网页爬虫之页面解析
前言
With the rapid development of the Internet,越来越多的信息充斥着各大网络平台。正如《死亡笔记》中L·Lawliet这一角色所提到的大数定律,在众多繁杂的数据中必然存在着某种规律,偶然中必然包含着某种必然的发生。不管是我们提到的大数定律,还是最近火热的大数据亦或其他领域都离不开大量而又干净数据的支持,为此,网络爬虫能够满足我们的需求,即在互联网上按照我们的意愿来爬取我们任何想要得到的信息,以便我们分析出其中的必然规律,进而做出正确的决策。同样,在我们平时上网的过程中,无时无刻可见爬虫的影子,比如我们广为熟知的“度娘”就是其中一个大型而又名副其实的“蜘蛛王”(SPIDER KING)。而要想写出一个强大的爬虫程序,则离不开熟练的对各种网络页面的解析,这篇文章将给读者介绍如何在Python中使用各大解析工具。
内容扼要
常用的解析方式主要有正则、Beautiful Soup、XPath、pyquery,本文主要是讲解后三种工具的使用,而对正则表达式的使用不做讲解,对正则有兴趣了解的读者可以跳转:正则表达式
- Beautiful Soup的使用
- XPath的使用
- pyquery的使用
- Beautiful Soup、XPath、pyquery解析腾讯招聘网案例
Beautiful Soup
Beautiful Soup是Python爬虫中针对HTML、XML的其中一个解析工具,熟练的使用之可以很方便的提取页面中我们想要的数据。此外,在Beautiful Soup中,为我们提供了以下四种解析器:
- 标准库,
soup = BeautifulSoup(content, "html.parser") - lxml解析器,
soup = BeautifulSoup(content, "lxml") - xml解析器,
soup = BeautifulSoup(content, "xml") - html5lib解析器,
soup = BeautifulSoup(content, "html5lib")
在以上四种解析库中,lxml解析具有解析速度快兼容错能力强的merits,所以本文主要使用的是lxml解析器,下面我们主要拿百度首页的html来具体讲解下Beautiful Soup的使用:
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
response = requests.get("https://www.baidu.com")
encoding = response.apparent_encoding
response.encoding = encoding
print(BeautifulSoup(response.text, "lxml"))
代码解读:
response = requests.get("https://www.baidu.com"),requests请求百度链接encoding = response.apparent_encoding,获取页面编码格式response.encoding = encoding,修改请求编码为页面对应的编码格式,以避免乱码print(BeautifulSoup(response.text, "lxml")),使用lxml解析器来对百度首页html进行解析并打印结果
打印后的结果如下所示:
<html> <head><meta content="text/html;charset=utf-8" http-equiv="content-type"/><meta content="IE=Edge" http-equiv="X-UA-Compatible"/><meta content="always" name="referrer"/><link href="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css" rel="stylesheet" type="text/css"/><title>百度一下,你就知道title>head> <body link="#0000cc"> <div id="wrapper"> <div id="head"> <div class="head_wrapper"> <div class="s_form"> <div class="s_form_wrapper"> <div id="lg"> <img height="129" hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" width="270"/> div> <form action="//www.baidu.com/s" class="fm" id="form" name="f"> <input name="bdorz_come" type="hidden" value="1"/> <input name="ie" type="hidden" value="utf-8"/> <input name="f" type="hidden" value="8"/> <input name="rsv_bp" type="hidden" value="1"/> <input name="rsv_idx" type="hidden" value="1"/> <input name="tn" type="hidden" value="baidu"/><span class="bg s_ipt_wr"><input autocomplete="off" autofocus="autofocus" class="s_ipt" id="kw" maxlength="255" name="wd" value=""/>span><span class="bg s_btn_wr"><input autofocus="" class="bg s_btn" id="su" type="submit" value="百度一下"/>span> form> div> div> <div id="u1"> <a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻a> <a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123a> <a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图a> <a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频a> <a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧a> <noscript> <a class="lb" href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1" name="tj_login">登录a> noscript> <script>document.write('+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录');
script> <a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">更多产品a> div> div> div> <div id="ftCon"> <div id="ftConw"> <p id="lh"> <a href="http://home.baidu.com">关于百度a> <a href="http://ir.baidu.com">About Baidua> p> <p id="cp">©2017 Baidu <a href="http://www.baidu.com/duty/">使用百度前必读a> <a class="cp-feedback" href="http://jianyi.baidu.com/">意见反馈a> 京ICP证030173号 <img src="//www.baidu.com/img/gs.gif"/> p> div> div> div> body> html>
从上述代码中,我们可以看见打印出的内容有点过于杂乱无章,为了使得解析后的页面清洗直观,我们可以使用prettify()方法来对其进行标准的缩进操作,为了方便讲解,博主对结果进行适当的删除,只留下有价值的内容,源码及输出如下:
bd_soup = BeautifulSoup(response.text, "lxml")
print(bd_soup.prettify())
<html>
<head>
<title>
百度一下,你就知道
title>
head>
<body link="#0000cc">
<div id="wrapper">
<div id="head">
<div class="head_wrapper">
<div class="s_form">
<div class="s_form_wrapper">
<div id="lg">
<img height="129" hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" width="270"/>
div>
div>
div>
<div id="u1">
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">
新闻
a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">
hao123
a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">
地图
a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">
视频
a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">
贴吧
a>
<a class="bri" href="//www.baidu.com/more/" name="tj_briicon" style="display: block;">
更多产品
a>
div>
div>
div>
<div id="ftCon">
<div id="ftConw">
<p id="lh">
<a href="http://home.baidu.com">
关于百度
a>
<a href="http://ir.baidu.com">
About Baidu
a>
p>
<p id="cp">
©2017 Baidu
<a href="http://www.baidu.com/duty/">
使用百度前必读
a>
<a class="cp-feedback" href="http://jianyi.baidu.com/">
意见反馈
a>
京ICP证030173号
<img src="//www.baidu.com/img/gs.gif"/>
p>
div>
div>
div>
body>
html>
节点选择
在Beautiful Soup中,我们可以很方便的选择想要得到的节点,只需要在bd_soup对象中使用.的方式即可,使用如下:
bd_title_bj = bd_soup.title
bd_title_bj_name = bd_soup.title.name
bd_title_name = bd_soup.title.string
bd_title_parent_bj_name = bd_soup.title.parent.name
bd_image_bj = bd_soup.img
bd_image_bj_dic = bd_soup.img.attrs
bd_image_all = bd_soup.find_all("img")
bd_image_idlg = bd_soup.find("div", id="lg")
代码解读:
bd_soup.title,正如前面所说,Beautiful Soup可以很简单的解析对应的页面,只需要使用bd_soup.的方式进行选择节点即可,该行代码正是获得百度首页html的title节点内容bd_soup.title.name,使用.name的形式即可获取节点的名称- bd_soup.title.string,使用
.string的形式即可获得节点当中的内容,这句代码就是获取百度首页的title节点的内容,即浏览器导航条中所显示的百度一下,你就知道 bd_soup.title.parent.name,使用.parent可以该节点的父节点,通俗地讲就是该节点所对应的上一层节点,然后使用.name获取父节点名称bd_soup.img,如bd_soup.title一样,该代码获取的是img节点,只不过需要注意的是:在上面html中我们可以看见总共有两个img节点,而如果使用.img的话默认是获取html中的第一个img节点,而不是所有bd_soup.img.attrs,获取img节点中所有的属性及属性内容,该代码输出的结果是一个键值对的字典格式,所以之后我们只需要通过字典的操作来获取属性所对应的内容即可。比如bd_soup.img.attrs.get("src")和bd_soup.img.attrs["src"]的方式来获取img节点所对应的src属性的内容,即图片链接bd_soup.find_all("img"),在上述中的.img操作默认只能获取第一个img节点,而要想获取html中所有的img节点,我们需要使用.find_all("img")方法,所返回的是一个列表格式,列表内容为所有的选择的节点bd_soup.find("div", id="lg"),在实际运用中,我们往往会选择指定的节点,这个时候我们可以使用.find()方法,里面可传入所需查找节点的属性,这里需要注意的是:在传入class属性的时候其中的写法是.find("div", class_="XXX")的方式。所以该行代码表示的是获取id属性为lg的div节点,此外,在上面的.find_all()同样可以使用该方法来获取指定属性所对应的所有节点
上述代码中解析的结果对应打印如下:
百度一下,你就知道
title
百度一下,你就知道
head
"129" hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" width="270"/>
{'hidefocus': 'true', 'src': '//www.baidu.com/img/bd_logo1.png', 'width': '270', 'height': '129'}
["129" hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" width="270"/>, /www.baidu.com/img/gs.gif"/>]
"lg" > "129" hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" width="270"/> 数据提取
在上一小节节点选择我们讲到了部分数据提取的方法,然而,Beautiful Soup的强大之处还不止步于此。接下来我们继续揭开其神秘的面纱。
.get_text()
获取对象中所有的内容:
all_content = bd_soup.get_text()
百度一下,你就知道 新闻 hao123 地图 视频 贴吧 登录 document.write('+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录');
更多产品 关于百度 About Baidu ©2017 Baidu 使用百度前必读 意见反馈 京ICP证030173号
.strings,.stripped_strings
print(type(bd_soup.strings))
#
.strings用于提取bd_soup对象中所有的内容,而从上面的输出结果我们可以看出.strings的类型是一个生成器,对此可以使用循环来提取出其中的内容。但是我们在使用.strings的过程中会发现提取出来的内容有很多的空格以及换行,对此我们可以使用.stripped_strings方法来解决该问题,用法如下:
for each in bd_soup.stripped_strings:
print(each)
输出结果:
百度一下,你就知道
新闻
hao123
地图
视频
贴吧
登录
更多产品
关于百度
About Baidu
©2017 Baidu
使用百度前必读
意见反馈
京ICP证030173号
.parent,.children,.parents
.parent可以选择该节点的父节点,.children可以选择该节点的孩子节点,.parents选择该节点所有的上层节店,返回的是生成器,各用法如下:
bd_div_bj = bd_soup.find("div", id="u1")
print(type(bd_div_bj.parent))
print("*" * 50)
for child in bd_div_bj.children:
print(child)
print("*" * 50)
for parent in bd_div_bj.parents:
print(parent.name)
结果输出:
<class 'bs4.element.Tag'>
**************************************************
<a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻a>
<a class="mnav" href="https://www.hao123.com" name="tj_trhao123">hao123a>
<a class="mnav" href="http://map.baidu.com" name="tj_trmap">地图a>
<a class="mnav" href="http://v.baidu.com" name="tj_trvideo">视频a>
<a class="mnav" href="http://tieba.baidu.com" name="tj_trtieba">贴吧a>
**************************************************
div
div
div
body
html
Beautiful Soup小结
Beautiful Soup主要的用法就是以上一些,还有其他一些操作在实际开发过程中使用的不多,这里不做过多的讲解了,所以整体来讲Beautiful Soup的使用还是比较简单的,其他一些操作可见官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#contents-children
XPath
XPath全称是XML Path Language,它既可以用来解析XML,也可以用来解析HTML。在上一部分已经讲解了Beautiful Soup的一些常见的骚操作,在这里,我们继续来看看XPath的使用,瞧一瞧XPath的功能到底有多么的强大以致于受到了不少开发者的青睐。同Beautiful Soup一样,在XPath中提供了非常简洁的节点选择的方法,Beautiful Soup主要是通过.的方式来进行子节点或者子孙节点的选择,而在XPath中则主要通过/的方式来选择节点。除此之外,在XPath中还提供了大量的内置函数来处理各个数据之间的匹配关系。
首先,我们先来看看XPath常见的节点匹配规则:
| 表达式 | 解释说明 |
|---|---|
/ |
在当前节点中选取直接子节点 |
// |
在当前节点中选取子孙节点 |
. |
选取当前节点 |
.. |
选取当前节点的父节点 |
@ |
指定属性(id、class……) |
下面我们继续拿上面的百度首页的HTML来讲解下XPath的使用。
节点选择
要想正常使用Xpath,我们首先需要正确导入对应的模块,在此我们一般使用的是lxml,操作示例如下:
from lxml import etree
import requests
import html
if __name__ == "__main__":
response = requests.get("https://www.baidu.com")
encoding = response.apparent_encoding
response.encoding = encoding
print(response.text)
bd_bj = etree.HTML(response.text)
bd_html = etree.tostring(bd_bj).decode("utf-8")
print(html.unescape(bd_html))
1~9行代码如Beautiful Soup一致,下面对之后的代码进行解释:
etree.HTML(response.text),使用etree模块中的HTML类来对百度html(response.text)进行初始化以构造XPath解析对象,返回的类型为etree.tostring(bd_html_elem).decode("utf-8"),将上述的对象转化为字符串类型且编码为utf-8html.unescape(bd_html),使用HTML5标准定义的规则将bd_html转换成对应的unicode字符。
打印出的结果如Beautiful Soup使用时一致,这里就不再显示了,不知道的读者可回翻。既然我们已经得到了Xpath可解析的对象(bd_bj),下面我们就需要针对这个对象来选择节点了,在上面我们也已经提到了,XPath主要是通过/的方式来提取节点,请看下面Xpath中节点选择的一些常见操作:
all_bj = bd_bj.xpath("//*") # 选取所有节点
img_bj = bd_bj.xpath("//img") # 选取指定名称的节点
p_a_zj_bj = bd_bj.xpath("//p/a") # 选取直接节点
p_a_all_bj = bd_bj.xpath("//p//a") # 选取所有节点
head_bj = bd_bj.xpath("//title/..") # 选取父节点
结果如下:
[0x14d6a6d1c88>, 0x14d6a6e4408>, 0x14d6a6e4448>, 0x14d6a6e4488>, 0x14d6a6e44c8>, 0x14d6a6e4548>, 0x14d6a6e4588>, 0x14d6a6e45c8>, 0x14d6a6e4608>, 0x14d6a6e4508>, 0x14d6a6e4648>, 0x14d6a6e4688>, ......]
[0x14d6a6e4748>, 0x14d6a6e4ec8>]
[0x14d6a6e4d88>, 0x14d6a6e4dc8>, 0x14d6a6e4e48>, 0x14d6a6e4e88>]
[0x14d6a6e4d88>, 0x14d6a6e4dc8>, 0x14d6a6e4e48>, 0x14d6a6e4e88>]
[0x14d6a6e4408>]
all_bj = bd_bj.xpath("//*"),使用//可以选择当前节点(html)下的所有子孙节点,且以一个列表的形式来返回,列表元素通过bd_bj一样是element对象,下面的返回类型一致img_bj = bd_bj.xpath("//img"),选取当前节点下指定名称的节点,这里建议与Beautiful Soup的使用相比较可增强记忆,Beautiful Soup是通过.find_all("img")的形式p_a_zj_bj = bd_bj.xpath("//p/a"),选取当前节点下的所有p节点下的直接子a节点,这里需要注意的是”直接“,如果a不是p节点的直接子节点则选取失败p_a_all_bj = bd_bj.xpath("//p//a"),选取当前节点下的所有p节点下的所有子孙a节点,这里需要注意的是”所有“,注意与上一个操作进行区分head_bj = bd_bj.xpath("//title/.."),选取当前节点下的title节点的父节点,即head节点
数据提取
在了解如何选择指定的节点之后,我们就需要提取节点中所包含的数据了,具体提取请看下面的示例:
img_href_ls = bd_bj.xpath("//img/@src")
img_href = bd_bj.xpath("//div[@id='lg']/img[@hidefocus='true']/@src")
a_content_ls = bd_bj.xpath("//a//text()")
a_news_content = bd_bj.xpath("//a[@class='mnav' and @name='tj_trnews']/text()")
输出结果:
['//www.baidu.com/img/bd_logo1.png', '//www.baidu.com/img/gs.gif']
['//www.baidu.com/img/bd_logo1.png']
['新闻', 'hao123', '地图', '视频', '贴吧', '登录', '更多产品', '关于百度', 'About Baidu', '使用百度前必读', '意见反馈']
['新闻']
img_href_ls = bd_bj.xpath("//img/@src"),该代码先选取了当前节点下的所有img节点,然后将所有img节点的src属性值选取出来,返回的是一个列表形式img_href = bd_bj.xpath("//div[@id='lg']/img[@hidefocus='true']/@src"),该代码首先选取了当前节点下所有id属性值为lg的div,然后继续选取div节点下的直接子img节点(hidefoucus=true),最后选取其中的src属性值a_content_ls = bd_bj.xpath("//a//text()"),选取当前节点所有的a节点的所遇文本内容a_news_content = bd_bj.xpath("//a[@class='mnav' and @name='tj_trnews']/text()"),多属性选择,在xpath中可以指定满足多个属性的节点,只需要and即可
提醒:读者在阅读的过程中注意将代码和输出的结果仔细对应起来,只要理解其中的意思也就不难记忆了。
XPath小结
耐心看完了XPath的使用方法之后,聪明的读者应该不难发现,其实Beautiful Soup和XPath的本质和思路上基本相同,只要我们在阅读XPath用法的同时在脑袋中不断的思考,相信聪明的你阅读至此已经能够基本掌握了XPath用法。
pyquery
对于pyquery,官方的解释如下:
pyquery allows you to make jquery queries on xml documents. The API is as much as possible the similar to jquery. pyquery uses lxml for fast xml and html manipulation.
This is not (or at least not yet) a library to produce or interact with javascript code. I just liked the jquery API and I missed it in python so I told myself “Hey let’s make jquery in python”. This is the result.
It can be used for many purposes, one idea that I might try in the future is to use it for templating with pure http templates that you modify using pyquery. I can also be used for web scrapping or for theming applications with Deliverance.
The project is being actively developped on a git repository on Github. I have the policy of giving push access to anyone who wants it and then to review what he does. So if you want to contribute just email me.
Please report bugs on the github issue tracker.
在网页解析过程中,除了强大的Beautiful Soup和XPath之外,还有qyquery的存在,qyquery同样受到了不少“蜘蛛”的欢迎,下面我们来介绍下qyquery的使用。
节点选择
与Beautiful Soup和XPath明显不同的是,在qyquery中,一般存在着三种解析方式,一种是requests请求链接之后把html进行传递,一种是将url直接进行传递,还有一种是直接传递本地html文件路径即可,读者在实际使用的过程中根据自己的习惯来编码即可,下面我们来看下这三种方式的表达:
import requests
from pyquery import PyQuery as pq
bd_html = requests.get("https://www.baidu.com").text
bd_url = "https://www.baidu.com"
bd_path = "./bd.html"
# 使用html参数进行传递
def way1(html):
return pq(html)
# 使用url参数进行传递
def way2(url):
return pq(url=url)
def way3(path):
return pq(filename=path)
print(type(way1(html=bd_html)))
print(type(way2(url=bd_url)))
print(type(way3(path=bd_path)))
#
#
#
从上面三种获得解析对象方法的代码中我们可以明显看见都可以得到一样的解析对象,接下来我们只要利用这个对象来对页面进行解析从而提取出我们想要得到的有效信息即可,在qyquery中一般使用的是CSS选择器来选取。下面我们仍然使用百度首页来讲解pyquery的使用,在这里我们假设解析对象为bd_bj。
response = requests.get("https://www.baidu.com")
response.encoding = "utf-8"
bd_bj = pq(response.text)
bd_title = bd_bj("title")
bd_img_ls = bd_bj("img")
bd_img_ls2 = bd_bj.find("img")
bd_mnav = bd_bj(".mnav")
bd_img = bd_bj("#u1 a")
bd_a_video = bd_bj("#u1 .mnav")
# 百度一下,你就知道
#
# ......
# 输出结果较长,读者可自行运行
正如上面代码所示,pyquery在进行节点提取的时候通常有三种方式,一种是直接提取出节点名即可提取出整个节点,当然这种方式你也可以使用find方法,这种提取节点的方式是不加任何属性限定的,所以提取出的节点往往会含有多个,所以我们可以使用循环.items()来进行操作;一种是提取出含有特定class属性的节点,这种形式采用的是.+class属性值;还有一种是提取含有特定id属性的节点,这种形式采用的是#+id属性值。熟悉CSS的读者应该不难理解以上提取节点的方法,正是在CSS中提取节点然后对其进行样式操作的方法。上述三种方式您也可以像提取bd_a_video一样混合使用
数据提取
在实际解析网页的过程中,三种解析方式基本上大同小异,为了读者认识pyquery的数据提取的操作以及博主日后的查阅,在这里简单的介绍下
img_src1 = bd_bj("img").attr("src") # //www.baidu.com/img/bd_logo1.png
img_src2 = bd_bj("img").attr.src # //www.baidu.com/img/bd_logo1.png
for each in bd_bj.find("img").items():
print(each.attr("src"))
print(bd_bj("title").text()) # 百度一下,你就知道
如上一二行代码所示,提取节点属性我们可以有两种方式,这里拿src属性来进行说明,一种是.attr("src"),另外一种是.attr.src,读者根据自己的习惯来操作即可,这里需要注意的是:在节点提取小结中我们说了在不限制属性的情况下是提取出所有满足条件的节点,所以在这种情况下提取出的属性是第一个节点属性。要想提取所有的节点的属性,我们可以如四五行代码那样使用.items()然后进行遍历,最后和之前一样提取各个节点属性即可。qyquery提取节点中文本内容如第七行代码那样直接使用.text()即可。
pyquery小结
pyquery解析如Beautiful Soup和XPath思想一致,所以这了只是简单的介绍了下,想要进一步了解的读者可查阅官方文档在加之熟练操作即可。
腾讯招聘网解析实战
通过上述对Beautiful Soup、XPath以及pyquery的介绍,认真阅读过的读者想必已经有了一定的基础,下面我们通过一个简单的实战案例来强化一下三种解析方式的操作。此次解析的网站为腾讯招聘网,网址url:https://hr.tencent.com/,其社会招聘网首页如下所示: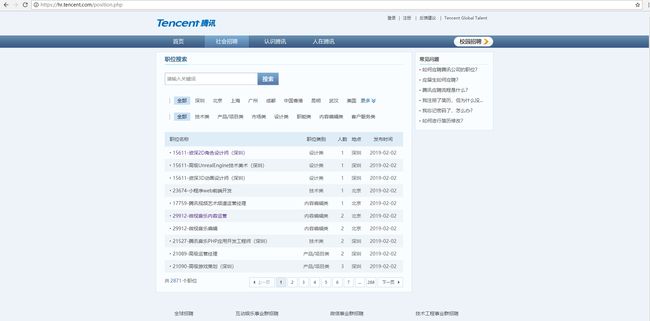
此次我们的任务就是分别利用上述三种解析工具来接下该网站下的社会招聘中的所有数据。
网页分析:
通过该网站的社会招聘的首页,我们可以发现如下三条主要信息:
- 首页url连接为https://hr.tencent.com/position.php
- 一共有288页的数据,每页10个职位,总职位共计2871
- 数据字段有五个,分别为:职位名称、职位类别、招聘人数、工作地点、职位发布时间
既然我们解析的是该网站下所有职位数据,再者我们停留在第一页也没有发现其他有价值的信息,不如进入第二页看看,这时我们可以发现网站的url链接有了一个比较明显的变化,即原链接在用户端提交了一个start参数,此时链接为https://hr.tencent.com/position.php?&start=10#a,陆续打开后面的页面我们不难发现其规律:每一页提交的start参数以10位公差进行逐步递增。之后,我们使用谷歌开发者工具来审查该网页,我们可以发现全站皆为静态页面,这位我们解析省下了不少麻烦,我们需要的数据就静态的放置在table标签内,如下所示: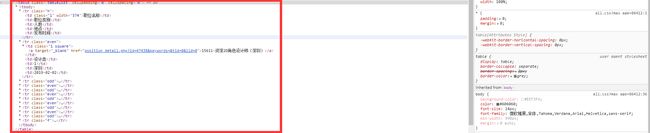
下面我们具体来分别使用以上三种工具来解析该站所有职位数据。
案例源码
import requests
from bs4 import BeautifulSoup
from lxml import etree
from pyquery import PyQuery as pq
import itertools
import pandas as pd
class TencentPosition():
"""
功能: 定义初始变量
参数:
start: 起始数据
"""
def __init__(self, start):
self.url = "https://hr.tencent.com/position.php?&start={}#a".format(start)
self.headers = {
"Host": "hr.tencent.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
}
self.file_path = "./TencentPosition.csv"
"""
功能: 请求目标页面
参数:
url: 目标链接
headers: 请求头
返回:
html,页面源码
"""
def get_page(self, url, headers):
res = requests.get(url, headers=headers)
try:
if res.status_code == 200:
return res.text
else:
return self.get_page(url, headers=headers)
except RequestException as e:
return self.get_page(url, headers=headers)
"""
功能: Beautiful Soup解析页面
参数:
html: 请求页面源码
"""
def soup_analysis(self, html):
soup = BeautifulSoup(html, "lxml")
tr_list = soup.find("table", class_="tablelist").find_all("tr")
for tr in tr_list[1:-1]:
position_info = [td_data for td_data in tr.stripped_strings]
self.settle_data(position_info=position_info)
"""
功能: xpath解析页面
参数:
html: 请求页面源码
"""
def xpath_analysis(self, html):
result = etree.HTML(html)
tr_list = result.xpath("//table[@class='tablelist']//tr")
for tr in tr_list[1:-1]:
position_info = tr.xpath("./td//text()")
self.settle_data(position_info=position_info)
"""
功能: pyquery解析页面
参数:
html: 请求页面源码
"""
def pyquery_analysis(self, html):
result = pq(html)
tr_list = result.find(".tablelist").find("tr")
for tr in itertools.islice(tr_list.items(), 1, 11):
position_info = [td.text() for td in tr.find("td").items()]
self.settle_data(position_info=position_info)
"""
功能: 职位数据整合
参数:
position_info: 字段数据列表
"""
def settle_data(self, position_info):
position_data = {
"职位名称": position_info[0].replace("\xa0", " "), # replace替换\xa0字符防止转码error
"职位类别": position_info[1],
"招聘人数": position_info[2],
"工作地点": position_info[3],
"发布时间": position_info[-1],
}
print(position_data)
self.save_data(self.file_path, position_data)
"""
功能: 数据保存
参数:
file_path: 文件保存路径
position_data: 职位数据
"""
def save_data(self, file_path, position_data):
df = pd.DataFrame([position_data])
try:
df.to_csv(file_path, header=False, index=False, mode="a+", encoding="gbk") # 数据转码并换行存储
except:
pass
if __name__ == "__main__":
for page, index in enumerate(range(287)):
print("正在爬取第{}页的职位数据:".format(page+1))
tp = TencentPosition(start=(index*10))
tp_html = tp.get_page(url=tp.url, headers=tp.headers)
tp.pyquery_analysis(html=tp_html)
print("\n")
部分结果如下: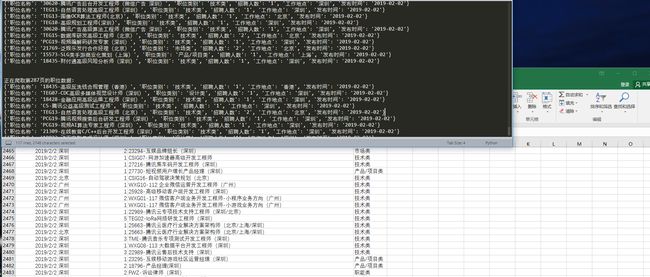
总结
在本篇文章中,首先我们分别介绍了Beautiful Soup、XPath、pyquery的常见操作,之后通过使用该三种解析工具来爬取腾讯招聘网中所有的职位招聘数据,从而进一步让读者有一个更加深刻的认识。该案例中,由于本篇文章重点在于网站页面的解析方法,所以未使用多线程、多进程,爬取所有的数据爬取的时间在两分钟左右,在之后的文章中有时间的话会再次介绍多线程多进程的使用,案例中的解析方式都已介绍过,所以读者阅读源码即可。
注意:本文章中所有的内容皆为在实际开发中常见的一些操作,并非所有,想要进一步提升等级的读者务必请阅读官方文档。