大数据与机器学习的平台化建设
8 月 11 日,「AI+Cloud 赋能行业新未来」为主题的 NIUDAY 成都站中,Camera360 数据部门技术总监龚俊衡为大家带来了关于「大数据与机器学习平台话建设」的分享,龚老师有超过 12 年的研发经验和拥有 4 年相关大数据架构师的经验。

本文是对分享内容的实录整理。
今天分享的主要是我们在大数据和机器学习方面的积累。从一开始到最后,基于我们自己面临的技术问题和一些业务需求,所踩过的一些坑。实际上我们尝试重新造过轮子,自己搭了一个平台。
在这里相信有许多想要学习大数据的同学,大家可以+下大数据学习裙:957205962,即可免费领取套系统的大数据学习教程
我们为什么要自己搭平台?
第一个问题:海量的数据
Camera360 有非常多的用户,遍布全球绝大多数地区,尤其是以东南亚、日韩这些地方的用户为主。Camera360 一个产品每天单纯收到的原始数据压缩之后高达 200G,还不包括小的产品,总存量数据超过 300T。所以面临着问题是:这些数据存在哪里?
因为所有数据都跟用户行为有关,比如每天用户什么时候使用我们的 APP,他喜欢自拍还是喜欢拍风景,还是喜欢用滤镜拍照等。这些数据都存储在这里,数据的安全性和可靠性非常重要。建设平台时,首先就要考虑安全性和可靠性,因为所有数据都是宝贵的用户资料,一旦丢失或者是一旦被人窃取会造成非常大的问题。
基于这些数据,我们光存在那里是没有用的。很多人提「大数据」会提到「大」这个字。为什么要存储那么大的数据量?存储是为了做什么?存在那里是为了提供价值,其中一个价值就是对 BI 产生支撑。
最早 Camera360 有了一批不小用户之后,对于工具类产品的管理人员、运营人员来说,我看看我的这些用户活跃情况、新增情况、在线时长,这些是最基本的需求。这些需求最早是利用一些第三方的 SDK,例如友盟等一些工具支撑,但是这些工具会有一些问题,就是没有办法基于运营人员需求切入更细层面的用户具体行为。
比如说用户用贴纸拍照,在前面经过哪些选择才会选择用贴纸拍照;用贴纸拍照会不会跟他用某一个滤镜有关;他用贴纸拍照是从什么路径进来,是基于首页进来,还是因为其他其他圈分享进来。这些非常细的是第三方 SDK 难以做到的事情,这块就需要我们自建数据计算逻辑来支撑,我们存在那里更多数据,其中一个作用就是提供 BI 支撑。
如果运营人员,产品人员对用户如何使用产品的细节搞不清楚,或者用户在某一些场景下容忍度比较低,比如说拍照滤镜速度太慢这些搞不清楚,就很难对下一步规划做出有效的判断。
我个人认为,我们存那么多数据最重要的一点,是为机器学习提供服务。说到机器学习就有无限的想象空间。即使对于工具类产品,它不像是什么抖音、今日头条这种内容性产品,我们在其中也能发现非常多的机器学习应用。
举一个最简单的例子,我们都要给用户发推送。一般来说怎么发呢?先说最简单的情况,看一下历史数据。看看过去一到五个月,这个地区可能是国家层面的属性,这些用户在什么时间拍照,或者是更细一点,这些用户在什么时间用什么贴纸拍照,是男的还是女的。我决定每天下午 7 点钟在泰国发一条什么贴纸信息,一下子就发出去。这种情况就会有一个问题,我们看数据,那个时间点愿意启动我们 APP的占所有用户的 8% 左右。如果在这个时间点又愿意使用贴纸拍照那数量更低,可能占总体用户的 1%。也就是说你对所有用户发一条消息,你真正命中用户,有可能在那一段时间启动的用户只有8%,可能真正用这个拍照的可能 1%,甚至 1% 都不到,这是对资源的浪费。如果用户心情不好一点可能就把你卸掉了。你要做的,不是仅仅针对一个国家在特定时间点做策略。
现在 Camera360 里的用户行为大概有上万个特征,我们把上万个特征全部拿过来,包括过去 30 天,70 天,90 天甚至 1 年前贴纸拍照的习惯。哪一个国家用户、平时在什么时间启动APP,甚至还有其他更详细特征,我们把这些东西都拿进来设置一个模型,这个模型很简单。第一,我预测用户在接下来一天使用贴纸或者是滤镜拍照概率取决于运营主题。另外预测这个用户大概在什么时间段启动 APP 的概率最大。有了这些数据,一旦决定推送 APP 后,我可以设定一个阈值。比如说 10%,用户对这个贴纸接受度至少达到 10%,基于每个用户每天使用 APP 不同时间频率发推送,效果会很好。我们预测过,机器学习预测用户启动时间和使用贴纸概率准确率,大概是 80% 左右,人工基于统计直接确定用户使用时段给所有人一起发,这个时间点准确率就是 8%,很简单的分类模型我们就达到了 1000 左右的提升,这是机器学习的例子。
我们有了这么多数据,有了这么多细节的用户学习后,就要产生价值。这么多的数据,每天还以这么快的速度增长,公司要对数据存储付出的成本非常大,这个成本只涨不跌,除非云厂商给我们来一个折扣,这个可遇不可求。面对这些数据,首先要考虑一个成本的问题。成本问题,我个人觉得最基本的一点是,对象存储或者是你自己的存储要分冷热平台,近期一年内的数据放比较热的数据,做到可以随时读取。数据归档后的存储,比较长的时间放在冷的平台里比较好。
这是我们面临第一个问题,海量数据以及我们为什么会有海量的数据。
第二个问题:机器学习的快速发展
这也是绝大多数公司遇到的问题。机器学习从 2012 年开始处于快速发展的周期,尤其是近 1-2 年发展非常快。我在做 PPT 时,上 ArXiv.org 网站上查 Machine Learning 关键字的论文,在上个月是 319 篇。公司为什么要追最新技术?比如说公司一个系统,准确率和召回率,NDCG 可能是 0.63 左右,新论文提出来 0.63 会提升到 0.65,甚至更高。你不跟进,那么对方就比你有优势。
因为我们现在的互联网用户跟之前 2012 年、2013 年的用户有一个最大的区别是选择太多。一个拍照软件去App Store 随便搜一下几百个,用户为什么用你这个东西。假如说,大部分这样应用有一个智能滤镜模块,如果我这边的模块效果,没有让用户达到想自拍的时候可以自动选择比较适合当前场景,或者是适合这些人肤色、脸形等更为合适的滤镜。用户很有可能直接选竞品就走掉了,这是搞机器学习算法要不断更新的原因。这些对用户体验、公司收入、用户留存等都会产生影响。
之前提到的一个月 319 篇,按照正常毕业 3-4 年的数学系、计科系的毕业生,在具备一定机器学习背景经验上做一篇论文要花多长时间呢?目前公开发表的很多论文不提供源代码,只有原理阐述,大部分基于相对靠谱的公开数据集, 在 2017 年我们数学底子比较好的工程师复现一篇论文大概是超过两周时间,最好一点就是工程师数学底子好,大概一周多时间。加入说这 300 多篇论文只有 10% 跟我公司有关,我要用多少工程师把这些论文复现,这是很大的问题。如果公司产品存在很多相关竞争对手,漏掉几篇就有可能导致竞争对手对你的超越,这是复现。还不包括我们需要自己实现一些算法改进,这种情况需要消耗更多的时间。要么我投入很多资源,我招很多优秀的人才跟进机器学习技术的发展,要么能不能采用其他的手段提高现有开发人员效率来复现论文呢?这是我们面临的第二个问题。
第三个问题:机器学习模型的复杂性
在这里相信有许多想要学习大数据的同学,大家可以+下大数据学习裙:957205962,即可免费领取套系统的大数据学习教程
很多机器学习模型已经迁移到深度学习,包括我们公司在内,公司从去年六七月之后再也没有部署新的传统模型了。我们这样做的一个前提是大数据,手上有很多的用户数据千万甚至上亿,我们要用一个模型把这些数据都用上。所有这类模型一定有一个特点,这个模型复杂度要非常高,否则根本无法利用如此多的数据。假如在有很多的数据使用了相对非常简单的模型,可能模型根本跑不完数据就完全收敛了并可以观察到大量的偏差,这种情况下就要提高模型复杂度降低偏差,基于这个特点上千万上亿的训练参数模型都可能存在。这样的模型就会存在比较多的超参数,用什么样的优化器,网络都少层, 每层多大, 需要 BN 或者 Dropout 不,这么多超参数加这么复杂模型带来非常大的挑战,这个模型不是效果好坏的问题, 而是需要训练多少时间到底跑不跑得出来的问题。
我们之前训练一个大概 7000 万多个参数的推荐模型,中间可能复合几个小规模模型,一个 GPU 上要跑两天时间,两天时间跑完一遍训练。如果在几十个超参数上完成搜索要跑多久,几个月时间吗?这很明显是不现实的事情。现在机器学习复杂性就摆在这里。
这种情况下,唯一一个办法就是分布式训练。根据我们经验,模型分布式会面临一个新的问题,我们要去找一个工程和算法能力比较强的人才非常难得,现在又加上一条要求熟悉分布式,你要让他学会在分布式环境里怎么解决网络瓶颈、IO 瓶颈。去哪里找这样的人?,如果有可以推荐给我。
深度学习如果过于复杂,你提供一个小数量量可能会过拟合,这么大的数据我们就加大数据量,十万、二十万、三十万、一百万、二百万慢慢往上提,训练成本非常高,训练一个深度模型的成本非常高。
第四个问题:有限的资源和成本
在有限的资源和成本的情况下,诚挚给大家一个建议:尽量不要自己造轮子。后面会跟大家讲如何造轮子,但是我还是要跟大家说不要自己造轮子。中小型公司面临一个问题,就是说在大数据和机器学习这边的资源投入一定是非常有限,以后绝大多数资源需要投入运营、市场、App 本身开发,或者是新方向的尝试上去。如果我们维护一个 20 - 30 人这样相对比较大的团队,单纯只是为这方面服务,我觉得对中小规模公司不太现实。我个人建议去选一个靠谱的 AI 大数据平台解决方案。
我们自己怎么造轮子?
下面介绍一下我们自己是怎么造轮子的,不然今天 PPT 绝大多数的内容就没了。主要介绍我们建设这个平台时,中间走过什么路、踩过什么坑。

最早我们想看一下用户行为统计、日活、月活等基本用户,我们当时用 HDFS、Hbase,搭建了数据脚本化查询的东西。每天很简单,在这个部门工作的同事也很枯燥,运营人员、公司管理层或者是产品提一个需求,然后他们就写完跑,等 3 个小时甚至更长时间才能跑出来,有时想看 1、2 年数据就要跑更长时间,可能用 1 到 2 天。那时候我们还在使用机房,当时团队 6 个人,运维占 2 个人,超过 1/3 资源投入在运维上。这个阶段主要是提供 BI 支持。
2016年问题逐渐出现了,就是需求越来越多,不是简单一个开发人员就可以做完的。这种情况下没办法每次新提需求就写一个,我们可以提供离线查询你们自己做,2016 年就是在做这件事情。2016 年机器学习已经兴起,产品内的一些细节的数据需求,比如关于滤镜、贴纸细节使用这样的也开始增加了。产品本身功能也越来越复杂,当时公司想做内容方面的尝试,我们就开始准备特征仓储,专门为机器学习服务。因为运营人员想看到的数据层面和我们机器学习用到的数据层面不太一样,希望我们特征库在任意一个时间尺度上捕捉到用户的行为特征。因为开始并不知道用户哪些特征管用,哪些特征会好,我们尽可能把特征全面的准备出来,预先计算好存在那里。
我们主要做两块,一个是刚才提到的特征库,另外是机器学习的算法。当时是用 Spark MLib 做推荐,内置一些算法,比较简单就可以实现,能够实现相关业务比较与人工基线 20% 左右的提升,在当时来说也算是小突破。大家不要小看 Spark MLib,我们完成这样简单的模型后几乎没有调参,也没有更多算法层面的工作,用户对贴纸接受度提升了 20% 以上,对次留也提高了 1%,这给我们当时非常大的信心,就是促使我们在机器学习方面做更大投入。
2017 年开始进行落地,2017 年都是离线,如果我想给用户提供贴纸,必须等到次日凌晨数据计算。模型对所有用户预测后才能看到我们推荐的贴纸和模型。工具类产品有很大一部分用户留存时间会非常短,可能就下载下来用 2 - 3 个月用户就走掉,如果模型还是离线模式工作很难对这部分用户产生价值,这部分用户还是会和人工推荐发生一些关系,当时我们开始向实时化迁移。因为之前做立宪这块,基本上利用图像存储、利用 Park 存储算,最多就是注册一个表,这样相对快一点。一旦写了就不可改变的行为,不适合我们的场景,所以我们就做了实时的数据仓储。
实时数据仓库做的事情,相当于把之前数据实时性做一次提升。其实很简单,用户本来每天凌晨对当天特征做聚合计算,然后存储在上面。实时计算用户以 5 - 10 秒为一个 Batch,把 24 小时降低到 5 秒,计算完立刻更新。我们有了实时计算后,因为我们之前 Spark MLib 中的算法也不支持实时增量,就把 Spark MLib 向 Tensorflow。在这里可能只有一句话,但是做还是花不少时间,到 2017 年初时还没有任何机器学习平台,我们做所有模型是一个工程师从头走到尾。MLib 的矩阵分解算法迁移到自编解码的协同过滤算法花了半个多月。我们迁移到 Tensorflow 之后,获得了一些实时性上的好处. 这是 2017 年初的进度。
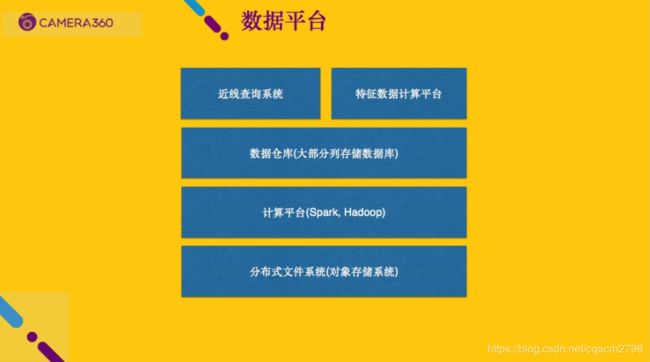
2017 之后经过这次模型迁移之后,我们意识到一个问题,后面想做更多的机器学习相关业务,或者是机器学习及 AI 相关的东西来增强我们的产品。像现在的这种开发模式肯定是不行的,一个原型模型需要花两周甚至更长时间。基于这个原因我们就需要进行平台化建设,首先是对我们数据平台进行一下梳理。离线存储还是需要,不可能所有都存储实时介质的中去,十几台成本还可以接受,上百台可能就接受不了。最底层需要有成本可控的一个分布式文件系统(或者对象存储),最上面有一个计算平台,可以是 Spark、Hive 都可以,我们最主要是 Spark Sql, 我们搭了一个集群.
数仓主要是为业务方服务,快速查询数据。之前提到的近线查询系统,它和数仓有一定的相似性,我们所有用户行为数据是实时增量计算并落地,每天晚上在统一导入数仓,实际上计算成本并没有增加,再一个就是就是特征数据计算平台。特征数据计算平台我们基于 Zeppelin 定制了一个数据交互式平台(包括对应的 IntelliJ 插件)。如果没有这个平台开发人员要跑一个任务很麻烦,你在云端起了一个集群,自动安装很多软件,然后本地一个脚本提交上去跑,还不一定能跑成功。起始阶段多半是失败,反复尝试终于成功,稳定运行了才能放到我们的调度平台里面去。有交互是查询平台之后,起一个计算集群,起完就会有这样一个网页(类似 Juypter),在里面做交互查询,写代码都可以,这块主要是给我们的开发人员用。用这个的好处是,绝大部分特征抽取任务在这个平台里都以通用框架的方式,框架包含了特征预处理的各种工具, 也能输出不同的格式, 比如 csv, parquet, tfrecords 等,有了数据平台后开发人员大部分的任务不需要从头到尾写。
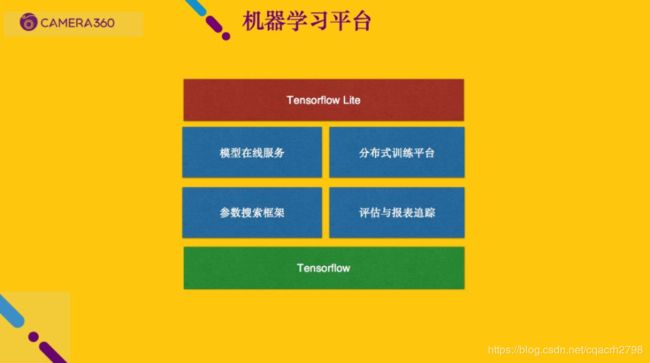
机器学习平台是这样,我们平台比较简单,后端基本上只有 Tensorflow。这里有一个比较重要就是模型在线服务, 可以考虑使用它的 Serving, 或者自己基于 Flask 写一个 Web Service这块下来看文档就行了,但是我更想说的是参数搜索框架和分布式训练平台。分布式训练平台比较简单也比较容易理解,之前提到训练大规模模型时通常需要非常多的时间,这种情况下单机多卡方式训练它,等几个小时或者一两天训练完开发人员来看看指标,不行再调,这种工作模式效率实在太低。首先我们需要一个支持数据并行的分布式平台,并行计算多个批次的数据,求梯度均值之后再更新到参数服务器,这块是非常必要的一个东西。但这块也没什么好说,像 Tensorflow,像绝大部分的机器学习框架都是提供分布式的功能, 当然这里面有比较大的学习成本,所以我建议选择比较成熟的机器学习平台,绝大多数情况只需要告诉它你这个模型需要多少计算资源就行了。
还有一个非常重要,但是很多人都没意识到,开发人员做完数据准备和模型设计, 剩下的就是两个字「调参」。很多人说机器学习就是花九天时间准备一个数据,花一个小时建立模型,再花九天调参和优化,确实是很枯燥。开发人员输入一组参数,跑完看结果,甚至是边跑边看,一天让他对黑绿屏幕终端发呆,这很明显是很低效率的工作。参数搜索就是开发人员提供一个参数空间,定义这个模型需要多少层、每层什么样的参数、每一层放什么, 甚至是不同的模型结构,我们把参数都提供给他。他需要做的首先是计算这次的参数空间有多大。因为我们平台是基于云平台,知道参数空间有多大之后,就可以知道大概需要多少次的计算,就能够搜索完绝大部分的参数组合。这种情况下,框架会去后台自动启动多个计算集群,并行去跑。最多启动 1 - 200 台 GPU 机器搜索模型参数,听着很吓人,但是算下来成本并不是很高。
接下来我会说成本的问题。使用参数搜索框架是因为不想让开发人员更多时间浪费在这方面。现在其实有更好的做法,谷歌很早就提供一个 AutoML 的东西,官方宣传很奇妙。你给它样本之后就不用管了,可以自动生成模型。现在不仅参数,开发架构都不用,扔上去让平台帮你搞定,但是这个东西一小时 20 美金,我们完全用不起。
前两天我看到一篇论文,论文很长,从头到尾描述了一个基于 ENAS 实现,这个作者非常厚道, 大部分其他的论文长篇大论完了之后没有代码只有理论,但是这个论文很厚道给了 github 上的源代码。基于这个算法搜索出可用的网络,在给足够资源情况下,比我们人工设计的更好。如果我们把这个东西拿过来,基于 Tensorflow,稍微改一下和自己的系统对接起来,再用机器学习就非常简单,我们只需要开发人员把数据处理好、特征工程做好、标签设定好,提供资源让框架跑就行,跑完就可以拿到可用模型。开发人员也很开心,他只需要维护这套框架就行。
在这里相信有许多想要学习大数据的同学,大家可以+下大数据学习裙:957205962,即可免费领取套系统的大数据学习教程
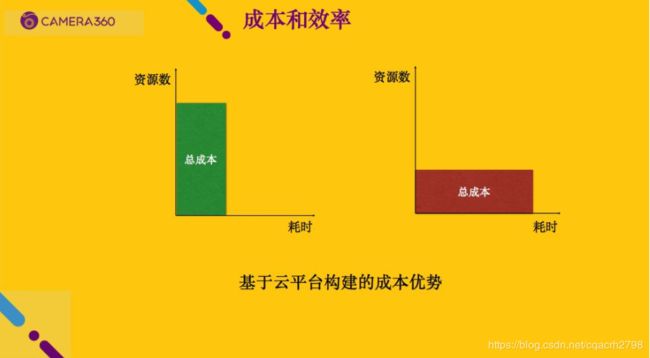
为什么我刚才说一次几百台机器搜索参数不要紧,原因是这样的。看上面的图,在资源有限的情况下,假设我自己有一个机房,我有十几台按月租的机器,我要做同样一件事,总成本是红框的面积大小,所消耗的时间是下面轴长的大小,可以看到成本就那么多。跟左边图比一下,左边图上面是资源数,绿色框最上面就是我们说的几百台机器,运行时间可以大大缩小,中间数学原理其实是很简单的。基于云平台做这件事情最大的好处是,我司花很大的代价迁到云平台,就是因为总成本不变、耗时更少,我们会有很大的时间优势在里面。
总结一下做机器学习最好有个参数搜索,甚至模型搜索的框架。第二,这套东西一定要跑到云上。最后,有了这两个东西之后,我们去做机器学习的效率就会大大的提升。
以上就是今天分享的全部内容,感谢。