使用Python处理excel表格(openpyxl)教程
现在有个小任务,需要处理excel中的数据。其实就是简单的筛选,excel玩的不熟练,而且需要处理的表有70多个,于是想着写个脚本处理一下吧。python中的openpyxl包可以轻松实现读写excel文件,下面简单介绍一下过程。
1.安装openpyxl通过pip或者easy_install均可安装openpyxl。openpyxl官网:https://openpyxl.readthedocs.org/en/latest/安装命令:
pip install openpyxl (在线安装)或者 easy_install openpyxl 即可。
2.使用openpyxl读xlsx加载workbook,注意,openpyxl只支持xlsx格式,老版的xls格式需要其他方法去加载。
wb = load_workbook(filename = r'tj.xlsx') 获取每个sheet的名称
sheetnames = wb.get_sheet_names() 获得第一个sheet
ws = wb.get_sheet_by_name(sheetnames[0])
获取一个单元格的数据
c = ws['A4']或者
c = ws.cell('A4') 或者
d = ws.cell(row = 4, column = 2) 一次获取多个单元格的数据
cell_range = ws['A1':'C2'] 或者
tuple(ws.iter_rows('A1:C2')) 或者
for row in ws.iter_rows('A1:C2'):
for cell in row:
print cell 或者
data_dic = []
for rx in range(0,ws.get_highest_row()):
temp_list = []
money = ws.cell(row = rx,column = 1).value
kind = ws.cell(row = rx,column = 2).value
temp_list = [money , kind]
#print temp_list
data_dic.append(temp_list)
for l in data_dic:
print l[0],l[1]
3.写入xlsx比如数据存在上边定义的data_dic中
out_filename = r'result.xlsx'
outwb = Workbook()
ew = ExcelWriter(workbook = outwb)
ws = outwb.worksheets[0]
ws.title = "res"
i=1
for data_l in data_dic:
for x in range(0,len(data_l)):
#col = get_column_letter(x)
ws.cell(column = x+1 , row = i , value = "%s" % data_l[x])
i+=1
ew.save(filename = out_filename) 再增加一个sheet写内容
ws2 = outwb.create_sheet(title = 's2')
for data_l in data_dic:
for x in range(0,len(data_l)):
ws2.cell(column = x+1 , row = i , value = "%s" % data_l[x])
i+=1
ew.save(filename = out_filename) 4.中文编码问题表格中的值,openpyxl会自动转换为不同的类型,有些表格中会有中文出现,就需要进行相应的转码。可以写一个函数专门处理转码,需要时调用
def gbk2utf(in_data , tag):
if 1 == tag:
return in_data.encode('gbk').decode('gbk')
elif 0 == tag:
return in_data.encode('gbk').decode('gbk').encode('utf8') 当原始的excel文件是gbk编码时,就需要tag=0的方式去处理,
因为读入后是gbk的编码,需要先encode为gbk再decode为unicode,再encode为utf8,就可以显示了。
【实战】
介绍下自己需要处理的表格情况,这是一个关于酬金的表格,每月都有,它的格式都是固定的,所以完全可以利用Python写一个脚本,来实现自己的需求,这样一来,每月只需敲击一个命令行,就能生成自己想要的表格,节约不少时间!~因为酬金分为很多大项,大项中又有很多小项,而我要做的就是把大项中的小项进行金额汇总,然后在写入一个新的表格,表格中是每个大项汇总的数据,以此生成我们需要进行绘图的数据。
这里直接粘贴源代码,因为可能涉及敏感信息,故有XXXX出现以代替原始注释,图片还有马赛克出现:
from openpyxl import Workbook
from openpyxl import load_workbook
wb = load_workbook("C:/Users/Administrator/Desktop/酬金.xlsx")
ws = wb.get_sheet_by_name('酬金明细')
ws_rows_len = len(ws.rows) #行数
ws_columns_len = len(ws.columns) #列数
#xxxxxxx
shop_name_column = 5
#xxxxx
user_start = 8
user_end = 23
#xxxxx
terminal_start = 24
terminal_end = 35
#xxxxx
infomation_start = 36
infomation_end = 42
#xxxx
group_start = 43
group_end = 45
#xxxx
commission_start = 46
commission_end = 60
#xxxx
stimulate_start = 61
stimulate_end = 65
#xxxx
net_start = 66
net_end = 67
#xxxxxxx
agreement_start = 68
agreement_end = 70
#数据有效行从第四行开始
start_row = 4
temp_data = []
for row in range(start_row, ws_rows_len+1):
t = 0
temp_data.append(ws.cell(row=row,column=shop_name_column).value)
#计算xxxxxx总金额
for column in range(user_start,user_end+1):
t += ws.cell(row=row,column=column).value
temp_data.append(t)
t = 0
#计算xxxx总金额
for column in range(terminal_start,terminal_end+1):
t += ws.cell(row=row,column=column).value
temp_data.append(t)
t = 0
#计算xxxx发展总金额
for column in range(infomation_start,infomation_end+1):
t += ws.cell(row=row,column=column).value
temp_data.append(t)
t = 0
#计算xxxx总金额
for column in range(group_start,group_end+1):
t += ws.cell(row=row,column=column).value
temp_data.append(t)
t = 0
#计算xxxxx总金额
for column in range(commission_start,commission_end+1):
t += ws.cell(row=row,column=column).value
temp_data.append(t)
t = 0
#计算xxxxx总金额
for column in range(stimulate_start,stimulate_end+1):
t += ws.cell(row=row,column=column).value
temp_data.append(t)
t = 0
#计算xxxxx总金额
for column in range(net_start,net_end+1):
t += ws.cell(row=row,column=column).value
temp_data.append(t)
t = 0
#计算xxxxxxxx总金额
for column in range(agreement_start,agreement_end+1):
t += ws.cell(row=row,column=column).value
temp_data.append(t)
#以上代码为获取酬金原始数据进行汇总
#下面将汇总得到的数据插入到一个新的数据表中
reward_ws_hearder = ['xxxx','xxxxx','xxxx','xxxxx','xxxxxx','xxxx','xxxx','xxxx','xxxx']
reward_ws = wb.create_sheet(title='酬金分析')
reward_ws.append(reward_ws_hearder)
start_list = 0
list_step = 9
end_list = start_list + list_step
for i in range(0,ws_rows_len-start_row+1):
reward_ws.append(temp_data[start_list:end_list])
start_list += list_step
end_list = start_list + list_step
wb.save("C:/Users/Administrator/Desktop/酬金1.xlsx") #另存为另一个表,防止意外破坏原始数据。
代码写得有点乱,仅供学习openpyxl参考。通过上述的代码,实现了一个新表存放了汇总的数据(原始数据有很多列,现在汇总到一起了) 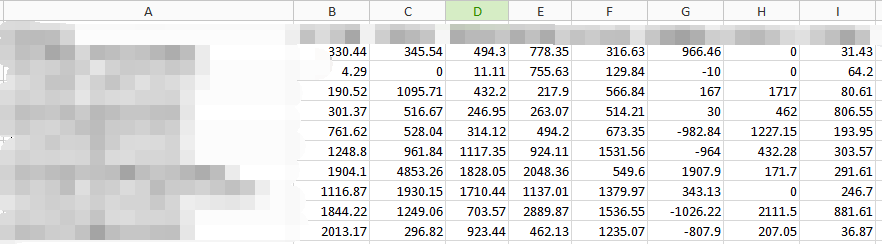
被马赛克涂抹的左边A列是名称,首行则是业务列别。可见数据则是汇总金额。如果我不用脚本处理的话,每次利用excel进行手动操作,那么需要对每个大项的小项进行汇总,然后用手动粘贴到一个新表中(自己的EXCEL不是很熟,然后对每一行都要进行一个绘图操作,算下来花的时间很多哦)而现在,只是花了时间写了一段代码,然后以后的以后,只要表格格式不变,我只需要运行py文件即可!~花的时间就1s吧。
下篇会介绍xlsxwriter这个库,因为我写到这里的时候想用openpyxl来进行绘图,发现openpyxl实现不了自己的需求,于是找到了这个写数据和画图都很强的xlsxwriter!而且文档也更加完善,有很多例子!!!
通过这次这个例子,自己以后也会更加学习如何善于发现,善于思考,如何运用自己以前所学的知识将它运用新的岗位上。
----------------------------------------------------------------------------------------------------------------------------------------------------------------
【附录】
openpyxl库学习
1、wb = Workbook()
2、获取sheet工作区间
1)# 激活worksheet,得到一个worksheet,默认得到sheet1 ws = wb.active
2)#命名sisilast格式,插入到最后 ws2 = wb.create_sheet("sisilast")
3)#命名sisilast格式,插入到最开始的位置 ws3 = wb.create_sheet("sisifrist",0)
3、给指定单元格赋值
1)直接写数据到指定的单元格中
>>>ws['A1'] = 100
2)使用openpyxl.worksheet.Worksheet.cell()方法操作某行某列的某个值:
>>> ws.cell(row=6,column=5,value='kaixin')
注意:
- 当worksheet在内存中被创建时,是没有包含cells的,cells是在首次访问时创建.
- 可以循环在内存中创建cells,这时不指定他们的值也会创建该cells些:(创建8x8cells)
>>> for i in range(1,9):
for j in range(1,9):
ws.cell(row=i,column=j,value=i*j)
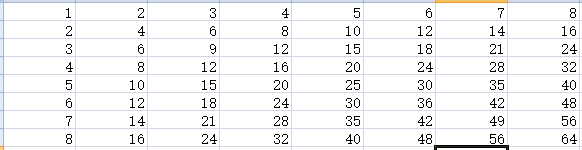
3.也可以使用 openpyxl.worksheet.Worksheet.iter_rows() 方法:(需要指定行->行,截止列)

4.也可以使用 openpyxl.worksheet.Worksheet.iter_cols() 方法:(需要指定列->列,截止行)
5.如果你需要遍历所有文件的行或列,可以使用openpyxl.worksheet.Worksheet.rows() 属性:>>>tuple(ws.rows)
or openpyxl.worksheet.Worksheet.columns() 属性:>>>tuple(ws.columns)
4、# 附加一行,从第一列开始附加 ws.append([1,2,3])
5、#保存文件到指定位置 wb.save("D:/test/test.xlsx")
6、修改sheet名称
创建的sheet的名称会自动创建,按照sheet,sheet1,sheet2自动增长,通过title属性可以修改其名称。
>>> from openpyxl import Workbook
>>> wb = Workbook()>>> ws = wb.create_sheet("haha")>>> ws.title = "heihei">>> wb.save("D:/test/heihei.xlsx")
7、查看workbook中的所有worksheets名称:openpyxl.workbook.Workbook.get_sheet_names()
>>> print(wb.sheetnames)['Sheet', 'heihei']
8、直接访问单元格
>>> value1 = ws['A3']
9、openpyxl.load_workbook()已经存在的workbook:

10、使用公式
![]()
--------------------------------------------------------------------------------------
【openpyxl的基本使用教程】
python操作excel方法
1)自身有Win32 COM操作office但讲不清楚,可能不支持夸平台,linux是否能用不清楚,其他有专业处理模块,如下
2)xlrd:(读excel)表,xlrd读大表效率高于openpyxl
3)xlwt:(写excel)表,
xlrd和xlwt对版本上兼容不太好,很多新版excel有问题。
新版excel处理:
openpyxl(可读写excel表)专门处理Excel2007及以上版本产生的xlsx文件,xls和xlsx之间转换容易
注意:如果文字编码是“gb2312” 读取后就会显示乱码,请先转成Unicode
安装openpyxl
1)下载openpyxl模块:https://pypi.python.org/pypi/openpyxl
2)解压到指定文件目录:tar -xzvf openpyxl.tar.gz
3)进入目录,找到setup.py文件,执行命令:python setup.py install
如果报错No module named setuptools 就使用命令“easy_install openpyxl”,easy_install for win32,会自动安装setuptools。
这里注意,如果不能自动安装,基本上python的模块都通过命令 python 模块名.py install 来安装,如果setuptools模块没有,直接去官网下载,然后前面命令安装就可以了
4)处理图片还需要安装pillow(PIL)
To be able to include images (jpeg, png, bmp,...) into an openpyxl file, you will also need the “pillow” library that can be installed with:
pip install pillow
pthon学习资料
python 学习小组http://www.thinksaas.cn/group/show/368/page/4
官网:
https://pypi.python.org/pypi/openpyxl
http://openpyxl.readthedocs.io/en/default/
good:
http://blog.csdn.net/suofiya2008/article/details/6284208
http://blog.csdn.net/zzukun/article/details/49946147
http://www.thinksaas.cn/topics/0/501/501962.html
openpyxl的使用
openpyxl定义多种数据格式
最重要的三种:
NULL空值:对应于python中的None,表示这个cell里面没有数据。
numberic: 数字型,统一按照浮点数来进行处理。对应于python中的float。
string: 字符串型,对应于python中的unicode。
Excel文件三个对象
workbook: 工作簿,一个excel文件包含多个sheet。
sheet:工作表,一个workbook有多个,表名识别,如“sheet1”,“sheet2”等。
cell: 单元格,存储数据对象
1)导入
from openpyxl import Workbook
from openpyxl import load_workbook
from openpyxl.styles import PatternFill, Border, Side, Alignment, Protection, Font, Color, Fill
from openpyxl.styles import colors
from openpyxl.styles import Fill,fills
from openpyxl.formatting.rule import ColorScaleRule
2)打开workbook:
wb = load_workbook('file_name.xlsx')
3)open sheet:
通过名字
ws = wb["frequency"]
等同于 ws2 = wb.get_sheet_by_name('frequency')
验证命令ws is ws2 is ws3 输出True
不知道名字用index
sheet_names = wb.get_sheet_names()
ws = wb.get_sheet_by_name(sheet_names[index])# index为0为第一张表
或者
ws =wb.active
等同于 ws = wb.get_active_sheet() #通过_active_sheet_index设定读取的表,默认0读第一个表
活动表表名wb.get_active_sheet().title
4)建新表
ws1 = wb.create_sheet() #默认插在最后
ws2 = wb.create_sheet(0) #插在开头
建表后默认名按顺序,如sheet1,sheet2...
ws.title = "New Title" #修改表名称
简化 ws2 = wb.create_sheet(title="Pi")
5)backgroud color of tab( be white by default)
ws.sheet_properties.tabColor = "1072BA" # set with RRGGBB color code
6)单元格使用
c = ws['A4'] #read 等同于 c = ws.cell('A4')
ws['A4'] = 4 #write
#ws.cell有两种方式,行号列号从1开始
d = ws.cell(row = 4, column = 2) #行列读写
d = ws.cell('A4')
写入cell值
ws.cell(row = 4, column = 2).value = 'test'
ws.cell(row = 4, column = 2, value = 'test')
7)访问多个单元格
cell_range = ws['A1':'C2']
读所有单元格数据
get_cell_collection()
8) 按行操作,按列操作
a)逐行读
ws.iter_rows(range_string=None, row_offset=0, column_offset=0): range-string(string)-单元格的范围:例如('A1:C4') row_offset-添加行 column_offset-添加列
返回一个生成器, 注意取值时要用value,例如:
for row in ws.iter_rows('A1:C2'):
for cell in row:
print cell
读指定行、指定列:
rows=ws.rows#row是可迭代的
columns=ws.columns#column是可迭代的
打印第n行数据
print rows[n]#不需要用.value
print columns[n]#不需要用.value
b)逐行写
(http://openpyxl.readthedocs.io/en/default/_modules/openpyxl/worksheet/worksheet.html#Worksheet.append)
ws.append(iterable)
添加一行到当前sheet的最底部 iterable必须是list,tuple,dict,range,generator类型的。 1,如果是list,将list从头到尾顺序添加。 2,如果是dict,按照相应的键添加相应的键值。
append([‘This is A1’, ‘This is B1’, ‘This is C1’])
append({‘A’ : ‘This is A1’, ‘C’ : ‘This is C1’})
append({1 : ‘This is A1’, 3 : ‘This is C1’})
8) #显示有多少张表
wb.get_sheet_names()
#显示表名,表行数,表列数
print ws.title
print ws.max_row
print ws.max_column
ws.get_highest_row() #UserWarning: Call to deprecated function
ws.get_highest_column()# UserWarning: Call to deprecated function
9) 获得列号x的字母 col = get_column_letter(x), x从1开始
from openpyxl.utils import get_column_letter
for x in range( 1, len(record)+ 1 ):
col = get_column_letter(x)
ws.cell( '%s%s' %(col, i)).value = x
通过列字母获取多个excel数据块
cell_range = "E3:{0}28".format(get_column_letter(bc_col))
ws["A1"] = "=SUM(%s)"%cell_range
10)excel文件是gbk编码,读入时需要先encode为gbk,再decode为unicode,再encode为utf8
cell_value.encode('gbk').decode('gbk').encode('utf8')
11) 公式计算formulae
ws["A1"] = "=SUM(1, 1)"
ws["A1"] = "=SUM(B1:C1)"
代码实例实例(直接修改使用)
from openpyxl import Workbook
from openpyxl.compat import range
from openpyxl.cell import get_column_letter
dest_filename = 'empty_book.xlsx'
wb = Workbook()
ws1 = wb.active
ws1.title = "range names"
for row in range(1, 40):
ws1.append(range(600))
ws3 = wb.create_sheet(title="Data")
for row in range(10, 20):
for col in range(27, 54):
_ = ws3.cell(column=col, row=row, value="%s" % get_column_letter(col))
print(ws3['AA10'].value)
wb.save(filename = dest_filename)
sheet_ranges = wb['range names']
print(sheet_ranges['D18'].value)
ws['A1'] = datetime.datetime(2010, 7, 21)
ws['A1'].number_format #输出'yyyy-mm-dd h:mm:ss'
rows = [
['Number', 'Batch 1', 'Batch 2'],
[2, 40, 30],
[3, 40, 25],
[4, 50, 30],
[5, 30, 10],
[6, 25, 5],
[7, 50, 10],
]
rows = [
['Date', 'Batch 1', 'Batch 2', 'Batch 3'],
[date(2015,9, 1), 40, 30, 25],
[date(2015,9, 2), 40, 25, 30],
[date(2015,9, 3), 50, 30, 45],
[date(2015,9, 4), 30, 25, 40],
[date(2015,9, 5), 25, 35, 30],
[date(2015,9, 6), 20, 40, 35],
]
for row in rows:
ws.append(row)
excel中图片的处理,PIL模块
try: from openpyxl.drawing import image import PIL except ImportError, e: print "[ERROR]",e report_file = self.excel_path + "/frquency_report_%d.xlsx" %id shutil.copyfile(configs.PATTEN_FILE, report_file) if not os.path.exists(report_file): print "generate file failed: ", report_file sys.exit(1) wb = load_workbook(report_file) ws = wb.get_sheet_by_name('frequency') img_f = configs.IMAGE_LOGO if os.path.exists(img_f): try: img = image.Image(img_f) ws.add_image(img, 'A1') except Exception, e: print "[ERROR]%s:%s" % (type(e), e) ws['A1'] = "程序化营销平台" else: ws['A1'] = "程序化营销平台" font1 = Font(size=22) ws['A1'].font = font1 ws['B4'] = ad_plan #等同ws.cell('B4') = ad_plan ws['B5'] = ad_names ws['B6'] = str(start_d) + ' to ' + str(end_d) wb.save(report_file) try: wb = load_workbook(report_file) ws = wb.get_sheet_by_name('frequency') row = 9 for it in query_result: one_row = it.split('\t') print one_row if '10' == one_row[0]: one_row[0] = '10+' col = 1 for one_cell in one_row: ws.cell(row = row, column = col).value = one_cell col = col + 1 row = row + 1 except Thrift.TException, tx: print '[ERROR] %s' % (tx.message) else: wb.save(report_file) finally: pass
http://www.python-excel.org/(后的页面,直接贴出来,主要是可以用Python来操作excel表格的一系列工具家族。)
Working with Excel Files in Python
| This site contains pointers to the best information available about working with Excel files in the Python programming language.
The PackagesThere are python packages available to work with Excel files that will run on any Python platform and that do not require either Windows or Excel to be used. They are fast, reliable and open source: openpyxlThe recommended package for reading and writing Excel 2010 files (ie: .xlsx)
Download | Documentation | Bitbucket xlsxwriterAn alternative package for writing data, formatting information and, in particular, charts in the Excel 2010 format (ie: .xlsx) Download | Documentation | GitHubxlrdThis package is for reading data and formatting information from older Excel files (ie: .xls)
Download | Documentation | GitHub xlwtThis package is for writing data and formatting information to older Excel files (ie: .xls)
Download | Documentation | Examples | GitHub xlutilsThis package collects utilities that require both xlrd and xlwt, including the ability to copy and modify or filter existing excel files. NB: In general, these use cases are now covered by openpyxl!
Download | Documentation | GitHub |
如果觉得本文的文章写得很好,打个赏,多少都行~~~
