接口实现拉钩爬虫
拉勾网是个反爬措施比较多的网站,其中有许多需要我们调试分析学习的地方,本章就以拉钩网上遇见的问题进行分析,然后进行爬虫设计。
1. 网页分析
打开网页链接(这里我是用python关键字搜索的):
https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=
之后查看网页源代码,搜索岗位信息(Ctrl+f),发现我们所需的数据不在网页源代码中出现,而是通过ajax接口把数据传递过来的。拉钩网是一个典型的用ajax来写的网站。
分析网页查找传递数据的接口
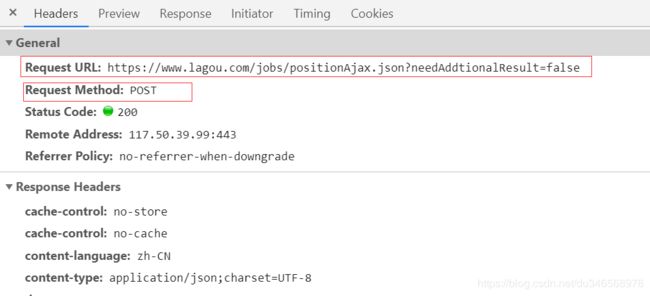
 之后查看网页的数据头信息:
之后查看网页的数据头信息:
2. 请求设计
从中我们可以知道请求的方式,请求的url,cookie,referer,data信息等,从而构建我们的请求头数据。之前我们在构建请求头的时候,有时候会习惯的只传递cookie,user-agent信息,然后会报错:{“status”:false,“msg”:“您操作太频繁,请稍后再访问”,“clientIp”:“113.94.81.141”},这倒不是操作频繁,而是检测到爬虫了,这是请求头信息不完善的问题,这里拉勾网还会检测Referer信息,如果没有的话,就会被检测到。
从这的学习,我们知道了有些网页的反爬的一种措施,之后可以注意一下,然后在不确定的时候可以采用笨的方法,请求头的数据全部传递。请求头的信息设计如下:
#此处需要设置Cookie,User-Agent,Referer,Accept(可以不设置),不然报操作频繁错误
urls = 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
'Referer':'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'Accept':'application/json, text/javascript, */*; q=0.01'
}
data = {
'first': 'false',
'pn':'1',
'kd': 'python'
}
#使用Session方法获取搜索页的cookie
s=requests.Session()
s.get(urls,headers=headers,timeout=3)
cookie = s.cookies
3. 获取url信息
在接口处查找提取我们所需的信息,检测找到的接口是否正确,然后通过分析,数据已json的格式存在preview。当然也可以将response中的数据复制粘贴在json.cn中,将传递的json数据格式化,进一步分析。
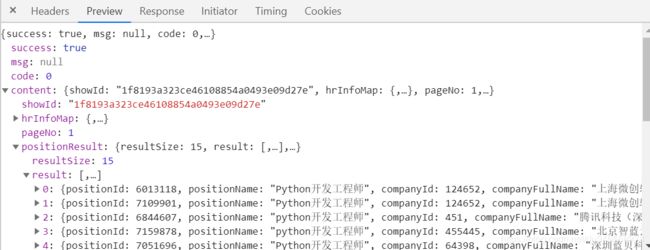
怎么获取数据呢? 我们可以通过获取返回的json内容,通过json的内容找到我们想要的数据,每个职位都有其详细信息的列表,我们这一步就是要获取其详细信息的列表,每个职位都有其固定的id信息,通过获取id信息,我们就可以拼凑出其url链接,实现代码如下:
def get_list_page():
# response = requests.post(url=url,headers=headers,data=data,cookies=cookie,timeout= 3)
# #json方法,如果返回的是json数据,那么这个方法可以直接load成字典
# print(response.json())
for x in range(10):
data['pn']=x
response = requests.post(url=url, headers=headers, data=data, cookies=cookie, timeout=3)
# print(response.json())
# time.sleep(1)
result = response.json()
positions = result['content']['positionResult']['result']
for position in positions:
positionID = position['positionId']
position_url = 'https://www.lagou.com/jobs/%s.html' % positionID
print(position_url)
prase_list_page(position_url)
time.sleep(10)
# break
break
4. 解析数据
在每个详细信息的页面,通过数据检查,发现网页源代码中可以查询到我们要爬取的数据信息,也就是说我们可以直接在网页上解析我们所要的数据,实现的代码如下:
def prase_list_page(url):
response = requests.get(url,headers=headers)
text = response.text
html = etree.HTML(text)
position_name = html.xpath('//div[@class="job-name"]/h1/text()')[0]
print(position_name)
job_request = html.xpath('//dd[@class="job_request"]//span')
#工资
salary = job_request[0].xpath('.//text()')[0].strip()
#城市
city = job_request[1].xpath('.//text()')[0]
city = re.sub(r'[\s/]','',city)
#年限
work_years = job_request[2].xpath('.//text()')[0]
work_years = re.sub(r'[\s/]','',work_years)
#学历
eduction = job_request[3].xpath('.//text()')[0]
eduction = re.sub(r'[\s/]','',eduction)
# 公司名字
company_name = html.xpath('//h3[@class="fl"]/em/text()')[0].strip()
desc = "".join(html.xpath('//dd[@class="job_bt"]//text()')).strip()
5. 总结
虽说我们通过这样的方法确实爬取到了工作的职位信息,但是还是有些问题需要解决,爬取几个岗位信息以后发现,报这样的错误:
 我们xpath语句并没有错,但是却没有匹配到信息,说明并没有提取到数据,说明我们的爬虫程序被检测到了,网页照常可以访问,但是爬虫程序却获取不到数据,就是我们爬虫程序的问题。这里排除检测,可能是我们的cookie信息可能失效了,需要更换cookie信息,由于本人没有好的cookie池,所以想要彻底实现拉钩爬虫这个项目的大兄弟可以在github或者买些cookie来解决。
我们xpath语句并没有错,但是却没有匹配到信息,说明并没有提取到数据,说明我们的爬虫程序被检测到了,网页照常可以访问,但是爬虫程序却获取不到数据,就是我们爬虫程序的问题。这里排除检测,可能是我们的cookie信息可能失效了,需要更换cookie信息,由于本人没有好的cookie池,所以想要彻底实现拉钩爬虫这个项目的大兄弟可以在github或者买些cookie来解决。
除此之外,可以选择selenium方法来实现本爬虫程序,就不需要为cookie信息头疼了。
整个代码的实现代码如下:
import time
from lxml import etree
import requests
import re
# 爬虫程序返回没有结果,爬取网页仍可以访问,说明爬虫程序被检测到了,最简单的方法:检测传递的参数(可能是cookie过期)
# ip地址被封的话,爬虫程序和网页都不能显示,
#此处需要设置Cookie,User-Agent,Referer,Accept(可以不设置),不然报操作频繁错误
urls = 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
'Referer':'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'Accept':'application/json, text/javascript, */*; q=0.01'
}
data = {
'first': 'false',
'pn':'1',
'kd': 'python'
}
#使用Session方法获取搜索页的cookie
s=requests.Session()
s.get(urls,headers=headers,timeout=3)
cookie = s.cookies
def get_list_page():
# response = requests.post(url=url,headers=headers,data=data,cookies=cookie,timeout= 3)
# #json方法,如果返回的是json数据,那么这个方法可以直接load成字典
# print(response.json())
for x in range(10):
data['pn']=x
response = requests.post(url=url, headers=headers, data=data, cookies=cookie, timeout=3)
# print(response.json())
# time.sleep(1)
result = response.json()
positions = result['content']['positionResult']['result']
for position in positions:
positionID = position['positionId']
position_url = 'https://www.lagou.com/jobs/%s.html' % positionID
print(position_url)
prase_list_page(position_url)
time.sleep(5)
# break
break
def prase_list_page(url):
response = requests.get(url,headers=headers)
text = response.text
html = etree.HTML(text)
position_name = html.xpath('//div[@class="job-name"]/h1/text()')[0]
print(position_name)
job_request = html.xpath('//dd[@class="job_request"]//span')
#工资
salary = job_request[0].xpath('.//text()')[0].strip()
#城市
city = job_request[1].xpath('.//text()')[0]
city = re.sub(r'[\s/]','',city)
#年限
work_years = job_request[2].xpath('.//text()')[0]
work_years = re.sub(r'[\s/]','',work_years)
#学历
eduction = job_request[3].xpath('.//text()')[0]
eduction = re.sub(r'[\s/]','',eduction)
# 公司名字
company_name = html.xpath('//h3[@class="fl"]/em/text()')[0].strip()
desc = "".join(html.xpath('//dd[@class="job_bt"]//text()')).strip()
if __name__ == '__main__':
get_list_page()