MySQL性能优化(三)--MySQL索引详细介绍(干货满满)
索引的含义:它是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对性能的影响就愈发重要。
1.数据表索引的目的?
- 索引就是为表建立的”目录”
- 索引的目录就是为了全表扫描(Full scan)
- 索引的存储形式是由存储引擎决定
2.MySQL数据库索引分类
根据索引的具体用途,MySQL 中的索引在逻辑上分为以下几类
2.1 按具体用途分类
2.1.1 普通索引
最基本的索引,它没有任何限制,用于加快查询
创建方法:
CREATE INDEX index_name ON table(column(length))
例如我创建的测试表test_table来演示一下创建普通索引
CREATE INDEX name_index ON test_table(name)
创建完毕查看一下:

2.1.2 唯一索引
与前面的普通索引类似,不同的是索引列的值必须唯一,但允许有空值,如果是组合索引,则列值的组合必须唯一。
创建方法:
CREATE UNIQUE INDEX indexName ON table(column(length))
例如:CREATE UNIQUE INDEX age_index on test_table(age)
查看索引:

2.1.3 主键索引
是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值,一般建表的时候同时创建主键索引。
如:CREATE TABLE `table` ( `id` int(11) NOT NULL AUTO_INCREMENT , `title` char(255) NOT NULL , PRIMARY KEY (`id`) );
2.1.4 组合索引
指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用,使用组合索引时遵循最左前缀集合
如:CREATE INDEX index_mytable_id_name ON mytable(id,name);
CREATE INDEX zh_index on test_table(age,name)
只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用,使用组合索引时遵循最左前缀集合,这一句话的意思是组合索引有效的化,查询时条件一定要加示例中第一个字段也就是age而且还必须是第一个条件,这样就是优先最左有效
2.1.5 全文索引
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。Fulltext索引跟其他索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配 ,fulltext索引配合match against操作使用,而不是一般的where语句加like。它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多。
创建方法:
CREATE FULLTEXT INDEX index_content ON article(content)
例如测试数据:CREATE FULLTEXT INDEX name_fulltext on test_table(name)

2.2 按存储方式物理分类
索引的类型和存储引擎有关,每种存储引擎所支持的索引类型不一定完全相同。根据存储方式的不同,MySQL 中常用的索引在物理上分为以下两类
- B+TREE索引 – 适用于范围查找
- Hash索引 – 适用于精确匹配
总结一下:
- 从存储结构上来划分:
1.1 BTree索引(B-Tree或B+Tree索引),hash索引(为每一行数据精准的建立数字指纹(hash值))通过hash值可以快速的找到数据
1.2 full-index 全文索引
1.3 R-Tree索引(多维索引,应用少,通常是用在Gis系统中)
- 从应用层次来分:普通索引,唯一索引(必须某一列是唯一值,比如主键索引,唯一索引效率高),复合索引(就是多列索引)
- 根据数据的物理是顺序和键值的逻辑(索引)顺序关系:聚集索引,非聚集索引
3. B+Tree索引
- Mysql中InnoDB与Myisam采用的是B+Tree索引
- B+Tree索引采用树形链表结构建立数据“目录” (不同的存储引擎有不同的存储结构,索引也是要占用磁盘内存的。
3.1 InnoDB引擎B+Tree索引原理
3.1.1 InnoDB引擎B+Tree索引-主键索引
主键索引含义:主键索引也叫聚簇索引是指主索引文件和数据文件为同一文件,聚簇索引主要用在Innodb存储引擎中。在该索引实现方式中B+Tree的叶子节点上的data就是数据本身,key为主键。在 InnoDB 里,索引B+ Tree的叶子节点存储了整行数据的是主键索引

按图说话:
- 首先有一个根节点,居中的基础范围,其次,二级和三级节点上按照顺序依次排列
- 是聚集索引,物理存储就是1在前,7在后
- 并且在三级节点有一个单向链表,比较适合查询
主键索引叶子节点存储的是数据,所以查询一次就能查询到,查询效果比较好
3.1.2 InnoDB引擎B+Tree索引-复合主键

InnoDB还是会以主键为物理存储
如果除了主键以外又设置了name为索引的话,那么节点就会是name名称,但是name只是会往id上靠,要查询也是查询名称,找name,根据name对应的id再找id索引下的数据。
3.2 为什么官方建议使用自增长主键作为索引?
- 在InnoDB使用主键,新增数据范围影响是最小的
- BTree索引是按照数据顺序进行排列的,新添加进来的数据会找到最后一块范围然后新增数据,然后在把局部修改。
3.3 MyISAM引擎B+Tree索引原理
MyISAM索引使用的是非聚簇索引,非聚簇索引的含义:非聚簇索引就是指B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址。也可以说B+Tree的叶子节点存储了主键的值是非聚簇索引。
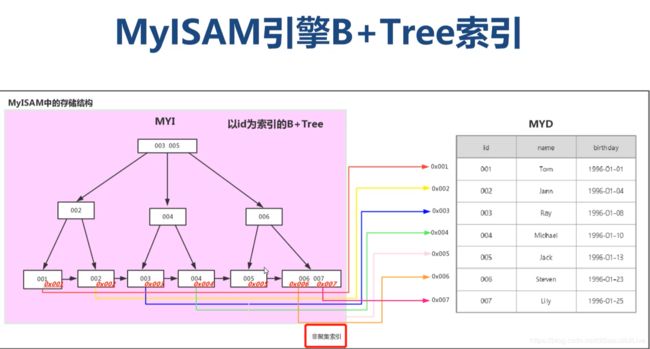
- MyISAM索引是非聚集索引,实际保存数据和索引组织顺序是不一致的
- 从索引的角度来说MyISAMB+Tree和InnoDB结构是完全一致的,不同的是InnoDB是以id号存储的,MyISAM是以磁盘存储物理地址位置来进行组织
- 非主键索引的叶子节点存储的是主键的值,查到主键的值以后,还需要再通过主键的值需要回表再进行一次查询
这里再次引申一个问题,非聚簇索引是所有的情况都查询多次么?
答:其实不是的,当非聚簇索引是覆盖索引的就可以查询一次。
那再引申一个问题,什么是覆盖索引呢?
答:覆盖索引是指一个查询语句的执行只用从索引中就能取得,不必从数据表中读取,也可以称之为实现了索引覆盖。当一条 查询语句符合覆盖索引条件时,MySQL只需要通过索引就可以返回查询所需要的数据,这样避免了查到索引后再返回表操作, 减少I/O提高效率。
如:表covering_index_sample中有一个普通索引 idx_key1_key2(key1,key2)。当我们通过SQL语句:select key2 from covering_index_sample where key1 ='keytest';的时候,就可以通过覆盖索引查询,无需回表。
3.4 B-Tree/B+Tree的区别
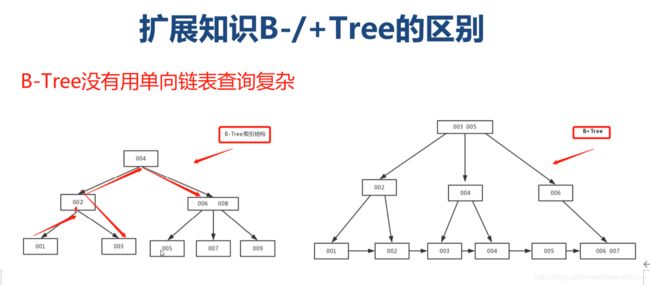
3.5 BTree索引使用技巧
- 查询语句的时候可以使用 EXPLAIN 查看sql执行的情况,执行快慢都可以看见,例如:EXPLAIN select * from innodb_test1 where id=1 ,实践证明,加了索引查询速度快

- 看一下没有加索引的结果,type为all,没有索引rows也变大了
EXPLAIN select * from innodb_test1 where uid=22

- 精准匹配,允许使用btree索引 如:where uid=22
- 范围匹配允许使用btree索引 如:where uid >1 and uid <3
- 建议使用字符相符的类型进行查询,虽然可以进行类型转换
- 字符串字段btree索引允许进行前缀查询 如 where name=”张三%”
- 字符串后缀和模糊匹配btree均不支持,直接进行了全表扫描。
- 复合索引查询都是以第一个左侧设置的字段索引为主
- 复合索引查询条件必须包含左侧列,直接书写右侧列将导致数据无法使用索引进行查询,除非左侧列和右侧列一起查询
- <> 和not in 也会导致不使用索引
4.hash索引介绍
- Hash索引(hash index)基于哈希表实现(为每一条数据创建hash值,用简短的hash值代替数据,方便用来检索这样的方式)
- 只有在对数据进行精准匹配才可以使用hash索引
- Hash索引为每条数据生成一个hashCode(这个hashcode就像摘要,通过hashCode能够快速获得数据位置)

4.1 hash索引特点
- Hash索引只包含哈希值和行索引
- 只支持精准匹配,不支持范围查询,模糊查询以及排序
- Hash取值速度非常快,但索引选择性很低,不建议使用
- MySQL目前只有Memory显示支持hash索引
4.2 InnoDB中的hash索引
- InnoDB存储引擎只支持显示创建BTree索引
- 数据精准匹配时,MySQL会自动生成HashCode,,存入缓存
3.6 索引的缺点
1. 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行insert、update、和delete。因为更新表时,不仅要保存数据,还要保存索引文件。
2. 建立索引会占用磁盘空间的索引文件,一般这个问题不太严重,但如果你在大表创建了多种组合索引,索引文件会增长很快。
索引只是提高效率的一个因素,如果有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。
3.7 索引的优点
- 索引大幅度提升了数据的检索效率
- 索引把随机IO,变成了顺序IO
3.8 索引是不是越多越好?
- 降低了写入数据的效率
- 太多的索引增加了查询优化器选择的时间
- 不合理的使用索引,会大幅占用磁盘空间
3.9 索引的优化策略
3.9.1 删除冗余索引
如果过多的索引,内存磁盘占用上就比较大,新增也要有重算消耗,那么有一种工具可以帮助删除冗余索引
- pt-duplicate-key-checker是percona-toolkit工具包中的实用组件(percona-toolkit只能在linux平台)
- 它可以帮助你检测表中重复的索引或者主键
3.9.2 实用索引SQL语句
#索引使用情况
SELECT
object_type,object_schema,object_name,index_name,
count_read,count_fetch, count_insert,
count_update,count_delete
FROM
performance_schema.table_io_waits_summary_by_index_usage
ORDER BY
sum_timer_wait desc;
得到的结果如下图:

3.9.3 减少表与索引碎片
在数据进行新增,修改,删除时数据会进行重组,那么就有可能出现空间的浪费,出现碎片。
- analyze table 表名; 对于索引进行优化,索引重新统计
- optimize table 表名;对于表进行优化,优化表空间,释放表空间,运行就会去掉表空间冗余的数据,运行optimize table会进行锁表,一定要在维护期间,否则会造成ip阻塞,数据量大执行时间就会长
4.10 什么情况下不会用到索引
- 索引选择性太差
- <>/not in 无法使用索引
- Is null 会使用索引,is not null 不会使用索引
- Where子句跳过左侧索引列,直接查询右侧索引字段
- 对索引列进行计算或者使用函数
4.11 使用索引优化排序
- 当order by 字段与索引字段顺序/排序方向相同时索引可优化排序速度
以上就是MySQL索引介绍的全部内容!希望能够帮助你!下次有时间还会整理Explain执行计划怎么看SQL语句性能的介绍!