一文掌握Redis的主从复制原理到实战
编程界的小学生
- 一、为什么要主从复制
- 二、主备和主从
- 1、主备
- 2、主从
- 三、主从三种方式
- 1、同步阻塞
- 1.1、原理图
- 1.2、优缺点
- 2、异步非阻塞
- 2.1、原理图
- 2.2、优缺点
- 3、同步阻塞MQ
- 3.1、原理图
- 3.2、优缺点
- 四、主从原理及实战
- 1、仅开启RDB
- 2、仅开启AOF
- 3、混合模式(RDB+AOF)
- 五、主从复制配置文件
- 1、配置主从
- 2、主从传输数据这期间,从节点是否允许对外提供服务
- 3、是否开启Slave从节点也支持写命令
- 4、先落磁盘再传输还是直接网络传输
- 5、全量还是增量
- 六、个人公众号
本文说了大量的CAP这三个字母的概念,不知道的转到这里
大白话图文结合的方式讲解什么是CAP
一、为什么要主从复制
为了实现高可用。如果单机的话,那么机器挂了,直接GG,影响业务。主从就是为了解决这个单点故障的,主(M)从(S)中任一节点挂了,其他节点还可以正常提供服务。不会影响当前业务。
二、主备和主从
1、主备
请求都只能打到Master主节点上,备机只是等主机挂了后来自动升级为客户端继续提供服务。也就是说他不会为主节点分摊请求压力。
2、主从
读请求会均摊到主节点和从节点上,而不是等主机挂了才提供服务。写请求在master上进行,然后同步到slaver。读请求会分摊,比如10w个请求,一主双从的话,可能M上3w个,两个S上处理6w个,他会为主节点分摊压力。所以可以解决单点故障问题。
三、主从三种方式
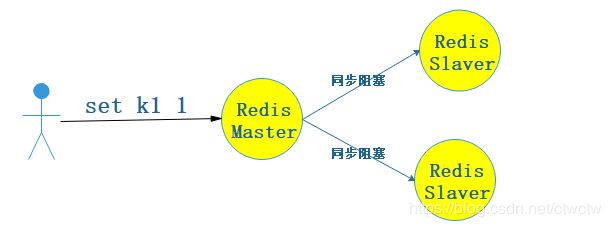
1、同步阻塞
1.1、原理图
这种方式讲究强一致性,必须等所有Slave都写入成功后我才会给客户端响应,否则一直阻塞。也是CAP中的C。
关于CAP的知识看这里大白话图文结合的方式讲解什么是CAP
1.2、优缺点
- 优点:数据强一致性。(但是会破坏可用性,也就是CAP的A)
- 缺点:效率低,同步阻塞。
2、异步非阻塞
2.1、原理图
redis采取的这种方式。没有采取下面同步阻塞mq的方式可能也是因为效率吧,因为Redis就是要高效。客户端发完请求到Redis Master后,立马给客户端返回,我不管你Slaver是否同步完成。保留CAP的A,舍弃C。

2.2、优缺点
- 优点:效率高,异步非阻塞。
- 缺点:会丢失数据,满足了CAP的A,舍弃了CAP的C。
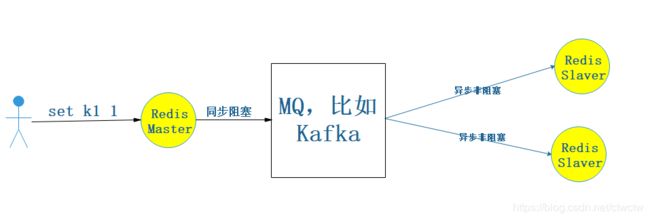
3、同步阻塞MQ
3.1、原理图
大数据hive采取的就是这种方式,他会保证最终一致性。相对于第二种方式好处在于能保证数据的最终一致性,坏处在于没第二种方式高效。但第二种存在丢数据的风险。
3.2、优缺点
- 优点:效率相对较高、能保证数据最终一致性。
- 缺点:没发现啥缺点。非要说缺点那就是有可能取到不一致的数据,因为不是强一致性。为什么Redis不采取这个?因为Redis要高效率,不想融入太多组件(MQ)进来。
四、主从原理及实战
其实就跟MySQL一个道理,mysql是靠binlog,而Redis靠的是rdb文件和aof文件。
对rdb和aof有疑问的转到下面连接
彻底搞懂Redis持久化之RDB原理
彻底搞懂Redis持久化之AOF原理
Redis持久化之RDB与AOF对比总结
1、仅开启RDB
仅仅开启RDB持久化,关闭AOF。
首先启动三个redis,端口分别是6379、6380、6381。我们这里设定6379为Master,其余两个为Slaver。
(1)如何设置Slaver

可以看到Redis5.x后开始用REPLICAOF命令代替5.x版本之前的SLAVEOF命令。
(2)设置Slaver
# 设置6380是6379的从节点
127.0.0.1:6380> REPLICAOF localhost 6379
OK
# 设置完成后去看6379和6380的log
# 6379的log
见下面第一个张图(名称为6379的log)
# 6380的log
见下面第一个张图(名称为6379的log)


(3)在Master执行写命令
127.0.0.1:6379> set k1 123
OK
127.0.0.1:6379> get k1
"123"
(4)在Slave(6380)上查看是否同步过来了
127.0.0.1:6380> keys *
1) "k1"
127.0.0.1:6380> get k1
"123"
(5)Slave是禁止执行写命令的
127.0.0.1:6380> set k2 123
(error) READONLY You can't write against a read only replica.
(6)设置6382也作为6379的Slave
设置从节点之前先在6382内set一个值,为了确定设置完后会进行flush操作。
127.0.0.1:6381> set k2 222
OK
127.0.0.1:6381> get k2
"222"
然后设置Slave
127.0.0.1:6381> REPLICAOF 127.0.0.1 6379
OK
127.0.0.1:6381> keys *
1) "k1"
可以获得如下两个知识点
- 设置Slave后进行了flush操作(上面的log也体现出来了),我们之前的k2没了。
- 将Master的数据同步过来了。
(7)补充
若6381宕机了,这时候他再启动的时候是会同步Master的数据的,增量同步的。不需要手动进行同步。但前提是需要作为Master的Slave,有如下三种方式:
- 客户端执行REPLICAOF
- 启动Redis的时候添加 --REPLICAOF 127.0.0.1 6379
比如
service redis_6381 start --REPLICAOF 127.0.0.1 6379
- 修改配置文件
(8)Master挂了怎么办
现象
从节点会一直报错

导致的问题:
Slave无法提供写请求,只能读了。影响了业务使用。
解决方案:
让其中一个Slave升级为Master,然后其他Slave作为这个新升级为Master的从。
# 升级为Master的方法:在客户端执行,比如我们升级6380为Master
127.0.0.1:6380> REPLICAOF no one
OK
# 这时候再看6380就不会再刷错了,但是6381还在刷,
# 因为6381是已经挂掉的6379的Slave,我们需要让6381作为6380的Slave,
# 我们再操作这步骤之前,对6380set一个key,然后看6381的数据会重新复制6380的数据
# 显示业务中几乎不会存在此情况,因为从节点升级就是升级,所有主从的数据都一致,不会随意改
# 这里只是演示效果而已。
127.0.0.1:6380> set kkk 3333
OK
# 6381作为6380的Slave
127.0.0.1:6381> REPLICAOF 127.0.0.1 6380
OK
127.0.0.1:6381> keys *
1) "kkk"
2) "k1"
127.0.0.1:6381> get kkk
"3333"
(9)总结
主从复制其实就是实现高可用(虽然是人工操作),避免单点故障问题。挂掉一个节点,我其他节点可以接着提供服务,但是明显缺点发现是Slave挂掉还好,Master挂掉可就难受了,Slave太多的话那就够运维折腾的了,这时候就有了哨兵,不在此篇范围内,下篇内容。
(10)主从复制原理图

2、仅开启AOF
和上面一样。只是会按照aof文件进行主从复制数据。
3、混合模式(RDB+AOF)
流程和仅开启RDB一样,只是主从复制的时候会优先按照aof来同步数据,因为aof文件丢失数据最少,更可靠。redis会判断aof文件是否存在,若开启了aof且文件存在,则以aof复制,若没开启aof则走rdb方式。
五、主从复制配置文件
通常也是调优的一种手段。
在redis.config配置文件中搜REPLICATION
我的配置文件是/etc/redis/6379.conf
1、配置主从
# 相当于我们上面客户端执行的REPLICAOF命令,配置到配置文件每次重启就不用手动再执行命令了。
replicaof
# master的密码
masterauth
2、主从传输数据这期间,从节点是否允许对外提供服务
# 默认是ye,允许
replica-serve-stale-data yes
看下面的log(这是我们建立主从关系的时候产生的log)

意思是说在和Master建立连接,获取完Master数据之间,也就是从库进行flush操作之前,是否允许对外继续提供请求。(就是Slave完成配置之前的那些flush之前的老数据是否还允许被访问。)
3、是否开启Slave从节点也支持写命令
# 默认只读,yes代表只读
replica-read-only yes
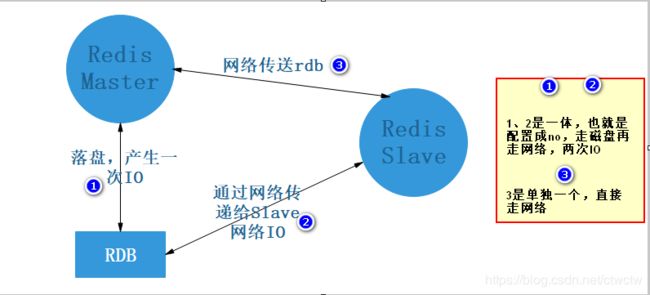
4、先落磁盘再传输还是直接网络传输
# 默认是先落盘,再进行网络传输。
repl-diskless-sync no
因为默认是Master先生成rdb文件到磁盘,这时候产生一次磁盘IO,然后将磁盘上rdb文件以网络的方式传递给Slave,这时候又产生一次IO,如果rdb几个GB的话那还不如直接走网络传输,就不走磁盘io了。 改为yes的话直接Master通过网络的方式发送rdb给Slave。默认是no,从日志也可以看出先落盘了

原理图
5、全量还是增量
repl-backlog-size 1mb
可以发现比主从复制原理图中多了个队列和偏移量。
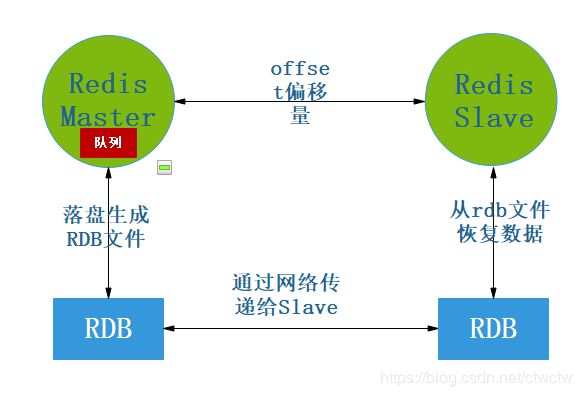
这个队列代表
repl-backlog-size参数设置的值大小,是决定全量复制还是增量复制的关键参数。
RDB每次同步到slave的时候,slave都会记录一个offset偏移量,然后每次同步数据的时候都会看队列里的数据偏移量是否符合slave上次同步的数据大小,若符合则增量,否则全量
举例:
如果设置的1MB
你挂了3s钟,假设1s钟就写了1MB,那么3s钟的队列肯定放不下,这时候就触发全量。
所以这个需要看业务调整大小。
再比如:
master是100MB数据,slave也是1MB数据,然后slave挂了。恢复的时候发现master已经有110MB了,但是队列大小只有1MB,把队列里的数据拿来显然不行,所以会触发全量,我只是举例,其实不会那么傻的判断总大小,而是通过偏移量来的。
六、个人公众号
微信公众号【Java码农社区】
