苹果曝光无人车新进展,这名华人工程师是主要贡献者

苹果进军自动驾驶汽车的传闻由来已久,最新的传闻是苹果已经搁置了整车研发的计划,转而开发自动驾驶汽车的软件平台。最近,也有不少路人在苹果总部附近看到过苹果的雷克萨斯路测车。
近日,向来以保密闻名的苹果发表在arXiv上的一篇论文又泄露了其无人车项目的最新进展。这篇论文的主题是“VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection”,作者为Yin Zhou(领英资料显示,Yin Zhou本科毕业于北京交通大学,2015年加入苹果,现任苹果高级AI 研究员)和Oncel Tuzel,其主要贡献在于:
-
提出了一种基于点云的三维检测的新型端到端可训练深度架构VoxelNet,它可直接在稀疏3D点上操作,避免了手动特征工程带来的信息瓶颈。
-
提出了一种有效的方法来实现VoxelNet,它可以从三维像素网格上的稀疏点结构和高效的并行处理中受益。
-
进行了KITTI基准测试,结果显示VoxelNet在基于LiDAR的汽车、行人和骑车者的检测基准方面达到了最领先的水平。
以下是论文的简要翻译:

摘要
精确检测三维点云(3D points cloud)中的物体是很多应用中的核心问题,如自主导航、家务机器人、AR/VR等。为了将高度稀疏的LiDAR点云与区域生成网络(Region Proposal Network,简称RPN)连接起来,大多数现有的方法都集中在手工特征表示上,例如鸟瞰图投影。在这项工作中,我们消除了对三维点云进行手动特征工程的需求,并提出了一个通用的3D检测网络VoxelNet,它将特征提取和边界框预测统一到一个single stage的端到端可训练深度网络中。具体而言,VoxelNet将点云划分为等间距的三维像素,并通过新引入的VFE(三维像素特征编码)层将每个三维像素内的一组点转换为统一的特征表示。
通过这种方法,点云被编码为描述性的体积表征,然后连接到RPN以生成检测结果。基于KITTI汽车检测基准的实验表明,VoxelNet大大超越了目前最先进的基于LiDAR的3D检测方法。此外,我们的网络还学习到了针对不同几何形状的对象的有效判别表征,使得我们在仅基于LiDAR数据的行人和骑车者的3D检测工作方面取得了令人鼓舞的结果。
VoxelNet架构
特征学习网络将原始点云作为输入,将空间划分为三维像素,并且将每个三维像素内的点变换为表征形状信息的矢量表示。该空间被表示为稀疏4D张量;卷积中间层负责处理4D张量,用以聚合空间信息(spatial context);最后,RPN生成3D检测结果。
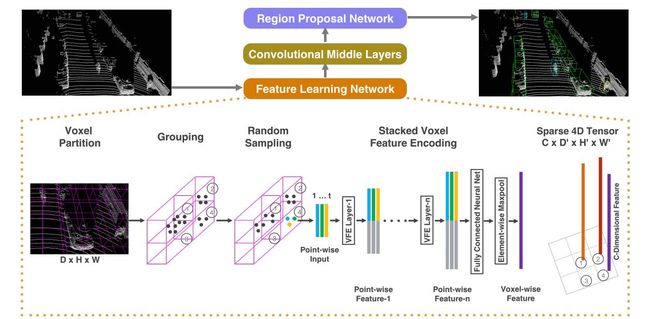
VoxelNet架构图
VoxelNet由三个功能模块组成:(1)特征学习网络,(2)卷积中间层,以及(3)区域生成网络RPN。

RPN结构图
GPU对处理密集张量结构进行了优化。直接使用点云的问题在于,点在空间上是稀疏分布的,每个三维像素都有不同数量的点。我们设计了一种将点云转换为密集张量结构的方法,其中堆叠的VFE操作可以在点和三维像素上并行处理。

有效实施
实验
我们在KITTI 3D物体检测基准上评估了VoxelNet,其中包含7,481个训练图像/点云和7,518个测试图像/点云,覆盖了三类对象:汽车,行人和骑车者。 对于每个类别,根据三个难度级别评估检测结果:简单、中等和困难,难度级别是根据对象大小、遮挡状态和截断级别确定的。
KITTI验证集评估
度量标准:我们遵循官方的KITTI评测协议,其中汽车这一类别的IoU阈值为0.7,行人和骑车者这一类别IoU阈值为0.5。鸟瞰(bird’s eye view)和全3D评测中IoU阈值都是一样的。我们使用了 AP (average precision)作为度量标准来比较各种不同的方法。
鸟瞰图评测结果如表一所示,在所有三个难度级别上,VoxelNet的表现始终优于其他方法。

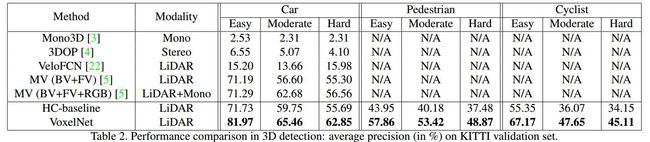
与鸟瞰视图检测相比,3D检测更具挑战性,因为它需要3D空间中形状的更精细定位。表2总结了3D检测结果。对于汽车这一类别,在所有三个难度级别上,VoxelNet的表现明显优于其他方法。
由于3D姿态和形状的高度变化,成功探测行人和骑车者这两个类别需要更好的3D形状表征。 如表2所示,对于更具挑战性的3D检测任务,VoxelNet的改进性能得到了强化(鸟瞰图提高8%,3D检测提高约12%),这表明VoxelNet在捕获3D形状信息方面比手工制作更有效。
KITTI测试集评估
评测结果如表三所示。VoxelNet在所有任务(鸟瞰图和3D检测)以及所有难度级别方面明显优于先前发表的最先进的方法。我们想要指出的是,KITTI基准测试中列出的其他许多领先方法都使用RGB图像和LiDAR点云,而VoxelNet仅仅使用LiDAR。

我们在下图中给出几个3D检测示例。为了更直观,我们将使用LiDAR检测到的3D盒投射到RGB图像上。如图所示,VoxelNet在所有类别中都能提供高度精确的三维边界框。

结论
大多数现有的基于LiDAR的3D检测方法都依赖于手工特征表示,例如鸟瞰图投影。在本文中,我们消除了手工特征工程的瓶颈,并提出了VoxelNet,这是一种新颖的基于点云的3D检测端到端可训练深度架构。我们的方法可以直接在稀疏3D点上操作,并有效地捕捉3D形状信息。我们还介绍了一个VoxelNet的高效实现的方法,它可以同时从点云稀疏性和三维像素网格上的并行处理中受益。
我们进行了KITTI汽车检测任务。实验表明,VoxelNet大大超越了其他基于LiDAR的3D检测方法。在更具挑战性的任务中,例如行人和骑车者的3D检测,VoxelNet也展示了令人鼓舞的结果,这说明VoxelNet能够提取更好的3D表征。
原文链接:https://arxiv.org/abs/1711.06396
热文精选
深度学习高手该怎样炼成?这位拿下阿里天池大赛冠军的中科院博士为你规划了一份专业成长路径
专访图灵奖得主John Hopcroft:中国必须提升本科教育水平,才能在AI领域赶上美国
双十一剁手后,听蒋涛谈谈AI人才多么吸金:2018年社招AI人才平均月薪竟高达4万,算法红利期还有2年
一文看懂科大讯飞2017年表现:刷新八项国际比赛记录,囊括四大消费场景,推出十大重点产品
何恺明包揽2项ICCV 2017最佳论文奖!这位高考状元告诉你什么是开挂的人生
2017年首份中美数据科学对比报告,Python受欢迎度排名第一,美国数据工作者年薪中位数高达11万美金
