一些关于KVM和VMware虚拟化原理的总结
感慨一下:VMware的官方文档详细到感人,足以见得VMware公司对技术的尊重!
一、KVM
(1)概述
KVM 全称是基于内核的虚拟机(Kernel-based Virtual Machine),它是一个 Linux 的一个内核模块,该内核模块使得 Linux 变成了一个Hypervisor。
(1)它由 Quramnet 开发,该公司于 2008年被 Red Hat 收购。
(2)它支持 x86 (32 and 64 位), s390, Powerpc 等 CPU。
(3)它从 Linux 2.6.20 起就作为一模块被包含在 Linux 内核中。
(4)它需要支持虚拟化扩展的 CPU。
(5)它是完全开源的。
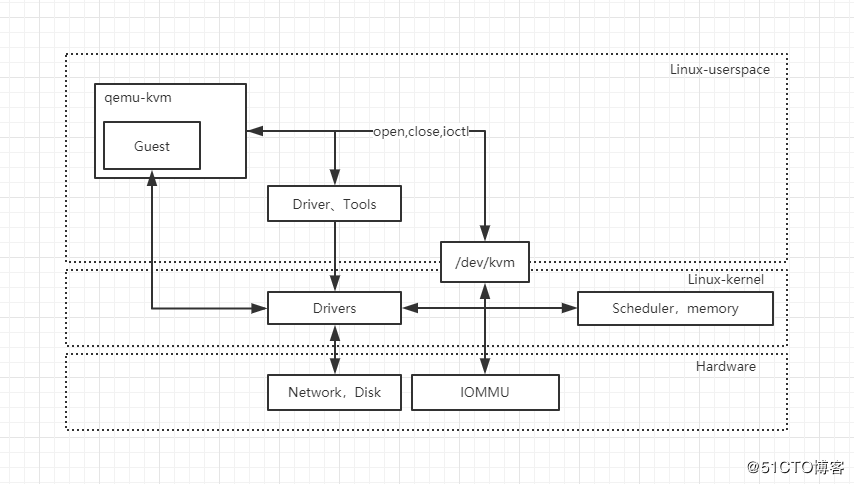
KVM 是基于虚拟化扩展(Intel VT 或者 AMD-V)的 X86 硬件的开源的 Linux 原生的全虚拟化解决方案。KVM 中,虚拟机被实现为常规的 Linux 进程,由标准 Linux 调度程序进行调度;虚机的每个虚拟 CPU 被实现为一个常规的 Linux 进程。这使得 KVM能够使用 Linux 内核的已有功能。但是,KVM 本身不执行任何硬件模拟,需要客户空间程序通过 /dev/kvm 接口设置一个客户机虚拟服务器的地址空间,向它提供模拟的 I/O,并将它的视频显示映射回宿主的显示屏。目前这个应用程序是 QEMU。
(1)客户机:客户机系统,包括CPU(vCPU)、内存、驱动(Console、网卡、I/O 设备驱动等),被 KVM 置于一种受限制的 CPU 模式下运行。
(2)KVM:运行在内核空间,提供CPU 和内存的虚拟化,以及客户机的 I/O 拦截。Guest 的 I/O 被 KVM 拦截后,交给 QEMU 处理。
(3)QEMU:修改过的为 KVM 虚机使用的 QEMU 代码,运行在用户空间,提供硬件 I/O 虚拟化,通过 IOCTL /dev/kvm 设备和 KVM 交互。
(2)KVM 实现拦截虚机的 I/O 请求的原理
现代 CPU 本身实现了对特殊指令的截获和重定向的硬件支持,甚至新的硬件会提供额外的资源来帮助软件实现对关键硬件资源的虚拟化从而提高性能。以 X86 平台为例,支持虚拟化技术的 CPU 带有特别优化过的指令集来控制虚拟化过程。通过这些指令集,VMM 很容易将客户机置于一种受限制的模式下运行,一旦客户机试图访问物理资源,硬件会暂停客户机的运行,将控制权交回给 VMM 处理。VMM 还可以利用硬件的虚级化增强机制,将客户机在受限模式下对一些特定资源的访问,完全由硬件重定向到 VMM 指定的虚拟资源,整个过程不需要暂停客户机的运行和 VMM 的参与。由于虚拟化硬件提供全新的架构,支持操作系统直接在上面运行,无需进行二进制转换,减少了相关的性能开销,极大简化了VMM的设计,使得VMM性能更加强大。从 2005 年开始,Intel 在其处理器产品线中推广 Intel Virtualization Technology 即 IntelVT 技术。
(3)QEMU-KVM
其实 QEMU 原本不是 KVM 的一部分,它自己就是一个纯软件实现的虚拟化系统,所以其性能低下。但是,QEMU 代码中包含整套的虚拟机实现,包括处理器虚拟化,内存虚拟化,以及 KVM需要使用到的虚拟设备模拟(网卡、显卡、存储控制器和硬盘等)。为了简化代码,KVM 在 QEMU 的基础上做了修改。VM 运行期间,QEMU 会通过 KVM 模块提供的系统调用进入内核,由 KVM 负责将虚拟机置于处理的特殊模式运行。遇到虚机进行 I/O 操作,KVM 会从上次的系统调用出口处返回 QEMU,由 QEMU 来负责解析和模拟这些设备。从 QEMU 的角度看,也可以说是 QEMU 使用了 KVM 模块的虚拟化功能,为自己的虚机提供了硬件虚拟化加速。除此以外,虚机的配置和创建、虚机运行所依赖的虚拟设备、虚机运行时的用户环境和交互,以及一些虚机的特定技术比如动态迁移,都是 QEMU 自己实现的。
(4)KVM
(1)KVM 内核模块在运行时按需加载进入内核空间运行。KVM 本身不执行任何设备模拟,需要 QEMU 通过 /dev/kvm 接口设置一个 GUEST OS 的地址空间,向它提供模拟的 I/O 设备,并将它的视频显示映射回宿主机的显示屏。它是KVM 虚机的核心部分,其主要功能是初始化 CPU 硬件,打开虚拟化模式,然后将虚拟客户机运行在虚拟机模式下,并对虚机的运行提供一定的支持。
(2)以在 Intel 上运行为例,KVM 模块被加载的时候,首先初始化内部的数据结构,做好准备后,KVM 模块检测当前的 CPU,然后打开 CPU 控制及存取 CR4 的虚拟化模式开关,并通过执行 VMXON 指令将宿主操作系统置于虚拟化模式的根模式,最后,KVM 模块创建特殊设备文件 /dev/kvm 并等待来自用户空间的指令。接下来的虚机的创建和运行将是 QEMU 和 KVM 相互配合的过程。两者的通信接口主要是一系列针对特殊设备文件 dev/kvm 的 IOCTL 调用。其中最重要的是创建虚机。它可以理解成KVM 为了某个特定的虚机创建对应的内核数据结构,同时,KVM 返回一个文件句柄来代表所创建的虚机。
(3)针对该句柄的调用可以对虚机做相应地管理,比如创建用户空间虚拟地址和客户机物理地址、真实物理地址之间的映射关系,再比如创建多个 vCPU。KVM 为每一个 vCPU 生成对应的文件句柄,对其相应地 IOCTL 调用,就可以对vCPU进行管理。其中最重要的就是“执行虚拟处理器”。通过它,虚机在 KVM 的支持下,被置于虚拟化模式的非根模式下,开始执行二进制指令。在非根模式下,所有敏感的二进制指令都被CPU捕捉到,CPU 在保存现场之后自动切换到根模式,由 KVM 决定如何处理。
(5)KVM功能列表
(1)支持CPU 和 memory 超分(Overcommit)
(2)支持半虚拟化I/O (virtio)
(3)支持热插拔 (cpu,块设备、网络设备等)
(4)支持对称多处理(Symmetric Multi-Processing,缩写为 SMP )
(5)支持实时迁移(Live Migration)
(6)支持 PCI 设备直接分配和 单根I/O 虚拟化 (SR-IOV)
(7)支持 内核同页合并 (KSM )
(8)支持 NUMA (Non-Uniform Memory Access,非一致存储访问结构 )
(6)KVM工具集合
(1)libvirt:操作和管理KVM虚机的虚拟化 API,使用 C 语言编写,可以由 Python,Ruby, Perl, PHP, Java 等语言调用。可以操作包括 KVM,vmware,XEN,Hyper-v, LXC 等 Hypervisor。
(2)Virsh:基于 libvirt 的 命令行工具 (CLI)。
(3)Virt-Manager:基于 libvirt 的 GUI 工具。
(4)virt-v2v:虚机格式迁移工具。
(5)virt-* 工具:包括 Virt-install (创建KVM虚机的命令行工具), Virt-viewer (连接到虚机屏幕的工具),Virt-clone(虚机克隆工具),virt-top 等。
(6)sVirt:安全工具。
(7)KVM 虚机的创建过程
qemu-kvm 通过对 /dev/kvm 的 一系列 ICOTL 命令控制虚机,一个 KVM 虚机即一个 Linux qemu-kvm 进程,与其他 Linux 进程一样被Linux 进程调度器调度。KVM 虚机包括虚拟内存、虚拟CPU和虚机 I/O设备,其中,内存和 CPU 的虚拟化由 KVM 内核模块负责实现,I/O 设备的虚拟化由 QEMU 负责实现。KVM户机系统的内存是 qemu-kvm 进程的地址空间的一部分。KVM 虚机的 vCPU 作为 线程运行在 qemu-kvm 进程的上下文中。
因为 CPU 中的虚拟化功能的支持,并不存在虚拟的 CPU,KVM Guest 代码是运行在物理 CPU 之上。通常来讲,主机操作系统和 VMM 运行在 VMX root 模式中,客户机操作系统及其应用运行在 VMX nonroot 模式中。因为两个模式都支持所有的 ring,因此,客户机可以运行在它所需要的 ring 中(OS 运行在 ring 0 中,应用运行在 ring 3 中),VMM 也运行在其需要的 ring 中 (对 KVM 来说,QEMU 运行在 ring 3,KVM 运行在 ring 0)。CPU 在两种模式之间的切换称为 VMX 切换。从 root mode 进入 nonroot mode,称为 VM entry;从 nonroot mode 进入 root mode,称为 VM exit。可见,CPU 受控制地在两种模式之间切换,轮流执行 VMM 代码和 Guest OS 代码。对 KVM 虚机来说,运行在 VMX Root Mode 下的 VMM 在需要执行 Guest OS 指令时执行 VMLAUNCH 指令将 CPU 转换到 VMX non-root mode,开始执行客户机代码,即 VM entry 过程;在 Guest OS 需要退出该 mode 时,CPU 自动切换到 VMX Root mode,即 VM exit 过程。可见,KVM 客户机代码是受 VMM 控制直接运行在物理 CPU 上的。QEMU 只是通过 KVM 控制虚机的代码被 CPU 执行,但是它们本身并不执行其代码。也就是说,CPU 并没有真正的被虚拟化成虚拟的 CPU 给客户机使用。

vSphere的CPU虚拟化与KVM有着非常相似的一致性:
二、CPU虚拟化
(1)为什么需要 CPU 虚拟化?
X86 操作系统是设计在直接运行在裸硬件设备上的,因此它们自动认为它们完全占有计算机硬件。x86 架构提供四个特权级别给操作系统和应用程序来访问硬件。 Ring 是指 CPU 的运行级别,Ring 0是最高级别,Ring1次之,Ring2更次之…… 就 Linux+x86 来说,操作系统(内核)需要直接访问硬件和内存,因此它的代码需要运行在最高运行级别 Ring0上,这样它可以使用特权指令,控制中断、修改页表、访问设备等等。应用程序的代码运行在最低运行级别上ring3上,不能做受控操作。如果要做,比如要访问磁盘,写文件,那就要通过执行系统调用(函数),执行系统调用的时候,CPU的运行级别会发生从ring3到ring0的切换,并跳转到系统调用对应的内核代码位置执行,这样内核就为你完成了设备访问,完成之后再从ring0返回ring3。这个过程也称作用户态和内核态的切换。那么,虚拟化在这里就遇到了一个难题,因为宿主操作系统是工作在 ring0 的,客户操作系统就不能也在 ring0 了,但是它不知道这一点,以前执行什么指令,现在还是执行什么指令,但是没有执行权限是会出错的。所以这时候虚拟机管理程序(VMM)需要避免这件事情发生。 虚机怎么通过 VMM 实现 Guest CPU 对硬件的访问,根据其原理不同有三种实现技术:全虚拟化、半虚拟化、硬件辅助的虚拟化。
(2)基于二进制翻译的全虚拟化(Full Virtualization with Binary Translation)
代表产品:VMware Workstation,QEMU,Virtual PC
客户操作系统运行在 Ring 1,它在执行特权指令时,会触发异常(CPU的机制,没权限的指令会触发异常),然后 VMM 捕获这个异常,在异常里面做翻译,模拟,最后返回到客户操作系统内,客户操作系统认为自己的特权指令工作正常,继续运行。但是这个性能损耗,就非常的大,简单的一条指令,执行完,了事,现在却要通过复杂的异常处理过程。
(3)超虚拟化(半虚拟化/操作系统辅助虚拟化 Paravirtualization)
代表产品:VMware ESXi/Microsoft Hyper-V/Xen 3.0/KVM
半虚拟化的思想就是,修改操作系统内核,替换掉不能虚拟化的指令,通过超级调用(hypercall)直接和底层的虚拟化层hypervisor来通讯,hypervisor 同时也提供了超级调用接口来满足其他关键内核操作,比如内存管理、中断和时间保持。种做法省去了全虚拟化中的捕获和模拟,大大提高了效率。所以像XEN这种半虚拟化技术,客户机操作系统都是有一个专门的定制内核版本,和x86、mips、arm这些内核版本等价。这样以来,就不会有捕获异常、翻译、模拟的过程了,性能损耗非常低。这就是XEN这种半虚拟化架构的优势。这也是为什么XEN只支持虚拟化Linux,无法虚拟化windows原因,微软不改代码啊。
(4)硬件辅助的全虚拟化
代表产品:Xen
2005年后,CPU厂商Intel 和 AMD 开始支持虚拟化了。 Intel 引入了 Intel-VT (Virtualization Technology)技术。 这种 CPU,有 VMX root operation 和 VMX non-root operation两种模式,两种模式都支持Ring 0 ~ Ring 3 共 4 个运行级别。这样,VMM 可以运行在 VMX root operation模式下,客户 OS 运行在VMX non-root operation模式下。而且两种操作模式可以互相转换。运行在 VMX root operation 模式下的 VMM 通过显式调用 VMLAUNCH 或 VMRESUME 指令切换到 VMX non-root operation 模式,硬件自动加载 Guest OS 的上下文,于是 Guest OS 获得运行,这种转换称为 VM entry。Guest OS 运行过程中遇到需要 VMM 处理的事件,例如外部中断或缺页异常,或者主动调用 VMCALL 指令调用 VMM 的服务的时候(与系统调用类似),硬件自动挂起 Guest OS,切换到 VMX root operation 模式,恢复 VMM 的运行,这种转换称为 VM exit。VMX root operation 模式下软件的行为与在没有 VT-x 技术的处理器上的行为基本一致;而VMX non-root operation 模式则有很大不同,最主要的区别是此时运行某些指令或遇到某些事件时,发生 VM exit。也就说,硬件这层就做了些区分,这样全虚拟化下,那些靠“捕获异常-翻译-模拟”的实现就不需要了。而且CPU厂商,支持虚拟化的力度越来越大,靠硬件辅助的全虚拟化技术的性能逐渐逼近半虚拟化,再加上全虚拟化不需要修改客户操作系统这一优势,全虚拟化技术应该是未来的发展趋势。
(5)多 CPU 服务器架构:SMP,NMP,NUMA
从系统架构来看,目前的商用服务器大体可以分为三类:
(1)多处理器结构 (SMP,Symmetric Multi-Processor):所有的CPU共享全部资源,如总线,内存和I/O系统等,操作系统或管理数据库的复本只有一个,这种系统有一个最大的特点就是共享所有资源。多个CPU之间没有区别,平等地访问内存、外设、一个操作系统。SMP 服务器的主要问题,那就是它的扩展能力非常有限。实验证明, SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
(2)海量并行处理结构 (MPP,Massive Parallel Processing):NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O 槽口等。在一个物理服务器内可以支持上百个 CPU 。但 NUMA 技术同样有一定缺陷,由于访问远地内存的延时远远超过本地内存,因此当 CPU 数量增加时,系统性能无法线性增加。
(3)MPP 模式则是一种分布式存储器模式,能够将更多的处理器纳入一个系统的存储器。一个分布式存储器模式具有多个节点,每个节点都有自己的存储器,可以配置为SMP模式,也可以配置为非SMP模式。单个的节点相互连接起来就形成了一个总系统。MPP可以近似理解成一个SMP的横向扩展集群,MPP一般要依靠软件实现。
(4)非一致存储访问结构 (NUMA : Non-Uniform Memory Access):它由多个 SMP 服务器通过一定的节点互联网络进行连接,协同工作,完成相同的任务,从用户的角度来看是一个服务器系统。其基本特征是由多个 SMP 服务器 ( 每个 SMP 服务器称节点 ) 通过节点互联网络连接而成,每个节点只访问自己的本地资源 ( 内存、存储等 ),是一种完全无共享 (Share Nothing) 结构。
通过uname -a可以查看CPU架构:
Linux linux.blue 3.10.0-1062.4.1.el7.x86_64 #1 SMP Fri Oct 18 17:15:30 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux(6)客户机系统的代码是如何运行的?
一个普通的 Linux 内核有两种执行模式:内核模式(Kenerl)和用户模式 (User)。为了支持带有虚拟化功能的 CPU,KVM 向 Linux 内核增加了第三种模式即客户机模式(Guest),该模式对应于 CPU 的 VMX non-root mode。KVM 内核模块作为 User mode 和 Guest mode 之间的桥梁:User mode 中的 QEMU-KVM 会通过 ICOTL 命令来运行虚拟机,KVM 内核模块收到该请求后,它先做一些准备工作,比如将 VCPU 上下文加载到 VMCS (virtual machine control structure)等,然后驱动 CPU 进入 VMX non-root 模式,开始执行客户机代码。三种模式的分工为:Guest 模式,执行客户机系统非 I/O 代码,并在需要的时候驱动 CPU 退出该模式;Kernel 模式,负责将 CPU 切换到 Guest mode 执行 Guest OS 代码,并在 CPU 退出 Guest mode 时回到 Kenerl 模式;User 模式,代表客户机系统执行 I/O 操作。
(7)QEMU-KVM 相比原生 QEMU 的改动
(1)原生的 QEMU 通过指令翻译实现 CPU 的完全虚拟化,但是修改后的 QEMU-KVM 会调用 ICOTL 命令来调用 KVM 模块。
(2)原生的 QEMU 是单线程实现,QEMU-KVM 是多线程实现。
(8)从客户机线程到物理 CPU 的两次调度
要将客户机内的线程调度到某个物理 CPU,需要经历两个过程:
(1)客户机线程调度到客户机物理CPU 即 KVM vCPU,该调度由客户机操作系统负责,每个客户机操作系统的实现方式不同。在 KVM 上,vCPU 在客户机系统看起来就像是物理 CPU,因此其调度方法也没有什么不同。
(2)vCPU 线程调度到物理 CPU 即主机物理 CPU,该调度由 Hypervisor 即 Linux 负责。
KVM 使用标准的 Linux 进程调度方法来调度 vCPU 进程。Linux 系统中,线程和进程的区别是 进程有独立的内核空间,线程是代码的执行单位,也就是调度的基本单位。Linux 中,线程是就是轻量级的进程,也就是共享了部分资源(地址空间、文件句柄、信号量等等)的进程,所以线程也按照进程的调度方式来进行调度。
此处应该说明Linux 进程调度原理和处理器亲和性(可以设置 vCPU 在指定的物理 CPU 上运行)。
(9)支持的客户机CPU结构和模型
KVM 支持 SMP 和 NUMA 多CPU架构的主机和客户机。对 SMP 类型的客户机,使用 “-smp”参数;对 NUMA 类型的客户机,使用 “-numa”参数。CPU 模型定义了哪些主机的 CPU 功能,会被暴露给客户机操作系统。为了在具有不同 CPU 功能的主机之间做安全的迁移,qemu-kvm 往往不会将主机CPU的所有功能都暴露给客户机。其原理如下:

每个 Hypervisor 都有自己的策略,来定义默认上哪些CPU功能会被暴露给客户机。至于哪些功能会被暴露给客户机系统,取决于客户机的配置。qemu32 和 qemu64 是基本的客户机 CPU 模型,但是还有其他的模型可以使用。你可以使用 qemu-kvm 命令的 -cpu 参数来指定客户机的 CPU 模型,还可以附加指定的 CPU 特性。"-cpu" 会将该指定 CPU 模型的所有功能全部暴露给客户机,即使某些特性在主机的物理CPU上不支持,这时候QEMU/KVM 会模拟这些特性,因此,这时候也许会出现一定的性能下降。
(10)客户机 vCPU 数目的分配方法
(1)不是客户机的 vCPU 越多,其性能就越好,因为线程切换会耗费大量的时间;应该根据负载需要分配最少的 vCPU。
(2)主机上的客户机的 vCPU 总数不应该超过物理 CPU 内核总数。不超过的话,就不存在 CPU 竞争,每个 vCPU 线程在一个物理 CPU 核上被执行;超过的话,会出现部分线程等待 CPU 以及一个 CPU 核上的线程之间的切换,这会有 overhead。
(3)将负载分为计算负载和 I/O 负载,对计算负载,需要分配较多的 vCPU,甚至考虑 CPU 亲和性,将指定的物理 CPU 核分给给这些客户机。
三、内存虚拟化
(1)概念
通过内存虚拟化共享物理系统内存,动态分配给虚拟机。虚拟机的内存虚拟化很像现在的操作系统支持的虚拟内存方式,应用程序看到邻近的内存地址空间,这个地址空间无需和下面的物理机器内存直接对应,操作系统保持着虚拟页到物理页的映射。现在所有的 x86 CPU 都包括了一个称为内存管理的模块MMU(Memory Management Unit)和 TLB(Translation Lookaside Buffer),通过MMU和TLB来优化虚拟内存的性能。KVM 实现客户机内存的方式是,利用mmap系统调用,在QEMU主线程的虚拟地址空间中申明一段连续的大小的空间用于客户机物理内存映射。
(2)VMM内存虚拟化的实现方式
(1)软件方式:通过软件实现内存地址的翻译,比如 Shadow page table (影子页表)技术。
(2)硬件实现:基于 CPU 的辅助虚拟化功能,比如 AMD 的 NPT 和 Intel 的 EPT 技术。
在KVM 中,虚机的物理内存即为 qemu-kvm 进程所占用的内存空间。KVM 使用 CPU 辅助的内存虚拟化方式。在 Intel 和 AMD 平台,其内存虚拟化的实现方式分别为:
(1)AMD 平台上的 NPT (Nested Page Tables) 技术。
(2)Intel 平台上的 EPT (Extended Page Tables)技术。
EPT 和 NPT采用类似的原理,都是作为 CPU 中新的一层,用来将客户机的物理地址翻译为主机的物理地址。EPT的好处是,它的两阶段记忆体转换,特点就是将 Guest Physical Address → System Physical Address,VMM不用再保留一份 SPT (Shadow Page Table),以及以往还得经过 SPT 这个转换过程。除了降低各部虚拟机器在切换时所造成的效能损耗外,硬体指令集也比虚拟化软体处理来得可靠与稳定。
KSM (Kernel SamePage Merging 或者 Kernel Shared Memory)
KSM 在 Linux 2.6.32 版本中被加入到内核中。其原理是,KSM 作为内核中的守护进程(称为 ksmd)存在,它定期执行页面扫描,识别副本页面并合并副本,释放这些页面以供它用。因此,在多个进程中,Linux将内核相似的内存页合并成一个内存页。这个特性,被KVM用来减少多个相似的虚拟机的内存占用,提高内存的使用效率。由于内存是共享的,所以多个虚拟机使用的内存减少了。这个特性,对于虚拟机使用相同镜像和操作系统时,效果更加明显。但是,事情总是有代价的,使用这个特性,都要增加内核开销,用时间换空间。所以为了提高效率,可以将这个特性关闭。其好处是,在运行类似的客户机操作系统时,通过 KSM,可以节约大量的内存,从而可以实现更多的内存超分,运行更多的虚机。
KVM Huge Page Backed Memory (巨页内存技术)
这是KVM虚拟机的又一个优化技术.。Intel 的 x86 CPU 通常使用4Kb内存页,当是经过配置,也能够使用巨页。使用巨页,KVM的虚拟机的页表将使用更少的内存,并且将提高CPU的效率。最高情况下,可以提高20%的效率!
四、IO虚拟化
在 QEMU/KVM 中,客户机可以使用的设备大致可分为三类:
(1)模拟设备:完全由 QEMU 纯软件模拟的设备。
(2)Virtio 设备:实现 VIRTIO API 的半虚拟化设备。
(3)PCI 设备直接分配 (PCI device assignment) 。
(1)全虚拟化 I/O 设备
KVM 在 IO 虚拟化方面,传统或者默认的方式是使用 QEMU 纯软件的方式来模拟 I/O 设备,包括键盘、鼠标、显示器,硬盘 和 网卡 等。模拟设备可能会使用物理的设备,或者使用纯软件来模拟。模拟设备只存在于软件中。

(1)客户机的设备驱动程序发起 I/O 请求操作请求。
(2)KVM 模块中的 I/O 操作捕获代码拦截这次 I/O 请求。
(3)经过处理后将本次 I/O 请求的信息放到 I/O 共享页 (sharing page),并通知用户空间的 QEMU 程序。
(4)QEMU 程序获得 I/O 操作的具体信息之后,交由硬件模拟代码来模拟出本次 I/O 操作。
(5)完成之后,QEMU 将结果放回 I/O 共享页,并通知 KMV 模块中的 I/O 操作捕获代码。
(6)KVM 模块的捕获代码读取 I/O 共享页中的操作结果,并把结果放回客户机。
注意:当客户机通过DMA (Direct Memory Access)访问大块I/O时,QEMU 模拟程序将不会把结果放进共享页中,而是通过内存映射的方式将结果直接写到客户机的内存中,然后通知KVM模块告诉客户机DMA操作已经完成。这种方式的优点是可以模拟出各种各样的硬件设备;其缺点是每次 I/O 操作的路径比较长,需要多次上下文切换,也需要多次数据复制,所以性能较差。
(2)QEMU 模拟网卡的实现
Qemu 纯软件的方式来模拟I/O设备,其中包括经常使用的网卡设备。Guest OS启动命令中没有传入的网络配置时,QEMU默认分配 rtl8139 类型的虚拟网卡类型,使用的是默认用户配置模式,这时候由于没有具体的网络模式的配置,Guest的网络功能是有限的。 全虚拟化情况下,KVM虚机可以选择的网络模式包括:默认用户模式、基于网桥的模式和基于NAT的模式。
网桥模式如下:

(1)网络数据从 Host 上的物理网卡接收,到达网桥。
(2)由于 eth0 与 tap1 均加入网桥中,根据二层转发原则,br0 将数据从 tap1 口转发出去,即数据由 Tap设备接收。
(3)Tap 设备通知对应的 fd 数据可读。
(4)fd 的读动作通过 tap 设备的字符设备驱动将数据拷贝到用户空间,完成数据报文的前端接收。
(3)准虚拟化 (Para-virtualizaiton) I/O 驱动 virtio
在 KVM 中可以使用准虚拟化驱动来提供客户机的I/O 性能。目前 KVM 采用的的是 virtio 这个 Linux 上的设备驱动标准框架,它提供了一种 Host 与 Guest 交互的 IO 框架。KVM/QEMU 的 vitio 实现采用在 Guest OS 内核中安装前端驱动 (Front-end driver)和在 QEMU 中实现后端驱动(Back-end)的方式。前后端驱动通过 vring 直接通信,这就绕过了经过 KVM 内核模块的过程,达到提高 I/O 性能的目的。纯软件模拟的设备和 Virtio 设备的区别:virtio 省去了纯模拟模式下的异常捕获环节,Guest OS 可以和 QEMU 的 I/O 模块直接通信。Host 数据发到 Guest,KVM 通过中断的方式通知 QEMU 去获取数据,放到 virtio queue 中,KVM 再通知 Guest 去 virtio queue 中取数据。

Virtio 在 Linux 中的实现
Virtio 是在半虚拟化管理程序中的一组通用模拟设备的抽象。这种设计允许管理程序通过一个应用编程接口 (API)对外提供一组通用模拟设备。通过使用半虚拟化管理程序,客户机实现一套通用的接口,来配合后面的一套后端设备模拟。后端驱动不必是通用的,只要它们实现了前端所需的行为。因此,Virtio 是一个在 Hypervisor 之上的抽象API接口,让客户机知道自己运行在虚拟化环境中,进而根据 virtio 标准与 Hypervisor 协作,从而客户机达到更好的性能。
(1)前端驱动:客户机中安装的驱动程序模块。
(2)后端驱动:在 QEMU 中实现,调用主机上的物理设备,或者完全由软件实现。
(3)virtio 层:虚拟队列接口,从概念上连接前端驱动和后端驱动。驱动可以根据需要使用不同数目的队列。比如 virtio-net 使用两个队列,virtio-block只使用一个队列。该队列是虚拟的,实际上是使用 virtio-ring 来实现的。
(4)virtio-ring:实现虚拟队列的环形缓冲区。
Linux 内核中实现的五个前端驱动程序
(1)块设备(如磁盘)
(2)网络设备
(3)PCI 设备
(4)气球驱动程序(动态管理客户机内存使用情况)
(5)控制台驱动程序
使用 virtio 设备 (以 virtio-net 为例)
Guest OS 中,在不使用 virtio 设备的时候,这些驱动不会被加载。只有在使用某个 virtio 设备的时候,对应的驱动才会被加载。每个前端驱动器具有在管理程序中的相应的后端的驱动程序。以 virtio-net 为例,解释其原理:
(1)多个虚机共享主机网卡 eth0。
(2)QEMU 使用标准的 tun/tap 将虚机的网络桥接到主机网卡上。
(3)每个虚机看起来有一个直接连接到主机PCI总线上的私有 virtio 网络设备。
(4)需要在虚机里面安装 virtio驱动。
总结 Virtio 的优缺点:更高的IO性能,几乎可以和原生系统差不多。客户机必须安装特定的 virtio 驱动。一些老的 Linux 还没有驱动支持,一些 Windows 需要安装特定的驱动。不过,较新的和主流的OS都有驱动可以下载了。Linux 2.6.24+ 都默认支持 virtio。可以使用 lsmod | grep virtio 查看是否已经加载。
vhost-net (kernel-level virtio server)
前面提到 virtio 在宿主机中的后端处理程序(backend)一般是由用户空间的QEMU提供的,然而如果对于网络 I/O 请求的后端处理能够在在内核空间来完成,则效率会更高,会提高网络吞吐量和减少网络延迟。在比较新的内核中有一个叫做 “vhost-net” 的驱动模块,它是作为一个内核级别的后端处理程序,将virtio-net的后端处理任务放到内核空间中执行,减少内核空间到用户空间的切换,从而提高效率。
vhost-net 的要求:qemu-kvm-0.13.0 或者以上,主机内核中设置 CONFIG_VHOST_NET=y 和在虚机操作系统内核中设置 CONFIG_PCI_MSI=y (Red Hat Enterprise Linux 6.1 开始支持该特性),在客户机内使用 virtion-net 前段驱动,在主机内使用网桥模式,并且启动 vhost_net。
一般来说,使用 vhost-net 作为后端处理驱动可以提高网络的性能。不过,对于一些网络负载类型使用 vhost-net 作为后端,却可能使其性能不升反降。特别是从宿主机到其中的客户机之间的UDP流量,如果客户机处理接受数据的速度比宿主机发送的速度要慢,这时就容易出现性能下降。在这种情况下,使用vhost-net将会是UDP socket的接受缓冲区更快地溢出,从而导致更多的数据包丢失。故这种情况下,不使用vhost-net,让传输速度稍微慢一点,反而会提高整体的性能。使用 qemu-kvm 命令行,加上“vhost=off”(或没有vhost选项)就会不使用vhost-net,而在使用libvirt时,需要对客户机的配置的XML文件中的网络配置部分进行如下的配置,指定后端驱动的名称为“qemu”(而不是“vhost”)。
virtio-balloon
另一个比较特殊的 virtio 设备是 virtio-balloon。通常来说,要改变客户机所占用的宿主机内存,要先关闭客户机,修改启动时的内存配置,然后重启客户机才可以实现。而 内存的 ballooning (气球)技术可以在客户机运行时动态地调整它所占用的宿主机内存资源,而不需要关闭客户机。该技术能够:当宿主机内存紧张时,可以请求客户机回收利用已分配给客户机的部分内存,客户机就会释放部分空闲内存。若其内存空间不足,可能还会回收部分使用中的内存,可能会将部分内存换到交换分区中。当客户机内存不足时,也可以让客户机的内存气球压缩,释放出内存气球中的部分内存,让客户机使用更多的内存。目前很多的VMM,包括 KVM, Xen,VMware 等都对 ballooning 技术提供支持。其中,KVM 中的 Ballooning 是通过宿主机和客户机协同来实现的,在宿主机中应该使用 2.6.27 及以上版本的 Linux内核(包括KVM模块),使用较新的 qemu-kvm(如0.13版本以上),在客户机中也使用 2.6.27 及以上内核且将“CONFIG_VIRTIO_BALLOON”配置为模块或编译到内核。在很多Linux发行版中都已经配置有“CONFIG_VIRTIO_BALLOON=m”,所以用较新的Linux作为客户机系统,一般不需要额外配置virtio_balloon驱动,使用默认内核配置即可。
(1)KVM 发送请求给 VM 让其归还一定数量的内存给KVM。
(2)VM 的 virtio_balloon 驱动接到该请求。
(3)VM 的驱动是客户机的内存气球膨胀,气球中的内存就不能被客户机使用。
(4)VM 的操作系统归还气球中的内存给VMM
(5)KVM 可以将得到的内存分配到任何需要的地方。
(6)KVM 也可以将内存返还到客户机中。
优势和不足:ballooning 可以被控制和监控,对内存的调节很灵活,可多可少。KVM 可以归还内存给客户机,从而缓解其内存压力。需要客户机安装驱动。大量内存被回收时,会降低客户机的性能。目前没有方便的自动化的机制来管理 ballooning,一般都在 QEMU 的 monitor 中执行命令来实现。内存的动态增加或者减少,可能是内存被过度碎片化,从而降低内存使用性能。在QEMU monitor中,提供了两个命令查看和设置客户机内存的大小。
(qemu) info balloon #查看客户机内存占用量(Balloon信息)
(qemu) balloon num #设置客户机内存占用量为numMBRedHat 的 多队列 Virtio (multi-queue)
目前的高端服务器都有多个处理器,虚拟使用的虚拟CPU数目也不断增加。默认的 virtio-net 不能并行地传送或者接收网络包,因为 virtio_net 只有一个TX 和 RX 队列。而多队列 virtio-net 提供了一个随着虚机的虚拟CPU增加而增强网络性能的方法,通过使得 virtio 可以同时使用多个 virt-queue 队列。它在以下情况下具有明显优势:
(1)网络流量非常大。
(2)虚机同时有非常多的网络连接,包括虚拟机之间的、虚机到主机的、虚机到外部系统的等。
(3)virtio 队列的数目和虚机的虚拟CPU数目相同。这是因为多队列能够使得一个队列独占一个虚拟CPU。
注意:对队列 virtio-net 对流入的网络流工作得非常好,但是对外发的数据流偶尔会降低性能。打开对队列 virtio 会增加中的吞吐量,这相应地会增加CPU的负担。 在实际的生产环境中需要做必须的测试后才确定是否使用。
五、I/O 设备直接分配和 SR-IOV
本文将分析 PCI/PCIe 设备直接分配(Pass-through)和 SR-IOV, 以及三种 I/O 虚拟化方式的比较。
(1)PCI/PCI-E 设备直接分配给虚机 (PCI Pass-through)
设备直接分配 (Device assignment)也称为 Device Pass-Through。PCI/PCIe Pass-through 原理如下:
这种方式,允许将宿主机中的物理 PCI 设备直接分配给客户机使用。较新的x86平台已经支持这种类型,Intel 定义的 I/O 虚拟化技术成为 VT-d,AMD 的称为 AMD-V。KVM 支持客户机以独占方式访问这个宿主机的 PCI/PCI-E 设备。通过硬件支持的 VT-d 技术将设备分给客户机后,在客户机看来,设备是物理上连接在PCI或者PCI-E总线上的,客户机对该设备的I/O交互操作和实际的物理设备操作完全一样,不需要或者很少需要 KVM 的参与。运行在 VT-d 平台上的 QEMU/KVM,可以分配网卡、磁盘控制器、USB控制器、VGA 显卡等设备供客户机直接使用。几乎所有的 PCI 和 PCI-E 设备都支持直接分配,除了显卡以外,PCI Pass-through 需要硬件平台 Intel VT-d 或者 AMD IOMMU 的支持。这些特性必须在 BIOS 中被启用。Red Hat Enterprise Linux 6.0 及以上版本支持热插拔的 PCI 设备直接分配到虚拟机。一般 SATA 或者 SAS 等类型的硬盘的控制器都是直接接入到 PCI 或者 PCI-E 总线的,所以也可以将硬盘作为普通的PCI设备直接分配个客户机。需要注意的是,当分配硬盘时,实际上将其控制器作为一个整体分配到客户机中,因此需要在硬件平台上至少有另两个或者多个SATA或者 SAS控制器。
(2)设备直接分配让客户机的优势和不足
在执行 I/O 操作时大量减少甚至避免 VM-Exit 陷入到 Hypervisor 中,极大地提高了性能,可以达到几乎和原生系统一样的性能。VT-d 克服了 virtio 兼容性不好和 CPU 使用频率较高的问题。一台服务器主板上的空间比较有限,因此允许添加的 PCI 和 PCI-E 设备是有限的。大量使用 VT-d 独立分配设备给客户机,让硬件设备数量增加,这会增加硬件投资成本。对于使用 VT-d 直接分配了设备的客户机,其动态迁移功能将受限,不过也可以使用热插拔或者libvirt 工具等方式来缓解这个问题。
(3)针对设备直接分配给客户机的不足提出的解决方案
在一台物理宿主机上,仅少数 I/O 如网络性能要求较高的客户机使用 VT-d直接分配设备,其他的使用纯模拟或者 virtio 已达到多个客户机共享同一个设备的目的。对于网络I/O的解决办法,可以选择 SR-IOV 是一个网卡产生多个独立的虚拟网卡,将每个虚拟网卡分配个一个客户机使用。
(4)SR-IOV 设备分配
VT-d 的性能非常好,但是它的物理设备只能分配给一个客户机使用。为了实现多个虚机共享一个物理设备,并且达到直接分配的目的,PCI-SIG 组织发布了 SR-IOV (Single Root I/O Virtualization and sharing) 规范,它定义了一个标准化的机制用以原生地支持实现多个客户机共享一个设备。不过,目前 SR-IOV (单根 I/O 虚拟化)最广泛地应用还是网卡上。SR-IOV 使得一个单一的功能单元(比如,一个以太网端口)能看起来像多个独立的物理设备。一个带有 SR-IOV 功能的物理设备能被配置为多个功能单元。SR-IOV 使用两种功能(function):
(1)物理功能(Physical Functions,PF):这是完整的带有 SR-IOV 能力的PCIe 设备。PF 能像普通 PCI 设备那样被发现、管理和配置。
(2)虚拟功能(Virtual Functions,VF):简单的 PCIe 功能,它只能处理I/O。每个 VF 都是从 PF 中分离出来的。每个物理硬件都有一个 VF 数目的限制。一个 PF,能被虚拟成多个 VF 用于分配给多个虚拟机。
Hypervisor 能将一个或者多个 VF 分配给一个虚机。在某一时刻,一个 VF 只能被分配给一个虚机。一个虚机可以拥有多个 VF。在虚机的操作系统看来,一个 VF 网卡看起来和一个普通网卡没有区别。SR-IOV 驱动是在内核中实现的。
(5)SR-IOV 的条件
(1)需要 CPU 支持 Intel VT-x 和 VT-D (或者 AMD 的 SVM 和 IOMMU)
(2)需要有支持 SR-IOV 规范的设备:目前这种设备较多,比如Intel的很多中高端网卡等。
(3)需要 QEMU/KAM 的支持。
六、Libvirt
(1)为什么需要Libvirt?
(1)Hypervisor 比如 qemu-kvm 的命令行虚拟机管理工具参数众多,难于使用。
(2)Hypervisor 种类众多,没有统一的编程接口来管理它们,这对云环境来说非常重要。
(3)没有统一的方式来方便地定义虚拟机相关的各种可管理对象。
(2)Libvirt提供了什么?
(1)它提供统一、稳定、开放的源代码的应用程序接口(API)、守护进程 (libvirtd)和和一个默认命令行管理工具(virsh)。
(2)它提供了对虚拟化客户机和它的虚拟化设备、网络和存储的管理。
(3)它提供了一套较为稳定的C语言应用程序接口。目前,在其他一些流行的编程语言中也提供了对libvirt的绑定,在Python、Perl、Java、Ruby、PHP、OCaml等高级编程语言中已经有libvirt的程序库可以直接使用。
(4)它对多种不同的 Hypervisor 的支持是通过一种基于驱动程序的架构来实现的。libvirt 对不同的 Hypervisor 提供了不同的驱动,包括 Xen 的驱动,对QEMU/KVM 有 QEMU 驱动,VMware 驱动等。在 libvirt 源代码中,可以很容易找到 qemu_driver.c、xen_driver.c、xenapi_driver.c、vmware_driver.c、vbox_driver.c 这样的驱动程序源代码文件。
(5)它作为中间适配层,让底层 Hypervisor 对上层用户空间的管理工具是可以做到完全透明的,因为 libvirt 屏蔽了底层各种 Hypervisor 的细节,为上层管理工具提供了一个统一的、较稳定的接口(API)。
(6)它使用 XML 来定义各种虚拟机相关的受管理对象。
目前,libvirt 已经成为使用最为广泛的对各种虚拟机进行管理的工具和应用程序接口(API),而且一些常用的虚拟机管理工具(如virsh、virt-install、virt-manager等)和云计算框架平台(如OpenStack、OpenNebula、Eucalyptus等)都在底层使用libvirt的应用程序接口。
七、QEMU/KVM 快照
磁盘快照:磁盘的内容(可能是虚机的全部磁盘或者部分磁盘)在某个时间点上被保存,然后可以被恢复。在一个运行着的系统上,一个磁盘快照很可能只是崩溃一致的(crash-consistent) 而不是完整一致(clean)的,也是说它所保存的磁盘状态可能相当于机器突然掉电时硬盘数据的状态,机器重启后需要通过 fsck 或者别的工具来恢复到完整一致的状态(类似于 Windows 机器在断电后会执行文件检查)。对一个非运行中的虚机来说,如果上次虚机关闭的时候磁盘是完整一致的,那么其被快照的磁盘快照也将是完整一致的。磁盘快照有两种:内部快照 - 使用单个的 qcow2 的文件来保存快照和快照之后的改动。这种快照是 libvirt 的默认行为,现在的支持很完善(创建、回滚和删除),但是只能针对 qcow2 格式的磁盘镜像文件,而且其过程较慢等。外部快照 - 快照是一个只读文件,快照之后的修改是另一个 qcow2 文件中。外置快照可以针对各种格式的磁盘镜像文件。外置快照的结果是形成一个 qcow2 文件链:original <- snap1 <- snap2 <- snap3。
内存状态(或者虚机状态):只是保持内存和虚机使用的其它资源的状态。如果虚机状态快照在做和恢复之间磁盘没有被修改,那么虚机将保持一个持续的状态;如果被修改了,那么很可能导致数据corruption。
系统还原点(system checkpoint):虚机的所有磁盘的快照和内存状态快照的集合,可用于恢复完整的系统状态(类似于系统休眠)。
关于 崩溃一致(crash-consistent)的附加说明:应该尽量避免在虚机I/O繁忙的时候做快照。这种时候做快照不是可取的办法。vmware 的做法是装一个 tools,它是个 PV driver,可以在做快照的时候挂起系统。似乎 KVM 也有类似的实现 QEMU Guest Agent,但是还不是很成熟。
八、虚拟机迁移
(1)使用 libvirt 迁移 QEMU/KVM 虚机和 Nova 虚机
迁移(migration)包括系统整体的迁移和某个工作负载的迁移。系统整理迁移,是将系统上所有软件包括操作系统完全复制到另一个物理机硬件机器上。虚拟化环境中的迁移,可分为静态迁移(static migration,或者 冷迁移 cold migration,或者离线迁移 offline migration) 和 动态迁移 (live migration,或者 热迁移 hot migration 或者 在线迁移 online migration)。静态迁移和动态迁移的最大区别是,静态迁移有明显一段时间客户机中的服务不可用,而动态迁移则没有明显的服务暂停时间。虚拟化环境中的静态迁移也可以分为两种,一种是关闭客户机后,将其硬盘镜像复制到另一台宿主机上然后恢复启动起来,这种迁移不能保留客户机中运行的工作负载;另一种是两台宿主机共享存储系统,这时候的迁移可以保持客户机迁移前的内存状态和系统运行的工作负载。 动态迁移,是指在保证客户机上应用服务正常运行的同时,让客户机在不同的宿主机之间进行迁移,其逻辑步骤和前面的静态迁移几乎一致,有硬盘存储和内存都复制的动态迁移,也有仅复制内存镜像的动态迁移。不同的是,为了保证迁移过程中客户机服务的可用性,迁移过程只能有非常短暂的停机时间。动态迁移允许系统管理员将客户机在不同物理机上迁移,同时不会断开访问客户机中服务的客户端或者应用程序的连接。一个成功的迁移,需要保证客户机的内存、硬盘存储和网络连接在迁移到目的主机后任然保持不变,而且迁移的过程的服务暂停时间较短。
(2)迁移效率的衡量
(1)整体迁移时间
(2)服务器停机时间:这时间是指源主机上的客户机已经暂停服务,而目的主机上客户机尚未恢复服务的时间。
(3)对服务性能的影响:客户机迁移前后性能的影响,以及目的主机上其它服务的性能影响。
其中,整体迁移时间受很多因素的影响,比如 Hypervisor 和迁移工具的种类、磁盘存储的大小(是否需要复制磁盘镜像)、内存大小及使用率、CPU 的性能和利用率、网络带宽大小及是否拥塞等,整体迁移时间一般分为几秒钟到几十分钟不等。动态迁移的服务停机时间,也有这些因素的影响,往往在几毫秒到几百毫秒。而静态迁移,其暂停时间较长。因此,静态迁移一般适合于对服务可用性要求不高的场景,而动态迁移适合于对可用性要求高的场景。
动态迁移的应用场景包括:负载均衡、解除硬件依赖、节约能源 和异地迁移。
(3)KVM 迁移的原理
对于静态迁移,你可以在宿主机上某客户机的 QEMU monitor 中,用 savevm my_tag 命令保存一个完整的客户机镜像快照,然后在宿主机中关闭或者暂停该客户机,然后将该客户机的镜像文件复制到另一台宿主机中,使用在源主机中启动该客户机时的命令来启动复制过来的镜像,在其 QEMU monitor 中 loadvm my_tag 命令恢复刚才保存的快照即可完全加载保存快照时的客户机状态。savevm 命令可以保证完整的客户机状态,包括 CPU 状态、内存、设备状态、可写磁盘中的内存等。注意,这种方式需要 qcow2、qed 等格式的磁盘镜像文件的支持。
如果源宿主机和目的宿主机共享存储系统,则只需要通过网络发送客户机的 vCPU 执行状态、内存中的内容、虚机设备的状态到目的主机上。否则,还需要将客户机的磁盘存储发到目的主机上。共享存储系统指的是源和目的虚机的镜像文件目录是在一个共享的存储上的。
在基于共享存储系统时,KVM 动态迁移的具体过程为:
(1)迁移开始时,客户机依然在宿主机上运行,与此同时,客户机的内存页被传输到目的主机上。
(2)QEMU/KVM 会监控并记录下迁移过程中所有已被传输的内存页的任何修改,并在所有内存页都传输完成后即开始传输在前面过程中内存页的更改内容。
(3)QEMU/KVM 会估计迁移过程中的传输速度,当剩余的内存数据量能够在一个可以设定的时间周期(默认 30 毫秒)内传输完成时,QEMU/KVM 会关闭源宿主机上的客户机,再将剩余的数据量传输到目的主机上,最后传输过来的内存内容在目的宿主机上恢复客户机的运行状态。
(4)至此,KVM 的动态迁移操作就完成了。迁移后的客户机尽可能与迁移前一直,除非目的主机上缺少一些配置,比如网桥等。
注意,当客户机中内存使用率非常大而且修改频繁时,内存中数据不断被修改的速度大于KVM能够传输的内存速度时,动态迁移的过程是完成不了的,这时候只能静态迁移。
(4)OpenStack Nova QEMU/KVM 实例动态迁移的环境配置
除了直接拷贝磁盘镜像文件的冷迁移,OpenStack 还支持下面几种虚机热迁移模式:
(1)不使用共享存储时的块实时迁移(Block live migration without shared storage)。这种模式不支持使用只读设备比如 CD-ROM 和 Config Drive。块实时迁移不需要 nova compute 节点都使用共享存储。它使用 TCP 来将虚机的镜像文件通过网络拷贝到目的主机上,因此和共享存储式的实时迁移相比,这种方式需要更长的时间。而且在迁移过程中,主机的性能包括网络和 CPU 会下降。
(2)基于共享存储的实时迁移 (Shared storage based live migration):两个主机可以访问共享的存储。
(3)从卷启动的虚机的实时迁移(Volume backed VM live migration)。这种迁移也是一种块拷贝迁移。