经过一晚上的BUG作战,烧香之后,目前好像大功告成,先上图
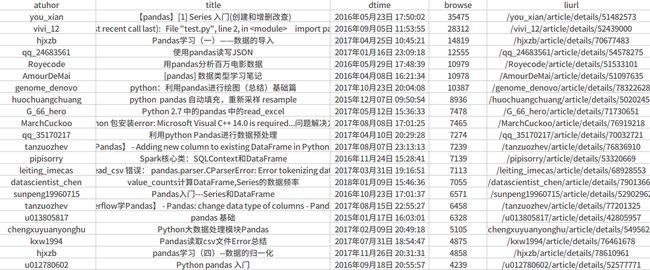
只爬了24页
代码重写了,之前的错误出现在18页和23页。BeautifulSoup,解析之后,遇到 """,这个字符,导致无法定位需要的信息
三个""",代码解析出错了,所以重写了
----JSON数据 obj=""" {"name":"Wes", "places_
首先感谢CSDN上面的各位大神的无私奉献,每当不懂的时候,百度出来的结果,好多都是CSDN上面的博客帮我解决的,收集到的文章将用于学习pandas分析。首先看搜索结果的链接
https://so.csdn.net/so/search/s.do?p=23&q=pandas&t=blog&domain=&o=&s=&u=&l=&f=&rbg=0,p=23是页数,q=pandas这是关键字,t=blog,就是搜索博客的意思,其他的没有进行分析,用这几个就够了。
def get_wen_list(keyword, page):
rooturl = 'https://so.csdn.net/so/search/s.do?'
key = 'q=%s' % (keyword)
result_pool = []
for pnum in range(0, page):
search_url = rooturl + 'p=%d&' % (pnum) + key + '&t=blog&domain=&o=&s=&u=&l=&f=&rbg=0'
print('开始爬第%d页链接' % pnum, search_url)
seget = requests.get(search_url)
Soup = BeautifulSoup(seget.text, 'lxml')
search_list = Soup.find_all(attrs={"class": "search-list-con"})
tilte_list = search_list.find_all(href=re.compile("https://blog.csdn.net"))
print() //以上的几句是一开始用beautifuSoup,发现问题,后来直接用正则,才有下面的语句
detail_list = re.findall('''/w+/article/details/[1-9][0-9]{7,}''', seget.text)
流程是:先按页数get,博文的列表,从中正则匹配出 作者的文章链接,文章链接如下
https://blog.csdn.net(这里不变) /chenzhenzhu2011/article/details/44183605 (要匹配的内容)
if detail_list: (获得当页所有的list后,因为有重复,需要去重)
new_pool = []
new_pool = list(set(detail_list))
print(new_pool)
for detail_url in new_pool:
get_detail = requests.get("https://blog.csdn.net" + detail_url)
Soup = BeautifulSoup(get_detail.text, 'lxml')
title = Soup.find(attrs = {"class" : "title-article" }).get_text()
dtime = Soup.find(attrs = {"class" : "time"}).get_text()
browse = Soup.find(attrs = {"class" : "read-count"}).get_text()
author = detail_url.split("/", 2)
tmp = [author[1], title, dtime, browse, detail_url]
result_pool.append(tmp)
print(tmp)
获得 ['作者' , '题目', '日期', '阅读数', '链接'],返回列表,之后写入CSV文件。
get_pool = get_wen_list(keyword, page)
copy_csv = open('pool.csv', 'a+', newline='')
fieldnames = ['atuhor', 'title', 'dtime', 'browse', 'liurl']
wr_pool = csv.writer(copy_csv)
wr_pool.writerow(fieldnames)
for pool in get_pool:
wr_pool.writerow(pool)
print("dWrite a total of %s bar data " % len(get_pool))
copy_csv.close()
下一步计划爬文章的内容,学习下大神走过的路