2月19 基于深度学习的车道线检测
基于深度学习的车道线检测
相比于haugh方法,DL方法性能提升角度:
- ROI区域的选择
- 图像处理过程的参数
- 处理速度(Haugh变换可能只有4.5-6帧/秒,要想实时,只能丢帧近似处理)

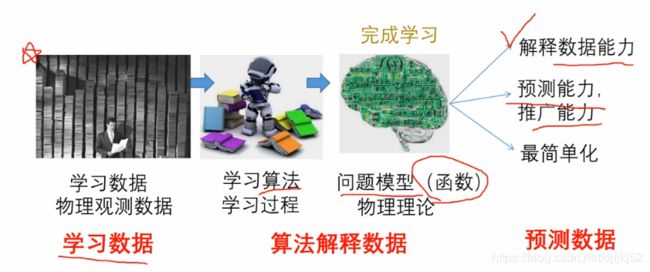


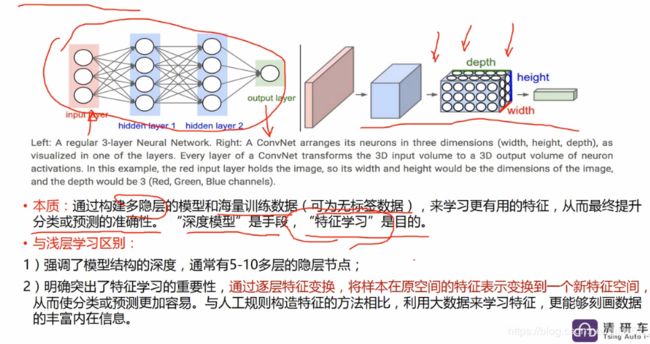
机器学习的子类——深度学习
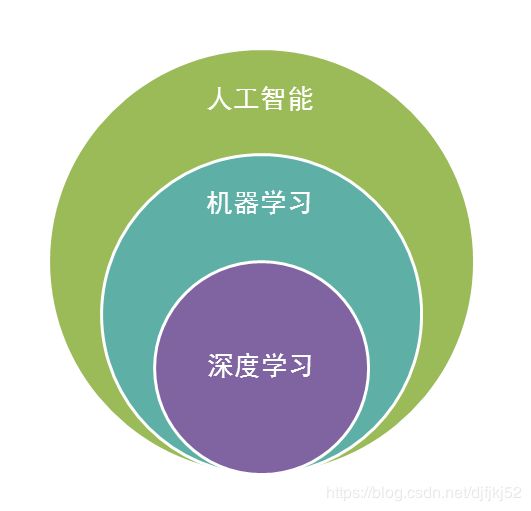
近来,机器学习的发展产生了一个新的方向,即“深度学习”。
深度学习,就是传统的神经网联发展到了多隐藏层的情况。
2006年,Geoffrey Hinton在科学杂志《Science》上发表了一篇文章,论证了两个观点:
1.多隐层的神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻画,从而有利于可视化或分类;
2.深度神经网络在训练上的难度,可以通过“逐层初始化” 来有效克服。

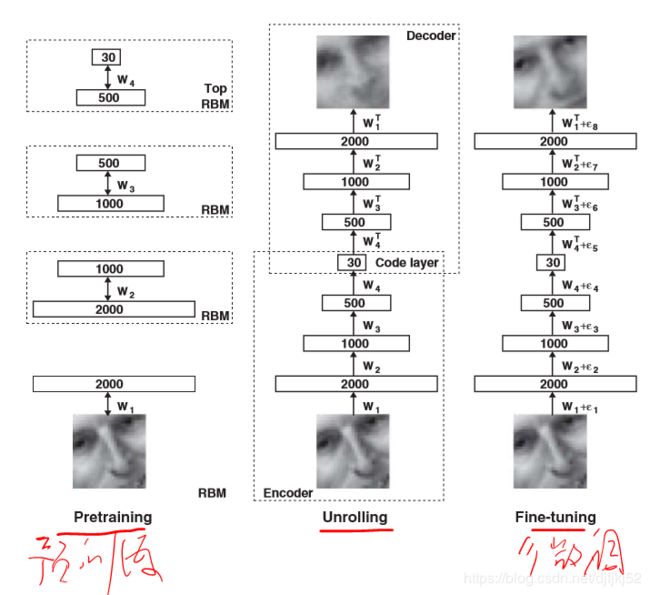
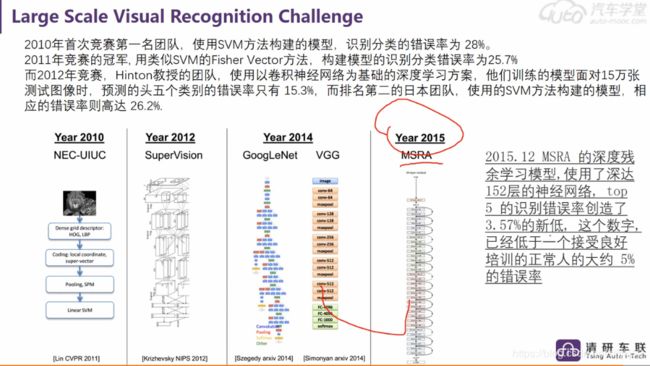



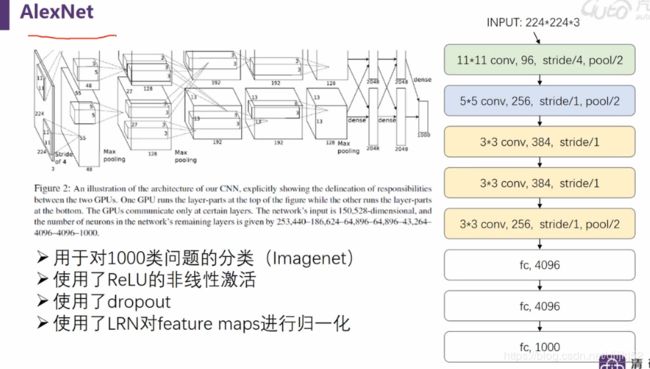
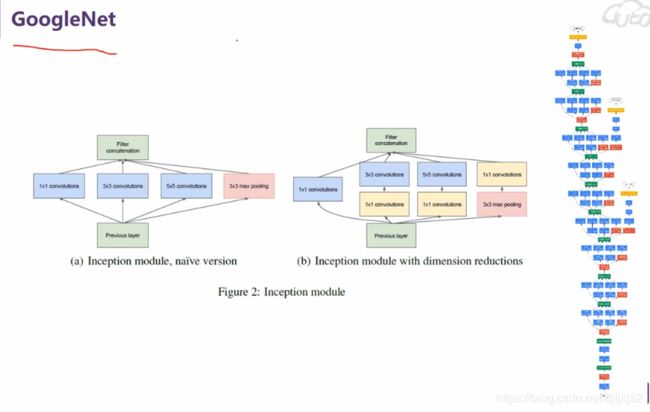
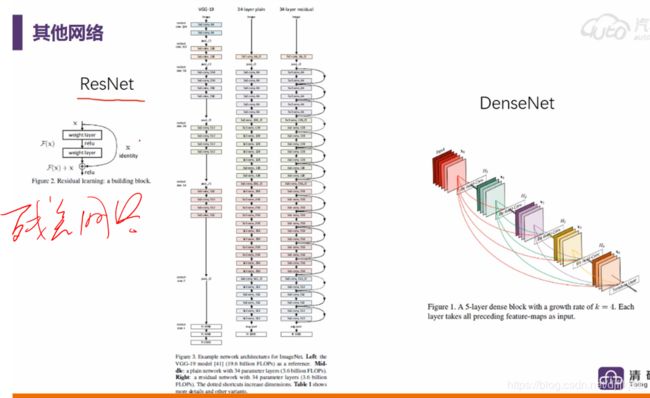
CNN、RCNN、YOLO等和Alexnet、VGG等的关系?
CNN是深度学习应用在CV领域的基础单元;
AlexNet、VGG这些模型都是基于CNN单元构建起来的,本来是用来训练图像分类任务的,比如ImageNet,但是在训练完分类任务后,这些模型的中间输出,可以理解为表达了图像的特征,能应用在其他任务中;
比如目标检测,RCNN系列、YOLO等都是利用了训练好的图像分类模型,利用它们提取的特征,再做下一步的工作;
链接:https://www.zhihu.com/question/67490422/answer/392236590
CNN一般是指一个网络里面含有大量的卷积层,你可以把常见的层(卷积、全连接等)理解为积木,网络就是这些积木搭起来的。
Lenet、Alexnet、Googlenet、VGG等模型是用于分类任务的,说其为经典是当时在那个年代,跑ILSVRC比赛,结果很好,不断刷新记录,而且里面的一些搭积木的方法也很值得学习,
之后又发现使用一些预训练好的权重来初始化网络比随机初始化好,所以这些预训练的模型一般作为现在的初始化套路。
RCNN、fastRCNN、fasterRCNN、YOLO、SSD、YOLOv2是用于检测任务的。
RCNN-> fastRCNN -> fasterRCNN 是two-stage的方法;YOLO->YOLOv2->YOLOV3, SSD是one-stage的方法。你说的RCNN的经典方法是two-stage的方法,以fasterRCNN为代表,还有很多都是基于此类方法去改善的,如Light-head RCNN
链接:https://www.zhihu.com/question/67490422/answer/523298840
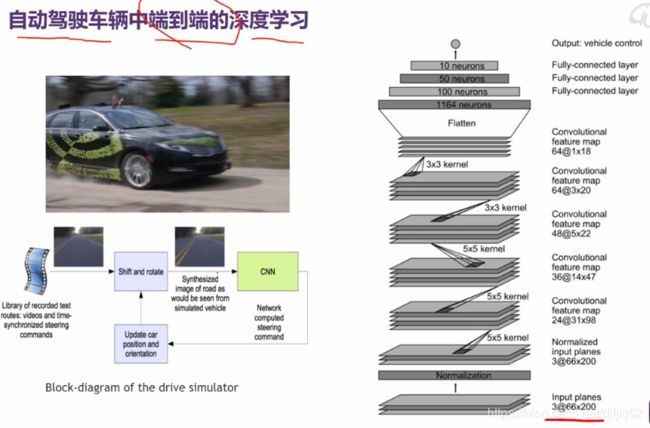
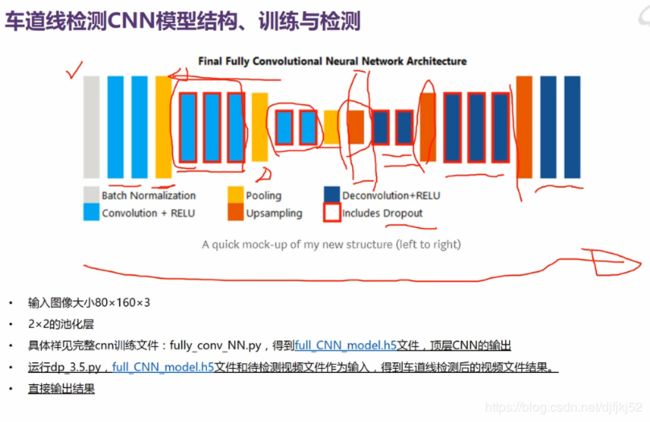
深度学习的车道线






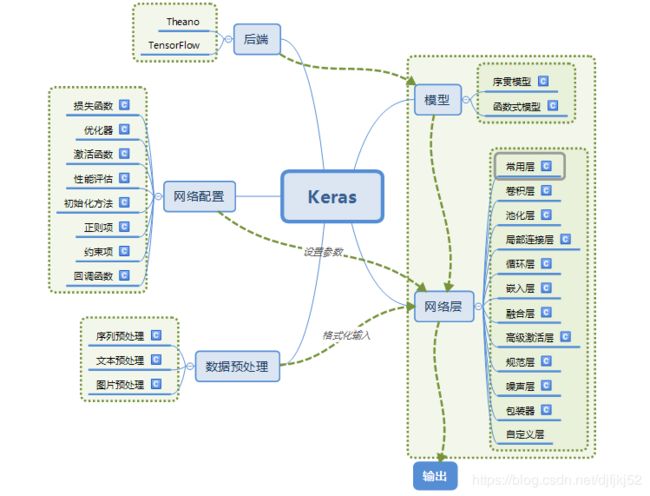
Keras的模块结构
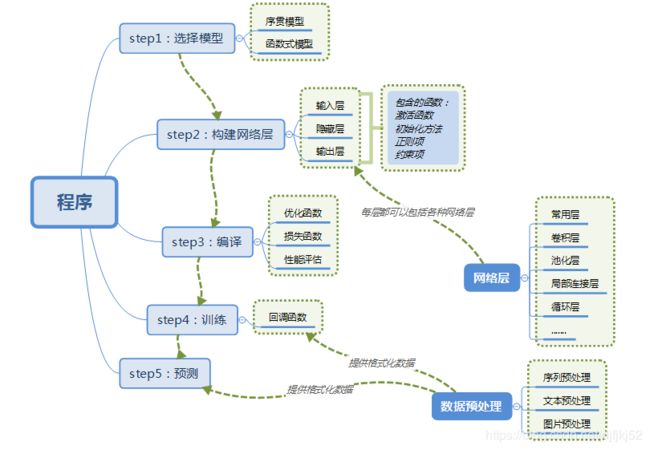
使用Keras搭建一个神经网络
主要概念
1)符号计算
Keras的底层库使用Theano或TensorFlow,这两个库也称为Keras的后端。无论是Theano还是TensorFlow,都是一个“符号式”的库。符号计算首先定义各种变量,然后建立一个“计算图”,计算图规定了各个变量之间的计算关系。
符号计算也叫数据流图,其过程如下(数据是按图中黑色带箭头的线流动的):
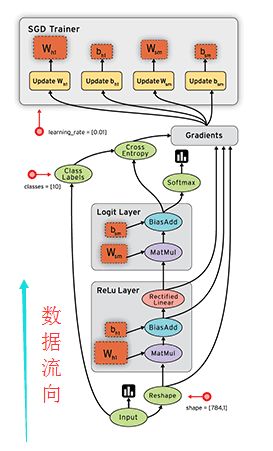
2)张量
张量(tensor),可以看作是向量、矩阵的自然推广,用来表示广泛的数据类型。张量的阶数也叫维度。
0阶张量,即标量,是一个数。
1阶张量,即向量,一组有序排列的数
2阶张量,即矩阵,一组向量有序的排列起来
3阶张量,即立方体,一组矩阵上下排列起来
4阶张量......
依次类推
重点:关于维度的理解
假如有一个10长度的列表,那么我们横向看有10个数字,也可以叫做10维度,纵向看只能看到1个数字,那么就叫1维度。注意这个区别有助于理解Keras或者神经网络中计算时出现的维度问题。
3)数据格式(data_format)
目前主要有两种方式来表示张量:
a) th模式或channels_first模式,Theano和caffe使用此模式。
b)tf模式或channels_last模式,TensorFlow使用此模式。
下面举例说明两种模式的区别:
对于100张RGB3通道的16×32(高为16宽为32)彩色图,
th表示方式:(100,3,16,32)
tf表示方式:(100,16,32,3)
唯一的区别就是表示通道个数3的位置不一样。
4)模型
Keras有两种类型的模型,序贯模型(Sequential)和函数式模型(Model),函数式模型应用更为广泛,序贯模型是函数式模型的一种特殊情况。
a)序贯模型(Sequential):单输入单输出,一条路通到底,层与层之间只有相邻关系,没有跨层连接。这种模型编译速度快,操作也比较简单
b)函数式模型(Model):多输入多输出,层与层之间任意连接。这种模型编译速度慢。

Keras是由纯python编写的基于theano/tensorflow的深度学习框架。





代码
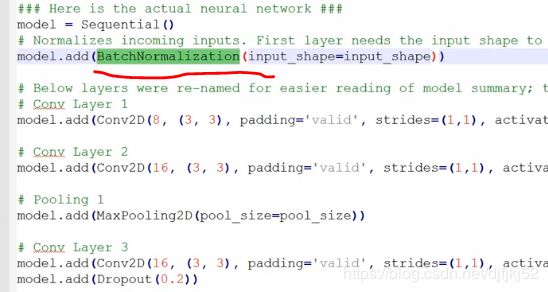

### Here is the actual neural network ###
model = Sequential()
# Normalizes incoming inputs. First layer needs the input shape to work
model.add(BatchNormalization(input_shape=input_shape))
'''
BatchNormalization论文可以阅读
'''
# Below layers were re-named for easier reading of model summary; this not necessary
# Conv Layer 1
model.add(Conv2D(8, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Conv1'))
...
### End of network ###
Debug 过程
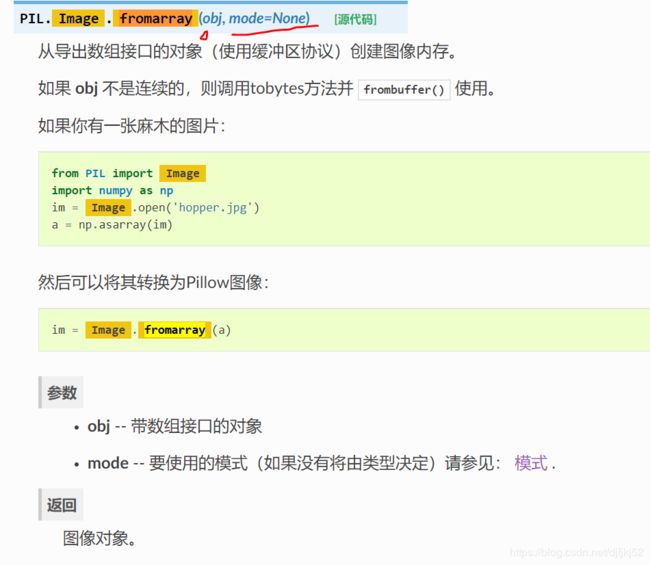
1.0 imresize 被历史放弃,改用PIL.Image.fromarray()
from PIL import Image
import numpy as np
# im = imresize(im, (h, int(w * aspect_ratio)), interp='bicubic')
im = np.array(Image.fromarray(im,model="None").resize((w,h),[mode])))
示例:
lane_image = np.array(Image.fromarray(lane_drawn,mode = 'RGB').resize((1280,720),3))
参考:https://blog.csdn.net/discoverer100/article/details/95534621
wiki:https://www.osgeo.cn/pillow/reference/Image.html?highlight=image%20fromarray
2.0 TypeError: Cannot handle this data type
我之前一直用的formarry函数用错了
错误:
lane_image = np.array(Image.fromarray(lane_drawn).resize((1280,720)))
正确的是:
lane_image = np.array(Image.fromarray(lane_drawn,mode = 'RGB').resize((1280,720),3))
参考地址:https://stackoverflow.com/questions/48039983/how-to-save-solve-this-saving-images-with-pil-image
参考的处理算法:https://www.osgeo.cn/pillow/handbook/concepts.html#concept-modes
参考中的建议:
Assuming the data in generated is valid.
- Iterate over the first dimension, keeping track of the index
- ensure correct datatype
- create the Image
- save the image
prefix = '\my\path\prefix'
ext = 'jpg'
for suffix, data in enumerate(generated):
print(data.shape)
data.dtype = np.uint8
im = Image.fromarray(data, mode = 'RGB')
print(f'{prefix}_{suffix}.{ext}')
im.save(f'{prefix}_{suffix}.{ext}', 'JPEG')

2.0 图像信息float32与uint8 ,导致图像放大后没有了像素!


# flaot转换uint
lane_drawn = np.dstack((blanks, lanes.avg_fit, blanks))
lane_drawn = np.dstack((blanks, lanes.avg_fit, blanks)).astype(np.uint8)
# 如果不转换,警告pillow的resize,就显示不出来了
参考:https://blog.csdn.net/banxia1995/article/details/87924224
参考:https://www.osgeo.cn/pillow/reference/Image.html?highlight=image%20fromarray
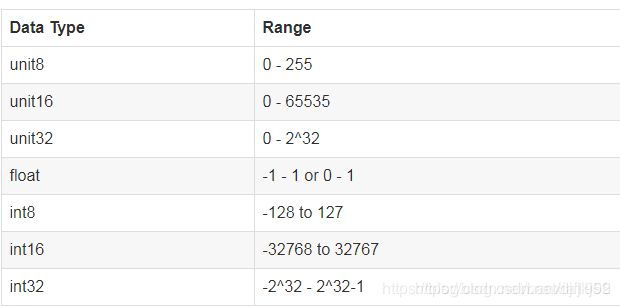
在python图像处理过程中,遇到的RGB图像的值是处于0-255之间的,为了更好的处理图像,通常会将图像值转变到0-1之间
这个处理的过程就是图像的float类型转变为uint8类型过程。
float类型取值范围 :-1 到1 或者 0到1
uint8类型取值范围:0到255
参考:https://blog.csdn.net/banxia1995/article/details/87924224
3.0 图片信息显示工具:
# cv2.namedWindow('Image')
# cv2.imshow('Image', lane_drawn)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# print(type(lane_drawn))
# print(lane_drawn.dtype)
# pixel_data = np.array(lane_drawn) #从图像生成纯粹的三维数组
# print(pixel_data) #打印图片的像素数据矩阵
4.0 Resize
https://www.osgeo.cn/pillow/reference/Image.html?highlight=image%20fromarray
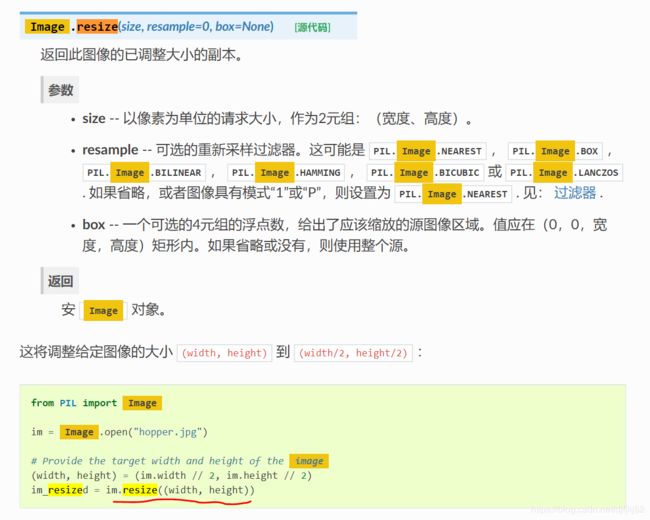
mode – 要使用的模式(如果没有将由类型决定)请参见: 模式 .
参考:https://www.osgeo.cn/pillow/handbook/concepts.html#concept-modes
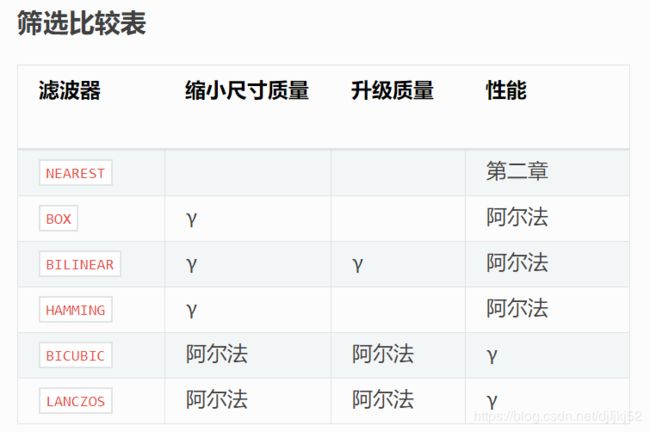
过滤器:对于可能将多个输入像素映射到单个输出像素的几何操作,python图像库提供了不同的重采样。 过滤器.
NEAREST
从输入图像中选取一个最近的像素。忽略所有其他输入像素。
BOX
源图像的每个像素贡献给具有相同权重的目标图像的一个像素。因为上标相当于 NEAREST . 此筛选器只能与 resize() 和 thumbnail() 方法。
3.4.0 新版功能.
BILINEAR
要调整大小,请使用可能有助于输出值的所有像素上的线性插值计算输出像素值。对于其他转换,使用输入图像中2x2环境上的线性插值。
HAMMING
生成的图像比 BILINEAR 在地方层面上没有错位 BOX . 此筛选器只能与 resize() 和 thumbnail() 方法。
3.4.0 新版功能.
BICUBIC
要调整大小,请使用可能有助于输出值的所有像素上的三次插值来计算输出像素值。对于其他转换,使用输入图像中4x4环境上的三次插值。
LANCZOS
对所有可能有助于输出值的像素使用高质量Lanczos过滤器(截断的sinc)计算输出像素值。此筛选器只能与 resize() 和 thumbnail() 方法。
np.zeros_like()函数
在学习用RNN网络实现连个数的加法运算时,看到代码中有行:W_update=np.zeros_like(W);
函数主要是想实现构造一个矩阵W_update,其维度与矩阵W一致,并为其初始化为全0;这个函数方便的构造了新矩阵,无需参数指定shape大小;
参考链接:https://blog.csdn.net/c20081052/article/details/79964321
# Generate fake R & B color dimensions, stack with G
blanks = np.zeros_like(lanes.avg_fit).astype(np.uint8)
lane_drawn = np.dstack((blanks, lanes.avg_fit, blanks)).astype(np.uint8)
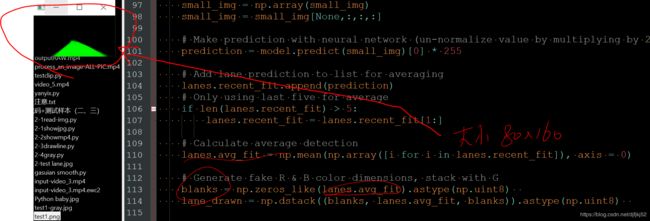
最后的效果:
