Oracle数据库第六课——Oracle空间管理、索引和序列的创建
知识点:学习 Oracle 数据库应用。主要学习如何创建表空间和用户,同时介绍如何运用 索引、同义词、序列等数据库对象。
1、表空间管理
什么是表空间?表空间是指 Oracle 数据库内部数据的逻辑组织结构,对应于磁盘上的一个或多个物理数据文件。
表空间的作用?Oracle 通过表空间的数据库对象来组织数据文件。在将数据插入 Oracle 数据库之前,必须首先建立表空间,然后将数据插入表空间的一个对象中。
如何理解表空间?数据库、表空间、数据文件、表、数据之间的关系可以用柜子、抽屉、文件夹、纸,以及写在纸上的信息的关系来描述。

数据库就是柜子,柜中的抽屉是表空间,抽屉中的文件夹是数据文件,文件夹中的纸是表,写在纸上的信息就是数据。即使在自己的柜子中也不应该把保险单放在名叫“学校记录”的抽屉中,而应放在名为“保险”的抽屉。数据库中的表空间也应使用类似的规则。
表空间的分类:永久性表空间、临时性表空间、撤销表空间。
- 永久性表空间:一般保存表、视图、过程和索引等的数据。SYSTEM、SYSAUX、 USERS、EXAMPLE 表空间是默认安装的。
- 临时性表空间:只用于保存系统中短期活动的数据,如排列数据等。
- 撤销表空间:用来帮助回退未提交的事务数据,已提交了的数据在这里是不可以恢复的。一般不需要创建临时和撤销表空间,除非把他们转移到其他磁盘中以提高性能。
对不同的用户分配不同的表空间,对不同的模式对象分配不同的表空间,方便对用户数据的操作,对模式对象的管理。可以将不同数据文件创建到不同的磁盘中,有利于管理磁盘空间,有利于提高 I/O 性能,有利于备份和恢复数据等。一般在完成 Oracle 系统的安装并创建 Oracle 实例后,Oracle 系统会自动建立多个表空间。
1.1 创建表空间
每个数据库创建的时候,系统都会默认地为它创建一个 SYSTEM 表空间,一个数据库 可以有若干表空间,也可以只有一个 SYSTEM 表空间。逻辑上的方案对象,如数据表、索引等既可以存储在物理上的一个数据文件内,也可以跨越物理上的数据文件,但必须属于同一个表空间。 创建表空间语法:
create tablespace tablespace_name
datafile ‘file_name’ [SIZE integer [K | M] ]
[AUTOEXTend [OFF | ON]];语法说明:
- tablespace_name:表空间名称。
- DATAFILE:指定组成表空间的一个或多个数据文件,当有多个数据文件时使用逗号分隔。
- file_name:指数据文件的路径和名称。
- SIZE:指定文件的大小,用 K 指定千字节大小,用 M 指定兆字节大小。
- AUTOEXTEND :用来启用或禁用数据文件的自动扩展,设置为 ON 则空间使用完毕会 自动扩展,设置为 OFF 则很容易出现表空间剩余容量为 0 的情况,使数据不能存储到数据库中。
示例练习1:创建一个自动增长的表空间workdbs
第一步:使用系统账户system登录PLSQL Developer(system 密码manager)
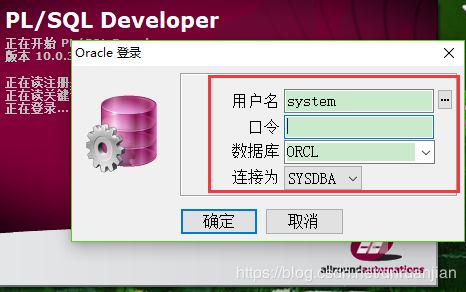
第二步:单击菜单栏【文件】——【新建】——【SQL Window】,并输入语句:
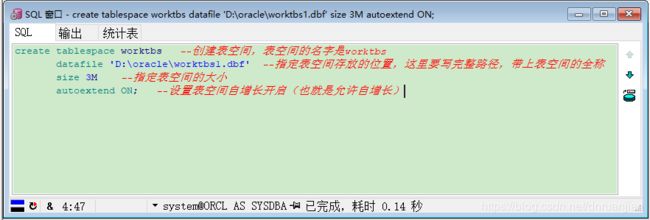
create tablespace worktbs --创建表空间,表空间的名字是worktbs
datafile 'D:\oracle\worktbs1.dbf' --指定表空间存放的位置,这里要写完整路径,带上表空间的全称
size 3M --指定表空间的大小
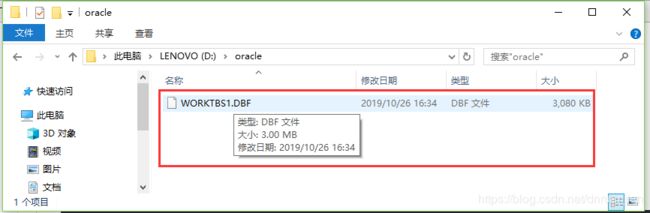
autoextend ON; --设置表空间自增长开启(也就是允许自增长)第三步:单击工具栏上的执行按钮,提示“已完成”。然后打开本地电脑磁盘对应文件夹,查看文件。
1.2 删除表空间
删除表空间语法: DROP TABLESPACE 表空间名;
示例练习2:删除表空间workdbs
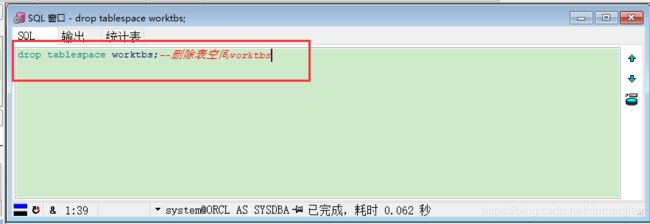
写完以后,点击工具栏执行按钮即可,提示“已完成”,代表已删除该表空间。
注意:使用drop方法删除表空间时,表空间的物理文件是不会被删除的,需要手工来删除。
提醒:删除表空间之前最好对数据库进行备份。
2、SQL语言基础(DML,DDL)
2.1 SQL 语言简介
SQL 语言是高级的结构化查询语言。用户使用 SQL 语言进行数据操作时,只需要提出“做什么”,而不必指明“怎么做”,具体的执行过程有系统自动完成,大大减轻了用户负担。SQL 语言是数据库服务器和客户端之间的重要沟通手段,用于存取数据以及查询、更新和管理关系型数据库系统。 经过多年的发展,SQL 语言已经成为关系型数据库的标准语言。SQL 支持如下类别的命令。
- 数据定义语言(DDL):CREATE(创建)、ALTER(更改)、TRUNCATE(截断)、 DROP(删除)命令。
- 数据操作语言(DML):INSERT(插入)、SELECT(选择)、DELETE(删除)和 UPDATE(更新)命令。
- 事务控制语言(TCL):COMMIT(提交)、SAVEPOINT(保存点)和 ROLLBACK(回滚)命令。
- 数据控制语言(DCL):GRANT(授予)和 REVOKE(回收)命令。
2.2 DDL 语言
数据定义语言中,CREATE TABLE 语句用来创建新表、ALTER TABLE 语句用来修改结构,TRUNCATE TABLE 语句用来删除表中的所有记录,DROP TABLE 语句用来删除表。本章结合以前学过的 DDL 语言知识,主要介绍数据定义语言中常用的 CREATE TABLE 命令和较为陌生的 TRUNCATE TABLE 命令。
(1)CREATE TABLE 命令语法:
CREATE TABLE [schema.] table_name
(
column_name1 datatype1,
[column_name2 datatype2],
……
)语法说明:
- schema 表示对象的所有者,即模式的名称。如果用户在自己的模式中创建表,则可以不指定所有者名称。
- table_name:表示表名称。
- column_name1:表示列名称。
- datatype:表示该列的数据类型及其宽度。
- 创建表时,需要指定唯一的表名称,表内唯一的列名称、列的数据类型及其宽度。
示例练习3:创建一个学员信息表stuInfo
第一步:使用系统账号登录PLSQL Developer(system 密码manager)
第二步:单击菜单栏【文件】——【新建】——【SQL Window】,并输入语句:
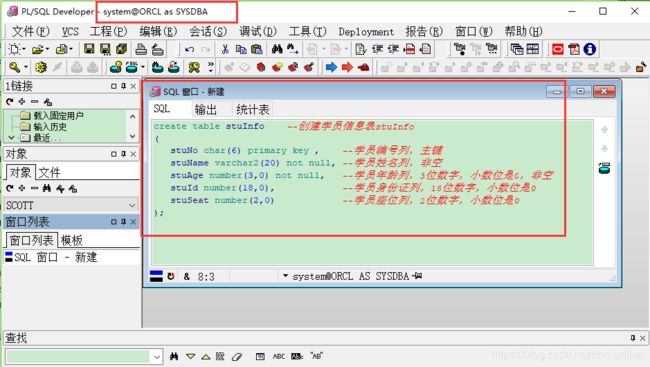
create table stuInfo --创建学员信息表stuInfo
(
stuNo char(6) primary key , --学员编号列,主键
stuName varchar2(20) not null, --学员姓名列,非空
stuAge number(3,0) not null, --学员年龄列,3位数字,小数位是0,非空
stuId number(18,0), --学员身份证列,18位数字,小数位是0
stuSeat number(2,0) --学员座位列,2位数字,小数位是0
);代码分析:创建表时,表名严格遵循以下列名规则。
- 表名首字符应该为字母。
- 不能使用 Oracle 保留字来为表名命名。
- 表名的最大长度为 30 个字符。
- 同一用户模式下的不同表不能具有相同的名称。
- 可以使用下划线、数字和字母,但是不能使用空格和单引号。
提示: Oracle 中的表名(还有列名、用户名和其他对象名)不区分大小写,系统会自动转换成大写。 Oracle 中也有 varchar 数据类型,但不建议使用,建议使用 varchar2,该数据类型是Oracle 标准数据类型。
第三步:单击工具栏上的执行按钮,提示“已完成”。

思考一个问题:我们创建的表,存放在哪个表空间里?
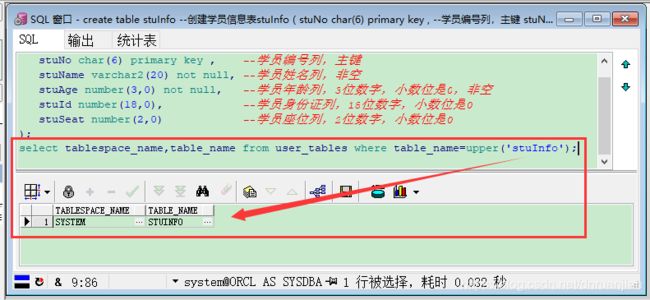
select tablespace_name,table_name from user_tables where table_name=upper('stuInfo');注意:建表未指定表空间,那么表会存在默认表空间中,默认表空间是你创建数据库的时候指定的那个表空间,一般都是SYSTEM的表空间。
案例延伸:oracle 创建表时 指定表表空间
方法:可以直接在创建表的语句后面追加“tablespace name”进行表空间指定。
sql语句:create table tablename(id int) tablespace tablespacename;
解释:在表空间“tablespacename”上创建表“tablename”。以上语句就实现了为表指定表空间。
(2)TRUNCATE TABLE 命令命令语法:
TRUNCATE TABLE 表名;如果存储在表中的数据不再使用,可以只删除表中的记录而不删除表结构。使用 TRUNCATE TABLE 命令将删除表中的所有行且不记录日志,所以与 DELETE 命令删除表中记录相比较节省资源,执行速度也较快。
2.3 DML 语言
数据操纵语言用于检索、插入和修改数据库信息。它是最常用的 SQL 命令,如 INSERT(插入)、SELECT(选择)、DELETE(删除)和 UPDATE(更新)。在学习 SQL Server 中已经详细介绍过了,这里只做补充介绍。
示例练习4:向学员信息表stuInfo中插入5行数据
第一步:在上面案例的基础上,在【SQL Window】,继续输入语句:
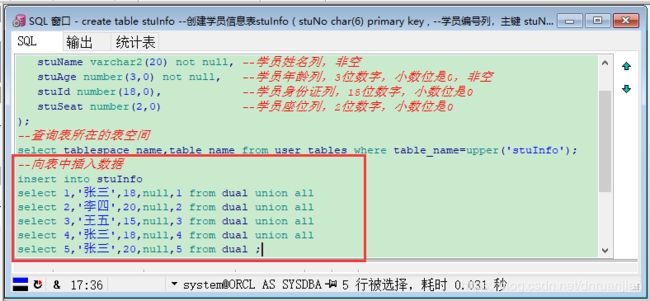
--向表中插入数据
insert into stuInfo
select 1,'张三',18,null,1 from dual union
select 2,'李四',20,null,2 from dual union
select 3,'王五',15,null,3 from dual union
select 4,'张三',18,null,4 from dual union
select 5,'张三',20,null,5 from dual ;第二步:点击工具栏上的执行按钮,会提示“5行被插入”
案例思考:查询我们表中的所有数据
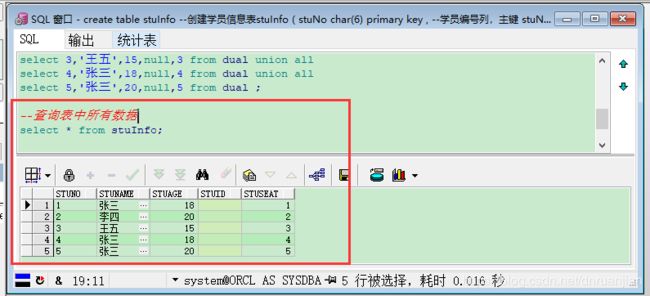
2.3.1 从语法角度介绍DML 语言操作
1) 查询无重复的行
要防止选择重复的行,可以在 SELECT 命令中包含 DISTINCT 子句。
例如:不重复显示所有学员的姓名和年龄
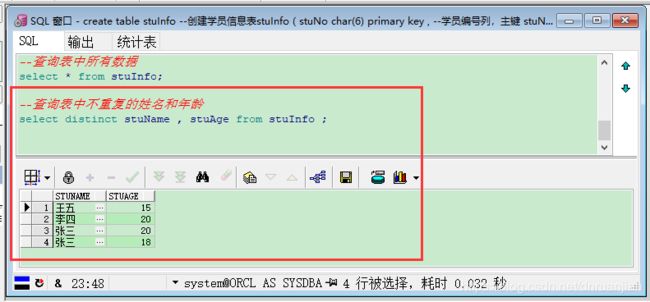
--查询表中不重复的姓名和年龄
select distinct stuName , stuAge from stuInfo ;注意:distinct 子句筛除结果集中内容全部相同的行,(如题,姓名为张三,年龄 为 18 的信息有两条)仅保留其中一行。
2) 带条件和排序的 SELECT 命令
要从表中选择特定的行,可以在 SELECT 命令中包含 WHERE 子句。它只能出现 在 FROM 子句后面,而且只检索符合 WHERE 条件的行。若要根据某个预定义的顺序 排列显示行,可以使用 ORDER 子句。它还可以用来以升序或降序来排列行和排列多个列。
例如:查询年龄大于17的学员,按照姓名升序排序,如果姓名相同,则按照年龄降序排序。
--查询年龄大于17的学员,按照姓名升序排序,如果姓名相同,则按照年龄降序排序。
select stuNo,stuName,stuAge
from stuInfo
where stuAge>17
order by stuName ASC ,stuAge DESC;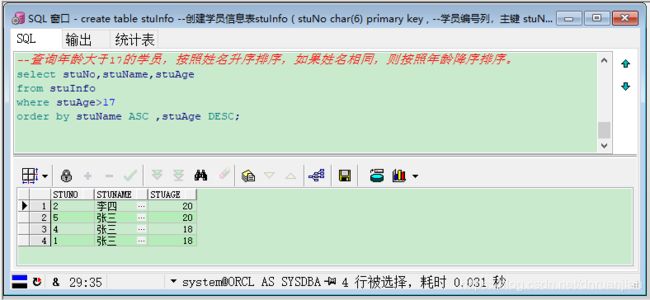
3) 使用列别名
列别名为列表达式提供的另一个名称,并显示在列标题中。列别名不会影响列的实际名称。列别名位于表达式后面。
例如:使用别名显示姓名、年龄和身份证号列。
--使用别名显示姓名、年龄和身份证号列。
select stuName as "姓 名",stuAge as "_年龄",stuId as 身份证号
from stuInfo;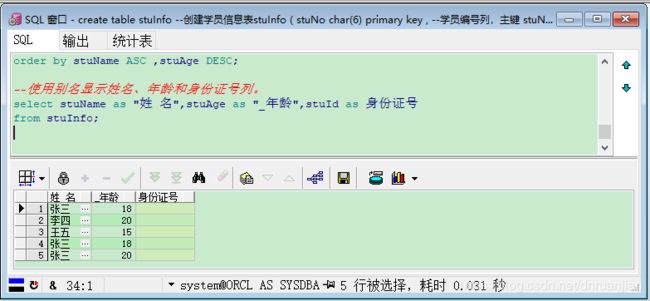
注意:如果列别名中指定含有特殊字符(如空格)的列标题使用双引号括起来。
4) 利用现有的表创建新表
Oracle 允许利用现有的表创建新表。 语法:
CREATE TABLE 新表名
AS
SELECT *|所需列名
FROM 现有表 [WHERE 条件]此命令可以把现有表中的所有记录复制到新表中,也可以仅复制选定的列或只复制结构而不复制记录。
例如:创建 newStuInfo 表,拷贝 stuInfo 表及其所有记录。
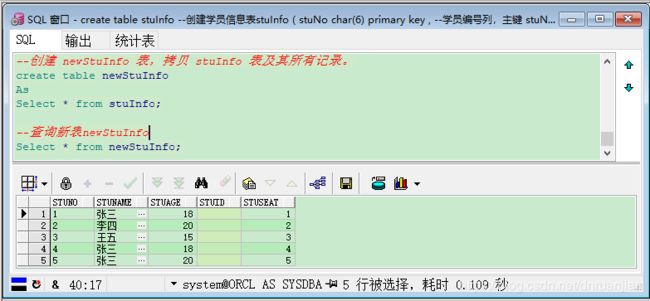
--创建 newStuInfo 表,拷贝 stuInfo 表及其所有记录。
create table newStuInfo
As
Select * from stuInfo;
--查询新表newStuInfo
Select * from newStuInfo;例如:创建 newStuInfo 表,它具有来自 stuInfo 表的学员姓名、学员编号和年龄的所有记录。
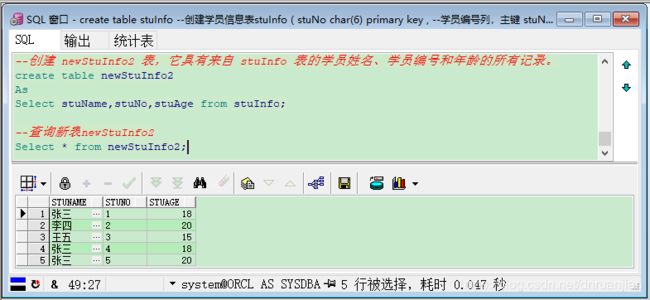
--创建 newStuInfo2 表,它具有来自 stuInfo 表的学员姓名、学员编号和年龄的所有记录。
create table newStuInfo2
As
Select stuName,stuNo,stuAge from stuInfo;
--查询新表newStuInfo2
Select * from newStuInfo2;例如:创建 newStuInfo3 表,仅仅复制表结构,而不复制记录。
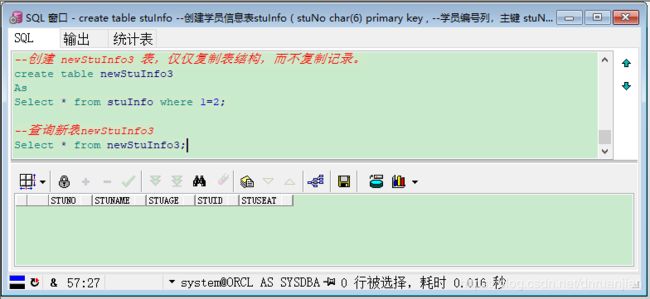
--创建 newStuInfo3 表,仅仅复制表结构,而不复制记录。
create table newStuInfo3
As
Select * from stuInfo where 1=2;
--查询新表newStuInfo3
Select * from newStuInfo3;
2.3.2.从使用技巧的角度介绍 DML 语言操作
1)查看表中行数
--查看表中行数
select count(*) from stuInfo;--效率较低
select count(1) from stuInfo;--效率较高2)取出 stuName,stuAge 列不存在重复数据的记录

--取出 stuName,stuAge 列不存在重复数据的记录
select stuName,stuAge
From stuInfo
Group by stuName,stuAge
Having (count(stuName||stuAge) <2);代码说明:“||”操作符为连接操作符,用于将两个或多个字符串合并成一个字符串,或将一个字符串与一个数值合并在一起,类似 SQL Server 中的“+”,将两部分内容连接在一起。例子中 count 函数中的参数只能有一个,所以用连接操作符做连接。
3) 查看当前用户所有数据量>100 万的表的信息

--查看当前用户所有数据量>100 万的表的信息
select table_name
From user_all_tables a
Where a.num_rows>1000000;提示:user_all_tables 为系统提供的数据视图,使用者可以通过查询该视图获得当前用户表的描述。
3、 从语法角度介绍DML 语言操作
3.1 什么是索引
索引是与表关联的可选结构,是一种快速访问数据的途径,可提高数据性能。
索引的作用:快速访问数据。
如果《新华字典》是一张表,那么索引相当于《新华字典》中的目录。如果没有索引,查询数据的时候,就采用逐一匹配的方式进行查询。如果存在索引,查询数据的时候,就可以直接根据索引来查询数据,从而加快查询速度。
数据库可以明确地创建索引,以加快对表执行 SQL 语句的速度。当索引键作为查询条件时,该索引将直接指向包含这些值的行的位置。即便删除索引,也无需修改任何 SQL 语句的定义。
3.2 索引的分类
在 Oracle 中,索引的分类如表所示:
| 物理分类 |
逻辑分类 |
| 分区或非分区索引 |
单列或组合索引 |
| B树索引(标准索引) |
唯一或非唯一索引 |
| 正常或反向键索引 |
基于函数索引 |
| 位图索引 |
|
(1) B 树索引
B 树索引通常也称为标准索引。索引的顶部为根,其中包含指向索引中下一级的项。下一级为分支块,分支块又指向下一级的块。最低一级为叶节点,其中包含指向表行的索引项。 叶块为双向链接,有助于按关键字值的升序和降序扫描索引。 创建普通索引的语法:create index 索引名 on 表名(列名);
CREATE [UNIQUE] INDEX index_name
ON table_name(column_list)
[TABLESPACE tablespace+name];语法说明:
- UNIQUE:用于指定唯一索引,默认情况下为非唯一索引。
- index_name:指所创建索引的名称。
- table_name:表示为之创建索引的表名。
- column_list:在其上创建索引的列名的列表,可以基于多列创建索引,列之间用逗号分割。
- Tablesapce_name:为索引指定表空间。
3.3 索引的原理
create index emp_index_sal on emp(sal);
1)表里数据按索引字段,从小到大排序
2)取出两个字段:索引字段(sal)和rowid
3)把这两个字段的的结果集保存在一张特殊的表里——索引表
4)创建一棵树Btree——二叉树
说明:oracle数据库的表中的每一行数据都有一个唯一的标识符,称为rowid,在oracle内部通常就是使用它来访问数据的。
3.4 创建索引的原则
创建索引时需遵循的原则:
1. 频繁搜索的列可以作为索引。
2. 经常排序、分组的列可以作为索引。
3. 经常用作连接的列(主键/外键)可以作为索引。
4. 将索引放在一个单独的表空间中,不要放在有回退段、临时段和表的表空间中。
5. 对大型索引而言,考虑使用 NOLOGGING 子句创建大型索引。
6. 根据业务数据发生的频率,定期重新生成或重新组织索引,并进行碎片整理。
7. 仅包含几个不同值的列不可以创建为 B 数索引,根据需要创建位图索引。
8. 不要在仅包含几行的表中创建索引。
3.5 删除索引
(1)DROP INDEX 语句用于删除索引
例如:删除员工表(emp)表中的 index_bit_job 位图索引:
drop Index index_bit_job;注意:在 SQL Server 中创建或删除索引时,必须指明表的名称和索引名称。而 Oracle 索引名在用户账户中是唯一的,删除时不需要指定表名。
(2)何时应删除索引
- 应用程序不再需要索引。
- 执行批量加载前删除索引。大量加载数据前删除索引,加载后再重建索引有以下好处:提高加载性能、更有效地使用索引空间。
- 索引已损坏。
3.6 重建索引
(1)ALTER INDEX ……REBUILD 语句用于重建索引
例如,将反向键索引更改为正常的 B 树索引。
alter index index_reverse_empno rebuild noreverse;(2)何时应重建索引
- 用户表被移动到新的表空间后,表上的索引不是自动移动,需要将索引移到指定表空间。
- 索引中包含很多已删除的项。对表进行频繁删除,造成索引空间浪费,可以重建索引。
- 需将现有正常索引转换成反向键索引。
示例练习4:练习索引的使用
第一步:使用系统账号登录PLSQL Developer(system 密码manager),创建一个用户wang,密码123,并授予该用户connect和resource角色。
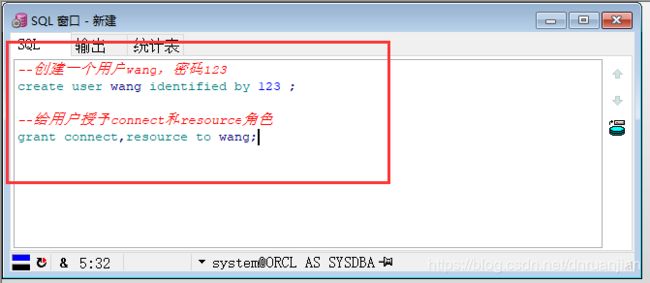
--创建一个用户wang,密码123
create user wang identified by 123 ;
--给用户授予connect和resource角色
grant connect,resource to wang;第二步:使用新创建的用户wang登录PLSQL Developer,新建一个SQL窗口,并创建表stu
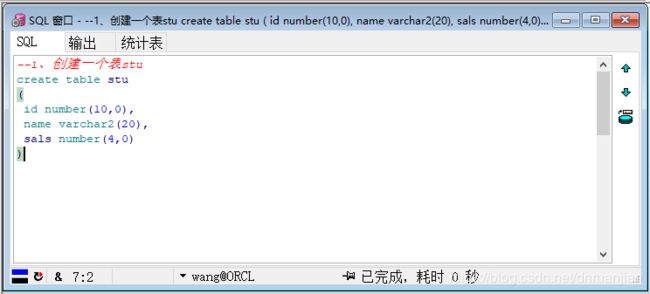
第三步:创建一个序列,用来制作id列的自增长。
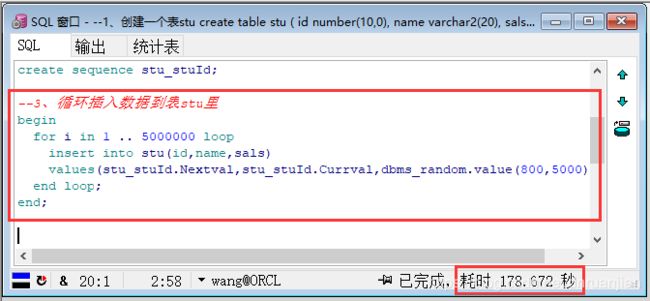
第四步:使用循环,向stu表中插入5000000行数据。(耗时会较长)
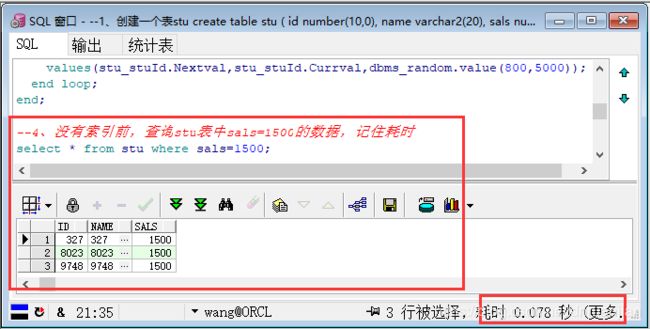
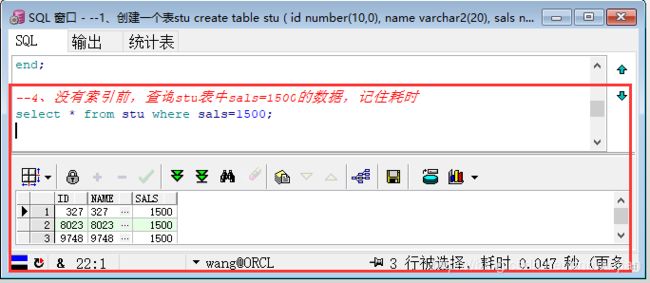
第五步:没有索引前,查询stu表中sals=1500的数据
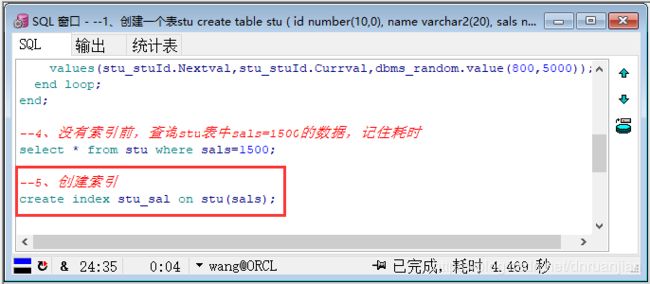
第六步:创建一个索引
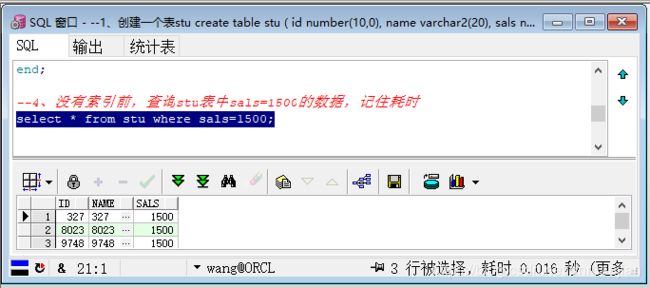
第七步:再次查询stu表中sals=1500的数据,对比两次查询的耗时。
多次查询stu表中sals=1500的数据,注意观察时间。
本案例完整代码:
--1、创建一个表stu
create table stu
(
id number(10,0),
name varchar2(20),
sals number(4,0)
)
--2、创建一个序列,用来作为id和name
create sequence stu_stuId;
--3、循环插入数据到表stu里
begin
for i in 1 .. 5000000 loop
insert into stu(id,name,sals)
values(stu_stuId.Nextval,stu_stuId.Currval,dbms_random.value(800,5000));
end loop;
end;
--4、没有索引前,查询stu表中sals=1500的数据,记住耗时
select * from stu where sals=1500;
--5、创建索引
create index stu_sal on stu(sals);
--6、索引创建成功后,再次执行第4步的操作,对比耗时代码分析:dbms_random.value函数 该函数用来产生一个随机数,有两种用法:
- 产生一个介于0和1之间(不包含0和1)的38位精度的随机数,语法为:dbms_random.value return number;这种用法不包含参数。
- 产生一个介于指定范围之内的38位精度的随机数,语法为:dbms_random.value(数字1,数字2);这种用法包含两参数,数字1用来指定要生成的随机数的下限,数字2指定上限,生成的随机。请注意生成的随机数有可能等于下限,但绝对小于上限,即“low<=随机数
4、 同义词
同义词是使用对象的一个别名,不占用任何实际存储空间,只是在 Oracle 的数据字典中保存其定义描述。在使用同义词时,Oracle 会将其翻译为对应对象的名称。
4.1 同义词用途
- 简化 SQL 语句。
- 隐藏对象的名称和所有者。
- 为分布式数据库的远程对象提供了位置透明性。
- 提供对对象的公共访问。
4.2 同义词分类
- 私有同义词
- 共有同义词
私有同义词只能被被当前模式的用户访问。私有同义词名称不可与当前模式对象名称相同。在当前模式下创建私有同义词,用户必须拥有 CREATE SYNONYM 系统权限。要在其他用户模式下创建私有同义词的语法:
第一步: 同义词的创建需要有创建同义词的权利。 system 赋予你: grant create (public) synonym to 用户名;
第二步:使用语句创建。
create [ or replace ] synonym 同义词名 for 同义词指的代内容; --创建私有同义词
create [ or replace ] public synonym 同义词名 for 同义词指代的内容;--创建公有同义词语法说明:
- or replace:表示在同义词存在的情况下替换该同义词。
- synonym_name:表示要创建的同义词的名称。
- object_name:指定要为之创建同义词的对象的名称。
4.3 公有同义词和私有同义词的区别
- 私有同义词只能在当前模式下访问,且不能与当前模式的对象同名。
- 公有同义词可被所有的数据库用户访问。
注意:
使用同义词前,要获得同义词对应对象的访问权限。
对象(如表)、私有同义词、公有同义词是否可以三者同名?对象与私有同义词不能同名;对象和公有同义词同名时,数据库有限选择对象作为目标,私有同义词和公有同义词同名时,数据库优先选择私有同义词作为目标。
4.4 删除同义词
DROP SYNONYM 语句用于从数据库中删除同义词。要删除同义词,用户必须拥有相应的权限。
- 删除同义词也要有删除同义词的权限 drop (public)synonym;
- 删除私有同义词:drop synonym 同义词名;
- 删除公有同义词:drop public synonym 同义词名;
示例练习5:练习同义词的使用
第一步:使用系统账号登录PLSQL Developer(system 密码manager),给用户wang授予访问SCOTT用户下emp表的权限。
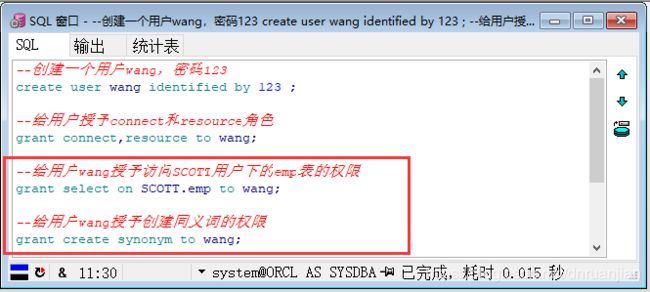
--给用户wang授予访问SCOTT用户下的emp表的权限
grant select on SCOTT.emp to wang;
--给用户wang授予创建同义词的权限
grant create synonym to wang;第二步:使用用户wang登录PLSQL Developer,新建一个SQL窗口,没有
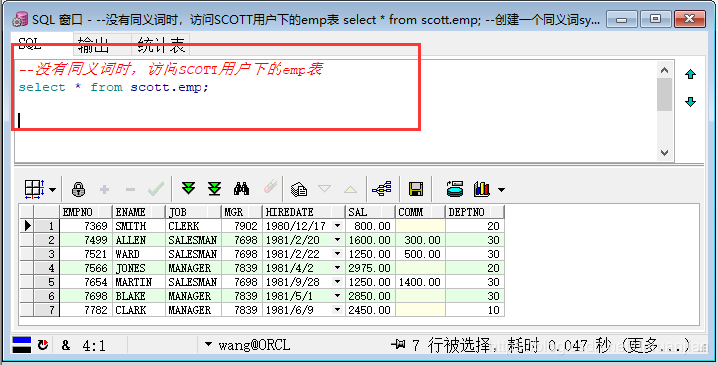
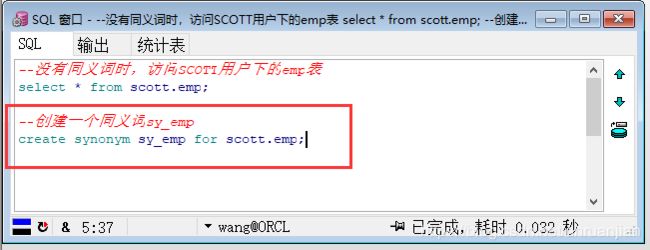
第三步:创建一个同义词sy_emp
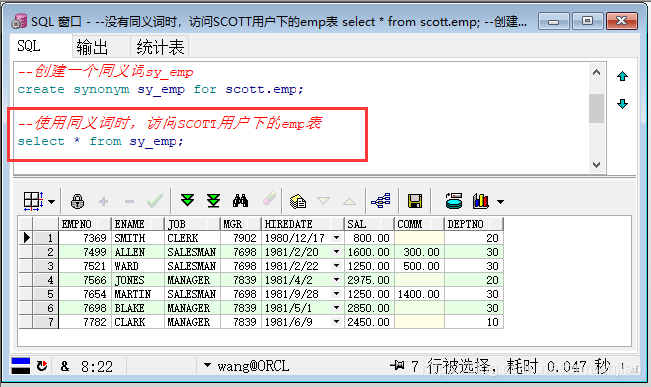
第四步:使用同义词时,访问SCOTT用户下的emp表
本案例完整代码:
--没有同义词时,访问SCOTT用户下的emp表
select * from scott.emp;
--创建一个同义词sy_emp
create synonym sy_emp for scott.emp;
--使用同义词时,访问SCOTT用户下的emp表
select * from sy_emp;
5、 序列
数据库表中的主键值有的时候我们会用数字类 型的并且自增。这样mysql、sql server中的都可以使用工具创建表的时候很容 易实现。但是oracle中没有设置自增的方法,一般情况我们会使用序列和触发器来实现主键自增的功能。
5.1 什么是序列
序列是oacle提供的,用于产生一系列唯一数字的数据库对象。序列通常用来自动生成主键或唯一键的值。序列可以按升序排列,也可以按降序排列。
5.2 序列的作用
- 自动提供唯一的数值
- 共享对象
- 主要用于提供主键值
- 将序列值装入内存可以提高访问效率
5.3 怎么创建序列
序列式用来生成唯一、连续的整数的数据库对象。例如,销售流水中的流水号可以使用序列自动生成。创建序列的语法:
CREATE SEQUENCE sequence_name
[START WITH integer]
[INCREMENT BY integer]
[MAXVALUE integer|NOMAXVALUE]
[MINVALUE integer|NOMINVALUE]
[CYCLE|NOCYCLE]
[CACHE integer|NOCACHE];语法说明:
- start with:指定要生成的第一个序列号。对于升序序列,其默认值为序列的最小值;对于降序序列,其默认值为序列的最大值。
- increment by:用于指定序列号之间的间隔,其默认值为 1。如果 n 为正值,则生成的序列将按照升序排列;如果 n 为赋值,则生成的序列将按降序排列。
- maxvalue:指定序列可以生成的最大值。
- NOMAXVALUE:如果指定了 NOMAXVALUE,Oracle 将升序序列的最大值设为 1027,将降序序列的最大值设为-1.这是默认选项。
- minvalue:指定序列的最小值。MINVALUE 必须小于或者等于 START WITH 的值,并且必须小于 MAXVALUE。
- NOMINVALUE:如果指定了 NOMINVALUE,Oracle 将升序序列的最小值设为 1,将降序序列的最小值设为-1026,这是默认选项。
- cycle:指定序列在达到最大值或最小值后,将继续从头开始生成值。
- NOCYCLE:指定序列在达到最大值或最小值后,将不能再继续生成值。这是默认选项。
- cache:使用 CACHE 选项可以预先分配一组序列号,并将其保留在内存中,这样可以更快的访问序列号。当用完缓存中的所有序列号时,Oracle 将生成另一组数值,并将其保留在缓存中。
- NOCACHE:使用 NOCACHE 选项,则不会为加快访问速度而预先分配序列号。如果在创建序列时忽略了 CACHE 和 NOCACHE 选项,Oracle 将默认缓存 20 个序列号。
例如:创建序列seq1。从序号 10 开始,每次增加 1,最大为 2000,不循环,再增加会报错,缓存 30 个序列号。
create sequence seq1
start with 10
increment by 1
maxvalue 2000
nocycle
cache 30;
示例练习6:练习序列的使用
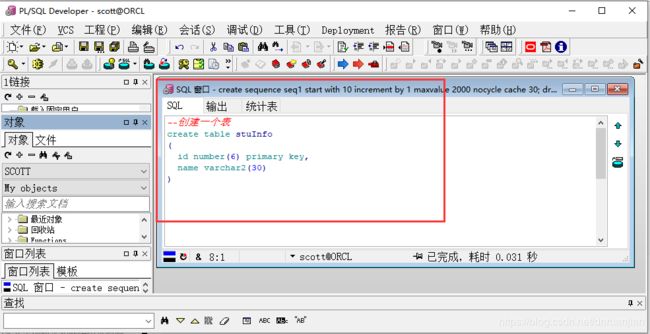
第一步:创建一个表stuInfo,输入SQL语句后,单击工具栏的执行按钮。
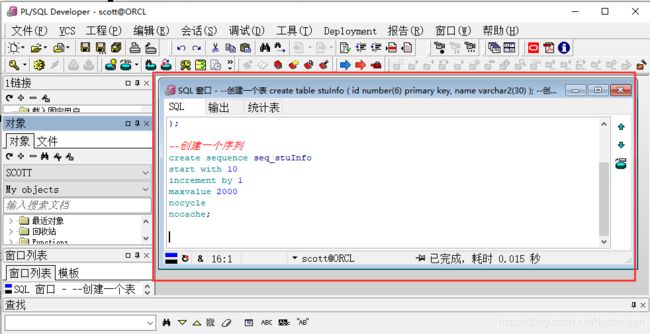
第二步:创建一个序列seq_stuInfo,输入SQL语句,然后单击工具栏的执行按钮。
第三步:使用序列seq_stuInfo,向stuInfo表中插入一行数据
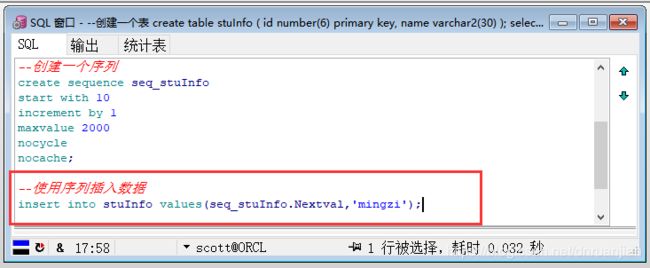
代码说明:oracle数据库中nextval用来获取序列号的下一个squence的值。
第四步:查询表stuInfo中的数据,发现插入一条语句。
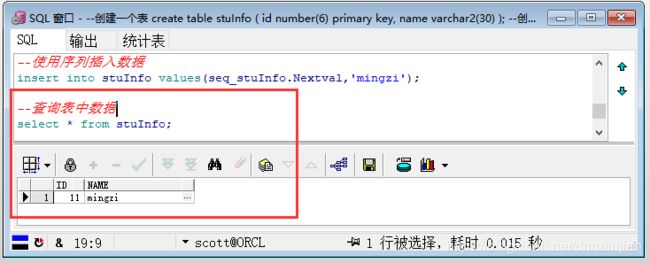
示例完整代码:
--创建一个表
create table stuInfo
(
id number(6) primary key,
name varchar2(30)
);
--创建一个序列
create sequence seq_stuInfo
start with 10
increment by 1
maxvalue 2000
nocycle
nocache;
--使用序列插入数据
insert into stuInfo values(seq_stuInfo.Nextval,'mingzi');
--查询表中数据
select * from stuInfo;
5.4 访问序列
创建了序列之后,可以通过 NEXTVAL 和 CURRVAL 伪列来访问该序列的值。可以从
伪列中选择值,但是不能操纵他们的值。下面分别说明 NEXTVAL 和 CURRVAL。
- NEXTVAL:创建序列后第一次使用 NEXTVAL 时,将返回该序列的初始值。以后再引用 NEXTVAL 时,将使用 INCREMENT BY 子句来增加序列值,并返回这个新值。
- CURRVAL:返回序列的当前值,即最后一次引用 NEXTVAL 时返回的值。
5.5 更改序列
ALTER SEQUENCE 命令用于修改序列的定义。如果执行下列操作,则会修改序列。
- 设置或删除 MINVALUE 或 MIAXVALUE。
- 修改增量值。
- 修改缓存中序列号的数目。
更改序列的语法:
ALTER SEQUENCE [schema.]sequence_name
[INCREMENT BY integer]
[MAXVALUE integer|NOMAXVALUE]
[MINVALUE integer|NOMINVALUE]
[CYCLE|NOCYCLE]
[CACHE integer|NOCACHE];注意:不能修改序列的 START WITH 参数。在修改序列时,应注意升序序列的最小值应小于最大值。
5.5 删除序列
DROP SEQUENCE 命令用于删除序列。还可以使用此语句重新开始一个序列,方法是先删除序列,然后在重新创建该序列。例如,一个序列的当前值为 100,现在想用值 25 重新开始此系列。此时,先可以删除此序列,然后以相同的名称重新创建它,并将 START WITH 参数设置为 25。
删除序列的语法:DROP SEQUENCE [schema.]sequence_name;
5.6 使用序列
可以使用序列设置 Oracle 的主关键字,所得值为从给定的起点开始的一系列整数值。序列所生成的数字只能保证在单个实例里是唯一的,这就不适合将它用作并行或者远程环境里的关键字,因为各自环境里的序列可能会生成相同的数字,从而导致冲突的发生。所以在不需要并行的环境中,可选择使用序列作为关键字。
还可以使用 SYS_GUID 函数生成 32 位的唯一编码作为主键。它源自不需要对数据库进行访问的时间戳和机器标识符,这回保证创建的标识符在每个数据库里的都是唯一的。但管理 SYS_GUID 生成的值必将困难,所以除非是在一个并行的环境里或者希望避免使用序列的情况下,才选择 SYS_GUID 来设置主关键字。 可以多运行几次以下代码来观察结果的变化。
SELECT SYS_GUID() FROM dual;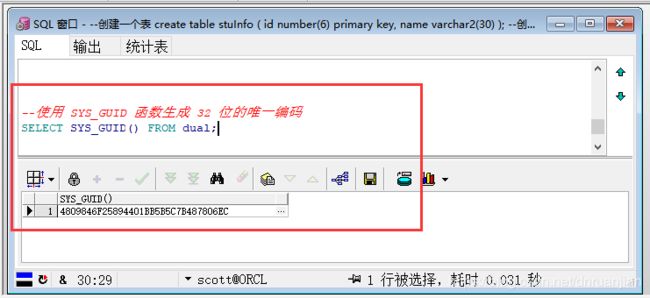
提示: 使用序列设置主关键字时,在数据库迁移时需要特别注意。由于迁移后的表中已经存在数据,如果不修改序列的起始值,将会在表中插入重复数据,违背主键约束。所以,在创建序列时要修改序列的起始值。
========这里是结束分割线=========