1. 传统证据合成理论中存在的问题
在这篇文章中,笔者希望和大家一起讨论关于传统证据合成理论中面临的两个问题于挑战,即【相关性问题】、【冲突性问题】。这两个问题在现实世界中广泛存在,围绕这两个问题的大量研究工作,推动了D-S证据理论的大踏步发展。
0x1:证据合成中的冲突性问题 -- 从Zadeh悖论说起
Dempster合成规则对各信息源提供的证据是平等对待的,认为各信息源提供证据的重要性与可靠性无优劣之分。但是实际应用中,不同的证据源提供证据的重要性与可靠性是存在差异的,这时如果还是直接应用传统D-S合成规则就会遇到问题。
例如在上一篇文章的例子中,
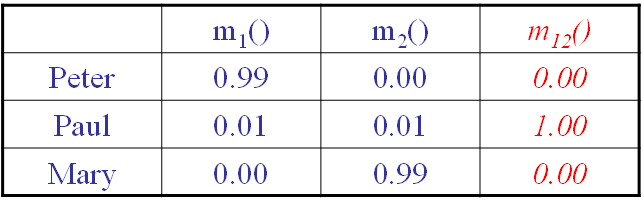
两名目击证人(Peter and Mary),它们的证词存在明显的冲突,几乎可以说是各执一词了。但是根据D-S合成规则进行证据融合的结果却明显违反我们的理性认知。可信度全部分配给了Paul命题。
显然,传统D-S合成理论没有很好地处理多源证据中的冲突性问题。
在这篇文章中,笔者和大家一起探讨关于相关证据和证据重要性或可靠性不同时的证据合成问题。
0x2:证据合成中的相关性问题 -- 从特征工程中相关性特征的危害说起
我们在之前的文章中讨论过相关性特征导致过拟合的问题。由于传统概率模型的对单原子特征累乘的特性,特征向量中如果存在很多相关性特征,会导致某一方面的一组特征获得太大的累计权重,这种特征权重聚集又进一步导致了过拟合现象的发生。
Relevant Link:
《证据推理理论、方法及其在决策评估中的应用》朱卫东、吴勇
0x3:相关性和冲突性是坏事吗?
极端情况下:
- 证据之间完全冲突,彼此之间完全没有交集
- 证据之间完全相关,彼此之间完全重合,本质上可以降维为单个证据
需要明白的是,相关性和冲突性这两个词,字面上看是贬义词,实际上它们是我们现实世界中广泛存在而又不可完全避免的现象。
用于支持事物的背后的证据,既不会呈现彼此完全冲突的状态,也不会彼此完全重合(完全相关),而是像上图那样,同时存在相关性和冲突性。
而冲突性和相关性是两个彼此相反的度量,冲突性越强,相关性就越弱;反之。
2. 相关证据合成方法
当两个证据中某些焦元的基本可信数由同一证据源(或依据相同特征、属性)产生时,称这样的焦元为相关焦元,称这两个证据互为相关证据。
在相关证据的证据合成中,若不考虑证据的相关性,而用Dempster合成方法进行相关证据的合成,那么将会产生其合成结果的超估计。
总体来说,相关证据合成方法的思想主要有两种:
- 一种是在相关证据合成时将基本可信数乘以一个调整系数,力图将相关证据转化为相当的独立证据,再按Dempster规则进行合成。
- 另一种是将两个相关证据在已知相关源证据的条件下分解两个相关证据为三个独立的源证据,然后再将相互独立的源证据按Dempster规则进行合成。
0x1:相关证据分解成独立证据的合成方法
D-S证据理论只适用于证据彼此独立的情况,而实际业务场景中,往往需要处理不独立的证据。

上图中,Ea、Ex、Eb 是三个独立的证据,它们合成为 E1、E2 这两个相关证据。
- E1 由 Ea 和 Ex 合成
- E2 由 Eb 和 Ex 合成
反之,可以将 E1、E2 这两个相关证据看成三个独立证据的合成。
证据 E1、E2、Ea、Ex、Eb 对应的基本可信数函数分别为 m1、m2、ma、mx、mb,则有:

若直接用D-S理论合成 E1 与 E2,则有:
![]()
从上式可以看到,合成中,独立的源证据 Ex 被多用了一次。合成证据的 m函数理论上来说应为:
![]()
假设识别框架 Θ={C,D},ma、mx、mb、m1、m2,则 m'、m 的差异的计算入下表所示:

如果已知独立的相关源证据 Ex 的基本可分配数 mx,则有由上面 m 和 m’ 的两式相减,反向求出独立源证据 Ea、Eb 的基本可分配数 ma、mb,然后,用Dempster合成方法对独立源证据 Ea、Eb、Ex 合成求出 E1、E2 合成证据的基本可信数函数 m。
相关证据分解成独立证据的合成方法,从理论上说合理可行。但是,用该方法处理的相关证据要具备一些前提条件:
- 它只适用于相关焦元集合C的构成元素与相关证据 E1、E2 的核 A、B 的构成元素相等的情况,该条件是相关证据的特殊情况
- 它要求已知独立的相关源证据 Ex 及其 mx,这是应用该方法解决问题的关键
- 用Dempster合成公式反向求出独立源证据 Ea、Eb 的的基本可分配数 ma、mb,计算工作量大,且计算结果不唯一
上述三个条件限制了该合成方法在一般相关证据合成中的应用。
0x2:调整相关证据基本可信数函数的合成方法
在相关证据的证据合成中,为了减少用Dempster合成方法进行相关证据的合成而产生其合成结果的超估计,产生了对相关证据的基本可信数进行衰减,以减少其合成结果的超估计,使相关证据合成的结果更接近独立证据源的合成结果。
1、规范证据相关概念定义
1)证据强度 S(E)
证据 E 的焦元为 A(A1,A2,....,Ak),焦元的个数为 n(A),焦元 Ai 的基数是 |Ai|,焦元 Ai 的基本可信数为 m(Ai),证据强度定义为 S(E):
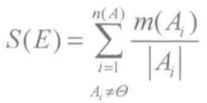
2)证据相关强度 S(E1,E2)
证据 E1、E2 的相关焦元为 C(C1,C2,....,Ck),焦元的个数为 n(C),焦元 Ci 的基数是 |Ci|,证据相关强度为 S(E1,E2):
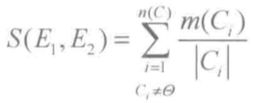
3)E1 对 E2 证据的规范证据相关度 r(E1,E2)
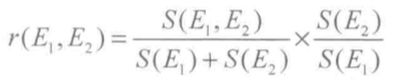
3)E2 对 E1 证据的规范证据相关度 r(E2,E1)
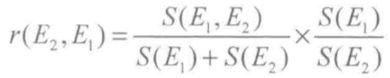
规范证据相关度与证据相关度成正比,证据相关度越大,相关证据的基本可信数对相关证据合成时的影响就越大。为了消除其影响,应对相关证据的基本可信数进行更大的修正,为此,用 1-r(Ei,Ej) 作为修正系数。
2、相关证据的修正合成方法
首先,对相关证据的基本可信数 m1(Ai)、m2(Bj) 按照下式进行修正:
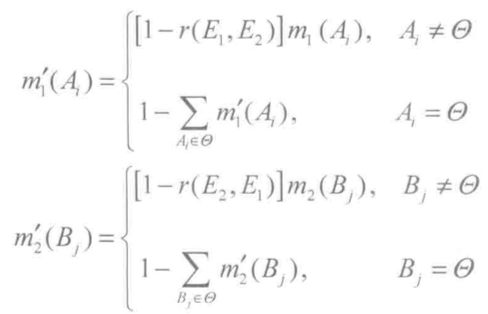
完成上面的修正之后,就可以基于修正后的基本可信数按照Dempster合成规则进行合成。
3、基于相关证据的修正合成方法的缺点
以上相关证据合成方法存在以下两个不足之处:
- 首先,定义的修正系数具有较强的假设性,它假设相关证据合成时,(1-规范证据相关度)与相关证据对合成证据焦元的基本可信数的超估计,遵循等比例关系。这样,用修正后的证据可看成独立证据。
- 其次,修正计算未考虑相关证据中相关焦元与非相关焦元的区别,而用修正系数对相关证据的所有焦元进行修正。
0x3:基于可变参数优化的相关证据合成方法
1、相关证据的相关焦元分布情况分析
设相关证据 E1、E2 对应的基本可信度分配分别为 m1、m2,对应的焦元分别为 A(A1,A2,...,An)、B(B1,B2,....,Bn),相关焦元为 C(C1,C2,.....,Ck),E1、E2 的焦元的交集为 G,则相关证据的焦元的集合情况可用下图表示:
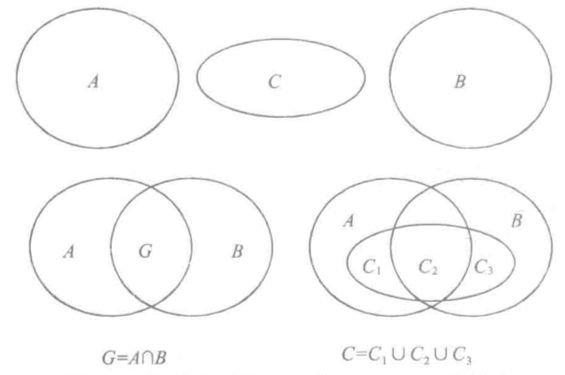
相关焦元集合 C 与 A、B、G 的关系
对上图分析可知,一般情况下,相关焦元的集合 C 满足:
![]()
C 集合可分解成 C1、C2、C3 三个部分,![]() 。
。
特殊的,当焦元都是单点元素时,
![]() ,并且 C1 与 C3 为空集
,并且 C1 与 C3 为空集
一般情况下,相关证据的焦元可分为相关焦元与非相关焦元两个部分。
2、基于可变参数优化的相关证据合成方法
基于消除上述相关证据合成方法存在的弱点,并考虑相关证据的相关焦元分布的一般情况,有学者提出了【基于可变参数优化的相关证据合成方法】。
设 Bel1,Bel2 是同一识别框架 Θ 上的两个相关证据 E1、E2 的信度函数,m1、m2 是对应的基本可信度分配,对应的焦元分别为 A1,A2,....,Ak 和 B1,B2,....,Bk,相关焦元集合为 C(C1,C2,....,Cj),如果:
![]() 存在,且
存在,且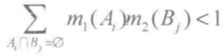
且基本可信度分配为 m,则有:

其中,

 ,
,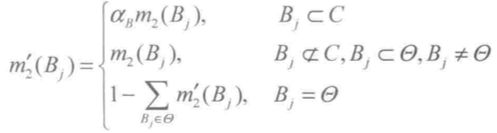
上述相关证据合成方法主要从以下几个方面进行了改造:
- 首先,在相关证据的合成中,产生合成证据焦元的基本可信数的超估计的原因是,相关焦元的基本可信数被重复运用于证据的合成,所以合理的做法是,只对相关焦元的基本可信数进行衰减。
- 其次,修正系数 aA,aB 是可变参数。由于相关证据合成在实际应用中都是面向具体问题的,修正系数 aA,aB 的确定可根据相关证据合成所解决的具体问题来确定。例如:
- 基于专家领域经验,设定一组适合具体问题场景的参数
- 基于数据驱动的方式,通过有标注数据进行有监督训练,通过参数优化的方法来确定参数
需要注意的是,在上式中,当 aA = 0,aB = 0 时,此时修正的合成公式退化为 m1(Ai),m2(Bj),即退化为Dempster合成公式。
3. 冲突证据的合成方法
Dempster合成规则的应用存在一些缺陷和局限性,如对于冲突非常高的证据合成可能会出现背离常理的结论,例如文章开头举的”Zadeh悖论例子“。为了解决Dempster在应用过程中的局限,有学者进行了深入的研究,提出了一系列的修正方法。
0x1:Dubois-Prade合成规则
Dubois-Prade规则认为当两个证据源不存在冲突时,证据源都是可靠的,如果存在冲突时,只有其中一个是可靠的。
因此对某个观测值而言,当一个证据判定其处于集合 X 中,另一个证据判定其处于 Y 之中时,
- 如果 X ∩ Y ≠ ∅,则合成结果处于 X ∩ Y 中
- 如果 X ∩ Y = ∅,则这两个命题是矛盾的,其中只能有一个判定为真。由于不能确定哪个判定是可靠的,因此合成结果放于集合 X ∪ Y 中。

Dubois和Prade针对两个证据源中有一个是可靠的,另外一个是错误的,而不确定哪条证据是错误的这种客观存在的情况,提出了析取规则,具体如下:

0x2:Smets组合规则
Smets认为人们往往事先难以确定一个完备的识别框架,且识别框架的不完备是造成证据冲突的根源。
在他的TBM理论中,引入”开放世界假设“,把对空集的基本概率赋值 m(∅) ≥ 0 定义为对”真命题在当前已知的识别框架之外“信任度,同时证据组合中取消对组合结果的归一化,而把两个证据组合产生的冲突归于 m(∅)。具体合成公式如下:

由上式可见,所有的冲突被分配给了空集,这主要是由于Smets人为导致融合结果不合理的原因是,在未知环境下,识别框架可能是不完备的,因而必然导致存在一些无法判断其真伪的未知命题,证据冲突正是由这些未知命题造成的,所以需要将冲突分配给空集。
换句话说,Smets认为,在识别框架不完善的情况下,空集可能就是潜在的新命题。
Smets组合理论的缺点在于,对决策问题而言,决策者主要关注的是识别框架中的元素,实际应用过程中,m(∅)是没有多少作用的。
0x3:Yager合成规则
Yager认为证据如果存在了冲突,那么证据组合的结果可能不是完全可靠的,所以需要将冲突证据完全分配给识别框架Θ上,具体合成公式如下:
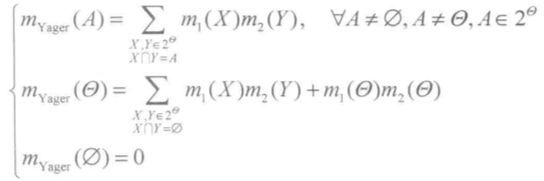
从上式中可以看到,Yager的公式取消了Dempster合成规则中的正则化过程,其基本思想是:冲突源于人们对判别对象的无知,既然人们并不了解冲突的具体情况,不如将所有的冲突都分配给识别框架。
笔者认为,Yager合成规则的基本思想非常贴近现实业务场景的问题本质,我们在现实业务场景中,对一个事物进行决策判断的时候,常常会面临所谓的”灰色地带问题“,例如:
- 某个进程行为既像恶意的,也像管理员自己执行的合法行为
- 某个python样本整体上看是合法的,但是有某几行代码似乎有一些包含不正常目的的迹象,不太能确定
Yager公式处理这种问题的解决思路,就类似于中国的老话,”似是而非,无极而太极“,”打圆场“,每种可能性都说道,每种又都不绝对,是一种折中的判断。
Yager合成规则的缺陷也很明显:
- 其一,该方法在证据数量超过2个时,合成结果不理想
- 其二,该方法的鲁棒性较差
- 其三,常常出现合成后不确定程度不减反增的现象
0x4:比例冲突重新分配规则
Smarandache和Dezert针对证据合成过程中存在的冲突问题,认为冲突信息的产生来自于识别框架中单焦元之间的冲突。
并集产生的不确定信息不参与产生冲突,并且单焦元产生冲突的作用大小与其本身的基本可信数成正比。
Smarandache和Dezert提出了一系列按一定比例将冲突进行分配的【比例冲突重新分配规则(the proportional conflict redistribution rules,PCR)】。
无论冲突的大小如何,PCR5冲突合并的效果总是不劣于Dempster合成规则和其他规则,合成公式具体如下:
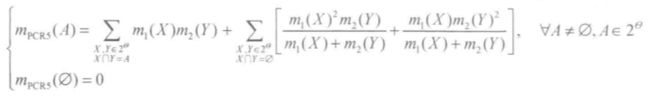
0x5:DSmT合成规则
Smarandache和Dezert提出的DSmT理论,放宽了对识别框架中焦元的约束限制,认为经典的证据理论假定的命题之间事实上是有交集的,框架命题之间的界限有时是模糊不清的,在原有识别框架的幂集基础上提出了具有更多命题的超幂集 DΘ。
DSmT去除了传统证据理论的一些主要限制,即:
- 识别框架的元素(证据)是互斥和穷举的
- 中间性原理(任何处于识别框架幂集中的元素的补集也属于该幂集)
- 合成规则中归一化组合规则
经典的DSmT融合规则的具体合成如下:
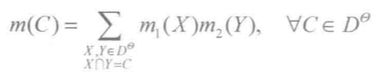
0x6:ER(Evidence Reasoning)合成规则
Yang等提出的证据推理方法得到比较广泛的应用,是D-S证据理论应用于决策评估领域的代表性成果。该方法兼具了修正证据源与改进D-S合成规则的思想。
证据推理合成规则应用权重修正证据源,主要沿用了D-S规则的合成思想,但在合成过程中对未分配证据进一步细分。
为便于理解,在此将证据推理规则按照传统D-S的形式表述,设在给定识别框架Θ下,有 m1 和 m2 两条待合成的证据,其权重分别为 ω1 和 ω2。
首先,用相对权重预处理基本可信度分配,将分配给识别框架的基本可信度分解成![]() 和
和![]() 两部分,
两部分,![]() 表示由权重引起的未分配,
表示由权重引起的未分配,![]() 表示对事物的无知引起的未分配,其中 i=1或2。下面对证据进行处理:
表示对事物的无知引起的未分配,其中 i=1或2。下面对证据进行处理:
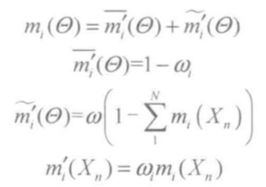
处理后的证据利用Dempster合成规则进行合成之后,利用下面两式去除权重引起的未分配信度![]() 的影响:
的影响:
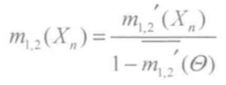 ,
,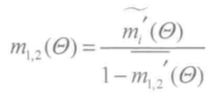
证据推理规则能够较好地处理冲突证据合成的问题,且满足交换律、结合律及非等幂性等性质。但是,该方法也有一定缺陷:
- 其一,收敛速度慢
- 其二,证据权重需要借助其他方法或依靠决策者主观判定确定
0x7:基于证据联盟的证据合成方法
在证据合成之前进行冲突分析,根据待合成证据的具体情况,灵活地选择证据合成策略。
- 如果证据间不存在强冲突的证据,可直接应用具有良好收敛性的经典D-S合成规则
- 如果证据间存在强烈冲突,则根据冲突情况将证据划分为若干个虚拟联盟,先应用D-S合成规则合成虚拟联盟内部的证据,再应用证据推理规则合成各个虚拟联盟
上述方法在保持D-S合成规则收敛性的同时,解决了冲突证据合成的问题。另外,冲突分析有助于了解证据间的关系,有利于识别和处理异常证据。
1、证据间冲突的测度
如前文所述,经典D-S证据理论以

反映两证据间的冲突程度,
- 若 k=1,则表明证据完全冲突,不能用Dempster-Shafer合成法则合成
- 若 k<1,则表明两个证据间虽然有差异,但存在一定的一致之处,可以用Dempster-Shafer合成法则合成
事实上,k在很多情况下不能充分反映证据间的冲突程度。
例如,识别框架 Θ={θ1,θ2},有两条证据 m1 和 m2 分别为:

很显然,从可信度分配来看,m1 和 m2 存在较大冲突,但是此时 k1,2 = 0,显然和实际情况不符。
此外,k 不满足距离公式的很多基本性质,故很多情况下难以应用 k 对证据进行比较分析。为了更精细地测度证据之间的冲突程度,Jousselme等学者提出了新的距离公式函数,用于测度证据之间的冲突程度。
定义一:
设 Θ 为一个包含 N 个不同的命题的完备的辨识框架,E 表示由 Θ 的所有子集生成的空间,每一个基本可信度分配表示为一个在空间 E 中的坐标系为 m(Ai) 的向量![]() ,满足:
,满足:
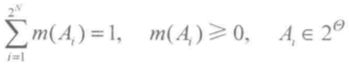
定义二:
设 Θ 为一个包含 N 个两两不同的命题的完备的识别框架,m1 和 m2 分别表示识别框架 Θ 上的两个基本可信度分配,m1 和 m2 的距离可以表示为:
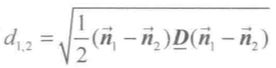
其中,![]() 表示一个 2N✖️2N 的矩阵,该矩阵中的元素:
表示一个 2N✖️2N 的矩阵,该矩阵中的元素:
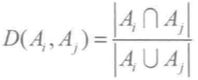
Jousselme距离的具体计算方法为:

其中,![]() ,
,![]() 为两个向量的内积。
为两个向量的内积。
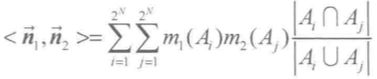
显然,Jousselme距离公式满足距离的基本性质:
- 0 ≤ d1,2 ≤ 1
- 当且仅当 d1,2 = 0时,m1 = m2
- d1,2 = d2,1
- d1,2 ≤ d1,3 + d3,2
设共计有 n 条待合成的证据,则可利用上式计算出任意两条证据 mi 和 mj 之间的距离,并生成距离矩阵(matrix of distance,MOD):
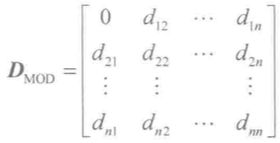
显然,DMOD为一个对角元素为0的对称矩阵。通过计算 DMOD 有助于人们准确地找到造成冲突的证据源,但仍然无法定量的测度证据系统(evidence system)的整体冲突程度。
证据系统的整体冲突程度不仅能够较好地评价证据系统可靠性和稳定性,而且能够合理地体现出依据证据系统做出决策的结果的稳定性与可信性。
证据系统的整体冲突程度应为系统内部所有证据之间冲突程度的综合结果。
定义三:
设在由 n 个证据组成的证据系统之中,证据系统的整体冲突程度CD,为系统内任意两条证据的距离的平均值。
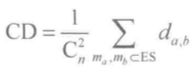
其中,
 :表示由 n 个证据两两组合可产生的组合数量
:表示由 n 个证据两两组合可产生的组合数量- da,b 表示证据系统中的任意两个不同的证据 ma 与 mb 间的距离
2、虚拟联盟的构建
在社会生活中,人们常常与观点同自己相似的人联合起来,对抗与自己的意见相左的人。虚拟联盟的构建就是根据人们在决策评估中经常出现的这种思维习惯或行为方式,对待合成证据进行划分。
构建虚拟联盟可以将支持不同命题的证据之间的力量对比情况清晰地呈现出来,找到主要冲突源,从而有利于细致分析证据的冲突情况。
虚拟联盟具体构建方法(down to top链接扩展)如下:
- 步骤一,设待合成的 n 条证据中任一证据 mj 在初始状态下独立构成一个虚拟联盟 Gj = {mj},通过计算证据间的Jousselme距离,建立距离矩阵 DMOD = [dij]nxn。
- 步骤二,根据应用环境设定冲突阈值 Mthreshold,即事先设定同一虚拟联盟内的两条证据不允许超越的最大距离,
- 若 max{dij} ≤ Mthreshold,即证据间不存在强冲突,则无需划分,可认为所有证据可以结成一个大的虚拟联盟
- 若 max{dij} ≥ Mthreshold,则需进一步将证据划分为若干个虚拟联盟
- 步骤三,从距离矩阵 DMOD 的非对角元素中找出 de,f = min{dij},则决策者 DMe 和 DMf 结成虚拟联盟,记为 Gr = {me,mf},并以 Gr 替换 me 和 mf。
- 步骤四,用公式 drj = max(dej,dfj) 计算虚拟联盟 Gr 与其他证据之间的距离,更新距离矩阵。
- 步骤五,重复步骤三、步骤四,直至各虚拟联盟间的距离均超过事先设定的冲突阈值 Mthreshold 为止,即达到收敛状态
3、虚拟联盟的权重
不同虚拟联盟中的证据数量与质量通常存在一定的差别,我们通过虚拟联盟的权重反映这种差异性。
虚拟联盟权重的大小取决于虚拟联盟内部证据受到其他证据的支持程度(或者说相关度)。如果一个证据被其他证据所支持,则该证据比较可信,若虚拟联盟内的证据可信性都比较高,其权重也较大。
设任意两条证据 mi 和 mj 之间的相似性测度 sij 为:
![]()
与距离矩阵 DMOD 类似,基于任何两个证据间的相似性,可以生成相似矩阵(matrix of similarity,MOS):

可以看出,如果两个证据间的冲突程度越小,对应的证据 mi 和 mj 的相似程度 sij 越大。
据此可以给出证据受到整个证据系统的支持程度的定义。
定义一:
设在由 n 个证据组成的证据系统之中,任意两条证据之间的相似程度为 sij,那么证据系统对证据 mi 的支持程度为:
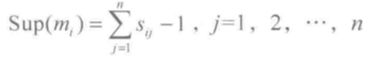
显然,上式实质上就是计算相似矩阵中的每一行之和,再减去其中证据 i 与自身的相似度1.
Supi 是相似程度的函数,体现了证据i 被其他 n-1 条证据支持的程度。
这个计量公式的基本思想在于:如果一个证据体与其他证据体比较相似,则认为它们相互支持的程度也比较高,该证据的可信性得到了其他证据的支持与证明。如果一个证据与其他证据体相似程度比较低,则认为该证据不被其他证据支持。
定义二:
设在由 n 个证据组成的证据系统之中,证据 mi 得到的支持程度为 Sup(mi),则证据 i 的可信度(Crd)为:
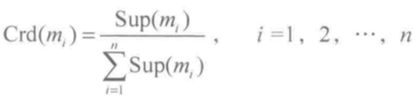
显然,Crd(mi)满足:
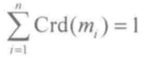
Crd(mi)可视为证据 mi 的权重。上式本质上就是将证据支持度压缩到了概率空间中。
定义三:
设 n 个证据经过冲突分析被划分为 m 个虚拟联盟 G1,G2,....,Gk,.....,Gm,其中任意虚拟联盟 Gk 由 g 条证据组成(g≥1),即:
![]()
则虚拟联盟 Gk 的权重 Wk 为:
![]()
显然,权重 Wk 满足:
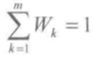
可见,虚拟联盟的权重是联盟内部的证据可信性的整体反映,因而权重 Wk 可以合理地体现出虚拟联盟 Gk 相对于整体证据系统中的重要程度。
4、基于虚拟联盟的证据合成新规则
通过冲突分析考察待合成证据的具体情况,灵活地选择证据合成策略。如果证据间不存在强冲突的证据,则直接应用D-S合成规则;如果存在强冲突,则证据合成过程如下图所示:
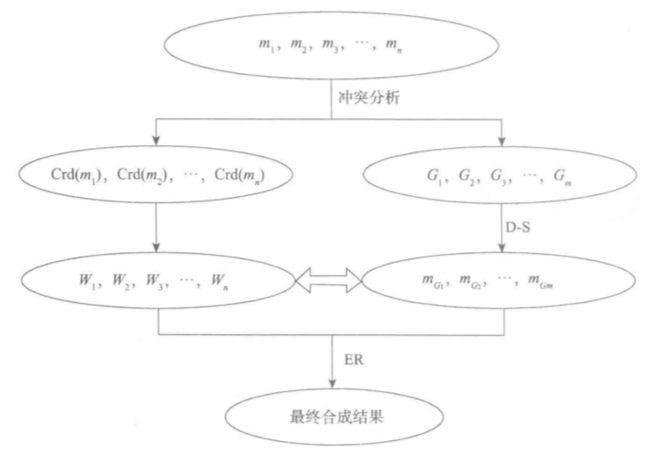
基于冲突分析的证据合成流程图
- 首先,将证据划分为若干个虚拟联盟,计算各证据的可信度Crd;
- 然后,应用D-S合成规则融合虚拟联盟内部的证据,获得虚拟联盟的基本可信度分配 mGk
- 最后,利用冲突分析中获得的权重信息,应用证据推理合成规则获取最终结果
4. 基于优化学习的综合系数修正证据合成方法
仅仅通过证据权重或证据相关对证据进行修正,有时可能会显得比较片面。
这个章节,我们来讨论一种基于数据驱动的,自适应学习的证据修正方法,利用优化的思想对证据进行综合的修正。
0x1:基于神经网络与Dempster合成规则的证据合成方法
人工神经网络是模拟生理学上人脑神经网络的结果和功能,用具有若干特性的感知机理论抽象、简化和模拟而构成的一种信息处理系统。它由大量神经元通过丰富和完善的连接而构成的自适应非线性动态系统。
自适应网络的整体参数是组成网络的各个结点参数集的并集。证据合成中将对每个证据的综合修正系数作为结点参数,用自适应网络来表示证据合成系统。该合成系统可用前向自适应网络来表示:
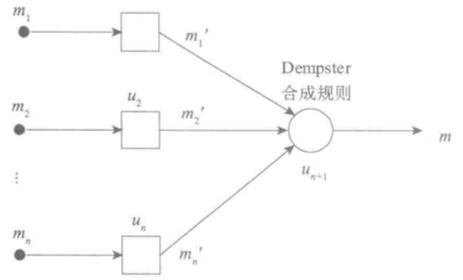
基于神经网络与Dempster合成规则的证据合成方法分为两个步骤来合成。
- 首先,面向具体问题确定学习样本,应用神经网络寻找最优的考虑证据相关性、重要性、可靠性与证据冲突的综合修正系数。
- 其次,用Dempster合成方法进行证据合成。
1、基于神经网络确定证据修正系数
设有一识别框架 Θ={θ1,θ2,.....,θh},则该识别框架有 H=2h 个元素,Bel1,Bel2,....,Beln 是同一识别框架 Θ 上的 n 个证据的信度函数,m1,m2,.....,mn 是对应的基本可信度分配,如果![]() 存在,设其基本可信度分配为 m。
存在,设其基本可信度分配为 m。
设第 i 个证据对第 j 个元素的基本可信数为 mi(Aj),mi(Aj)对应的综合修正系数为 ai(Aj),i=1,2,....,n;j=1,2,....,2k-1,则对第 i 个证据的基本可信数的修正公式为:

该修正公式可以看成神经网络自适应结点的结点函数。
ai(Aj)的取值用神经网络基于学习样本进行优化计算得到,其取值范围是[0,1]。
设有 P 组学习样本,每组样本对应于 n 个证据合成的一组输入与合成结果输出的正确值。将第 p 组训练数据的误差指标定义为误差的平方和,优化的目标是使 E 最小:


综合修正系数对误差指标的影响
2、用Dempster合成方法进行证据合成
对基本可信数进行修正后,用Dempster合成规则进行合成,就可得出 n 个证据的合成结果 m。
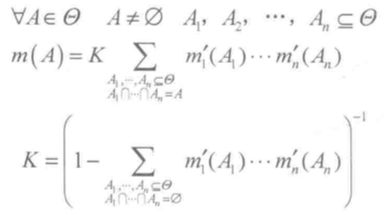
0x2:基于神经网络与Dempster合成规则的证据合成方法的三个性质
假设对 n 个证据的合成,存在 P 组学习样本,该样本可看成 n 个证据合成的 P 组理想目标值,则对这组理想目标值来说,n个证据合成的目标函数为:
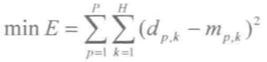
则基于神经网络与Dempster合成规则的证据合成方法存在以下三个性质:
1、性质一,基于神经网络与Dempster合成规则的证据合成方法其合成结果等于或优于经典Dempster合成方法
对基于神经网络与Dempster合成规则的证据合成方法来说,综合修正系数矩阵 ai,j 的各项都取值为 1 时,即:
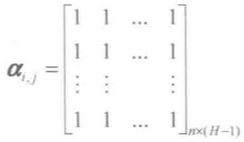
这时 mi' 等于 mi,即此时的合成结果与Dempster合成方法的合成结果相同。
设此时的合成误差为 Ed,由于神经网络在优化综合修正系数时的目标函数为求 E 的最小值,因此有:
![]()
即基于神经网络与Dempster合成规则的证据合成方法合成结果与学习样本的误差小于或等于Dempster合成方法。
性质二,基于神经网络与Dempster合成规则的证据合成方法具有对证据按信息的质量进行加权选择与排除的能力
换句话说,综合修正系数 ai,j 的取值越大,则该系数对应的第 i 个证据第 j 个元素的基本可信数对证据合成结果的影响就越大。
当第 i 个证据没有信息价值时,该证据对应的修正系数取值为 ai = (0,0,....,0),则该证据对证据合成结果的影响将被排除。由于Dempster合成规则具有结合律与交换律,所以该结论可推广到多个证据的合成情况。
性质三,基于神经网络与Dempster合成规则的证据合成方法的合成结果等于或优于n个证据中性能最好的单个证据的基本可信数
假设:n个证据中,第 i 个证据的基本可信数为 mi,p,k,第 p 次的理想目标值为 dp,k,第 L 个证据的性能最好,即第 L 个证据与其他证据相比,它的基本可信数与样本的理想目标值的误差为最小,即:
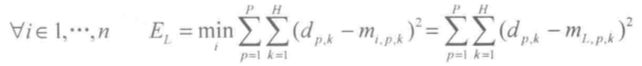
对基于神经网络与Dempster合成规则的证据合成方法来说,将综合修正系数矩阵 ai,j 与第 L 个证据相对应行的值取为1,其余的系数都取为0,即:
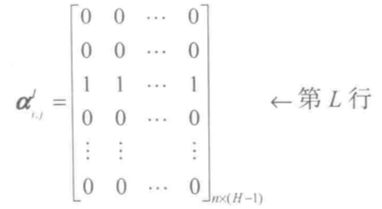
这时,由:
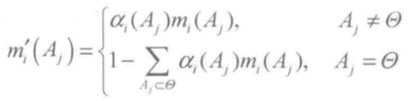
可知,mL' = mL,其余的基本可信数为 mi' = (0,0,....,1)。用:
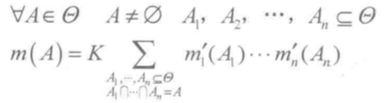
合成,即可得 m = mL,即 mp,k = mL,p,k。
基于神经网络与Dempster合成规则的证据合成方法的合成结果与第L个证据的基本可信数相等。
所以,经过神经网络优化的 ai,j*产生的mp,k*的合成结果E,优于或等于特定参数di,j'产生的mL,p,k的合成结果EL,即满足:

即:
![]()
基于神经网络与Dempster合成规则的证据合成方法的合成结果优于或等于(合成结果与学习样本的误差小于或等于) n个证据中性能最好的单个证据的基本可信数。
5. 基于冲突性证据合成理论在各个领域的应用
基于 D-S 证据的多语段融合语音情感识别
基于物联网节点加权的D-S证据理论数据融合算法