Marcus十大理由质疑深度学习?LeCun说大部分错了

大数据文摘作品
作者:Aileen, 魏子敏,钱天培,龙牧雪
昨天下午,一直对深度学习持质疑态度的纽约大学教授、人工智能创业者Gary Marcus在arxiv上发布了一篇长文,列举十大理由,质疑深度学习的局限性,在AI学术圈又掀起了一轮波澜。
Gary Marcus文章地址:
https://arxiv.org/ftp/arxiv/papers/1801/1801.00631.pdf
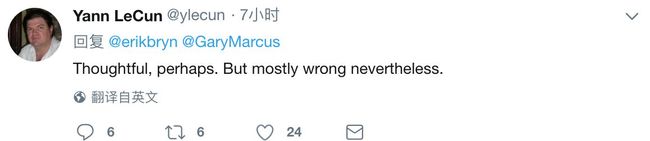
而就在刚刚,一直对Gary Marcus这一观点持反对态度的Facebook人工智能研究中心负责人Yann LeCun发推文“怼”了这一论调,称“有想法,可能吧,但是,大部分都错了“(Thoughtful, perhaps. But mostly wrong nevertheless.)。
似乎听到了LeCun的冷笑……作者很礼貌地回复:“您能不能详细说说哪里错了?我们之前辩论的时候您可不是这么说的。”
当然不只是简单质疑,推文下观战的各位也不安分的呼喊LeCun说出更多质疑理由,LeCun在之后又发推叙述了自己的观点:“不正确,Gary混淆了‘深度学习’和‘监督学习’。”

图注:LeCun怼的是Jason Pontin的“支持Gary"的转推,值得一提的是,Jason曾经在MIT科技评论任职主编。
现在美国时间已是深夜,我们期待LeCun在深思熟虑后给出更多想法,可能也会写出一篇20几页的长文也不一定呢。
Gary Marcus和Yann LeCun关于“深度学习”的争执由来已久。去年,两人还曾经公开就此问题辩论了两个小时,文摘菌当时细看了整个视频,全程观点犀利、逻辑缜密,让人佩服。来不及等LeCun观点的同学也欢迎戳下边的视频先看看两人的辩论?
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1.7647058823529411" data-w="480" data-src="http://v.qq.com/iframe/player.html?vid=j0528tgkmh8&width=670&height=376.875&auto=0" style="display: block; width: 670px !important; height: 376.875px !important;" width="670" height="376.875" data-vh="376.875" data-vw="670" src="http://v.qq.com/iframe/player.html?vid=j0528tgkmh8&width=670&height=376.875&auto=0"/>
在去年的辩论中,Marcus和LeCun都坦言,深度学习当前还远不能实现简单的常识推理。LeCun甚至表示,如果在他的有生之年,深度学习在常识推理方面的智能能够达到一只小老鼠的水平,那他也就心满意足了。
然而,对于深度学习发展的何去何从,两人却产生了不小的分歧。Marcus认为深度学习应该更全面地借鉴人类探索认知世界的方式,加入更多对物体、集合、空间等的认识表示,而LeCun则认为深度学习并不需要太多地模拟人类的认知方式。
去年两人的讨论更多的是对深度学习未来发展之争,孰是孰非皆未可知。而这次两人的争论则似乎更有看头——Marcus本次质疑的是深度学习当前发展现状,是一场基于事实的讨论。两人此次再度怼上,输赢恐怕终有一个分晓。
让我们也回顾一下Gary Marcus这篇发布在arxiv上,长达27页的文献质疑了深度学习的哪些问题,仅摘录了部分精彩观点:
1.深度学习至今缺少足够的数据。
人类可以在一些尝试后学习抽象关系。但深度学习不具备这种学习抽象概念的能力,其需要依赖大量数据。深度学习目前缺乏通过明确的语言定义来学习抽象概念的机制,在DeepMind开发棋类和Atari游戏AI的工作中,有成千上万甚至数十亿的训练样例时效果最好。
正如Brenden Lake和他的同事最近在一系列论文中强调的那样,人类学习复杂规则要比深度学习系统更有效率。
2.深度学习至今仍不够深入,且在迁移度上存在很大局限。
尽管深度学习能够带来一些惊人的成果,但重要的是要认识到,深度学习中的“深度”一词指的是技术特性(在现代神经网络中使用了大量的隐藏层),而不是一个概念。
Robin Jia和Percy Liang(2017)最近的实验是语言领域的一个例子。神经网络在一个被称为SQUAD(斯坦福问答应答数据库)的问题回答任务上进行了训练,其目标是突出特定段落中对应于给定问题的单词。例如,通过一个已训练的系统,可准确地识别出超级碗 XXXIII 的胜利者是 John Elway。但 jia 和 Liang 表明,仅靠插入干扰句(例如宣称谷歌的 Jeff Dean 在另一个杯赛中获得了胜利)就可以让准确率大幅下降。在 16 个模型中,平均准确率从 75% 下降了到了 36%。
通常情况下,深度学习提取的模式,比最初的模式更肤浅。
3.现在的深度学习并没有能够处理层次化结构的方法。
至少目前来说,深度学习无法学到层次结构。
深度学习学到的是各种特征之间的相关性,这些特征本身是“平坦的”或非分层的,就好像在一个简单的非结构化列表中一样,每个特征都是平等的。层次结构(例如,识别句法结构中的主要从句和嵌入式从句)在这样的系统中并不能被直接表示,因此深度学习系统被迫使用其他代理变量,例如序列中呈现的单词的顺序位置。
相对而言,像Word2Vec(Mikolov,Chen,Corrado,&Dean,2013)这样的将单个词汇表示为向量的系统表现更好。另一些系统试图在矢量空间中表示完整的句子(Socher,Huval,Manning,&Ng,2012),但是,正如Lake和Baroni的实验所表明的那样,循环神经网络难以处理丰富的层次结构。
4.深度学习至今无法解决开放性的推理问题。
如果你不能理解“John promised Mary to leave” 和 “John promised to leave Mary”之间的细微差别,那么你不能推断谁是谁离开了谁,或者接下来可能发生什么。
目前的机器阅读系统已经在“问答”这样的任务中取得了一定程度的成功,其中对于给定问题的答案被明确地包含在文本中,但是在推理超出文本的任务时却很少成功。组合多个句子(所谓的多跳推理)或通过组合明确的句子与没有在特定文本选择中陈述的背景知识,对于深度学习还很难。
5.深度学习还不够透明。
“黑箱”神经网络的相对不透明性一直是过去几年讨论的重点(Samek,Wiegand,&Müller,2017; Ribeiro,Singh,&Guestrin,2016)。
目前的深度学习系统有几百万甚至几十亿的参数,对开发人员来说,很难使用人类可解释的标签(“last_character_typed”)来标注它们,而仅仅能描述它们在一个复杂的网络中的位置(例如,网络模块k中第j层的第i个节点的活动值)。
尽管在复杂网络中可以看到个体节点的贡献(Nguyen,Clune,Bengio,Dosovitskiy和Yosinski,2016),但大多数研究者都承认,整个神经网络仍然是一个黑盒子。
6.深度学习尚未能很好地结合先验知识。
深度学习的主要方法是解释学,也即,将自我与其他潜在有用的知识隔离开来。
深入学习的工作通常包括,找到一个训练数据库,与各个输出相关联的输入集,通过学习这些输入和输出之间的关系,通过调参等方式,学习解决问题的方法。有些研究会主动弱化先验知识,比如以 LeCun 为代表的神经网络连接约束等研究。
人们可以很容易地回答“威廉王子和他那还没几岁的儿子乔治王子谁高”这样的问题。你可以用衬衫做沙拉吗?如果你把一根别针插入一根胡萝卜,它是在胡萝卜还是在别针上留下一个洞?据我所知,没有人会试图通过深度学习来解决这类问题。这些显而易见的简单问题需要人类将知识整合到大量不同的来源中。如果要达到人类认知的灵活性,除了深度学习,我们还需要另一个完全不同的工具。
7.深度学习还无法区分“因果关系”和“相关性”。
因果关系和相关性是两个不同的概念,这两者的区别也是深度学习面临的一个严重问题。粗略地说,深度学习学习输入和输出特征之间的复杂关联,但没有固有的因果表示。
比如,把人类作为整体数据,深度学习可以很容易地学习到,“身高”和“词汇量”是相互关联的,但不能说这种相关性来自“长大(growth)“和”发展(development)”。孩子们在学习更多的单词时也在长大,但这并不意味着,长大会使他们学习更多的单词,也不是说,学习新的单词使他们长大。
因果关系在人工智能的其他一些方法中是中心因素(Pearl,2000),但深度学习的核心不是应对这一任务的,所以深度学习很少考虑这一问题。
8.深度学习在一个环境稳定的世界里表现最好,然而现实往往并非如此。
深度学习在高度稳定的世界中表现很好,比如棋盘类游戏,因为其有着不变的规则,而在政治和经济这类不断变化的问题上,表现很有限。
如果在诸如股票预测等任务中应用深度学习,那么很有可能出现Google预测流感趋势的命运:一开始在搜索趋势方面预测流行病学数据方面做得很好,但是却无法预测出像2013年流感季节高峰的出现(Lazer,Kennedy,King,&Vespignani,2014)。
9. 当你需要一个近似的结果时,深度学习效果不错,但不能完全信赖这些结果。
深度学习系统在某个特定领域,表现会比较优秀,但很容易被愚弄。
越来越多的论文显示了这种脆弱性,从上面提到的语言学例子、到视觉领域的例子,都反映了这一问题。在Nguyen,Yosinski和Clune在2014年的一篇论文中,深度学习将黄黑相间的条纹误以为校车,将带有贴纸的停车标志误以为装满食品的冰箱。
10.深度学习仍很难被工程化。
从上面提出的所有问题还会引出另一个事实,那就是深度学习很难被着真正稳健地工程化。
Google的一个作者团队在2014的一篇文章中提到,机器学习就好像“ 有着高利息的技术债务信用卡”,意思是说,我们可以相对容易地使系统在一些有限的环境下工作(短期收益),但是很难保证他们能够在可能与以前的训练数据不相似的新数据的情况下工作(长期债务)。
正如Google的Peter Norvig(2016)所指出的那样,机器学习仍然缺乏经典编程的渐进性,透明性和可调试性,在实现稳健性方面面临着挑战。 Henderson及其同事最近对这些观点进行了扩展,重点强调了深入的强化学习,并指出了与稳健性和可复制性有关的一些严重问题。尽管自动化机器学习系统的开发已经取得了一些进展,但还有很长的路要走。

志愿者介绍
回复“志愿者”加入我们



往期精彩文章
点击图片阅读
2018AI行业地图丨CB Insights:这100家AI初创公司募资额超百亿