主要的数据结构
文件系统是什么
我们从一个最基本、经常被问起的一个问题入手:如何定义文件系统?文件系统是一种组织存储设备上的数据和元数据的一种方式。当然要想用代码来实现这个‘模糊’的定义是一件多么有趣的事情。正如前面提到的,有超级多的文件系统种类。基于此种情况,我们期望的是Linux文件系统的结构是分层实现,可以将用户接口层、文件系统实现层以及驱动实现曾区分开来。
挂载(mouting)
将文件系统和存储设备联系起来的方法是挂载(mouting)。mount命令通常被用于将文件系统和当前文件目录级别联系起来。在mount过程中,需要提供文件系统类型、一个文件系统、以及挂载点。
从Linux文件系统的角度来举例来说明,基于当前文件系统的文件中穿件一个文件系统。首先我们可以使用dd命令创建一个指定大小的文件(这里使用/dev/zero作为源)。换句话说,文件全零。
xxx@xxx:~/CODE/tmp/macro $ ls -al
-rw-rw-r-- 1 xxx xxx 409600 Jul 4 16:11 file.img
xxx@xxx:~/CODE/tmp/macro $ dd if=/dev/zero of=file.img bs=4k count=100
100+0 records in
100+0 records out
409600 bytes (410 kB) copied, 0.0094725 s, 43.2 MB/s现在我们有了一个文件大小为400k的文件file.img。使用losetup命令给file.img分配一个设备。这里不打算这样搞,因为我这而没有root权限,而且不太清楚/dev/loop0设个设备时干啥的,所以这里这一步就先跳过(译者注)
losetup /dev/loop0 file.img接下来使用mke2fs来在file.img上创建文件系统(其实质也就是所谓的/dev/loop0)。
xxx@xxx:~/CODE/tmp/macro $ mke2fs -t ext4 -c file.img 100
mke2fs 1.42 (29-Nov-2011)
file.img is not a block special device.
Proceed anyway? (y,n) y
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
16 inodes, 100 blocks
5 blocks (5.00%) reserved for the super user
First data block=1
1 block group
8192 blocks per group, 8192 fragments per group
16 inodes per group
Checking for bad blocks (read-only test): done
Allocating group tables: done
Writing inode tables: done
Filesystem too small for a journal
Writing superblocks and filesystem accounting information: done如果我们使用了losetup命令将/dev/loop0和file.img关联起来,那么/dev/loop0也就可以看做是file.img啦。但是我们这里并没有执行这个命令。这里打算将file.img mount到~/CODE/tmp/macro/mountfile,需要注意的是:文件系统为ext2;一旦mount成功,就可以认为是一个新的文件系统啦,可以使用ls命令查看了
root@xxx:/mnt/sda/xxx/CODE/tmp/macro# ls mountfile/
root@xxx:/mnt/sda/xxx/CODE/tmp/macro# mount -t ext4 file.img ./mountfile/
root@xxx:/mnt/sda/xxx/CODE/tmp/macro# ls mountfile/
lost+found
接下来我们在我们mount的文件系统~/CODE/tmp/macro/mountfile上创建另外一个文件系统。
root@xxx:/mnt/sda/xxx/CODE/tmp/macro/mountfile# dd if=/dev/zero of=file.img bs=4k count=10
10+0 records in
10+0 records out
40960 bytes (41 kB) copied, 0.000257434 s, 159 MB/s
mke2fs -c xxxx
我们可以使用同样的方法在~/CODE/tmp/macro/mountfile上创建一个新的文件系统,并将其挂在到对应的节点。演示到这里,能看到Linux的文件系统的强大之处。
文件系统架构
到现在为止,上文已经介绍了文件系统是如何被一步步构造起来的,接下来将回到Linux文件系统的架构层面进行介绍。这里将从两方面进行说明。第一:从顶层的使用者角度;第二:从文件系统的具体实现、如何开发等角度进行阐述。
文件系统架构
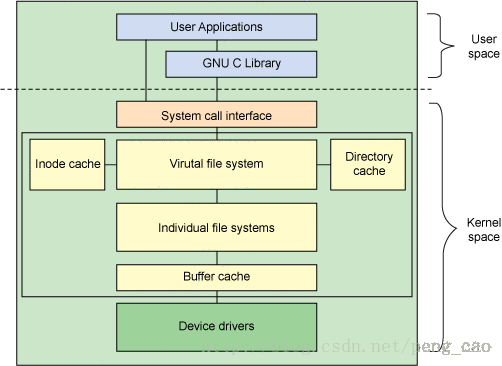
文件系统相关的绝大部分代码存在于kernel源文件中(除去用户空间的一些相关操作),他们之间关系如上图所示,
- 用户通常指一些应用(这图所示的是指一些system相关的)以及GNU C Library等给用户提供了诸如open、close等系统调用的一些公共库。系统调用用于汇聚上层的一些请求并将其传递到kernel空间。
- VFS是在文件系统中的一个最重要的接口,该组件暴漏出了一些列的接口并且将其进行抽象独立于文件系统。VFS中提供了Inode cache 和Directory cache这两个重要的缓存机制。用于缓存最近使用过的对象
- 每一个独立的文件系统的实现,录入ext2,JFS等等,都会通过VFS给用户提供大量的接口以供使用。buffer cache操纵者文件系统和块设备之间的读写buffer cache。如:读写请求就必须要经过这里的buffer cache。这就允许一些请求被缓存,以达到高速读取的目的(而不是直接去物理设备进行寻址然后再读取)。buffer cache 由LRU算法进行管理。这里需要注意点的一点是:我们可以通过相关的同步命令(flush)来强制的将buffer数据写入物理设备,buffer cache中的所有缓存都会被写入物理设备。
主要结构
Linux通常是通过一系列公用的对象来看待文件系统。这些文件对象是指:superblock、inode、dentry和file。在文件系统的最开始通常是superblock,superblock描述和维护着文件系统的状态。每一个对象在文件系统中的表现形式都是inode。inode包含了所有的对于文件系统管理着所有用的metadata信息(例如:可以在当前对象上进行哪些操作等等)。另外一类结构我们称之为:dentries被用来在name和inode之间进行转换,dentries保存了大量的最近使用的信息。dentry也保存了目录和文件之间的关系。总而言之:VFS代表了一个打开的文件(保存有文件的open、close、write offset、read offset等信息)
虚拟文件系统层
从某种角度上来说,VFS担当了文件系统的顶级接口。VFS同当前被mount的文件系统保存着密切联系。
文件系统可以通过一系列函数将其动态的添加、移除。但是kernel同样也保留着当前所支持的文件系统列表,在用户控件,可以通过/proc来查看文件系统。/proc这个虚拟的文件向用户空间展示了当前所被分配的设备。如果需要在Linux中新增加一个文件系统。需要调用register_filesystem()。这个函数只有一个参数file_system_type,这个参数定义了文件系统的名称、属性、以及两个superblock相关的函数。当然可以register也就可以unregister。一旦我们注册了一个新的文件系统,那么就会被添加到file_system列表中,该列表记录着当前所支持的所有文件系统(如下图二所示)。我们可以通过cat /proc/filesystem来进行查看。
root@xxx:/mnt/sda/xxx/CODE/tmp/macro# cat /proc/filesystems
nodev sysfs
nodev rootfs
nodev bdev
nodev proc
nodev cgroup
nodev cpuset
nodev tmpfs
nodev devtmpfs
nodev debugfs
nodev securityfs
nodev sockfs
nodev pipefs
nodev anon_inodefs
nodev devpts
ext3
ext4
nodev ramfs
nodev hugetlbfs
nodev ecryptfs
fuseblk
nodev fuse
nodev fusectl
nodev pstore
nodev mqueue
nodev esn_cfs
root@xxx:/mnt/sda/xxx/CODE/tmp/macro#
图二:通过kernel注册文件系统

另外一个对于VFS来说重要的数据结构如下图三所示。他提供了文件系统当前所mount的节点,该结构被连接到superblock结构体当中稍后介绍
图三:The mounted file systems list

superblock
superblock结构体从某种程度上来说是代表了对应的文件系统。他包含了一些所必须的用于管理的信息,包含文件系统名称,大小以及状态,同时还有一个块设备的引用,metadata信息等等。superblock信息常常是存储在存储媒介上的,所以:如果superblock不存在其实是可以创建,对应的数据结构如下所示: (代码在:./linux/include/linux/fs.h)
Figure 4. The superblock structure and inode operations
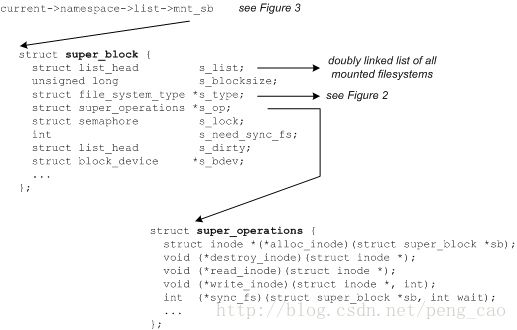
对于superblock来说,其中一项重要的作用就是定义了superblock的一些列操作。supreblock结构体定义了一系列用于对inode进行操作的alloc_inode destory_inode read_inode write_inode sync_fs等函数。对应的可以在superblock结构体中的super_operations中找到。每一种文件都提供了他自己的inode方法,并且都是有VFS进行提供了统一的抽象。
inode and dentry
Inode是文件(对象、实体)在文件系统中的唯一标识。独立的文件系统提供了filename和唯一inode标识符之间的转换方法。inode结构的一部分如下图五所示,同事也展示了其他的一些同inode强相关的结构。在这里我们需要注意inode_operations file_operations。这些结构所对应的最小操作单元是inode。例如:inode_operations定义了对inode上的目录的操作,file_operations定义了inode上文件的操作(通常叫做系统调用)
Figure 5. The inode structure and its associated operations

最近的被经常使用的inode和dentries被分别保存在inode和directory缓存中。但是,对于在inode缓存中的inode其实也是有一个dentry的引用,该引用时被缓存在dentries中的。具体的定义参加linux/include/linux/fs.h
Buffer cache
除了上面所提到的文件系统中各个独立实现的部分(通常可以在./linux/fs下找到),在文件系统层级的最底部是buffer cache。他是读写需求和物理设备之间的‘媒介’ 。为了提升效率,Linux必须保持有一些缓存需求用于避免对物理设备频繁的访问。