本文是阅读李沐教程的理解,教程地址https://github.com/mli/gluon-tutorials-zh/blob/master/chapter_computer-vision/ssd.md,视频地址https://discuss.gluon.ai/t/topic/2421/34
先大概阐述ssd的流程, 再后面的内容详细解释每一个模块的作用
总体过程
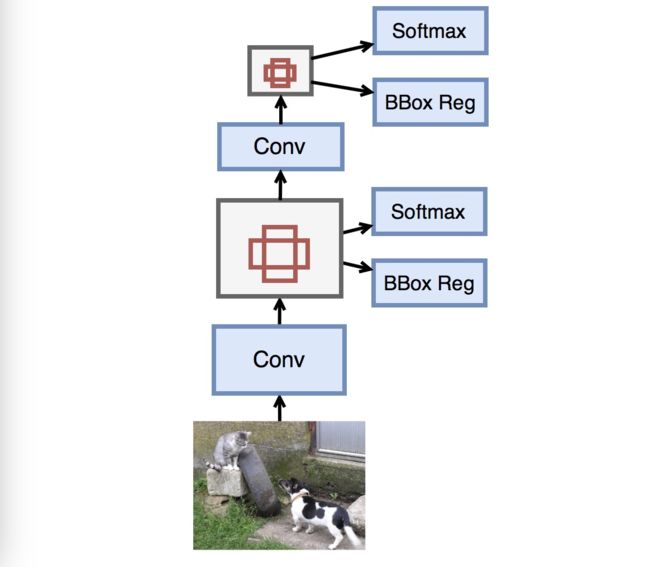
输入图片->Conv抽取特征->用抽取的特征生成anchors->对每一个anchor预测分类->对每一个anchor预测框对位置->降采样特征继续重复生成anchor并做预测
过程详解
一下对内容和原文顺序上对应,对于比较容易理解对直接copy一个标题
获取数据
from mxnet import gluon
root_url = ('https://apache-mxnet.s3-accelerate.amazonaws.com/'
'gluon/dataset/pikachu/')
data_dir = '../data/pikachu/'
dataset = {'train.rec': 'e6bcb6ffba1ac04ff8a9b1115e650af56ee969c8',
'train.idx': 'dcf7318b2602c06428b9988470c731621716c393',
'val.rec': 'd6c33f799b4d058e82f2cb5bd9a976f69d72d520'}
for k, v in dataset.items():
gluon.utils.download(root_url+k, data_dir+k, sha1_hash=v)
读取数据
from mxnet import image
from mxnet import nd
data_shape = 256
batch_size = 32
rgb_mean = nd.array([123, 117, 104])
def get_iterators(data_shape, batch_size):
class_names = ['pikachu']
num_class = len(class_names)
train_iter = image.ImageDetIter(
batch_size=batch_size,
data_shape=(3, data_shape, data_shape),
path_imgrec=data_dir+'train.rec',
path_imgidx=data_dir+'train.idx',
shuffle=True,
mean=True,
rand_crop=1,
min_object_covered=0.95,
max_attempts=200)
val_iter = image.ImageDetIter(
batch_size=batch_size,
data_shape=(3, data_shape, data_shape),
path_imgrec=data_dir+'val.rec',
shuffle=False,
mean=True)
return train_iter, val_iter, class_names, num_class
train_data, test_data, class_names, num_class = get_iterators(
data_shape, batch_size)
print train_data, test_data
print class_names, num_class
Gluon中使用的batch = train_data.next()获取的包含数据和label,batch[0]才是一个批次的图片数据,而且还没有batch[1]数据,只有下标为0的数据
图示数据
生成锚框
使用MultiBoxPrior类生成锚框,输入参数分别是输入特征向量,锚框对大小和比例,假设每个像素生成size为n, 比例为m对锚框,每个像素点将生成m+n-1个框,这样做对目的是减少框对数量,选取典型
from mxnet import nd
from mxnet.contrib.ndarray import MultiBoxPrior
# shape: batch x channel x height x weight
n = 40
x = nd.random.uniform(shape=(1, 3, n, n))
y = MultiBoxPrior(x, sizes=[.5,.25,.1], ratios=[1,2,.5])
print y.shape
boxes = y.reshape((n, n, -1, 4))
print(boxes.shape)
# The first anchor box centered on (20, 20)
# its format is (x_min, y_min, x_max, y_max)
print boxes[20, 20, 0, :]
上面代码中生成了(3+3-1)4040=8000个框, 这里所谓的每个像素我的理解是在channel维度对等位置的所有点共同构成一个像素,在预测与downsample后预测的代码可以看见,输入321282020,生成的框的个数是(size-1)(ratio-1)2020
预测物体类别
from mxnet.gluon import nn
def class_predictor(num_anchors, num_classes):
"""return a layer to predict classes"""
return nn.Conv2D(num_anchors * (num_classes + 1), 3, padding=1)
cls_pred = class_predictor(5, 10)
cls_pred.initialize()
x = nd.zeros((2, 3, 20, 20))
y = cls_pred(x)
y.shape
对于第n个输入,比如232020的图片,第(i, j)像素置信值在Y[n, : , i, j]里, 通道数是不同anchor和类别的对应,第(i, j)像素的置信值仍然在输出的(i, j)位置,但是不同anchor和anchor里面的类别反应在不同的通道上面,比如以(i, j)为中心的第a个锚框,输出中a(num_class+1)~a(num_class+1)+1+b代表了 它的置信值,其中b偏移通道代表了锚框包含第b类物体;总的来说,一个输入的特征,做了类别预测的卷积后,它将占有输出(num_class+1)anchors个通道,第(i,j)像素是由输入的所有通道的(i,j)共同组成的
预测边界框
同类别预测一样,输入第(i,j)像素的anchor对应的框信息将反应在输出某4个通道上, 假设输出是Y,那么对应输入中第 n 个样本的第 (i,j) 像素为中心的锚框的转换在Y[n,:,i,j]里。具体来说,对于第a个锚框,它的变换在a4到a4+3通道里
def box_predictor(num_anchors):
"""return a layer to predict delta locations"""
return nn.Conv2D(num_anchors * 4, 3, padding=1)
box_pred = box_predictor(10)
box_pred.initialize()
x = nd.zeros((2, 3, 20, 20))
y = box_pred(x)
y.shape
减半模块
主体网络抽取特征后多次预测,每次减半
def down_sample(num_filters):
"""stack two Conv-BatchNorm-Relu blocks and then a pooling layer
to halve the feature size"""
out = nn.HybridSequential()
for _ in range(2):
out.add(nn.Conv2D(num_filters, 3, strides=1, padding=1))
out.add(nn.BatchNorm(in_channels=num_filters))
out.add(nn.Activation('relu'))
out.add(nn.MaxPool2D(2))
return out
blk = down_sample(10)
blk.initialize()
x = nd.zeros((2, 3, 20, 20))
y = blk(x)
y.shape
计算预测
def toy_ssd_forward(x, model, sizes, ratios, verbose=False):
body, downsamplers, class_predictors, box_predictors = model
anchors, class_preds, box_preds = [], [], []#每个feature map都会生成很多个anchors
# feature extraction
x = body(x)
for i in range(5):
# predict
anchors.append(MultiBoxPrior(
x, sizes=sizes[i], ratios=ratios[i]))
class_preds.append(
flatten_prediction(class_predictors[i](x)))
box_preds.append(
flatten_prediction(box_predictors[i](x)))
if verbose:
print('Predict scale', i, x.shape, 'with',
anchors[-1].shape[1], 'anchors')
# down sample
if i < 3:
x = downsamplers[i](x)#downsample了又接着做类和框的预测是怎么体现的?x就没有下文了?
elif i == 3:
x = nd.Pooling(
x, global_pool=True, pool_type='max',
kernel=(x.shape[2], x.shape[3]))
# concat date
print('at last anchor shape', anchors[-2].shape)
print('class preds shape', class_preds[-1].shape)
print('box prediction shape', class_preds[-1].shape)
return (concat_predictions(anchors),
concat_predictions(class_preds),
concat_predictions(box_preds))
一次前向计算,anchors还是三维的不变,将class_preds和box_preds都flatten成二维的,class_preds会在整体forward之后reshape成3维,最后一维是num_class+1代表被分类的信息
from mxnet import gluon
class ToySSD(gluon.Block):
def __init__(self, num_classes, verbose=False, **kwargs):
super(ToySSD, self).__init__(**kwargs)
# anchor box sizes and ratios for 5 feature scales
self.sizes = [[.2,.272], [.37,.447], [.54,.619],
[.71,.79], [.88,.961]]
self.ratios = [[1,2,.5]]*5
self.num_classes = num_classes
self.verbose = verbose
num_anchors = len(self.sizes[0]) + len(self.ratios[0]) - 1
# use name_scope to guard the names
with self.name_scope():
self.model = toy_ssd_model(num_anchors, num_classes)
def forward(self, x):
anchors, class_preds, box_preds = toy_ssd_forward(
x, self.model, self.sizes, self.ratios,
verbose=self.verbose)
# it is better to have class predictions reshaped for softmax computation
class_preds = class_preds.reshape(shape=(0, -1, self.num_classes+1))
return anchors, class_preds, box_preds
以下面这段代码举例
net = ToySSD(num_classes=2, verbose=True)
net.initialize()
x = batch.data[0][0:1]
print('Input:', x.shape)
anchors, class_preds, box_preds = net(x)
#anchors.shape
print('Output achors:', anchors.shape)#问题,这个地方anchors怎么变成了正常的形状, 之前不是reshape成了二位的了吗
print('Output class predictions:', class_preds.shape)
print('Output box predictions:', box_preds.shape)
输出:
('Input:', (1L, 3L, 256L, 256L))
('Predict scale', 0, (1L, 64L, 32L, 32L), 'with', 4096L, 'anchors')
('Predict scale', 1, (1L, 128L, 16L, 16L), 'with', 1024L, 'anchors')
('Predict scale', 2, (1L, 128L, 8L, 8L), 'with', 256L, 'anchors')
('Predict scale', 3, (1L, 128L, 4L, 4L), 'with', 64L, 'anchors')
('Predict scale', 4, (1L, 128L, 1L, 1L), 'with', 4L, 'anchors')
('Output achors:', (1L, 5444L, 4L))
('Output class predictions:', (1L, 5444L, 3L))
('Output box predictions:', (1L, 21776L))
告诉系统样本有两类,那么输出加上背景将会有3类,一共推荐了5444个框,每个框用一个四维向量表示->(1,5444,4),每个框对于每一个类有一个置信度->(1,5444,3),这个变成类3维是reshape了, 每个框的分类信息->(1,21776)=(1,5444*4)
MultiBoxTarget类的作用
from mxnet.contrib.ndarray import MultiBoxTarget
def training_targets(anchors, class_preds, labels):
class_preds = class_preds.transpose(axes=(0,2,1))#形状换个位置
print(class_preds.shape)
return MultiBoxTarget(anchors, labels, class_preds)
out = training_targets(anchors, class_preds, batch.label[0][0:1])
print ('first',out[0].shape)
print ('second', out[1].shape)
print ('second', out[2].shape)
out
输出:
(1L, 3L, 5444L)
('first', (1L, 21776L))
('second', (1L, 21776L))
('second', (1L, 5444L))
[
[[ 0. 0. 0. ..., 0. 0. 0.]]
,
[[ 0. 0. 0. ..., 0. 0. 0.]]
,
[[ 0. 0. 0. ..., 0. 0. 0.]]
]
输入推荐的框,类的预测类别,还有训练数据的真正标签,具体形状见上一步依次是三维的包含了位置信息的anchors, 三维的包含了类别信息的class_preds,标准标签,输出三个:
1 预测的边框跟真实边框的偏移,大小是batch_size x (num_anchors*4)
2 用来遮掩不需要的负类锚框的掩码,大小跟上面一致
3 锚框的真实的标号,大小是batch_size x num_anchors
一共5444个框,乘以坐标信息所以是21776,第三个输出是锚框的信息,输出的是该锚框具体属于哪一类,从输出看,大部分是0,也就是负类,所以这个MultiBoxTarget已经对三维的class_predict特征做了分类,并最终把它分为了某一类
输入为数据集中第一张图片和其对应的label, 这里每张图片都只有一个label,label三维,第一维batch size, 第二维一张图片有多少个label,第三维包含坐标和分类; 输出三个:预测的边框和真实的边框的偏移,只有被选出来的锚框和真实边框的偏移;mask,被预测为负类的值为0, 其他的为1;没一个框的分类
在第一张图片和其对应的label输出中,一共推荐出了16个候选框,因此box_target张量中只有16个有四个一组组成的偏移张量,bbox_mask与上面对应的位置为1, 其他都为0, bbox_class对应上面张量的位置被分类,由于这个实验只有一个分类,所以box_mask和box_class才会一模一样,也就是关于分类的label信息,一个数字,被broadcast了,只是负类的那些框所对应的分类被置成0
class FocalLoss(gluon.loss.Loss):
def __init__(self, axis=-1, alpha=0.25, gamma=2, batch_axis=0, **kwargs):
super(FocalLoss, self).__init__(None, batch_axis, **kwargs)
self._axis = axis
self._alpha = alpha
self._gamma = gamma
def hybrid_forward(self, F, output, label):
output = F.softmax(output)
print ('class_preds softmax shape', output.shape)
print ('label shape', label.shape)
print ('self axis', self._axis)
print ('input 0:8', output[0][0:8][:])
print ('label 0:8', label[0][0:8])
pj = output.pick(label, axis=self._axis, keepdims=True)
print ('pj 0:8', pj[0][0:8])
#print ('pj', pj)
#print ('pj shape', pj.shape)
loss = - self._alpha * ((1 - pj) ** self._gamma) * pj.log()
return loss.mean(axis=self._batch_axis, exclude=True)
cls_loss = FocalLoss()
cls_loss
[[ 0.43306479 0.56693518]
[ 0.64298385 0.35701618]
[ 0.40293515 0.59706485]
[ 0.75093931 0.24906068]
[ 0.53080744 0.46919253]
[ 0.94422591 0.0557741 ]
[ 0.4179053 0.58209473]
[ 0.72441477 0.27558523]]
)
('label 0:8',
[ 0. 0. 0. 0. 0. 0. 0. 0.]
)
('pj 0:8',
[[ 0.43306479]
[ 0.64298385]
[ 0.40293515]
[ 0.75093931]
[ 0.53080744]
[ 0.94422591]
[ 0.4179053 ]
[ 0.72441477]]
)
输入loss的数据经过softmax的形状(1, 5444, 2),pick函数的作用是把具体正类别正确分类的概率取出,如上代码显示,选取了前八个框的分类概率结果,由于label都是0负类,所以左边一列被选出,每个框正确预测的概率传给交叉商损失函数,再对所有框算出来的概率求均值返回。pj中,j是真实的类别,pj就是和label对比,这个anchor的类别被预测正确的概率,也就是把前向传播正确预测的那一个概率值拿出来,在进过一次卷进和reshape后,class_preds变成batch_size x anchor_num x (num_class+1), anchors和class_pred丢进MultiBoxTarget产生class_target, class_preds和class_targets做交叉熵损失
class SmoothL1Loss(gluon.loss.Loss):
def __init__(self, batch_axis=0, **kwargs):
super(SmoothL1Loss, self).__init__(None, batch_axis, **kwargs)
def hybrid_forward(self, F, output, label, mask):
print ('output shape', output.shape)
print ('label shape', label.shape)
print ('mask shape', mask.shape)
loss = F.smooth_l1((output - label) * mask, scalar=1.0)
import numpy
numpy.set_printoptions(threshold='nan')
print ('loss before', loss, 'loss shape before', loss.shape)
loss = loss.mean(self._batch_axis, exclude=True)
print ('loss shape', loss.shape)
print ('loss', loss)
return loss
box_loss = SmoothL1Loss()
box_loss
L1的作用是把前向计算出来的框和label的框做距离计算,通过anchors选出与label IOU比较高的一些候选框,然后将候选框与label框做deatle得到box_target, 训练的时候就是要让box_target与box_pred比较,做loss的时候用box_pred和box_target做比较,最后一个anchor和一个box_pred得到一个框
yolo最后的softmax使用全联接,没有利用空间信息,比较复杂,bound box预测的是绝对位置信息,不像ssd bound box预测的是相对位置
yolo2把每个训练数据的真实边框做聚类,k-means