1.简介
Amazon Rekognition是提供图像和视频分析服务的Amazon Web Service(AWS)。 您可以提供图像或视频,该服务将检测物体,人物和场景。 检测到的面部也可以与一组已知面部进行匹配。 这允许实现用例,例如用户验证,人数统计或公共安全。
该服务基于亚马逊的深度学习技术,该技术也在其他服务中使用。 要使用该服务,不需要有关基础技术的知识,只需简单地调用现有的API并处理调用的结果即可。
目录
- 1.简介
- 2.基础知识
- 3.项目设置
- 4.图像操作
-
- 4.1。 检测标签
- 4.2。 检测人脸
- 4.3。 比较面Kong
- 5.馆藏
-
- 5.1。 创建收藏
- 5.2。 列出收藏
- 5.3。 删除收藏
- 5.4。 描述集合
- 5.5。 索引面
- 5.6。 搜索面Kong
- 6.视频操作
-
- 6.1。 准备工作
- 6.2。 检测标签
- 6.3。 追踪人员
- 7.下载源代码
有两种不同的API集:一种用于分析图像,另一种用于视频分析。 两者都可以执行应用程序可以使用的对象检测和识别。 例如,您可以开发一个应用程序,使用户可以通过脸部或某些对象搜索他们的照片集。 因此,您可以让您的应用程序将图像或视频数据发送到Amazon Rekognition,并让其返回有关上传资料的元数据。 您的应用程序使用此元数据管理数据库,并允许用户在其中进行搜索。
通过视频API,您可以跟踪存储的视频中或来自实时摄像机的视频流中的人。 这样,可以通知您是否在存储的视频中或在实况摄像机的前面检测到了已知人物。
2.基础知识
在开始之前,我们必须学习一些有关图像检测和识别的概念。
label可以引用图像或视频中的不同项目:
- 对象:花,树,桌子等
- 事件:婚礼,生日聚会等
- 概念:景观,傍晚,自然等
- 活动:下车等。
Amazon Rekognition具有专门的操作,可将所有检测到的标签返回到图像或视频上。
Rekognition服务还将返回其在图像或视频中检测到的脸部以及标志性信息(例如眼位和检测到的情绪)。 您可以将人员注册到集合中,并让Amazon在提交的图像上搜索这些人员。 后一个功能称为“面部搜索”。
在视频上,可以通过不同的帧跟踪一个人。 该服务提供有关检测的面部和框内位置的信息。
作为一项特殊功能,Amazon Rekognition还可以识别图像和视频中的数千名名人。 跟踪信息可以告诉您某个演员出现在电影的哪个部分。
一个有趣的选项是检测图像中的文本并将其转换为机器可读的文本。 这使您可以检测图像中的车牌号或开发可帮助残障人士识别餐厅中路牌或菜单卡的应用程序。
最后但并非最不重要的一点是,Amazon Rekognition Service还可以帮助检测图像和视频上的不安全内容,例如裸露,泳装或内衣。
图像分析的API是同步的,并且将JSON文档作为输入并返回JSON响应。 图像可以是Amazon S3存储桶中提供的jpeg或png文件,也可以是byte64编码的图像。
随着视频分析花费更多时间,视频API是异步的。 这意味着您通过通过Amazon S3存储桶提供视频来开始处理,后端通过向SNS主题发送消息将结果通知您。 Amazon SNS是一种消息服务,用于使用发布/订阅范式进行通知。
如果您想分析流式视频内容,则视频是通过Amazon Kinesis提供的,后端通过必须实现的流处理器通知您有关识别的信息。
要搜索面部,您必须创建一个包含要检测的面部的集合。 由于这些面Kong存储在Amazon Rekognition服务中,因此对这些集合的操作也称为“存储操作”。 与这些“存储操作”相反,可以在不将任何信息存储在Amazon服务器上的情况下调用“非存储操作”。 这些“非存储操作”包括检测标签和面部,识别名人或检测文本的操作。
“存储操作”将有关检测到的面部的信息存储在Amazon Rekognition服务中。 此信息也称为模板。 由深度学习算法的特定版本计算出的模板可能与新版本不兼容。 因此,必须使用新版本的算法使用相同的图像数据再次计算模板。 正如亚马逊所说,“模型版本”与带有面Kong的集合有关。 由于无法选择将现有集合升级到新的“模型版本”,因此必须创建一个新集合(针对新的“模型版本”)并再次添加所有图像。 否则,随着时间的推移,您可能会遇到兼容性问题。
3.项目设置
在本教程中,我们将使用Java作为编程语言,并使用maven作为构建工具。 我们将创建一个小示例应用程序,以演示Amazon Rekognition的基本功能。
它要求您已安装Java> = 1.8和Maven> = 3.0。
第一步,我们将在命令行上创建一个简单的maven项目:
mvn archetype:generate -DgroupId=com.javacodegeeks.aws -DartifactId=rekognition -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false此命令将在文件系统中创建以下结构:
|-- src
| |-- main
| | `-- java
| | `-- com
| | `-- javacodegeeks
| | `-- aws
| `-- test
| | `-- java
| | `-- com
| | `-- javacodegeeks
| | `-- aws
`-- pom.xml pom.xml定义了我们将用作依赖项的库:
1.11.401
com.amazonaws
aws-java-sdk-rekognition
${aws.version}
com.amazonaws
aws-java-sdk-core
${aws.version}
工件aws-java-sdk-rekognition包含用于Amazon Rekognition Web服务的即用型Java API,而工件aws-java-sdk-core包含一组较大的Amazon AWS开发工具包使用的代码。 由于aws-java-sdk-core是aws-java-sdk-rekognition的可传递依赖aws-java-sdk-rekognition ; 因此,您也可以忽略它,因为maven会自动获取它。
我们的Maven工件的结果应该是一个包含所有依赖项的jar文件,以便我们可以在命令行上轻松执行它。 因此,我们将maven-assembly-plugin添加到我们的构建中,并告诉它哪个类包含我们要执行的main()方法:
maven-assembly-plugin
com.javacodegeeks.aws.App
jar-with-dependencies
make-assembly
package
single
由于com.javacodegeeks.aws.App类是之前由maven原型插件创建的,因此我们现在可以构建模块:
mvn clean package成功构建之后,我们可以通过以下方式启动应用程序:
java -jar target\rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar现在,我们拥有一个运行中的构建,我们必须创建一个Amazon AWS账户。 因此,打开https://aws.amazon.com/ ,选择“创建一个AWS账户”并按照说明进行操作。 在此注册过程中,您将收到一个电话,并使用电话的键盘输入PIN。
一旦可以访问您的AWS账户,就应该创建一个有权访问Amazon Rekognition API的用户。 例如, 在此说明如何执行此操作。
在这两个步骤的最后,您应该拥有一个带ID和密钥的AWS访问密钥。 这些凭证可以存储在本地系统上的AWS凭证配置文件中:
- 在Linux,macOS或Unix上:〜/ .aws / credentials
- 在Windows上:C:\ Users \ USERNAME \ .aws \ credentials(其中USERNAME是您的用户名)
该文件包含以下几行:
aws_access_key_id =
aws_secret_access_key =用您的帐户的实际值替换右侧的占位符。
此外,您还可以在AWS配置文件中设置要使用的默认AWS区域:
- 在Linux,macOS或Unix上:〜/ .aws / config
- 在Windows上:C:\ Users \ USERNAME \ .aws \ config(其中USERNAME是您的用户名)
配置文件具有以下内容:
region =在右侧的占位符替换为您的AWS区域(例如us-east-1或eu-west-1)。
4.图像操作
在本章中,我们将仔细研究可用的图像操作。
4.1检测标签
首先,我们让Amazon Rekognition在提供的图像上检测标签。
因此,我们通过一些简单的代码通过main()方法扩展了App类,这些代码通过命令行参数调用我们的新类DetectLabels :
public class App {
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Please provide at least one argument.");
return;
}
switch (args[0]) {
case "detect-labels":
DetectLabels detectLabels = new DetectLabels();
detectLabels.run(args);
break;
default:
System.err.println("Unknown argument: " + args[0]);
return;
}
}
} 在下一步中,我们创建一个简单的工厂类来实例化AmazonRekognition对象。 此实例提供对Amazon Rekognition的所有API方法的访问:
public class ClientFactory {
public static AmazonRekognition createClient() {
ClientConfiguration clientConfig = new ClientConfiguration();
clientConfig.setConnectionTimeout(30000);
clientConfig.setRequestTimeout(60000);
clientConfig.setProtocol(Protocol.HTTPS);
AWSCredentialsProvider credentialsProvider = new ProfileCredentialsProvider();
return AmazonRekognitionClientBuilder
.standard()
.withClientConfiguration(clientConfig)
.withCredentials(credentialsProvider)
.withRegion("eu-west-1")
.build();
}
} Amazon AWS开发工具包使用构建器模式来创建合适的配置。 方法standard()将所有选项初始化为默认值。 之后,我们提供特定的客户端配置。 这应该演示如何调整例如连接超时和请求超时。 除此之外,我们还将HTTPS设置为传输协议。 可以为客户端设置许多其他选项。
正如我们之前创建的credentials文件一样,我们可以使用ProfileCredentialsProvider将AWS凭证传递给应用程序。 这将使代码检查credentials文件并从那里获取凭据。
由于我们已将此信息存储在config文件中,因此可以省略代码中的区域。 在这里,它仅显示我们使用构建器API可以完全控制所有选项。
在实现代码以创建Amazon Rekognition客户端之后,我们可以进一步了解如何检测提供的图像上的标签:
public class DetectLabels {
public void run(String[] args) {
if (args.length < 2) {
System.err.println("Please provide an image.");
return;
}
String imgPath = args[1];
byte[] bytes;
try {
bytes = Files.readAllBytes(Paths.get(imgPath));
} catch (IOException e) {
System.err.println("Failed to load image: " + e.getMessage());
return;
}
ByteBuffer byteBuffer = ByteBuffer.wrap(bytes);
AmazonRekognition rekognition = ClientFactory.createClient();
DetectLabelsRequest request = new DetectLabelsRequest()
.withImage(new Image().withBytes(byteBuffer))
.withMaxLabels(10);
DetectLabelsResult result = rekognition.detectLabels(request);
List labels = result.getLabels();
for (Label label : labels) {
System.out.println(label.getName() + ": " + label.getConfidence());
}
}
}
我们传递给run()方法的String数组填充有命令行中的参数。 第一个参数用于调用上面的DetectLabels类(请参阅App类); 因此,我们可以使用第二个参数来提供图像。 然后使用两个参数调用该应用程序:
java -jar target/rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar detect-labels img/work.jpg 当第一行检查命令行参数是否存在时,接下来的几行将图像文件的内容读入byte数组,并将其包装到ByteBuffer 。 然后是时候为Amazon Rekognition API创建客户端和DetectLabelsRequest实例了。 该请求对象填充有字节缓冲区和不返回超过10个标签的指令。 最后,此请求将传递到客户端的detectLabels()方法,并且返回的标签将打印在控制台上。
我们正在使用以下示例图像:
输出将查找示例图像,如下所示:
Human: 99.18134
People: 99.18133
Person: 99.18134
Computer: 74.21879
Electronics: 74.21879
Laptop: 74.21879
Pc: 74.21879
Art: 71.1518
Modern Art: 71.1518
Afro Hairstyle: 70.530525我们可以看到,Amazon Rekognition确保图像上有人类,有电脑/笔记本电脑和现代艺术品。 它甚至检测到图像左上方的“非洲发型”。
如果愿意,您现在可以扩展应用程序并将这些标签存储在数据库中,并让用户搜索它们。 对于较大的图像集合,您将有一种简单的方法,不仅可以根据图像中的文件名和元数据,还可以根据其内容为图像建立索引。
4.2检测人脸
Amazon Rekognition不仅可以检测标签,而且可以检测人脸。 在本节中,我们将更详细地探讨此功能。
首先,通过在命令行上接受另一个参数来扩展主类App :
case "detect-faces":
DetectFaces detectFaces = new DetectFaces();
detectFaces.run(args);
break; 新类DetectFaces的方法run(String[])如下所示:
public void run(String[] args) {
if (args.length < 2) {
System.err.println("Please provide an image.");
return;
}
String imgPath = args[1];
byte[] bytes;
try {
bytes = Files.readAllBytes(Paths.get(imgPath));
} catch (IOException e) {
System.err.println("Failed to load image: " + e.getMessage());
return;
}
ByteBuffer byteBuffer = ByteBuffer.wrap(bytes);
AmazonRekognition rekognition = ClientFactory.createClient();
DetectFacesRequest request = new DetectFacesRequest()
.withImage(new Image().withBytes(byteBuffer))
.withAttributes(Attribute.ALL);
DetectFacesResult result = rekognition.detectFaces(request);
String orientationCorrection = result.getOrientationCorrection();
System.out.println("Orientation correction: " + orientationCorrection);
List faceDetails = result.getFaceDetails();
for (FaceDetail faceDetail : faceDetails) {
printFaceDetails(faceDetail);
}
}它从第二个命令行参数中提取图像的文件名,并将所有字节读入数组。 这样,可以通过以下方式调用应用程序:
java -jar target/rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar detect-faces img/work.jpg 方法printFaceDetails()输出有关面部检测的所有可用信息:
private void printFaceDetails(FaceDetail faceDetail) {
System.out.println("###############");
AgeRange ageRange = faceDetail.getAgeRange();
System.out.println("Age range: " + ageRange.getLow() + "-" + ageRange.getHigh());
Beard beard = faceDetail.getBeard();
System.out.println("Beard: " + beard.getValue() + "; confidence=" + beard.getConfidence());
BoundingBox bb = faceDetail.getBoundingBox();
System.out.println("BoundingBox: left=" + bb.getLeft() +
", top=" + bb.getTop() + ", width=" + bb.getWidth() +
", height=" + bb.getHeight());
Float confidence = faceDetail.getConfidence();
System.out.println("Confidence: " + confidence);
List emotions = faceDetail.getEmotions();
for (Emotion emotion : emotions) {
System.out.println("Emotion: " + emotion.getType() +
"; confidence=" + emotion.getConfidence());
}
Eyeglasses eyeglasses = faceDetail.getEyeglasses();
System.out.println("Eyeglasses: " + eyeglasses.getValue() +
"; confidence=" + eyeglasses.getConfidence());
EyeOpen eyesOpen = faceDetail.getEyesOpen();
System.out.println("EyeOpen: " + eyesOpen.getValue() +
"; confidence=" + eyesOpen.getConfidence());
Gender gender = faceDetail.getGender();
System.out.println("Gender: " + gender.getValue() +
"; confidence=" + gender.getConfidence());
List landmarks = faceDetail.getLandmarks();
for (Landmark lm : landmarks) {
System.out.println("Landmark: " + lm.getType()
+ ", x=" + lm.getX() + "; y=" + lm.getY());
}
MouthOpen mouthOpen = faceDetail.getMouthOpen();
System.out.println("MouthOpen: " + mouthOpen.getValue() +
"; confidence=" + mouthOpen.getConfidence());
Mustache mustache = faceDetail.getMustache();
System.out.println("Mustache: " + mustache.getValue() +
"; confidence=" + mustache.getConfidence());
Pose pose = faceDetail.getPose();
System.out.println("Pose: pitch=" + pose.getPitch() +
"; roll=" + pose.getRoll() + "; yaw" + pose.getYaw());
ImageQuality quality = faceDetail.getQuality();
System.out.println("Quality: brightness=" +
quality.getBrightness() + "; sharpness=" + quality.getSharpness());
Smile smile = faceDetail.getSmile();
System.out.println("Smile: " + smile.getValue() +
"; confidence=" + smile.getConfidence());
Sunglasses sunglasses = faceDetail.getSunglasses();
System.out.println("Sunglasses=" + sunglasses.getValue() +
"; confidence=" + sunglasses.getConfidence());
System.out.println("###############");
}该信息包括:
- 边界框::包围脸部的框。
- 置信度::盒子包含一张脸的置信度。
- 面部界标::界标列表,每个界标(例如左眼,右眼和嘴巴)描述x和y坐标。
- 面部属性::描述面部的其他属性(例如性别,胡须等)。 对于大多数属性,置信度值指示Amazon Rekognition对该属性的确信程度。
- 质量::脸部的亮度和清晰度。
- 姿势::姿势描述图像内部人脸的旋转。
- 情绪::一组检测到的情绪。
上面的示例代码使用withAttributes()方法告诉Amazon Rekognition返回所有可用的面部属性。 如果省略此参数,则该服务将仅返回BoundingBox,
信心,姿势,品质和地标。
还请注意方向校正的输出。 如果此值不为null ,则指示是否需要旋转图像。 在这种情况下,您不仅需要旋转图像本身,而且还必须旋转返回的边界框和地标。 如果该值为null ,则必须从其Exif元数据中提取图片的方向。 Amazon Rekognition在内部评估此值,但不会通过API返回它。
将示例代码与上面最后一部分中的示例图像一起运行将产生以下结果(缩短):
Orientation correction: ROTATE_0
###############
Age range: 35-52
Beard: false; confidence=63.299633
BoundingBox: left=0.67542213, top=0.503125, width=0.16322702, height=0.10875
Confidence: 99.99996
Emotion: HAPPY; confidence=33.592426
Emotion: CONFUSED; confidence=3.7694752
Emotion: ANGRY; confidence=3.3934474
Eyeglasses: false; confidence=99.92778
EyeOpen: true; confidence=99.999115
Gender: Male; confidence=99.92852
Landmark: eyeLeft, x=0.72928935; y=0.54335195
Landmark: eyeRight, x=0.77855927; y=0.5483551
Landmark: nose, x=0.7247987; y=0.56508356
Landmark: mouthLeft, x=0.72980136; y=0.58450377
Landmark: mouthRight, x=0.7671486; y=0.58911216
Landmark: leftPupil, x=0.73123896; y=0.54353833
Landmark: rightPupil, x=0.78261787; y=0.54776514
Landmark: leftEyeBrowLeft, x=0.71933734; y=0.53303427
Landmark: leftEyeBrowUp, x=0.7256926; y=0.5320847
Landmark: leftEyeBrowRight, x=0.7333774; y=0.5329594
Landmark: rightEyeBrowLeft, x=0.76563233; y=0.53686714
Landmark: rightEyeBrowUp, x=0.78357726; y=0.5374825
Landmark: rightEyeBrowRight, x=0.7988768; y=0.5429575
Landmark: leftEyeLeft, x=0.7218825; y=0.54265666
Landmark: leftEyeRight, x=0.7381058; y=0.54474115
Landmark: leftEyeUp, x=0.7287737; y=0.5410849
Landmark: leftEyeDown, x=0.7291001; y=0.54527205
Landmark: rightEyeLeft, x=0.77009064; y=0.5488282
Landmark: rightEyeRight, x=0.7880702; y=0.54891306
Landmark: rightEyeUp, x=0.778157; y=0.5459737
Landmark: rightEyeDown, x=0.7784402; y=0.55022097
Landmark: noseLeft, x=0.73085135; y=0.5707799
Landmark: noseRight, x=0.74700916; y=0.57319427
Landmark: mouthUp, x=0.7397919; y=0.58404857
Landmark: mouthDown, x=0.74021983; y=0.5951085
MouthOpen: false; confidence=91.05297
Mustache: false; confidence=95.113785
Pose: pitch=1.6241417; roll=11.053664; yaw-40.602734
Quality: brightness=49.62646; sharpness=99.93052
Smile: true; confidence=87.8063
Sunglasses=false; confidence=99.95385
###############
###############
Age range: 26-43
Beard: true; confidence=98.0061
BoundingBox: left=0.12851782, top=0.47375, width=0.23170732, height=0.154375
Confidence: 99.99996
[...]我们可以看到,Amazon Rekognition服务检测到两张脸,一张留着胡须,一张没有胡须。 在这两种情况下,服务都非常确定它已检测到边界框内的人脸。 第一个检测是图像中心的人。 亚马逊的算法认为这个人很高兴,但是对此并不确定。 它检测到该人的眼睛张开,该人没有眼镜,并且是年龄在35-52岁之间的男性。 人的嘴没有张开,也没有胡须或墨镜。 但是,此人笑容约为87.8%。
在具有更多细节和人物的图像上,有时不清楚哪个检测属于哪张脸。 因此,在图像上绘制边框是有意义的。
如前所述,我们必须考虑图像的方向,并在必要时旋转边界框。 相应的代码如下所示:
private BoundingBox convertBoundingBox(BoundingBox bb, String orientationCorrection, int width, int height) {
if (orientationCorrection == null) {
System.out.println("No orientationCorrection available.");
return null;
} else {
float left = -1;
float top = -1;
switch (orientationCorrection) {
case "ROTATE_0":
left = width * bb.getLeft();
top = height * bb.getTop();
break;
case "ROTATE_90":
left = height * (1 - (bb.getTop() + bb.getHeight()));
top = width * bb.getLeft();
break;
case "ROTATE_180":
left = width - (width * (bb.getLeft() + bb.getWidth()));
top = height * (1 - (bb.getTop() + bb.getHeight()));
break;
case "ROTATE_270":
left = height * bb.getTop();
top = width * (1 - bb.getLeft() - bb.getWidth());
break;
default:
System.out.println("Orientation correction not supported: " +
orientationCorrection);
return null;
}
System.out.println("BoundingBox: left=" + (int)left + ", top=" +
(int)top + ", width=" + (int)(bb.getWidth()*width) +
", height=" + (int)(bb.getHeight()*height));
BoundingBox outBB = new BoundingBox();
outBB.setHeight(bb.getHeight()*height);
outBB.setWidth(bb.getWidth()*width);
outBB.setLeft(left);
outBB.setTop(top);
return outBB;
}
} 根据图像的方向,根据可用信息计算左坐标和上坐标。 此方法的返回值是一个新的BoundingBox ,它已经包含像素值而不是相对于图像的宽度和高度给出的相对浮点数。
转换后的BoundingBox允许我们使用Java SDK类ImageIO加载图像,并为每个边界框绘制一个红色矩形:
private void drawBoundingBoxes(byte[] bytes, DetectFacesResult result) {
int width;
int height;
BufferedImage img;
Graphics2D graphics;
try {
img = ImageIO.read(new ByteArrayInputStream(bytes));
width = img.getWidth();
height = img.getHeight();
graphics = img.createGraphics();
} catch (IOException e) {
System.err.println("Failed to read image: " + e.getLocalizedMessage());
return;
}
System.out.println("Image: width=" + width + ", height=" + height);
String orientationCorrection = result.getOrientationCorrection();
System.out.println("Orientation correction: " + orientationCorrection);
List faceDetails = result.getFaceDetails();
for (FaceDetail faceDetail : faceDetails) {
drawBoundingBox(faceDetail, orientationCorrection, width, height, graphics);
}
try {
ImageIO.write(img, "jpg", new File("img_bb.jpg"));
} catch (IOException e) {
System.err.println("Failed to write image: " + e.getLocalizedMessage());
}
}
private void drawBoundingBox(FaceDetail faceDetail, String orientationCorrection, int width, int height,
Graphics2D graphics) {
BoundingBox bb = faceDetail.getBoundingBox();
BoundingBox cbb = convertBoundingBox(bb, orientationCorrection, width, height);
if (cbb == null) {
return;
}
graphics.setColor(Color.RED);
graphics.setStroke(new BasicStroke(10));
graphics.drawRect(cbb.getLeft().intValue(), cbb.getTop().intValue(),
cbb.getWidth().intValue(), cbb.getHeight().intValue());
} ImageIO.read()方法将图像加载到BufferedImage ,可以使用相应的ImageIO.write()方法进行存储。 在这两者之间,我们创建了Graphics2D实例,该实例允许我们在缓冲的图像上绘制矩形。 该示例代码为每个转换后的边界框绘制一个厚度为10像素的红色矩形:

显然,我们可以看到两个边界框,并验证每个边界框都包含一个面。
4.3比较面Kong
API方法“比较面Kong”使我们能够检测第二张图片(称为目标图片)中第一张图片(称为源图片)给出的面Kong。 如果源图像不是仅包含一个图像的经典肖像,则Amazon Rekognition将使用最大的脸Kong。 该服务将在目标图像中返回此脸部的所有匹配项,以及指示该服务如何确定目标图像中的人是源图像中的人的相似度值。
为了扩展我们的应用程序,我们将以下代码添加到App类的switch语句中:
case "compare-faces":
CompareFaces compareFaces = new CompareFaces();
compareFaces.run(args);
break; 新的类CompareFaces如下所示:
public class CompareFaces {
public void run(String[] args) {
if (args.length < 3) {
System.err.println("Please provide two images: .");
return;
}
ByteBuffer image1 = loadImage(args[1]);
ByteBuffer image2 = loadImage(args[2]);
if (image1 == null || image2 == null) {
return;
}
CompareFacesRequest request = new CompareFacesRequest()
.withSourceImage(new Image().withBytes(image1))
.withTargetImage(new Image().withBytes(image2))
.withSimilarityThreshold(70F);
CompareFacesResult result = ClientFactory.createClient().compareFaces(request);
List boundingBoxes = new ArrayList<>();
List faceMatches = result.getFaceMatches();
for (CompareFacesMatch match : faceMatches) {
Float similarity = match.getSimilarity();
System.out.println("Similarity: " + similarity);
ComparedFace face = match.getFace();
BoundingBox bb = face.getBoundingBox();
boundingBoxes.add(bb);
}
BoundingBoxDrawer bbDrawer = new BoundingBoxDrawer();
bbDrawer.drawBoundingBoxes(image2.array(), result.getTargetImageOrientationCorrection(), boundingBoxes);
}
private ByteBuffer loadImage(String imgPath) {
byte[] bytes;
try {
bytes = Files.readAllBytes(Paths.get(imgPath));
} catch (IOException e) {
System.err.println("Failed to load image: " + e.getMessage());
return null;
}
return ByteBuffer.wrap(bytes);
}
} 我们希望用户提供两个图像:源图像和目标图像。 这两个图像均作为命令行参数提供,并使用loadImage()方法加载到ByteBuffer 。 在下一步中,代码创建一个CompareFacesRequest实例,并设置源图像和目标图像以及我们要使用的相似性阈值。 使用客户端的方法compareFaces()将该请求发送到Amazon Rekognition服务。
调用的结果是CompareFacesResult一个实例,该实例使用其方法getFaceMatches()传递潜在的匹配项。 对于每个匹配项,我们输出相似性并将边界框添加到列表中。 稍后将此列表提供给BoundingBoxDrawer实例,该实例基本上包含上一个示例中的重构代码,并在目标图像上绘制边界框并将其保存在当前工作目录中。
现在,我们可以使用两个图像编译并启动程序:
java -jar target\rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar compare-faces img\dinner2.jpg img\dinner3.jpg第一张图片是女人的画像:

第二张图片显示了女人和男人:

我们的示例应用程序输出以下信息:
Similarity: 96.0
Image: width=5760, height=3840
BoundingBox: left=2341, top=936, width=1076, height=1073Amazon的算法非常确定(96.0%),目标图像上的女人与源图像上的女人是同一个人。 目标图像上的边界框告诉我们算法将女人定位的位置:

5.馆藏
集合是Amazon Rekognition中管理面Kong的基本单位。 您可以创建一个或多个集合并将其存储在其中。 之后,您可以搜索特定集合以进行面部匹配。 这与“比较面部”操作不同,后者仅允许在目标图像的源图像中搜索面部。
您在特定的Amazon区域内创建一个集合,并且该集合与当前的面部检测模型相关联。
例如,当您想监视商店中的客户时,集合有用的用例。 为了将员工与客户分开,您可以创建一个名为“ staff”的集合,并为公司所有员工注册面部图像。 现在,您只需要查询集合,就可以知道检测到的人脸是属于工作人员还是顾客。 您还可以与不允许进入建筑物的人员一起创建第二个收藏集。 如果您的应用程序从此集合中检测到人脸,则警报会通知工作人员。
5.1创建收藏
使用集合的第一步当然是创建集合。 以下代码段扩展了App类中的switch语句:
case "create-collection":
CreateCollection cc = new CreateCollection();
cc.run(args);
break; 新的类CreateCollection看起来很简单:
public class CreateCollection {
public void run(String[] args) {
if (args.length < 2) {
System.err.println("Please provide a collection name.");
return;
}
String collectionName = args[1];
CreateCollectionRequest request = new CreateCollectionRequest()
.withCollectionId(collectionName);
AmazonRekognition rekognition = ClientFactory.createClient();
CreateCollectionResult result = rekognition.createCollection(request);
Integer statusCode = result.getStatusCode();
String collectionArn = result.getCollectionArn();
String faceModelVersion = result.getFaceModelVersion();
System.out.println("statusCode=" + statusCode + "\nARN="
+ collectionArn + "\nface model version=" + faceModelVersion);
}
} 我们希望将一个集合名称作为参数,并将其传递给CreateCollectionRequest的withCollectionId()方法。 随后,该请求将作为参数传递给AmazonRekognition客户端的方法createCollection() 。
客户端响应包含状态码,内部全局全局唯一的内部Amazon资源名称(ARN)和面部模型版本。
编译完类后,我们可以通过以下方式调用它:
java -jar target\rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar create-collection my-coll这将产生以下示例输出:
statusCode=200
ARN=aws:rekognition:eu-west-1:047390200627:collection/my-coll
face model version=3.0 显然,该操作成功完成,并为面部模型3.0版创建了一个名为my-coll的集合。
5.2列表集合
现在我们已经创建了第一个集合,现在该列出所有可用的集合了。
因此,我们在命令行参数评估器中添加了另一种情况:
case "list-collections":
ListCollections lc = new ListCollections();
lc.run(args);
break; 类ListCollections发送ListCollectionsRequest亚马逊Rekognition服务和打印所有返回的id:
public class ListCollections {
public void run(String[] args) {
ListCollectionsRequest request = new ListCollectionsRequest()
.withMaxResults(100);
AmazonRekognition rekognition = ClientFactory.createClient();
ListCollectionsResult result = rekognition.listCollections(request);
List collectionIds = result.getCollectionIds();
while (collectionIds != null) {
for (String id : collectionIds) {
System.out.println(id);
}
String token = result.getNextToken();
if (token != null) {
result = rekognition.listCollections(request.withNextToken(token));
} else {
collectionIds = null;
}
}
}
}由于结果列表可能很长,因此API提供了分页选项。 如果有进一步的收集可用,它将返回一个令牌。 下一个请求必须提交此令牌,并由此获得下一组收集标识符。
该类的编译版本可以通过以下方式执行:
java -jar target\rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar list-collections仅创建了一个集合,输出如下所示:
my-coll5.3删除收藏
最后,我们必须实现从Amazon Rekognition删除集合的功能。
与之前的两个步骤一样,我们扩展了App类:
case "delete-collection":
DeleteCollection dc = new DeleteCollection();
dc.run(args);
break; 新类DeleteCollection只需创建一个DeleteCollectionRequest ,其ID为要删除的集合,然后将其发送到后端:
public class DeleteCollection {
public void run(String[] args) {
if (args.length < 2) {
System.err.println("Please provide a collection name.");
return;
}
String collectionId = args[1];
DeleteCollectionRequest request = new DeleteCollectionRequest()
.withCollectionId(collectionId);
AmazonRekognition rekognition = ClientFactory.createClient();
DeleteCollectionResult result = rekognition.deleteCollection(request);
Integer statusCode = result.getStatusCode();
System.out.println("Status code: " + statusCode);
}
}使用现有集合的ID调用它会导致以下输出:
java -jar target\rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar delete-collection my-coll
Status code: 2005.4描述集合
在使用集合一段时间后,查询有关它的一些元数据会很有帮助。 因此,Amazon Rekognition API提供了“描述收集”方法。
对于实现,我们扩展App类:
case "describe-collection":
DescribeCollection descc = new DescribeCollection();
descc.run(args);
break; 新的类DescribeCollection看起来像:
public class DescribeCollection {
public void run(String[] args) {
if (args.length < 2) {
System.err.println("Please provide a collection name.");
return;
}
DescribeCollectionRequest request = new DescribeCollectionRequest()
.withCollectionId(args[1]);
AmazonRekognition rekognition = ClientFactory.createClient();
DescribeCollectionResult result = rekognition.describeCollection(request);
System.out.println("ARN: " + result.getCollectionARN()
+ "\nFace Model Version: " + result.getFaceModelVersion()
+ "\nFace Count: " + result.getFaceCount()
+ "\nCreated: " + result.getCreationTimestamp());
}
} DescribeCollectionRequest仅取集合的名称,而结果提供给我们ARN,人脸模型版本,人脸计数和创建时间戳记:
java -jar target\rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar describe-collection my-coll
ARN: arn:aws:rekognition:eu-west-1:047390200627:collection/my-coll
Face Model Version: 3.0
Face Count: 0
Created: Fri Sep 07 21:28:05 CEST 20185.5索引面
现在我们知道如何使用集合,是时候插入一些面Kong了。 相应的API方法称为“索引面”。
为了将人脸插入到集合中,我们需要提供带有人脸的图像,Amazon Rekognition会将所有检测到的人脸插入到集合中。 在大多数情况下,您只希望使用只有一个人的图像(例如,肖像),否则可能会无意间将其他人/脸插入到收藏集中。 如果您不确定图像,当然可以使用“检测面Kong”方法检查Amazon Rekognition将检测到多少张面Kong。
该服务将不存储您提供的图像。 它在内部创建有关检测到的脸部的数据结构,并将其存储在集合中。 当前无法直接访问此信息。 当您对集合执行搜索时,将间接使用它。 在这种情况下,Amazon Rekognition将尝试将提供的面部与集合中的所有面部进行匹配。 该服务当然会使用内部数据结构来执行此搜索,但是作为API的用户,您将无法与其联系。
如果要将集合中的匹配项与为索引此脸部而提供的图像相关联,则必须提供“外部标识符”。 在像我们这样的简单情况下,这可以是文件名,在更复杂的应用程序中,您可能必须跟踪Amazon Rekognition为每个检测到的脸部返回的脸部ID及其所在的图像。
第一步是扩展我们的主类:
case "index-faces":
IndexFaces indf = new IndexFaces();
indf.run(args);
break; IndexFaces类至少需要另外两个参数:一个检测到的脸部应该插入的集合以及至少一个图像:
public class IndexFaces {
public void run(String[] args) {
if (args.length < 3) {
System.err.println("Please provide a collection and images: ... ");
return;
}
AmazonRekognition rekognition = ClientFactory.createClient();
String collectionId = args[1];
for (int i = 2; i < args.length; i++) {
String imageArg = args[i];
Path path = Paths.get(imageArg);
ByteBuffer byteBuffer;
try {
byte[] bytes = Files.readAllBytes(path);
byteBuffer = ByteBuffer.wrap(bytes);
} catch (IOException e) {
System.err.println("Failed to read file '" + imageArg + "': " + e.getMessage());
continue;
}
IndexFacesRequest request = new IndexFacesRequest()
.withCollectionId(collectionId)
.withDetectionAttributes("ALL")
.withImage(new Image().withBytes(byteBuffer))
.withExternalImageId(path.getFileName().toString());
IndexFacesResult result = rekognition.indexFaces(request);
System.out.println("Indexed image '" + imageArg + "':");
List faceRecords = result.getFaceRecords();
for (FaceRecord rec : faceRecords) {
FaceDetail faceDetail = rec.getFaceDetail();
BoundingBox bb = faceDetail.getBoundingBox();
System.out.println("Bounding box: left=" + bb.getLeft() +
"; top=" + bb.getTop() +
"; width=" + bb.getWidth() +
"; height=" + bb.getHeight());
Face face = rec.getFace();
System.out.println("Face-ID: " + face.getFaceId() +
"\nImage ID: " + face.getImageId() +
"\nExternal Image ID: " + face.getExternalImageId() +
"\nConfidence: " + face.getConfidence());
}
}
}
} 对于每个提供的图像,将构造一个包含图像字节的ByteBuffer 。 该缓冲区传递给IndexFacesRequest的实例。 IndexFacesRequest还使用集合ID和外部图像ID来跟踪提供的图像,因为Amazon不会存储它。 此外,我们还告知服务应检测到所有属性。 如前所述,默认情况下,仅处理面Kong的基本属性。
响应包含一个面部记录列表。 每个记录都包含一个FaceDetail和Face实例。 我们已经从“ Detect Faces”调用中了解了FaceDetail类, Face类提供了一个内部人脸ID,一个内部图像ID,我们提供的外部图像ID以及一个置信度值。
运行以上代码以提供先前创建的集合和两个图像结果,结果如下:
>java -jar target\rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar index-faces my-coll img\dinner1.jpg img\dinner2.jpg
Indexed image 'img\dinner1.jpg':
Bounding box: left=0.35050505; top=0.12651515; width=0.18787879; height=0.28181818
Face-ID: 7c1f2f31-7d88-4bb3-98e4-040edfe3c60a
Image ID: e6dd5551-bd19-5377-94f4-db69730e7ba3
External Image ID: dinner1.jpg
Confidence: 99.99777
Indexed image 'img\dinner2.jpg':
Bounding box: left=0.45353535; top=0.09249432; width=0.3050505; height=0.45792267
Face-ID: 0c8f1a0f-e401-4caf-8a5f-ec06d175f486
Image ID: b1dd15e7-4d08-5489-a14b-dd0dc009143a
External Image ID: dinner2.jpg
Confidence: 99.999916Amazon Rekognition在提供的每张图像上检测到一张脸,并返回了脸ID,图像ID和外部ID(在我们的情况下为文件名)。 在这两种情况下,Amazon Rekognition都可以确定边界框包含一张脸。
现在,已经将这两张面Kong添加到集合my-coll ,我们可以使用“ describe-collection”命令进行验证:
>java -jar target\rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar describe-collection my-coll
ARN: arn:aws:rekognition:eu-west-1:047390200627:collection/my-coll
Face Model Version: 3.0
Face Count: 2
Created: Fri Sep 07 21:28:05 CEST 20185.6搜索面Kong
创建具有两个面Kong的集合后,我们现在可以将其与图像中的面Kong进行匹配。 因此,我们使用“按图像搜索面部”方法,该方法会拍摄一张图像并使用检测到的面部来搜索集合。 或者,也可以通过“索引面Kong”调用返回的现有面KongID进行搜索。
我们的新代码从App类调用:
case "search-faces-by-image":
SearchFacesByImage sfbi = new SearchFacesByImage();
sfbi.run(args);
break;要通过图像搜索人脸,我们必须提供两个参数:集合和图像。
public class SearchFacesByImage {
public void run(String[] args) {
if (args.length < 3) {
System.err.println("Please provide a collection and images: ");
return;
}
String collectionId = args[1];
String imageArg = args[2];
Path path = Paths.get(imageArg);
ByteBuffer byteBuffer;
try {
byte[] bytes = Files.readAllBytes(path);
byteBuffer = ByteBuffer.wrap(bytes);
} catch (IOException e) {
System.err.println("Failed to read file '" + imageArg + "': " + e.getMessage());
return;
}
SearchFacesByImageRequest request = new SearchFacesByImageRequest()
.withCollectionId(collectionId)
.withImage(new Image().withBytes(byteBuffer));
AmazonRekognition rekognition = ClientFactory.createClient();
SearchFacesByImageResult result = rekognition.searchFacesByImage(request);
List faceMatches = result.getFaceMatches();
for (FaceMatch match : faceMatches) {
Float similarity = match.getSimilarity();
Face face = match.getFace();
System.out.println("MATCH:" +
"\nSimilarity: " + similarity +
"\nFace-ID: " + face.getFaceId() +
"\nImage ID: " + face.getImageId() +
"\nExternal Image ID: " + face.getExternalImageId() +
"\nConfidence: " + face.getConfidence());
}
}
} 这两个参数都传递给SearchFacesByImageRequest的实例。 收到的结果包含一个面部匹配列表。 每个FaceMatch告诉我们匹配项和集合FaceMatch脸的标识符的相似性:
>java -jar target\rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar search-faces-by-image my-coll img\dinner3.jpg
MATCH:
Similarity: 96.45872
Face-ID: 0c8f1a0f-e401-4caf-8a5f-ec06d175f486
Image ID: b1dd15e7-4d08-5489-a14b-dd0dc009143a
External Image ID: dinner2.jpg
Confidence: 9999.99 如果您将服务返回的“ Face-ID”进行比较,您会发现它为我们索引图像dinner2.jpg时所获得的相同。 这符合我们之前提供的返回的“外部图像ID”。
6.视频操作
在本章中,我们将仔细研究可用的视频操作。
您可以使用Amazon Rekognition来检测视频中的以下内容:
- 标签
- 面Kong
- 人
- 名流
为了分析视频资料,您必须将其存储在Amazon S3存储桶中。 由于所有操作都是异步的,因此可以通过调用例如StartLabelDetection启动操作。 异步作业完成后,它将通知消息发送到Amazon SNS主题。 可以通过查询Amazon Simple Queue Service(SQS)来检索此状态。 调用相应的get操作会将分析结果传递到您的应用程序。
除了使用Amazon SQS服务之外,还可以实施一个隶属于Amazon SNS主题的Amazon Lambda函数。 该函数将针对该主题上的每条消息被调用,并且可以随后在服务器端处理分析结果。
视频必须使用H.264编解码器进行编码。 支持的文件格式是MPEG-4和MOV。 一个视频文件可以包含一个或多个编解码器。 如果遇到任何困难,请验证特定文件是否包含H.264编码的内容。
视频的最大文件大小为8 GB。 如果文件较大,则必须先将其拆分为较小的块。
前面的部分显示了如何创建集合以及如何搜索图像中存储在集合中的面部。 视频也可以这样做。 这意味着您将创建一个集合和索引面。 然后,可以使用StartFaceSearch操作开始搜索集合中的人脸。
6.1准备
在开始实施我们的第一个视频分析之前,我们必须设置一个IAM服务角色,该角色允许Amazon Rekognition访问Amazon SNS主题。 因此,转到Amazon AWS控制台内的IAM服务页面并创建一个新角色。 选择“ AWS服务”作为类型,选择“识别”作为服务:

在下一步中,检查新角色是否附加了策略“ AmazonRekognitionServiceRole”:
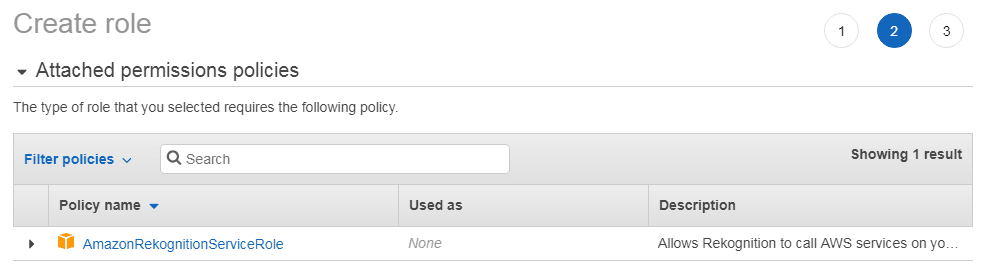
该角色允许Amazon Rekognition服务访问以“ AmazonRekognition”为前缀的SNS主题。
最后一步要求您为新角色指定名称:

请写下该角色的ARN,稍后再用。
您需要确保所使用的用户至少具有以下权限:
- AmazonSQSFullAccess
- AmazonRekognitionFullAccess
- AmazonS3ReadOnlyAccess
另外,我们向该IAM用户添加以下“内联策略”:
{
"Version": "2012-10-17",
"Statement": [{
"Sid": "MySid",
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:"
}]
}请用上面提到的ARN替换ARN。
现在是时候创建一个SNS主题了。 因此,导航到AWS控制台内的SNS服务并创建一个新主题。 请注意,主题名称必须以AmazonRekognition :

再次,请写下该主题的ARN。
有一个SNS主题,我们可以使用AWS内的SQS控制台为其创建标准队列:
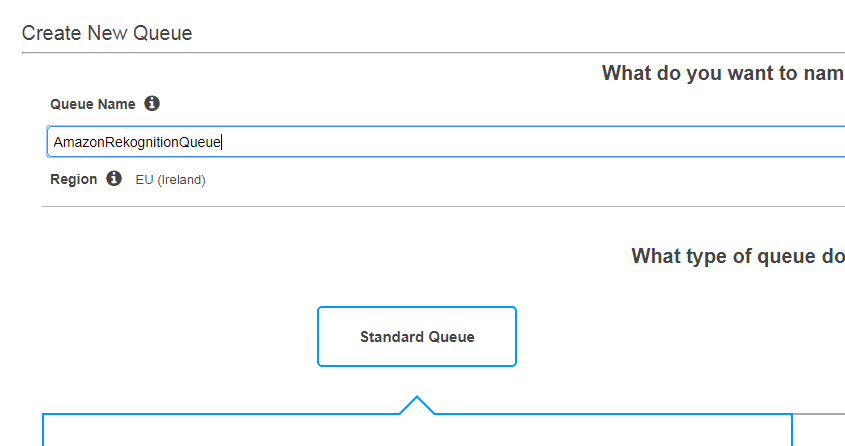
新队列应该存储先前创建的主题的消息。 因此,我们将此队列订阅主题:

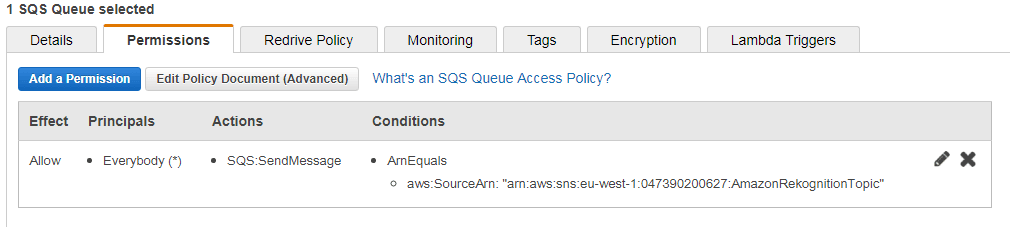
通过查看SQS队列的权限,验证SNS主题可以将消息发送到队列:
最后,我们可以将视频上传到S3存储桶。 此处举例说明如何使用Amazon S3。 请注意,存储桶与SNS主题,SQS队列以及为您的应用程序配置的存储桶位于同一区域。
6.2检测标签
完成所有设置操作后,我们现在准备实施一个可检测视频中标签的应用程序。
因此,我们扩展了App类:
case "detect-labels-video":
DetectLabelsVideo detectLabelsVideo = new DetectLabelsVideo();
detectLabelsVideo.run(args);
break; 此外,我们创建了一个名为DetectLabelsVideo的新类:
public class DetectLabelsVideo {
private static final String SQS_QUEUE_URL = "https://sqs.eu-west-1.amazonaws.com/...";
private static final String ROLE_ARN = "arn:aws:iam::...";
private static final String SNS_TOPIC_ARN = "arn:aws:sns:...";
public void run(String[] args) throws InterruptedException {
if (args.length < 3) {
System.err.println("Please provide a collection and images: 首先,请将常量SQS_QUEUE_URL , ROLE_ARN和SNS_TOPIC_ARN的值SNS_TOPIC_ARN为您的值。 通过在“详细信息”选项卡中的SQS服务页面中的AWS控制台中选择队列,可以获取SQS队列的URL。
该代码在开始时使用该角色的ARN和SNS主题创建一个NotificationChannel 。 该通道用于提交StartLabelDetectionRequest请求。 此外,此请求还使用存储桶和视频名称,检测的最低置信度和作业标签来指定Amazon S3中的视频位置。 结果消息包含在后台异步处理的作业的ID。
因此,我们的代码必须使用AmazonSQS实例轮询SQS队列。 这是由ClientFactory内部的一些新代码创建的:
public static AmazonSQS createSQSClient() {
ClientConfiguration clientConfig = createClientConfiguration();
return AmazonSQSClientBuilder
.standard()
.withClientConfiguration(clientConfig)
.withCredentials(new ProfileCredentialsProvider())
.withRegion("eu-west-1")
.build();
} ClientConfiguration与Rekognition客户端相同,因此我们可以将其重构为方法createClientConfiguration() 。
AmazonSQS提供了方法receiveMessage()来从SQS队列收集新消息。 队列的URL作为此方法的第一个参数提供。 以下代码遍历所有消息并提取作业ID。 如果它与我们之前获得的相匹配,则将评估作业的状态。 在情况下,它SUCCEEDED ,我们可以查询的结果亚马逊Rekognition服务。
这是通过提交完成GetLabelDetectionRequest与作业ID,最大的结果和排序顺序的Rekognition服务。 由于列表可能很长,因此使用令牌对结果进行分页。 当结果包含“下一个令牌”时,我们必须提交另一个请求以检索剩余的结果。 对于每个检测到的标签,我们输出标签的名称,标签的置信度以及相对于视频开头的时间戳。
用户可以通过提供三个参数来启动应用程序:
java -jar target\rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar detect-labels-video javacodegeeks-videos people_walking.mp4第一个参数是在我们的应用程序中启动的操作,第二个参数是S3存储桶,第三个参数是存储桶中视频的名称。 如前所述,请仔细检查存储桶是否位于您正在使用的AWS区域内。 在这里,我选择了与步行者一起观看的视频。 随意选择您拥有的任何H.264编码视频。
视频的示例输出如下所示:
Started label detection.
Waiting for message with job-id:563b31a1f1fa05a9cb917d270c7c500631bc13e159ea18e4e8bfa5d6ad689624
......
Found job: "563b31a1f1fa05a9cb917d270c7c500631bc13e159ea18e4e8bfa5d6ad689624"
Label: Crowd; confidence=58.403896; ts=0
Label: Human; confidence=98.9896; ts=0
Label: People; confidence=97.9793; ts=0
Label: Person; confidence=98.9896; ts=0
Label: Crowd; confidence=53.8455; ts=166
Label: Human; confidence=98.9825; ts=166
Label: People; confidence=97.965004; ts=166
Label: Person; confidence=98.9825; ts=166
Label: Human; confidence=98.9161; ts=375
Label: People; confidence=97.8322; ts=375
Label: Person; confidence=98.9161; ts=375
Label: Crowd; confidence=51.8283; ts=583
Label: Human; confidence=98.9411; ts=583
Label: People; confidence=97.8823; ts=583
Label: Person; confidence=98.9411; ts=583
Label: Human; confidence=98.896996; ts=792
Label: People; confidence=97.794; ts=792
Label: Person; confidence=98.896996; ts=792
Label: Human; confidence=99.0301; ts=959
Label: People; confidence=98.060104; ts=959
Label: Person; confidence=99.0301; ts=959
Label: Human; confidence=99.026695; ts=1167
Label: People; confidence=98.0535; ts=1167
Label: Person; confidence=99.026695; ts=1167
Label: Clothing; confidence=51.8821; ts=1376
[...]如我们所见,该服务非常确定它已经检测到人群。 输出将被截断,因为其余示例视频将重复相同的输出。
6.3跟踪人员
视频分析的另一个有趣的操作是跟踪视频中的人物。 因此,Amazon Rekognition提供了StartPersonTracking和GetPersonTracking方法。
基本步骤与前面的示例相同。 首先,我们必须扩展App class :
case "track-persons":
TrackPersons trackPersons = new TrackPersons();
trackPersons.run(args);
break; 接下来,我们可以重用或重构上一示例中的类。 由于轮询消息队列的循环保持不变,因此我们只需startLabelDetection()以下两个方法替换两个方法startLabelDetection()和getResultsLabels :
private String startPersonTracking(String s3Bucket, String video, NotificationChannel channel,
AmazonRekognition rekognition) {
StartPersonTrackingRequest request = new StartPersonTrackingRequest()
.withVideo(new Video()
.withS3Object(new S3Object()
.withBucket(s3Bucket)
.withName(video)))
.withJobTag("track-person")
.withNotificationChannel(channel);
StartPersonTrackingResult result = rekognition.startPersonTracking(request);
return result.getJobId();
}
private void getPersonTracking(AmazonRekognition rekognition, String jobId) {
String token = null;
do {
GetPersonTrackingRequest request = new GetPersonTrackingRequest()
.withJobId(jobId)
.withMaxResults(10)
.withSortBy(PersonTrackingSortBy.TIMESTAMP);
if (token != null) {
request.setNextToken(token);
}
GetPersonTrackingResult result = rekognition.getPersonTracking(request);
List persons = result.getPersons();
for (PersonDetection detection : persons) {
PersonDetail person = detection.getPerson();
Long index = person.getIndex();
Long timestamp = detection.getTimestamp();
System.out.println("Face with id " + index + " detected at " + timestamp + ".");
}
token = result.getNextToken();
} while (token != null);
} 第一种方法创建并提交新的GetPersonTrackingRequest 。 该实例将视频在Amazon S3中的位置,作业标签和通知通道传输到Amazon Rekognition服务。 结果作业ID返回给此方法的调用者。 随后将其用于从SQS队列中获取正确的消息。 找到相应的消息后,将调用getPersonTracking()方法。 它将带有作业ID,最大结果数和排序顺序的GetPersonTrackingRequest发送到后端。 响应包含带有PersonDetection对象的列表。 Eech PersonDetection提供视频中人物的索引(可用于跟踪后续列表中的人物),视频中检测的时间戳和有关面部检测的细节(在上面的代码中未显示)。
Starting the application on the video before shows the following sample output:
java -jar target\rekognition-1.0-SNAPSHOT-jar-with-dependencies.jar track-persons javacodegeeks-videos people_walking.mp4
Waiting for message with job-id:6ea86fa7c61860f5043077365930ff1aaafb39532cfe046ddca01ed138a075f6
............................................................................
Found job: "6ea86fa7c61860f5043077365930ff1aaafb39532cfe046ddca01ed138a075f6"
Face with id 0 detected at 0.
Face with id 1 detected at 0.
Face with id 2 detected at 0.
Face with id 3 detected at 0.
Face with id 4 detected at 0.
Face with id 5 detected at 0.
Face with id 3 detected at 41.
Face with id 4 detected at 41.
Face with id 5 detected at 41.
Face with id 6 detected at 41.
Face with id 3 detected at 125.
Face with id 4 detected at 125.
Face with id 5 detected at 125.
Face with id 0 detected at 166.
Face with id 3 detected at 166.
Face with id 4 detected at 166.
Face with id 5 detected at 166.
Face with id 6 detected at 166.
Face with id 3 detected at 250.It is now up to you to extend the examples to a complete application.
7.下载源代码
That was Amazon AWS Rekognition Tutorial.
You can download the full source codes of this example here: Amazon AWS Rekognition Tutorial
翻译自: https://www.javacodegeeks.com/2018/09/amazon-aws-rekognition-tutorial.html