导读
在当今Web服务数据中心网络中,网络设备的故障已经逐渐成为日常发生的事件。对于故障发生后如何处理,之前已经提出了很多的研究。不幸的是,数据中心部署的互联网服务的性能依然受到影响。本文介绍的是NetMan实验室发表在SIGMETRICS2018的一篇文章《PreFix: Switch Failure Prediction in Datacenter Networks》,文章采用了一种不同的方法——预测故障。这样,运维人员就可以在潜在故障发生前介入并解决。
简介
当前,数据中心网络中传输了大量的数据流量,并部署了大量的服务器和网络设备,包括ToR 交换机和聚合交换机在内的多种交换机,从服务器收集数据流量,并转发和汇聚给上层的路由器。因此,交换机在数据中心网络中扮演了基础的角色。交换机故障,即交换机不能够转发流量的事件,在数据中心网络中经常发生,在总的网络设备故障中占主导地位,为了让数据中心网络具有较好的容错机制,处理交换机故障是很有必要的。
当前的数据中心网络故障容错方案,聚焦于改变协议和网络拓扑。这样,数据中心网络可以自动地从网络故障中恢复。但是,上述方法并不能覆盖所有的交换机,有时候又需要运维人员快速的诊断并定位。这些方法或者面临部署问题,或者需要大量的时间以定位并解决交换机故障。在这篇文章中,提出一种新的思路,即在交换机故障发生前预测交换机故障。使用这一方法,可以通过提前“解决(fix)”问题,以有效地避免互联网服务性能受损。因此,命名新的系统为“PreFix”。
设计思想以及困难
在研究交换机故障预测这一问题时,很重要的一点是明确什么是交换机故障预测。PreFix 致力于在运行中决定一个交换机是否会在未来近期内发生故障。这一故障预测基于对当前交换机系统状态的测量,以及对历史交换机故障的研究。
当用于在线预测时,故障预测系统需要每隔一段时间就预测一次。所以,需要首先通过把较长的时间区间切分成小的时间片,以实现把连续的时间转化为离散的时间。文章研究的对象是一个拥有固定时间长度的时间片(比如15分钟),想要预判在这个时间片未来的一段时间之内(比如0.5小时到24小时)是否会发生故障。在对训练样本标注的时候,如果在某个时间片之后的一段时间内,并没有发生故障,那么时间片是非征兆消息序列,反之就是征兆消息序列。因此,交换机故障预测问题转变成了一个时间片分类的问题。即根据时间片的关联消息序列,将时间片分类为征兆时间片或非征兆时间片。
PreFix 的思路是,同一交换机型号的交换机在故障发生前共享相同的系统日志模式,可以采用机器学习的方法将这些共同的模式从日志中提取出来以预测交换机的故障。
PreFix面临的困难如下:
系统日志中的噪声信号。系统日志中包含了非常丰富的信息,然而并不是所有信息都能用于故障预测。因此需要过滤掉无关的系统日志消息,获得可靠的预测模式。
样本失衡。对于一个数据中心来说,往往产生海量的日志,交换机故障的比例太小,也即机器学习的正样本和负样本严重失衡,这对于一个机器学习问题来说,要达到高精度和高召回率是一个很大的挑战。
运算时计算开销。在文章研究的数据中心网络中,如果每15分钟做一次故障预测,则需要分析200,000条系统日志消息。开销太大。因此,PreFix 中特征提取和预测模型必须具备较高的计算效率。
PreFix系统
PreFix 的整体模型如下所述。对于每一个型号的交换机,在离线阶段,PreFix从历史系统日志消息中学习消息模板,从模板序列中提取4个特征,并基于历史交换机故障案例,采用随机森林(Random Forest, RF)方法训练模型。相似的,在在线预测阶段,PreFix 将一台交换机产生的实时系统日志映射到系统消息模板上,提取4个模板序列特征,并使用训练过的模型确定该交换机在不久的将来是否会发生故障。框架图如下所示:

Prefix_framework
下面我们要介绍一下系统的详细细节。
首先需要从历史系统日志消息中学习消息模板。文章采用NetMan实验室提出的FT-tree方法,准确地、增量式地从系统日志消息中学习模板。总的日志模板是固定的,文章定义为N。学习系统日志消息的模板之后,可以将一个历史系统日志消息或一个实时系统日志消息与一个特定消息模板匹配,并使用该消息模板的ID来表示该系统日志消息。
在完成模板提取之后,系统将会提取出模板序列的特征用于预测,但是PreFix并不聚焦于单个消息模板中的单词,而是聚焦于模板序列的模式,包括频率、周期性、序列和爆发性4种特征以构建描述特征的向量。
频率特征。对于一段时间而言,PreFix构建一个N维向量以表示每一个消息模板出现的次数,从而实现提取消息模板序列的频率特征的目的。特别的,对于某个时间段来说,统计每一个日志模板出现的次数,也就是N维向量中,每一维的数字,从而构成频率特征。
周期性特征。PreFix 尝试判断某个消息模板是具有周期性,我们用aj作为衡量消息模板周期性的数值,它的的计算是基于所有匹配到tj模板上的系统日志的时间跨度, 因此对于同一个tj,这个值会保持恒定。
序列特征。多个交换机故障前的系统日志消息共享了某些共同的序列特征。如果能够从征兆模板序列中提取出有用的模板序列特征,并过滤掉噪声消息模板,就可以得到有用的特征。为此,我们提出了一个新的方法,LCS2,即两阶段的最长公共子序列(LCS)。LCS2算法背后的动机是如果两个征兆模板序列拥有共有的部分,那么它们的LCS不仅仅继承了共有的部分,同样过滤掉了一些两个模板序列中噪声序列模板。
爆发性特征。尽管某些单独出现的特征模板对故障的预测并没有什么帮助,但是当它们突然出现的时候,就往往意味着故障。对于一个给定的日志模板tj,如果tj出现的次数在一段时间中存在一个或多个突然的增长,意味着爆发。在第i个时间段内,我们可以得到Oi=(O1,O2...On),其中,On是模板tn出现的次数,因此上述问题转化为求出现在Oi中的一个或者多个尖峰。我们已经有了检测时间序列中行为变化的方法,该异常检测方法基于奇异谱变换,从而可以提取出爆发性特征。
在PreFix的最后一步,系统采用一种有监督的分类算法,即随机森林算法(Random Forest)来判断是否一个时间片对应的模板序列预示着故障。在本章的实验中,选择Gini 系数来计算信息增益并选择属性。我们对时间片提取4种特征,对于发生过故障的时间片,PreFix将其标记为1(也可以称之为正样本)。类似的,把每个没有发生过故障的时间片标记为0。这样就得到了特征和标注,我们把它们送入到随机森林中,训练模型,并用于检测。
实验验证
数据集
通过与网络运维人员合作,文章随机地挑选了来自2个交换机生产厂商的3种交换机型号(为简单起见,此后将使用M1,M2,M3 分别标记这3 种型号的交换机),并使用数据中心网络中所有的属于上述3种型号的交换机以验证和评测PreFix 的性能。具体地,文章分析了上述交换机超过2 年的系统日志以及全部的硬件故障。这些交换机分布在超过20个数据中心中。所有的交换机硬件故障都是经过运维人员人工验证的,所以可以被用作本章评价PreFix性能的标记好的真实数据。
系统评测
PreFix 是首个基于系统日志的预测数据中心网络中交换机故障的系统。因此,在这个领域内没有可以用来对比的基准测试方法。为了展示PreFix 的性能,文章将PreFix 与其他两个流行的基于日志的故障预测方法做对比。这两种方法分别是应用于计算机系统的SKSVM方法,以及应用于骨干网设备的HSMM方法。我们采用PR_curve来对这三种方法做一个对比。

M1型号交换机

M2型号交换机

M3型号交换机
从PR 曲线中可以看出,在三种型号的交换机中,PreFix 均优于其他两种方法。在本章的场景中,HSMM只提取了序列特征,但是其他3种特征也同样重要。此外SKSVM的性能也不好,因为其只提取了序列特征,并且该方法过多的依赖于序列的连续性,当存在噪声,效果非常差,同时,考虑到计算成本,系统日志消息的消息类型被用作系统日志消息的SKSVM标签。但是,消息类型并不能完全地提取出系统日志消息所代表的事件。
为了论证PreFix的通用性,文章把PreFix系统用在了硬盘故障预测上。在评估过程中,使用的是Backblaze数据集中的ST4000DM000硬盘模型,包括了29084块硬盘,其中发生过的硬盘故障已经被运维人员标出。该实验的PR_curve如下:
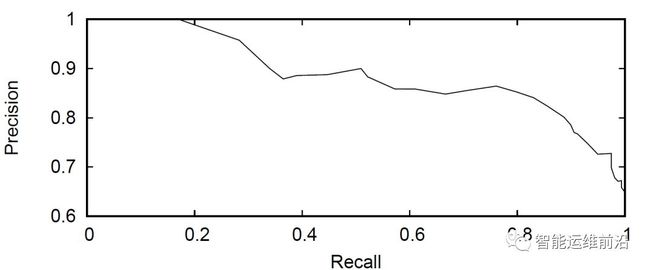
从图中我们看到,最好的f1score可以达到0.837。尽管PreFix并不是特地为硬盘故障预测而设计的系统,但是在这一问题上,它仍然有很好的性能,这表明了PreFix的通用性,也表明PreFix也可以用在其他的设备中。
总结
文章设计并实现了一个新的框架——PreFix,用于预测在不久的将来是否会发生交换机硬件故障。对于每种型号的交换机,在离线学习阶段PreFix 从历史系统日志中学习模板,将系统日志消息与模板匹配,从模板序列中提取频率,爆发性用周期性和序列特征,并使用随机森林模型学习故障模式和非故障模式。类似地,在在线预测阶段,PreFix 将实时的系统日志消息与模板匹配,提取4种特征,并使用随机森林算法以确定当前状态是否预示着交换机故障。文章通过使用部署在超过20个数据中心中的3种型号的近万台交换机上采集的系统日志,比较SKSVM、HSMM 和PreFix 的性能。实验证明了PreFix 在准确性方面优于SKSVM和HSMM。具有较高的精度。同时又通过磁盘故障预测,证明了PreFix的通用性。