非法破解?击键声也会出卖你?嘘,小心隔墙有耳……
全文共5776字,预计学习时长17分钟

来源:Pexels
曾几何时,教会一台计算机辨认猫狗还是前沿研究。
而现在,图像分类只是机器学习的入门级,使用TensorFlow仅需几行代码即可完成。
事实上,机器学习领域在短短几年内已经取得了长足的进步,以至于使用它可以轻松的开发出潜在致命或救命的程序。因此,有必要讨论技术的使用与滥用问题,以期找到减少或阻止滥用的方法。
本文将说明该技术的一种潜在滥用可能——使用机器学习非法破解密码。

图1:听按键声音(图源:rawpixel.com;
为了更具体地说明,(请看图一),我们能通过键盘敲击声辨别出正在输入的内容吗?正如你所想的,其中存在一些潜在的安全隐患,比如非法破解密码。
因此我做了一个名叫Kido的项目(按键声解码)用于探究是否存在上述可能。(https://github.com/tikeswar/kido)
概述
该问题是一个有监督机器学习问题,我们将要完成以下几步。
1. 数据收集和前期准备。
2. 训练和项目评估。
3. 测试和错误分析(提高模型精确性)
4. 结论Github链接。
使用Python,Keras, TensorFlow完成该项目。
1.数据收集
首先考虑如何收集用于训练模型的数据?
有许多收集数据的方式,但为了证明这个想法是否可行,我使用MacBook Pro的键盘打字,并用QuickTime播放器通过内置麦克风录制打字声音(图2)。
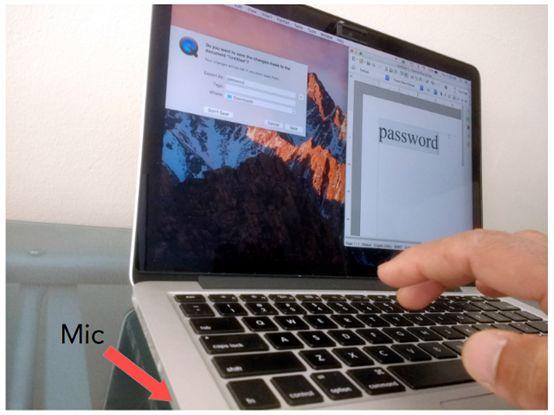
图2:使用MacBook制作训练用数据
该方法有两个好处,其一,数据差别较小,因此其二,可以帮助我们集中于证明想法是否可行,减少不必要的处理。
2. 数据准备
下一步对数据预处理,这样我们就可以将其输入神经网络(NN)进行训练。
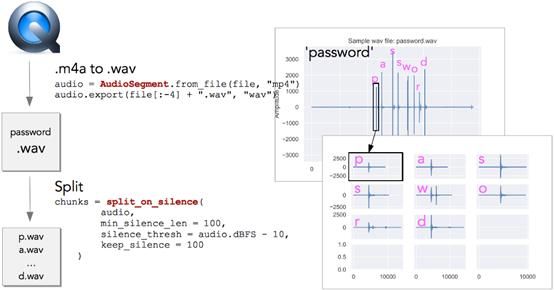
图3:将Mp4文件转换为Wav文件分割音频
Quicktime以mp4格式保存音频文件。由于Python有较好的处理Wav文件的库,我们首先将mp4转换为wav。右上角的每个峰值对应一个击键(见图3),然后通过静默检测将音频分割成独立的块,使得每个块只包含一个字母。现在我们可以把这些块输入到一个神经网络中。但是除上述方法外,还有一个更好的方法。

图4:将数据块转换成光谱图
将每一个数据块转换成光谱图(图4)。现在图像中包含更多信息,也更易使用卷积神经网络(CNN)对其进行处理。
为了训练网络,我收集了大约16000个样本,确保每个字母至少有600个样本。
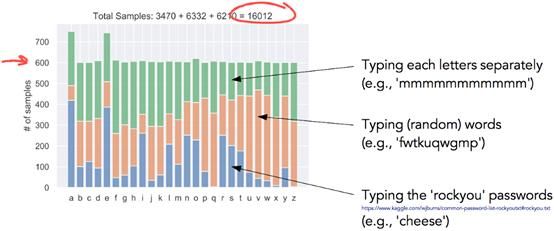
图5:数据样本
然后,将数据打乱并分成训练集和验证集。每个字母约有500个训练样本+ 100个验证样本(图6)。
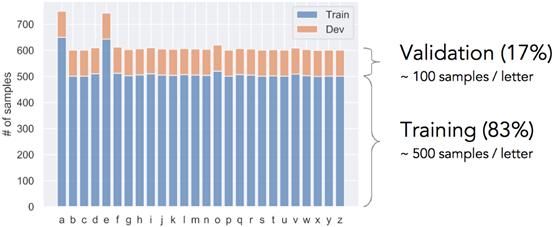
图6:训练集与验证集的分离。
因此,简而言之,图7是我们需要解决的机器学习问题。
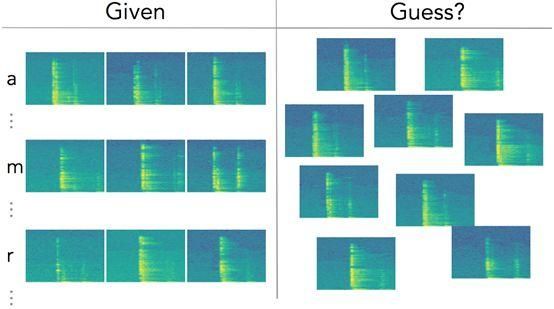
图7:问题简述
3. 训练和验证
我使用了一个相当小而简单的网络架构(基于Laurence Moroney的石头-纸张-剪刀的例子)。如图8所示,将图像缩放到150*150像素,它有三个颜色通道,经过一系列的卷积+池化层进行扁平化处理(使用droppout防止过度拟合)。随后将处理结果传送至全连接层,最后输出。输出层有26个类,对应每个字母。
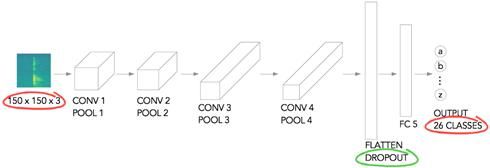
图8:网络架构
TensorFlow中的模型如下
model = tf.keras.models.Sequential([
# 1st convolution
tf.keras.layers.Conv2D(64, (3,3),activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
# 2nd convolution
tf.keras.layers.Conv2D(64, (3,3),activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# 3rd convolution
tf.keras.layers.Conv2D(128, (3,3),activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# 4th convolution
tf.keras.layers.Conv2D(128, (3,3),activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# Flatten the results to feed into aDNN
tf.keras.layers.Flatten(),
tf.keras.layers.Dropout(0.5),
# FC layer
tf.keras.layers.Dense(512,activation='relu'),
# Output layer
tf.keras.layers.Dense(26,activation='softmax')
])
模型概要:
_________________________________________________________________
Layer (type) OutputShape Param #
=================================================================
conv2d_4 (Conv2D) (None, 148,148, 64) 1792
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 74, 74, 64) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 72,72, 64) 36928
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 34,34, 128) 73856
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 15,15, 128) 147584
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None,6272) 0
_________________________________________________________________
dropout_1 (Dropout) (None,6272) 0
_________________________________________________________________
dense_2 (Dense) (None,512) 3211776
_________________________________________________________________
dense_3 (Dense) (None,26) 13338
=================================================================
Total params: 3,485,274
Trainable params: 3,485,274
Non-trainable params: 0
训练结果如图9所示。经过大约13轮学习,这一模型验证准确率达到80%,训练准确率达到90%。使用简单模型处理如此复杂的问题,却能获得这么高的准确率,我感到十分惊喜。
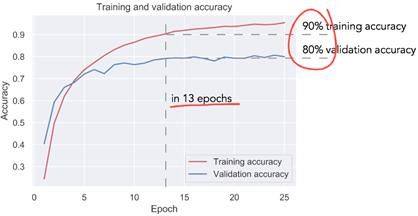
图9:训练与验证的准确性拟合结果
目前为止这个模型看起来很有效,但请注意这只是字符级而非单词级的准确性。
这意味着什么?如果要正确地猜测密码,必须准确预测每一个字符,而不是大部分字符!请看图10。
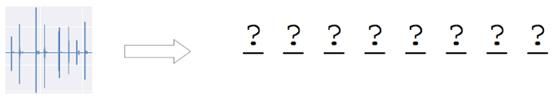
图10:猜密码
4.测试
因此,为了测试这个模型,我又从rock. txt列表中提取了200个不同的密码,然后尝试使用刚刚训练的模型来预测密码(图11)。
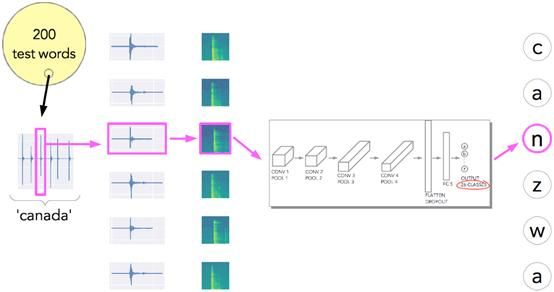
图11:测试模型
图12为测试准确率。柱状图显示了字符级的准确性(左边的图表显示了正确和错误的数量,而右边的图表显示的是同样的百分比)。字符级的测试正确率约为49%,单词级的测试正确率为1.5%(该网络在200个测试单词中有3个完全正确)。
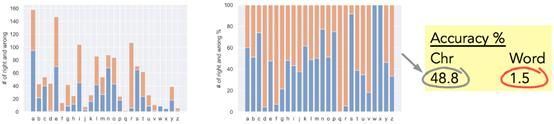
图12:测试精确率
考虑到任务的复杂性,1.5%的单词级准确度还不错,那么能不能进一步提高准确性呢?
误差分析
让我们分析个别误差,看是否有方法提高预测准确度。

图13: 测试结果样本
图13给出了一些样本测试结果。第一列包含实际的测试词,中间一列包含相应的预测词,其中各个字符用红色表示错误,绿色表示正确。第三列只显示正确预测的字符,用下划线替换错误预测的字符(以便于显示)。
对于单词“aaron”,模型只对了一个字符,对于“canada”,大部分字符正确,对于“lokita”,所有字符正确。如图12所示,单词级的准确率只有1.5%。
仔细看测试实例(图14),特别是“Canada”,可以辨别出其大部分是正确的,接近于实际单词。那么使用拼写检查器处理CNN的预测结果,将会发生什么?
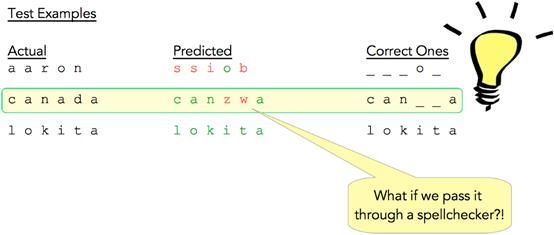
图14:对测试样品的想法
这正是我所做的(图15),这将准确率由1.5%提高到了8%,使用一个相当简单的模型架构以及一个拼写检查器,就可以实现百分之八的密码预测正确率,这个结果不容小觑。

图15:使用拼写检查器后
我认为,如果使用一个序列模型(RNN或者transformer模型),而不是简单的拼写检查,甚至可以得到更高的单词级准确性,这可以作为进一步研究的课题。
但是让我们更仔细地观察测试结果(图16)。注意到a被预测为s,n被预测为b,等等。
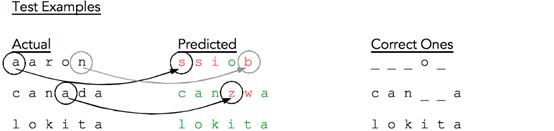
图16:对测试对象的进一步分析
那么如果根据这个预测错误构建映射呢?如果映射,误差是否会与接近度构成相关关系?似乎正是如此。
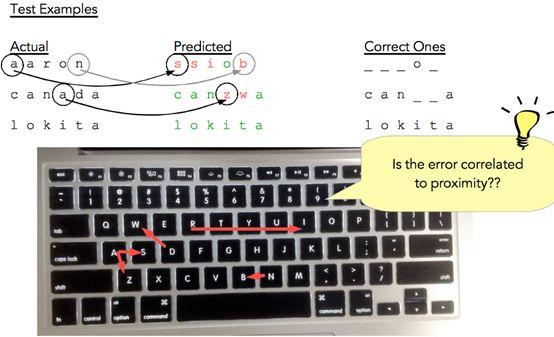
图17:构建键盘上的错误映射
接下来,我们能量化这种误差与邻近性的关系吗?
图18显示了带有麦克风的MacBook Pro键盘和按比例绘制的键位。图19显示了一些样本字母在键盘上的误差图。
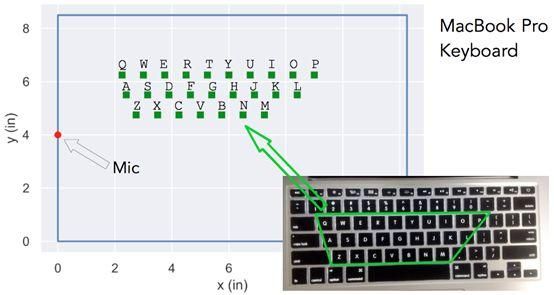
图18:带麦克风和按键位置的MacBook Pro键盘(按比例绘制)
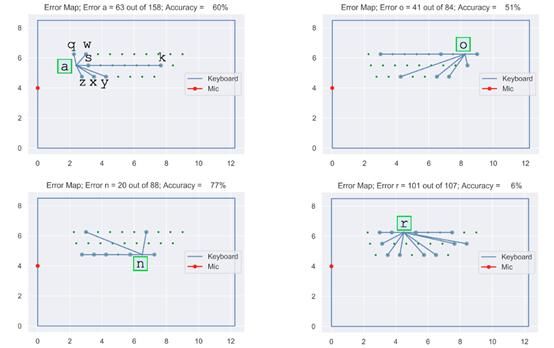
图19:所构建的映射
在图19中,左上角的图表明a常被错误地预测为“z,x,y,k,s,w,q”。其他三幅图表示其他字母的错误预测情况。
图19更清晰地表明,错误可能与字母与麦克风的距离差有关,然而,是否能得到更定量的测量方法呢?
用d_ref代表参考字母与麦克风的距离,d_predicted代表预测字母与麦克风的距离。d代表两个值之间差的绝对值。(见图20)
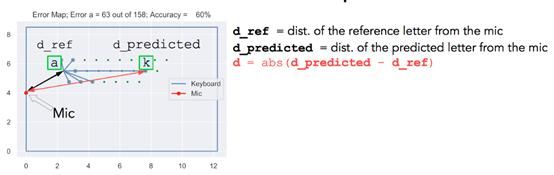
图20:一些定义
图21显示了d值与误差发生率关系的直方图。我们可以看到一个非常清晰的趋势,大多数的错误都来自于与麦克风相对距离较近的字母。这意味着我们可以通过更多的数据,更大更好的网络架构来提高模型的准确率。
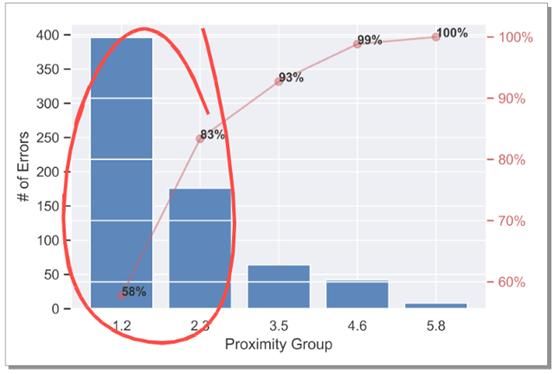
图21:w.r.t的d值误差直方图
那么麦克风位置,即麦克风与某个键的距离与误差率有关呢?为了研究这一点,我们重新排列了图12的误差率,使x轴上字母与麦克风之间的距离呈递增顺序,并未观察到太强相关性,这表明误差率与麦克风位置无关。
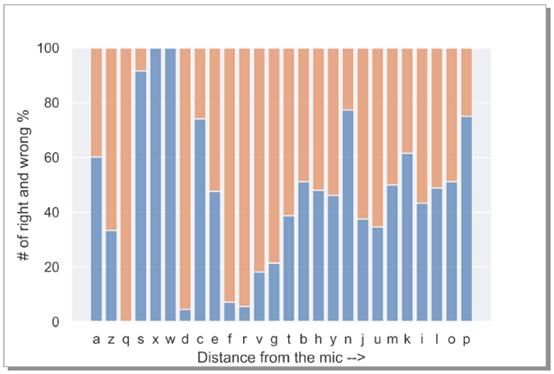
图22:错误与d_ref的关系
图22指出了极为重要的一点,可以将麦克风放置在任何位置窃听按键声以进行非法入侵!令人毛骨悚然。
模型改进
我对这一研究做了一些简化,只是为了验证仅仅通过键盘声非法破解密码的想法是否可行。针对更复杂的实际情况,下面给出了一些改进想法。
·正常打字速度——造成信号处理(需要隔离单个按键声),在上述研究中,我每次只缓慢输入了一个字母。
·任意按键——造成信号处理困难(如Capslock,shift等)。在上述研究中,我只输入了小写字母。(没有输入任何大写字母、数字、特殊字符、特殊按键等)。
·背景噪音——导致噪音干扰。上述研究中只有一些简单且较轻的车辆行驶噪声,没有更复杂的背景噪声。(如咖啡厅背景噪声)
·不同的键盘、麦克风设置以及不同的打字者——更多的数据,更大、种类更多的网络架构有助于改进模型。
·可以使用其他的振动信号代替音频信号吗?

来源:Pexels
结论
考虑到上述简化研究,得出以下结论。
1. 通过击键声音破解密码似乎是可行的
2. 通过少量数据与简单的CNN架构以及拼写检查,可以获得较高的单词级准确性。(本研究中为8%)。
3. 误差分析
*简单的拼写检查可以大幅提高单词级别的准确性(在本例中从1.5%提高到8%)
*误差与键与键之间的接近程度相关
*误差与麦克风的位置无关
Github链接: https://github.com/tikeswar/kido
附:注意你的击键声,隔墙有耳!


留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)