本文基于Spark2.1.0、Kafka 0.10.2、Scala 2.11.8版本
背景:
Kafka做为一款流行的分布式发布订阅消息系统,以高吞吐、低延时、高可靠的特点著称,已经成为Spark Streaming常用的流数据来源。
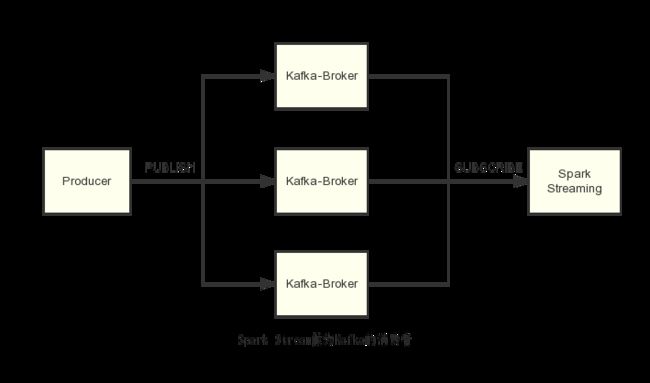
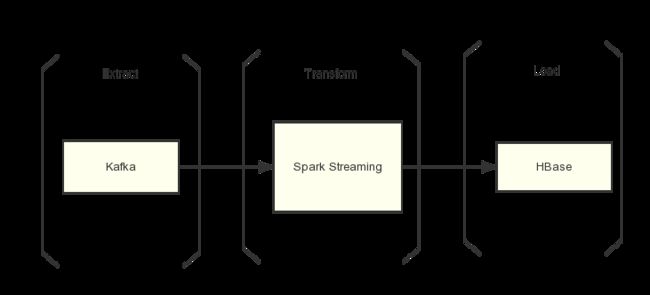
1,Kafka Topic的消费保证:
流数据,顾名思义,就是无界的、流动的、快速的、连续到达的数据序列,所以它不像可靠的文件系统(如HDFS)在计算出现故障时,可以随时恢复数据来重新计算。
那么,如何保证流数据可靠的传递呢?我们先了解下面的概念:
Producer通过Broker传递消息给Consumer,Consumer消费消息,
P-B-C 3者之间的传输,主要有以下几种可能的场景:
At most once(最多传输一次): 消息可能会丢,但绝不会重复传输;
At least one (至少传输一次): 消息绝不会丢,但可能会重复传输;
Exactly once(精确传输一次): 每条消息肯定会被传输一次且仅传输一次,不会重复.
3种场景,适合不同生产环境的需要,相关介绍网上很多,这里就不多说了。
本文的重点是,如何用Spark 2.1.0、Kafka 0.10.2、spark-streaming-kafka-0-10_2.11-2.1.0.jar、HBase 1.3.0来配合实现消息Exactly once(精确一次)的传递和消费。网上相关的scala或者java代码,都是基于老版本的API,目前没有发现基于new Kafka consumer API的实现,所以看到本文觉得有收获的同学,就给点个赞吧。
2,Kafka 0.10.2版本介绍:
Kafka 0.10.2版本,为了和Zookeeper的解耦,较之前的版本有了很大的变化,老版本的高级API和简单API的说法不见了,取而代之的是New Consumer API及New Consumer Configs,相关接口的参数及P-B-C 3者的配置参数有了很多改动。
Spark官方与之配合的工具包spark-streaming-kafka-0-10_2.11-2.1.0.jar 也做了相应的改变,取消了KafkaCluster类、取消了ZkUtils.updatePersistentPath等多个方法,也都是为了不在将Topic offset由zookeeper自动保存,而由用户灵活的选择Kafka和Spark 2.1.0官方提供的几种方法来保存offset,最好的使用情况下,端到端的业务可以达到精确一次的消费保证。
(为了美观,本文相关的java代码都用贴图方式展现了,最终实现的端到端精确一次消费消息的源码见文末的链接)
3,Kafka官方提供的多种消费保证:
Consumer的3个重要的配置,需要配合使用,来达到Broker到Consumer之间精确一次的消费保证。


请看这些参数的组合(有点绕,请仔细看)
(enable.auto.commit:false) + (auto.offset.reset:earliest):
在Broker到Consumer之间实现了至少一次语义,因为不使用Kafka提供的自动保存offset功能,每次应用程序启动时,都是从Topic的初始位置来获取消息。也就是说,应用程序因为故障失败,或者是人为的停止,再次启动应用程序时,都会从初始位置把指定的Topic所有的消息都消费一遍,这就导致了Consumer会重复消费。
(enable.auto.commit:false) + (auto.offset.reset:latest):
在Broker到Consumer之间实现了至多一次语义,因为不使用Kafka提供的自动保存offset功能,每次应用程序启动时,都是从Topic的末尾位置来获取消息。也就是说,应用程序因为故障失败,或者是人为的停止后,如果Producer向Broker发送新的消息,当再次启动应用程序时,Consumer从指定的Topic的末尾来开始消费,这就导致了这部分新产生的消息丢失。
(enable.auto.commit:true)+(auto.offset.reset:earliest)+(auto.commit.interval.ms) :
在Broker到Consumer之间实现了精确一次语义,因为使用了Kafka提供的自动保存offset功能,当应用程序第一次启动时,首先从Topic的初试位置来获取消息,原有的消息一个都没有丢失;紧接着,在auto.commit.interval.ms时间后,Kafka会使用coordinator协议commit当前的offset(topic的每个分区的offset)。当应用程序因为故障失败,或者是人为的停止,再次启动应用程序时,都会从coordinator模块获取Topic的offset,从上一次消费结束的位置继续消费,所以不会重复消费已经消费过的消息,也不会丢失在应用程序停止期间新产生的消息,做到了Broker到Consumer之间精确一次的传递。
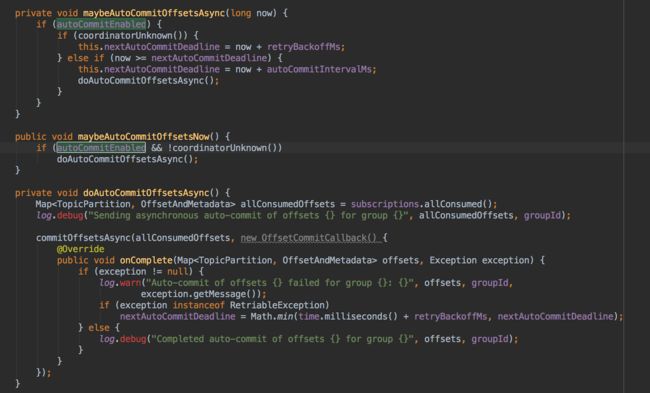
下面是Kafka 0.10.2 ConsumerCoordinator.java的源码片段,用户配置enable.auto.commit:true对应的代码是autoCommitEnabled为true,最终调用doAutoCommitOffsetsAsync,使用coordinator协议保存offset(注意,最新版本已经和zookeeper解耦,不会把offset保存在zookeeper中,所以通过zkCli.sh是看不到相关topic的)
下面是实现的Spark Streaming代码。
当然,这还远远不够,因为这样的方式,会出现业务两段性的后果:
1,读完消息先commit再处理消息。这种模式下,如果consumer在commit后还没来得及处理消息就crash了,下次重新开始工作后就无法读到刚刚已提交而未处理的消息,这就对应于At most once;
2,读完消息先处理再commit。这种模式下,如果处理完了消息在commit之前consumer crash了,下次重新开始工作时还会处理刚刚未commit的消息,实际上该消息已经被处理过了。这就对应于At least once。
所以,要想实现端到端消息的精确一次消费,还需要耐心往后看。
3,Spark官方提供的多种消费保证:(基于spark-streaming-kafka-0-10_2.11-2.1.0.jar,相比前一个版本有很多改变)
CheckPoint:
通过设置Driver程序的checkpoint,来保存topic offset。这种方法很简单,但是缺陷也很大:应用程序有改变时,无法使用原来的checkpoint来恢复offset;只能满足Broker到Consumer之间精确一次的传递。
当应用程序第一次启动时,首先从Topic的初试位置来获取消息,原有的消息一个都没有丢失;紧接着,在batch时间到达后,Spark会使用checkpoint保存当前的offset(topic的每个分区的offset)。当应用程序失败或者人为停止后,再次启动应用程序时,都会从checkpoint恢复Topic的offset,从上一次消费结束的位置继续消费,所以不会重复消费已经消费过的消息,也不会丢失在应用程序停止期间新产生的消息。
实现的Spark Streaming代码如下(注意:Spark 1.6.3之后,检查checkpoint的实现已经不在用JavaStreamingContextFactory工厂操作了,请细看我的代码是怎么做的)
Kafka itself:
和前面提到的enable.auto.commit:true异曲同工,不过这里用commitAsync方法异步的把offset提交给Kafka 。当应用程序第一次启动时,首先从Topic的初试位置来获取消息,原有的消息一个都没有丢失;紧接着,用commitAsync方法异步的把offset提交给Kafka(topic的每个分区的offset)。当应用程序失败或者人为停止后,再次启动应用程序时,都会从kafka恢复Topic的offset,从上一次消费结束的位置继续消费,所以不会重复消费已经消费过的消息,也不会丢失在应用程序停止期间新产生的消息。
与checkpoint相比,应用程序代码的更改不会影响offset的存储和获取。然而,这样的操作不是事务性的,由于是异步提交offset,当提交offset过程中应用程序crash,则无法保存正确的offset,会导致消息丢失或者重复消费。
实现的Spark Streaming代码如下:
Your own data store:(当当当当,好戏出场)
如果要做到消息端到端的Exactly once消费,就需要事务性的处理offset和实际操作的输出。
经典的做法让offset和操作输出存在同一个地方,会更简洁和通用。比如,consumer把最新的offset和加工后的数据一起写到HBase中,那就可以保证数据的输出和offset的更新要么都成功,要么都失败,间接实现事务性,最终做到消息的端到端的精确一次消费。(新版本的官网中只字未提使用Zookeeper保存offset,是有多嫌弃)
实现的Spark Streaming代码如下(ConsumerRecord类不能序列化,使用时要注意,不要分发该类到其他工作节点上,避免错误打印)
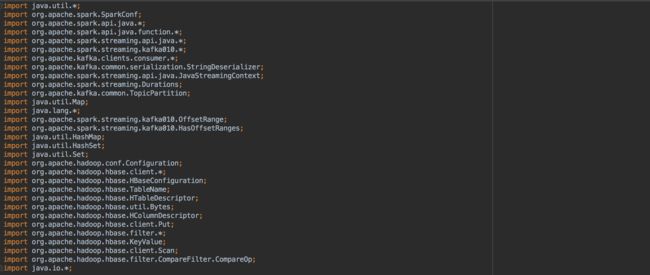
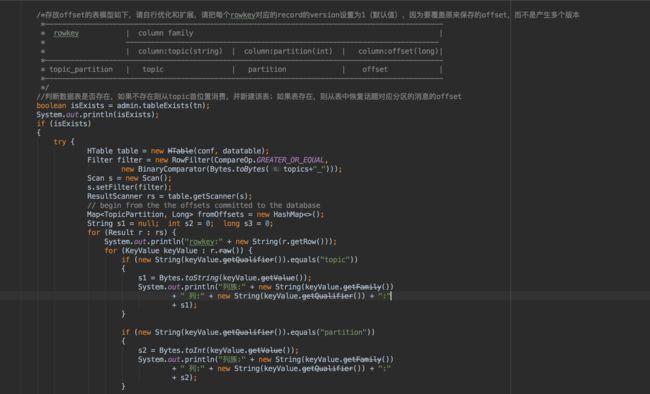
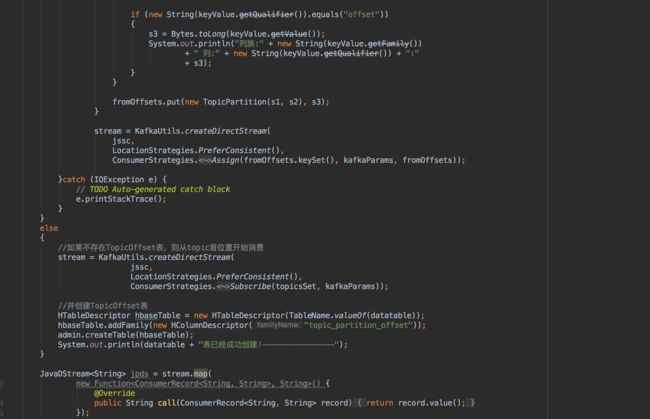
其实说白了,官方提供的思路就是,把JavaInputDStream转换为OffsetRange对象,该对象具有topic对应的分区的所有信息,每次batch处理完,Spark Streaming都会自动更新该对象,所以你只需要找个合适的地方保存该对象(比如HBase、HDFS),就可以愉快的操纵offset了。
4,相关链接
本文实现的精确一次消费的Java源代码
Spark Streaming + Kafka Integration Guide (Kafka broker version 0.10.0 or higher)
Kafka 0.10.2 Documentation
(如需转载,请标明作者和出处)