大数据开发平台:Spark环境搭建:看这一篇博客就够了!!
目录
写在前面:
安装环境:
开始安装:
一:下载安装包
二:上传安装包到CentOS系统并解压
三:本地模式 Local 初体验:
启动本地模式 Spark Shell
体验读取本地数据并计算:
体验读取HDFS数据并计算
四:standalone 集群模式
角色介绍:
集群规划:
修改配置并分发到其他节点
分发到其他节点
启动Spark集群和关闭Spark集群
启动集群式Spark Shell
五:standalone-HA 集群高可用模式
原理:
配置 HA
启动ZK集群
启动Spark HA集群
测试 HA集群
六:on yarn集群模式
准备工作:
Cluster模式 【❤❤❤常用方式❤❤❤】:
示例程序:
client模式[了解]
两种提交方式的区别:
七:Spark参数详解
参数总结:
八:使用IDEA编写Spark程序
1、创建Maven项目
2、本地执行:前提条件你的本机必须配置了Scala并且你的IDEA配置了Scala对应版本的插件
3、集群运行:
不容易,这么长你都看完了赶紧点个赞吧!!!
看完点赞 养成习惯 !!!!
写在前面:
安装环境:
CentOS 6.9【传送门】
HaddopCDH5.14【传送门】
首先Spark是一个基于内存的用于大规模数据处理的统一分析引擎。
其次它支持使用Scala、Python、R、SQL等语言快速编写应用程序,使用非常方便。
最后Spark可以运行在Hadoop、Apache Mesos,Kubernetes等环境、也可以进行独立或者在云上运行,它可以访问各种资源。
开始安装:
一:下载安装包
官网【英文版】
官网【中文版文档】
官方下载网址【传送门】
本次安装的Spark是已经编译好的适用CDH版本【https://pan.baidu.com/s/1RDAxpz2r2X2JZSpUFJ1Kkg 提取码: gdg9】
二:上传安装包到CentOS系统并解压

tar zxvf spark-2.2.0-bin-2.6.0-cdh5.14.0.tgz -C ../servers/
三:本地模式 Local 初体验:
解压目录说明:

启动本地模式 Spark Shell
开箱即用 直接启动bin 目录下的 Spark Shell
bin/spark-shell看到LOGO就表明本地模式启动成功

●spark-shell说明
1.直接使用 bin./spark-shell
表示使用local 模式启动,在本机启动一个SparkSubmit进程
2.还可指定参数 --master,如:
bin/spark-shell --master local[N] 表示在本地模拟N个线程来运行当前任务
bin/spark-shell --master local[*] 表示使用当前机器上所有可用的资源
3.不携带参数默认就是
bin/spark-shell --master local[*]
4.后续还可以使用--master指定集群地址,表示把任务提交到集群上运行,如
bin/spark-shell --master spark://node01:7077
5.退出spark-shell
使用 :quit体验读取本地数据并计算:
准备数据:
vim /root/words.txt
hello me you her
hello you her
hello her
hello在Spark中计算:
val textFile = sc.textFile("file:///root/words.txt")
val counts = textFile.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
counts.collect//收集结果
# Array[(String, Int)] = Array((you,2), (hello,4), (me,1), (her,3))体验读取HDFS数据并计算
准备数据:
# 上传文件到hdfs
hadoop fs -put /root/words.txt /wordcount/input/words.txt
# 目录如果不存在可以创建
hadoop fs -mkdir -p /wordcount/input
在Spark中计算:
val textFile = sc.textFile("hdfs://node01:8020/wordcount/input/words.txt")
val counts = textFile.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
# 把计算结果写入到/wordcount/output
counts.saveAsTextFile("hdfs://node01:8020/wordcount/output")四:standalone 集群模式
角色介绍:
Spark是基于内存计算的大数据并行计算框架,实际中运行计算任务肯定是使用集群模式,那么我们先来学习Spark自带的standalone集群模式了解一下它的架构及运行机制。
Standalone集群使用了分布式计算中的master-slave模型,
master是集群中含有master进程的节点
slave是集群中的worker节点含有Executor进程
查看官方集群模式概述【传送门】
集群规划:
node01:master
node02:slave/worker
node03:slave/worker修改配置并分发到其他节点
1、修改 spark-env.sh
cd /export/servers/spark/conf
# 最好是做一个备份
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
#配置java环境变量
export JAVA_HOME=/export/servers/jdk1.8
#指定spark Master的IP
export SPARK_MASTER_HOST=node01
#指定spark Master的端口
export SPARK_MASTER_PORT=7077
cp slaves.template slaves
vim slaves
node02
node03
按需配置(不是重点):
●配置spark环境变量 (建议不添加,避免和Hadoop的命令冲突)
将spark添加到环境变量,添加以下内容到 /etc/profile
export SPARK_HOME=/export/servers/spark
export PATH=$PATH:$SPARK_HOME/bin
注意:
hadoop/sbin 的目录和 spark/sbin 可能会有命令冲突:
start-all.sh stop-all.sh
解决方案:
1.把其中一个框架的 sbin 从环境变量中去掉;
2.改名 hadoop/sbin/start-all.sh 改为: start-all-hadoop.sh
分发到其他节点
●通过scp 命令将配置文件分发到其他机器上
scp -r /export/servers/spark node02:/export/servers
scp -r /export/servers/spark node03:/export/servers启动Spark集群和关闭Spark集群
●集群启动和停止
在主节点上启动spark集群
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/sbin/start-all.sh
在主节点上停止spark集群
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/sbin/start-all.sh
●单独启动和停止
在 master 安装节点上启动和停止 master:
start-master.sh
stop-master.sh
在 Master 所在节点上启动和停止worker(work指的是slaves 配置文件中的主机名)
start-slaves.sh
stop-slaves.sh启动后查看WEB界面:http://Master节点IP:8080/

启动集群式Spark Shell
●集群模式启动spark-shell
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/bin/spark-shell --master spark://node01:7077
测试:使用集群方式进行计算
●注意
集群模式下程序是在集群上运行的,不要直接读取本地文件,应该读取hdfs上的
因为程序运行在集群上,具体在哪个节点上我们运行并不知道,其他节点可能并没有那个数据文件●运行程序
sc.textFile("hdfs://node01:8020/wordcount/input/words.txt")
.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
.saveAsTextFile("hdfs://node01:8020/wordcount/output2")
Spark日志 http://Master节点IP:4040/jobs/

五:standalone-HA 集群高可用模式
原理:
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障的问题。
如何解决这个单点故障的问题,Spark提供了两种方案:
1.基于文件系统的单点恢复(Single-Node Recovery with Local File System)--只能用于开发或测试环境。
2.基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)--可以用于生产环境。
 配置 HA
配置 HA
该HA方案使用起来很简单,首先启动一个ZooKeeper集群,然后在不同节点上启动Master,注意这些节点需要具有相同的zookeeper配置。
●先停止Sprak集群
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/sbin/stop-all.sh
●在node01上配置:
vim /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf/spark-env.sh
●注释掉Master配置
#export SPARK_MASTER_HOST=node01
●在spark-env.sh添加SPARK_DAEMON_JAVA_OPTS,内容如下:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"
参数说明
spark.deploy.recoveryMode:恢复模式
spark.deploy.zookeeper.url:ZooKeeper的Server地址
spark.deploy.zookeeper.dir:保存集群元数据信息的文件、目录。包括Worker、Driver、Application信息。

分发到其他节点
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf/
scp spark-env.sh node02:$PWD
scp spark-env.sh node03:$PWD 启动ZK集群
Zookeeper安装教程【传送门】
zkServer.sh start #启动
zkServer.sh stop #关闭启动Spark HA集群
●node01上启动Spark集群执行
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/sbin/start-all.sh
●在node02上再单独只起个master:
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/sbin/start-master.sh
●注意:
在普通模式下启动spark集群
只需要在主节点上执行start-all.sh 就可以了
在高可用模式下启动spark集群
先需要在任意一台主节点上执行start-all.sh
然后在另外一台主节点上单独执行start-master.sh
node01

node02
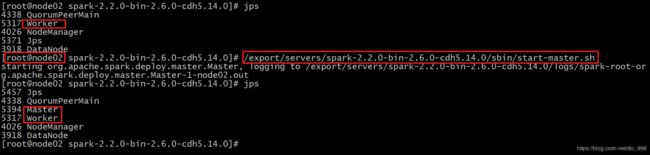
查看WEB界面的变化
http://node01:8080/

http://node02:8080/

可以观察到有一台状态为StandBy ,当ALIVE宕机后 StandBy就会转换为ALIVE状态进行服务。
测试 HA集群
切换测试:
●测试主备切换
1.在node01上使用jps查看master进程id
2.使用kill -9 id号强制结束该进程
3.稍等片刻后刷新node02的web界面发现node02为Alive

计算测试:
●测试集群模式提交任务
1.集群模式启动spark-shell
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/bin/spark-shell --master spark://node01:7077,node02:7077
2.运行程序
sc.textFile("hdfs://node01:8020/wordcount/input/words.txt").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).saveAsTextFile("hdfs://node01:8020/wordcount/output3")六:on yarn集群模式
查看 on Yarn集群模式的官方文档【传送门】
准备工作:
1.安装启动Hadoop(需要使用HDFS和YARN,已经ok)
2.安装单机版Spark(已经ok)
注意:不需要集群,因为把Spark程序提交给YARN运行本质上是把字节码给YARN集群上的JVM运行,但是得有一个东西帮我去把任务提交上个YARN,所以需要一个单机版的Spark,里面的有spark-shell命令,spark-submit命令
3.修改配置:
在spark-env.sh ,添加HADOOP_CONF_DIR配置,指明了hadoop的配置文件的位置
vim /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf/spark-env.sh
export HADOOP_CONF_DIR=/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
Cluster模式 【❤❤❤常用方式❤❤❤】:
●说明
在企业生产环境中大部分都是cluster部署模式运行Spark应用
Spark On YARN的Cluster模式 指的是Driver程序运行在YARN集群上
●补充Driver是什么:
运行应用程序的main()函数并创建SparkContext的进程

示例程序:
spark-shell是一个简单的用来测试的交互式窗口
spark-submit用来提交打成jar包的任务
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--queue default \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
10


查看Yarn日志 http://node01:8088/cluster

client模式[了解]
学习测试时使用,开发不用,了解即可
Spark On YARN的Client模式 指的是Driver程序运行在提交任务的客户端

/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--queue default \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
10
两种提交方式的区别:
Cluster和Client模式最本质的区别是:Driver程序运行在哪里!
运行在YARN集群中就是Cluster模式,
运行在客户端就是Client模式
当然还有由本质区别延伸出来的区别。
●cluster模式:生产环境中使用该模式
1.Driver程序在YARN集群中
2.应用的运行结果不能在客户端显示
3.该模式下Driver运行ApplicattionMaster这个进程中,如果出现问题,yarn会重启ApplicattionMaster(Driver)
●client模式:
1.Driver运行在Client上的SparkSubmit进程中
2.应用程序运行结果会在客户端显示
七:Spark参数详解
spark-shell
spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下可以用scala编写spark程序,适合学习测试时使用!
●示例
spark-shell可以携带参数
spark-shell --master local[N] 数字N表示在本地模拟N个线程来运行当前任务
spark-shell --master local[*] *表示使用当前机器上所有可用的资源
默认不携带参数就是--master local[*]
spark-shell --master spark://node01:7077,node02:7077 表示运行在集群上
spark-submit
spark-submit命令用来提交jar包给spark集群/YARN
spark-shell交互式编程确实很方便我们进行学习测试,但是在实际中我们一般是使用IDEA开发Spark应用程序打成jar包交给Spark集群/YARN去执行。
❤❤❤ spark-submit命令是我们开发时常用的!!! ❤❤❤
参数总结:
local 本地以一个worker线程运行(例如非并行的情况).
local[N] 本地以K worker 线程 (理想情况下, N设置为你机器的CPU核数).
local[*] 本地以本机同样核数的线程运行.
spark://HOST:PORT 连接到指定的Spark standalone cluster master. 端口是你的master集群配置的端口,缺省值为7077.
mesos://HOST:PORT 连接到指定的Mesos 集群. Port是你配置的mesos端口, 默认5050. 或者使用ZK,格式为 mesos://zk://....
yarn-client 以client模式连接到YARN cluster. 集群的位置基于HADOOP_CONF_DIR 变量找到.
yarn-cluster 以cluster模式连接到YARN cluster. 集群的位置基于HADOOP_CONF_DIR 变量找到.
其他参数示例
--master spark://node01:7077 指定 Master 的地址
--name "appName" 指定程序运行的名称
--class 程序的main方法所在的类
--jars xx.jar 程序额外使用的 jar 包
--driver-memory 512m Driver运行所需要的内存, 默认1g
--executor-memory 2g 指定每个 executor 可用内存为 2g, 默认1g
--executor-cores 1 指定每一个 executor 可用的核数
--total-executor-cores 2 指定整个集群运行任务使用的 cup 核数为 2 个
--queue default 指定任务的对列
--deploy-mode 指定运行模式(client/cluster)
●注意:
如果 worker 节点的内存不足,那么在启动 spark-submit的时候,就不能为 executor分配超出 worker 可用的内存容量。
如果--executor-cores超过了每个 worker 可用的 cores,任务处于等待状态。
如果--total-executor-cores即使超过可用的 cores,默认使用所有的。以后当集群其他的资源释放之后,就会被该程序所使用。
如果内存或单个 executor 的 cores 不足,启动 spark-submit 就会报错,任务处于等待状态,不能正常执行。
八:使用IDEA编写Spark程序
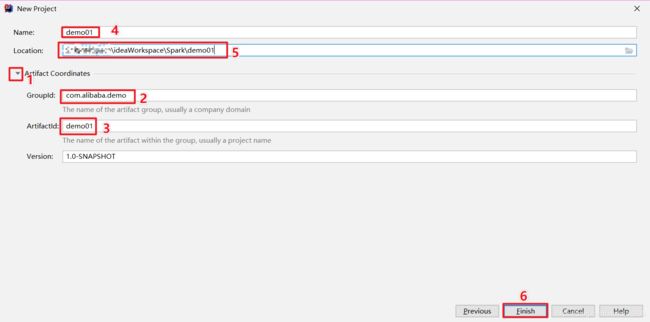
1、创建Maven项目

给项目起名字,并选择项目存储路径!



2、本地执行:前提条件你的本机必须配置了Scala并且你的IDEA配置了Scala对应版本的插件

准备数据
Hadoop Hive
Hbase Hadoop Hive hive
Spark Flink Kylin
Sqoop Flume Kafka Spark Hadoop Hbase
Flink Kylin Spark Spark_Streaming编写代码并执行查看结果
package com.alibaba.demo01
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Test01 {
def main(args: Array[String]): Unit = {
//1.创建SparkContext
val config = new SparkConf().setAppName("wordcount").setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
//2.读取文件
//A Resilient Distributed Dataset (RDD)弹性分布式数据集
//可以简单理解为分布式的集合,但是spark对它做了很多的封装,
//让程序员使用起来就像操作本地集合一样简单,这样大家就很happy了
val fileRDD: RDD[String] = sc.textFile("C:\\Users\\****\\Desktop\\data\\words.txt")
//3.处理数据
//3.1对每一行按空切分并压平形成一个新的集合中装的一个个的单词
//flatMap是对集合中的每一个元素进行操作,再进行压平
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
//3.2每个单词记为1
val wordAndOneRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
//3.3根据key进行聚合,统计每个单词的数量
//wordAndOneRDD.reduceByKey((a,b)=>a+b)
//第一个_:之前累加的结果
//第二个_:当前进来的数据
val wordAndCount: RDD[(String, Int)] = wordAndOneRDD.reduceByKey(_ + _)
//4.收集结果
val result: Array[(String, Int)] = wordAndCount.collect()
result.foreach(println)
}
}
查询结果

3、集群运行:
package com.alibaba.demo01
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Test01 {
def main(args: Array[String]): Unit = {
//1.创建SparkContext
val config = new SparkConf().setAppName("wordcount")//.setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
//2.读取文件
//A Resilient Distributed Dataset (RDD)弹性分布式数据集
//可以简单理解为分布式的集合,但是spark对它做了很多的封装,
//让程序员使用起来就像操作本地集合一样简单,这样大家就很happy了
val fileRDD: RDD[String] = sc.textFile(args(0))
//3.处理数据
//3.1对每一行按空切分并压平形成一个新的集合中装的一个个的单词
//flatMap是对集合中的每一个元素进行操作,再进行压平
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
//3.2每个单词记为1
val wordAndOneRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
//3.3根据key进行聚合,统计每个单词的数量
//wordAndOneRDD.reduceByKey((a,b)=>a+b)
//第一个_:之前累加的结果
//第二个_:当前进来的数据
val wordAndCount: RDD[(String, Int)] = wordAndOneRDD.reduceByKey(_ + _)
wordAndCount.saveAsTextFile(args(1))
}
}
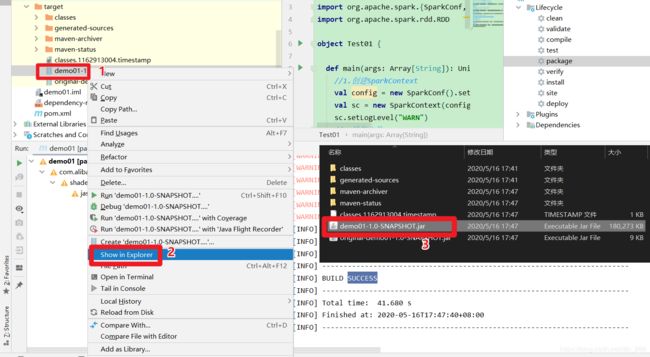
打包

找到打好的 jar包上传的Linux系统,在Spark环境中去执行。

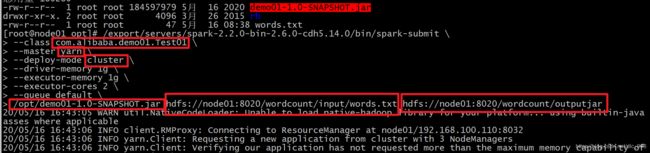
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/bin/spark-submit \
--class com.alibaba.demo01.Test01 \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--queue default \
/opt/demo01-1.0-SNAPSHOT.jar hdfs://node01:8020/wordcount/input/words.txt hdfs://node01:8020/wordcount/outputjar