监控系统----docker部署grafana+prometheus+alertmanager+exporter
GPE监控系统
- 一、prometheus
- 1、prometheus简介
- 1.1、 基础架构
- 1.2、核心组件
- 1.3、主要功能
- 2、prometheus搭建
- 2.1、配置文件如下
- 2.2、docker启动
- 2.3、简单使用
- 二、node-exporter搭建
- 三、pushgateway和alertmanager
- 1、pushgateway搭建
- 2、alertmanager搭建
- 2.1、配置
- 2.2、docker启动
- 2.3、钉钉机器人receivers搭建
- 四、grafana
- 1、grafana简介
- 2、grafana搭建
- 3、简单使用
一、prometheus
1、prometheus简介
详细介绍见官方网站:https://prometheus.io/docs/introduction/overview/
1.1、 基础架构

1.2、核心组件
- prometheus:主要用于抓取数据和存储时序数据,另外还提供查询和 Alert Rule 配置管理
- client libraries,用于对接 Prometheus Server, 可以查询和上报数据
- push gateway ,用于批量,短期的监控数据的汇总节点,主要用于业务数据汇报等。
- exporter:多种类型,收集不同数据,如:node-exporter等等
- alertmanager:用于告警通知管理
1.3、主要功能
- 一个多维数据模型,其中包含通过度量标准名称和键/值对标识的时间序列数据
- 灵活的查询语句(PromQL)
- 不依赖分布式存储;单服务器节点是自治的
- 采用 http 协议,使用 pull 模式,拉取数据,简单易懂
- 通过服务发现或静态配置发现目标
- 支持多种统计数据模型,图形化友好。
2、prometheus搭建
安装前准备
mkdir -p /data/docker/gpe/prometheus
cd /data/docker/gpe/prometheus
mkdir -p config/conf.d
mkdir -p config/rules
mkdir data
sudo chmod 777 data
config/
├── conf.d
│ └── host.json
├── prometheus.yml
└── rules
└── instance.yml
2.1、配置文件如下
host.json
[
{
"targets": ["172.17.0.1:9100"],
"labels": {
"instance": "host-localhost"
}
}
]
instance.yml
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
prometheus.yml
详细配置见:https://prometheus.io/docs/prometheus/latest/configuration/configuration/
global: # 全局设置,可以被覆盖
scrape_interval: 15s # 设定抓取数据的频率,默认为1min
evaluation_interval: 15s # 评估规则的频率,默认为1min
scrape_timeout: 15s # 设定抓取数据的超时时间,默认为10s
alerting:
alertmanagers:
- static_configs:
- targets:
- 172.17.0.1:9093 # # Alertmanager配置,设定alertmanager和prometheus交互的接口
rule_files:
- '/etc/prometheus/rules/*.yml' # 报警规则存放路径
scrape_configs:
- job_name: prometheus
scrape_interval: 15s # 抓取周期,默认采用global配置
static_configs:
- targets: ['172.17.0.1:9090'] # prometheus所要抓取数据的地址
labels: # 定义标签,便于区分
instance: prometheus
- job_name: pushgateway
- honor_labels: true
static_configs:
- targets: ['172.17.0.1:9091']
labels:
instance: pushgateway
- job_name: host
metrics_path: '/metrics'
file_sd_configs: # 基于文件的服务发现
- files:
- /etc/prometheus/conf.d/host.json
注意:服务自动发现使用,比如我想新加一个主机节点的监控,我只需要修改host.json文件即可,不需要重启prometheus服务
2.2、docker启动
上述配置完成后,执行下面命令启动prometheus服务
注意从 2.0 开始,热加载功能是默认关闭的,添加--web.enable-lifecycle:开启配置文件热加载,可以通过curl -X POST http://ip:port/-/reload实现
docker run -d -h 172.17.0.1 --name prometheus -p 9090:9090 \
-v /data/docker/gpe/prometheus/config/:/etc/prometheus \
-v /data/docker/gpe/prometheus/data:/prometheus/data \
prom/prometheus:v2.19.0 \
--config.file=/etc/prometheus/prometheus.yml --web.enable-lifecycle
2.3、简单使用
访问:http://localhost:9090,进入到如下界面

点击Alerts,可以查看开始定义好的报警规则

查看instance状态(两个down的还没有搭建)
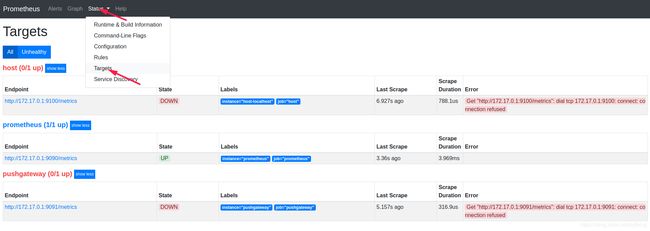
二、node-exporter搭建
docker run -d --net=host --name node-exporter -p 9100:9100 \
-v /proc:/host/proc:ro \
-v /sys:/host/sys:ro \
-v /:/rootfs:ro \
prom/node-exporter:v1.0.0
访问:http://localhost:9100/metrics
三、pushgateway和alertmanager
1、pushgateway搭建
docker run -d -h 172.17.0.1 -p 9091:9091 --name pushgateway --restart=always prom/pushgateway:v1.2.0
访问:http://localhost:9091/
2、alertmanager搭建
以钉钉报警为例
2.1、配置
详细配置见:https://prometheus.io/docs/alerting/latest/configuration/
mkdir /data/docker/gpe/alertmanager
vim alertmanager.yml
alertmanager.yml配置如下:
global:
resolve_timeout: 5m # 在没有报警的情况下声明为已解决的时间
# # 配置邮件发送信息
# smtp_smarthost: 'smtp.test.com:465'
# smtp_from: 'your_email'
# smtp_auth_username: 'your_email'
# smtp_auth_password: 'email_passwd'
# smtp_hello: 'your_email'
# smtp_require_tls: false
# 设置报警的分发策略
route:
receiver: webhook # 发送警报的接收者的名称,默认的receiver
group_wait: 10s # 当一个新的报警分组被创建后,需要至少等待多久时间发送一组警报的通知
group_interval: 1m # 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息
repeat_interval: 24h # 报警发送成功后,重新发送等待的时间
group_by: ['altername'] # 报警分组依据
# #子路由,使用email发送
# routes:
# - receiver: email
# match_re:
# serverity : email # label 匹配email
# group_wait: 10s
# 定义警报接收者信息
receivers:
- name: webhook # 与route匹配
webhook_configs:
- url: http://172.17.0.1:8060/dingtalk/webhook/send
send_resolved: true # 发送已解决通知
#- name: 'email'
# email_configs:
# - to: '[email protected]'
# send_resolved: true
# 抑制规则配置
#inhibit_rules:
# [ - ... ]
#target_match:
# [ : , ... ]
#target_match_re:
# [ : , ... ]
#source_match:
# [ : , ... ]
#source_match_re:
# [ : , ... ]
#[ equal: '[' , ... ']' ]
2.2、docker启动
docker run -d -h 172.17.0.1 --name alertmanager -p 9093:9093 \
-v /data/docker/gpe/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml \
prom/alertmanager:v0.20.0 \
--config.file=/etc/alertmanager/alertmanager.yml
2.3、钉钉机器人receivers搭建
参考:https://theo.im/blog/2017/10/16/release-prometheus-alertmanager-webhook-for-dingtalk/
注意:不同版本的镜像,消息格式可能不一样
docker run -d --name webhook-dingtalk -p 8060:8060 \
timonwong/prometheus-webhook-dingtalk:v1.4.0 \
--ding.profile="webhook=https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxx"
测试CPU报警,停止node-exporter服务:
docker stop node-exporter
查看prometheus Alerts显示的状态将变为PENDING

持续1分钟左右,状态变为FIRING,此时将消息发送至alertmanager

查看alertmanager会显示接受到的alert信息,此时alertmanager将通过webhook转发至钉钉机器人

发送消息示例如下:

重启node-exporter服务后,将再次送一次RESOLVED信息
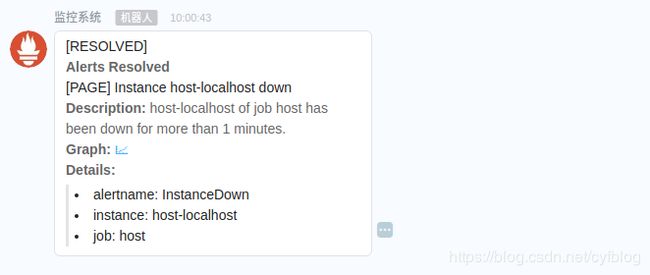
补充:告警信息生命周期的3中状态
- inactive:表示当前报警信息即不是firing状态也不是pending状态
- pending:表示在设置的阈值时间范围内被激活的
- firing:表示超过设置的阈值时间被激活的
四、grafana
1、grafana简介
详细介绍见官方:https://grafana.com/docs/grafana/latest/
Grafana是开源的可视化和分析软件。它使您可以查询,可视化,警告和浏览指标,无论它们存储在哪里。用简单的英语,它为您提供了将时间序列数据库(TSDB)数据转换为精美的图形和可视化效果的工具。
2、grafana搭建
安装前准备
mkdir -p /data/docker/gpe/grafana
cd /data/docker/gpe/grafana
mkdir data
sudo chmod 777 data
docker启动命令如下,可以通过GF_INSTALL_PLUGINS预先安装一些指定插件
docker run -d --name grafana -p 3000:3000 \
-e GF_INSTALL_PLUGINS="grafana-piechart-panel" \
-v /data/docker/gpe/grafana/data:/var/lib/grafana \
grafana/grafana:7.0.0
3、简单使用
访问:http://localhost:3000/,默认用户密码:admin/admin,注意:生产环境一定要修改密码

添加数据源,有多个类型,选择prometheus类型,进行如下配置然后点击Save & Test,没有问题即可


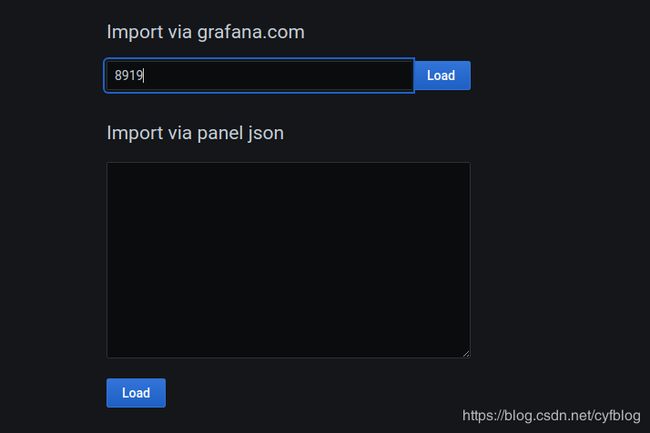
去官方查找node-exporter示例模板:https://grafana.com/grafana/dashboards?orderBy=name&direction=asc
导入:8919

最终牛逼的页面:
