webRTC中音频相关的netEQ(五):DSP处理
上篇(webRTC中音频相关的netEQ(四):控制命令决策)讲了MCU模块是怎么根据网络延时、抖动缓冲延时和反馈报告等来决定给DSP模块发什么控制命令的。DSP模块根据收到的命令进行相关处理,处理简要流程图如下。

从上图看出如果有语音包从packet buffer里取出来先要做解码得到PCM数据,没有就不用做解码了。编解码也是数字信号处理算法的一种,是个相当大的topic,不是本文所关注的,本文关注的是对解码后的PCM数据做数字信号处理,如加减速。如果命令是非Normal命令,就要根据命令做DSP处理,是Normal命令就不用做了。最后取出一帧数据用于播放。
MCU发给DSP的主要的控制命令有正常播放(normal)、加速播放(accelerate)、减速播放(preemptive expand)、丢包补偿(PLC,代码中叫expand)、融合(merge)等。正常播放就是不需要做额外的DSP处理。加减速也就是改变语音时长,即在不改变语音的音调并保证良好音质的情况下使语音在时间轴上压缩或者拉伸,或者叫变速不变调。语音时长调整算法可分为时域调整和频域调整,时域调整以重叠区波形相似性(WSOLA)算法为代表,通常用在语音通信中。频域调整通常音乐数据中。丢包补偿就是基于先前的语音数据生成当前丢掉的语音数据。融合处理发生在上一播放的帧与当前解码的帧不是连续的情况下,需要来衔接和平滑一下。这些都是非常专业的算法,本文不会涉及,本文是讲工程上的一些实现,主要是buffer的处理。
在讲这些处理之前先看netEQ里相关的几块buffer,分别是decodedBuffer(用于放解码后的语音数据)、algorithmBuffer(用于放DSP算法处理后的语音数据)、speechBuffer(用于放将要播放的语音数据,这个在前面的文章(webRTC中音频相关的netEQ(二):数据结构)中讲过)和speechHistoryBuffer(用于放丢包补偿的历史语音数据,即靠这些数据来产生补偿的语音数据)。

先看加速处理。它主要用于加速播放,是抖动延迟过大时在不丢包的情况下尽量减少抖动延迟的关键措施。它的处理流程如下:
1,看decodedBuffer里是否有30Ms的语音数据(语音数据量要大于等于30Ms才能做加速处理),如果没有就需要向speechBuffer里未播放的语音数据借,使满足大于等于30Ms的条件。下图示意了借的步骤:
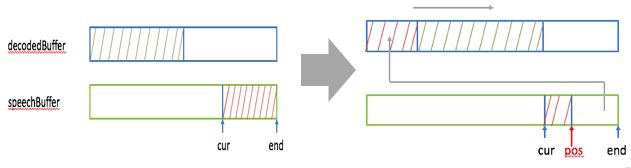
先算出decodedBuffer里缺的样本数(记为nsamples, 等于30Ms的样本数减去buffer里已有的样本数),即需要向speechBuffer借的样本数。然后在decodedBuffer里将已有的样本数右移nsamples,同时从speechBuffer里end处开始取出nsamples个样本,将其放在decodedBuffer里开始处空出来的地方。
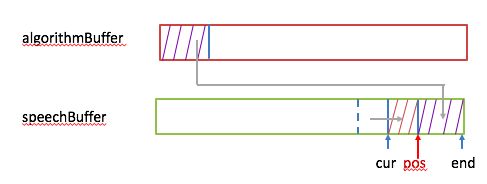
2,做加速算法处理,输入是decodedBuffer里的30Ms语音数据,输出放在algorithmBuffer里。如果压缩后的样本数小于向speechBuffer借的样本个数nsamples(假设小msamples),不仅要把这些压缩后的样本拷进speechBuffer里(从end位置处向前放),同时还要把从cur到pos处的样本数向后移msamples,cur指针也向后移msamples个数。下图给出了示意:
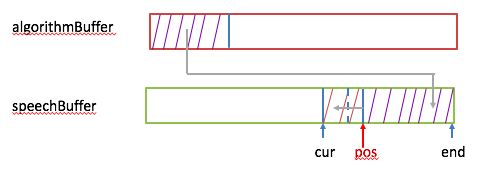
如果压缩后的样本数大于向speechBuffer借的样本个数(假设大qsamples),先要把从cur到pos处的样本数向前移qsamples(cur和pos指针都要向前移qsamples个数),然后把这些压缩后的样本拷进speechBuffer里(从pos位置处向后放)。下图给出了示意:
3,从speechBuffer里取出一帧语音数据播放,同时把cur指针向后移一帧的位置。
减速处理的流程跟加速是类似的, 这里就不详细讲了。下面开始讲丢包补偿,它的处理流程如下:
1,基于speechHistoryBuffer利用丢包补偿算法生成补偿的语音数据(记样本数为nsamples)放在algorithmBuffer里,同时还要更新speechHistoryBuffer里的数据为下次做丢包补偿做准备。示意图如下:
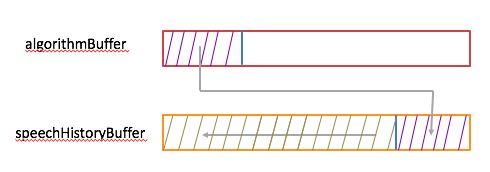
先把speechHistoryBuffer里的数据左移nsamples,然后把algorithmBuffer里的nsamples个样本放在speechHistoryBuffer的尾部。
2,把algorithmBuffer里生成的数据放到speechBuffer里。示意图如下:

先将speechBuffer里的数据左移nsamples,然后把algorithmBuffer里的nsamples个样本放在speechBuffer的尾部,同时cur指针也要左移nsamples。
3,从speechBuffer里取出一帧语音数据播放,同时把cur指针向后移一帧的位置。
至于merge中buffer的处理,相对简单,这里就不讲了。至此我觉得netEQ的主要核心点都讲完了,共5篇,算一个系列吧。理解了这些核心点后要想对netEQ有更深的认识就得去实际的调试了,把一些细节搞得更清楚。netEQ里面的细节特别多,要想全部搞清楚是要花不少时间的。要是全部搞清楚了对语音接收侧处理的认识会有一个质的提升。