实践:在运维大数据这事上,Apache Kylin比ELK更擅长?

题图: from Zoommy
记得十年前,我曾问过一名应用运维工程师,如何用两个关键词描述下自己的日常工作?
他居然不假思索,略带调侃的回答我, “背锅” 与 “惊醒”,随即愣了一下,改口说,“发布” 与 “排障”。
的确,在人肉化运维时代,“你的软件是否支持傻瓜式运维?” 似乎成为了一种判定系统可运维能力的标准,找个应届生,懂点Linux命令,上传下JAR包,执行下开发给你写好的脚本,或是给你搞个WEB导航栏,东按一下,西按一下,报错了?找开发解决就行了。
多年前,许多人都预测在不久的将来,DevOps将彻底取代传统运维,但我却不以为然,总觉得运维人员更应该提升在自动化方面的能力,并学习和钻研在不同应用场景中如何平稳落地,不能生搬硬套,说白了,就是学会如何利用自动化工具,更大程度的节省人力。
但如果系统规模越来越大,复杂度越来越高,自动化程度达到一定高度之后,“如何利用数据代替机器决策、分析?如何基于大数据技术,帮助在告警过滤、异常监测、自动修复等环节发挥效用,提高整体运维效率,降低运维成本?”,就会成为你下一阶段的探索目标。
对许多企业来说,这是一个漫长的演进过程。在2018年,在部分中间件系统的监控、故障趋势与定位、资源使用等场景中,我们尝试基于Apache Kylin做了一些探索,通过本文分享给大家。
当时中间件运维的监控现状
在很长一段时间里,我们的运维监控都是基于Zabbix和ELK这两个工具。
Zabbix,用于监视各种网络参数,保证服务器系统的安全运营,并提供灵活的通知机制。

通过上图可以看到,我们基本用Zabbix来监控一些基础标准服务,什么网络呀,磁盘,内存等等。
既然是工具,总有它的局限性,虽然Zabbix支持API二次开发,但对开发能力与精力投入有一定要求,因此,如果你的系统中带有自定义协议,并还想增加一些监控逻辑的话,一般不会选择Zabbix进行处理。
如果按概率计算,由基础架构引发的故障毕竟是小概率事件,大部分的异常都是由应用缺陷或BUG引起的,而现在的应用又越拆越碎,越拆越细,大量的开源系统纵横交错,一旦问题爆发,基本很难在第一时间定位问题根源。

在这样的情况下,我们选择ELK,希望通过对系统日志、 应用日志、安全日志的收集、分析、定位来找到故障原因,提高诊断的效率,同时对系统情况有个全面的理解,避免事后救火的被动。

图1. 分布式缓存(A组代理层)的日志流水
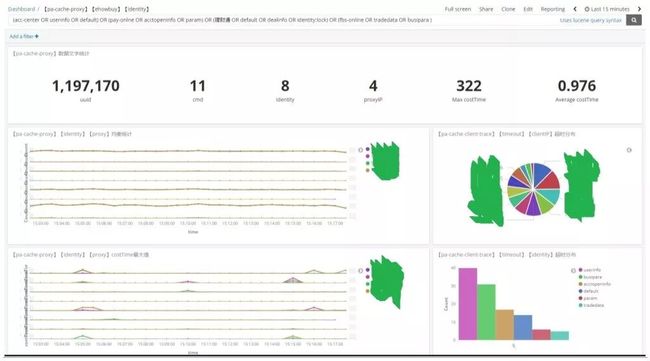
图2. 分布式缓存(A组代理层)的统计汇总页
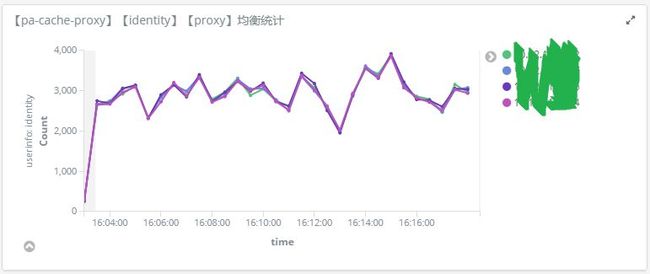
图3. 分布式缓存(A组代理层)的流量均衡
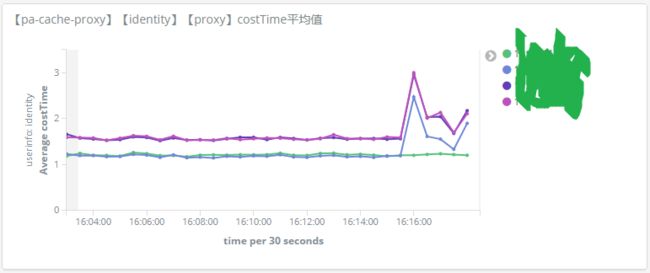
图4. 分布式缓存(A组代理层)的平均耗时
乍看之下,故事讲到这就应该圆满结束了。因为我们似乎找到了解决方案,毕竟ELK有着强大的强大的搜索功能,完美的展示功能,还具有分布式特性,能够解决大型集群运维工作很多问题。
为什么不在ELK这条路上一黑到底?
去年听过某期《逻辑思维》,主题叫 “限制也能激发创造力?”。
当时听完,没什么太大的触动,只觉得故事挺精彩,观点很新奇。
2018年下半年,互联网寒冬悄悄来袭,金融行业首当其冲,我们开始对IT资源的投入进行合理的调整。
第一条,便是 “无特殊需求,不再采购新服务器”。
大家都明白,系统的演进是一个不断采坑与填坑的过程,加之应用越拆越碎,越拆越细,如果你系统的部署不在容器云上,且不具备弹性伸缩的能力,光靠普通的虚拟化技术是无法达到硬件资源相对程度的最大利用率的。
通过购买新服务器来进行短时间缓冲、中转,在搞技术的小伙伴看来,似乎是一件合情合理的事情。
但在老板的眼中,业务没变化,流量没增加,花钱投资硬件?你们觉得合适吗?没毛病。
此时,我才开始逐渐领悟 “限制也能激发创造力?” 的真正含义。
有人说,应用拆分、ELK、购买引荐,这三者之间有啥关系?何况你谈的是中间件,还不是应用,你太会扯淡了吧。
先别急着喷,下面我来通过一个案例进行说明下。
对ELK有了解的人都知道,ELK,是ElasticSearch、Logstash、Kibana的组合,其中,ElasticSearch(以下简称ES)主要负责提供搜集、分析、存储数据三大功能,也就是说一切的日志分析都是由ES来完成的。
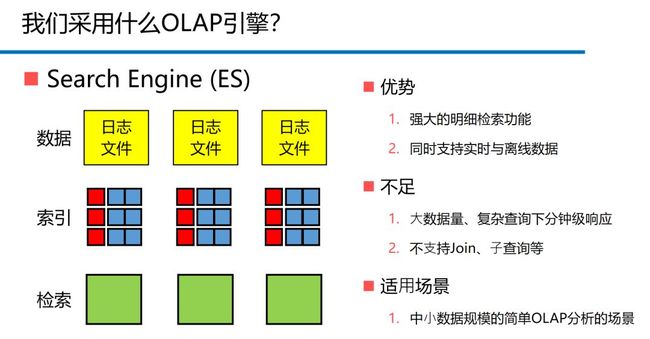
图5. ES的优势、不足与适用场景
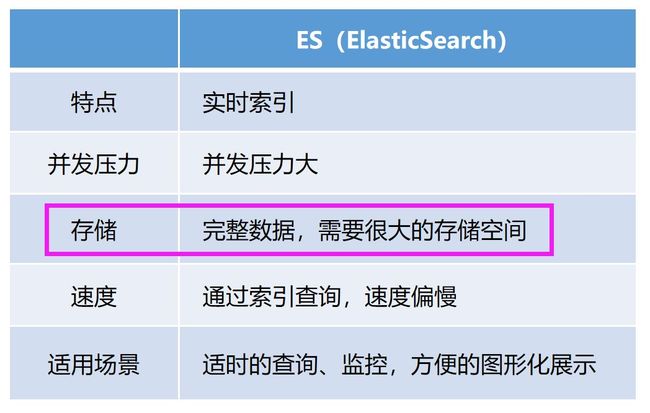
图6. ES的一些技术特点
把别的先搁一边,咱们先来算一笔存储空间的账。
由于ES的明细检索功能是依赖完整数据的,所以就需要大量的存储空间,保存的时间轴越久,空间就越大。单就缓存中间件来说,每天的PV总量 > 1亿,高峰期更是惊人。如果想存储这些日志,每天至少需要40G的存储空间,如果想分析30天就需要1.2T,再算上硬盘阵列Raid5,一个月至少需要占用1.8T空间。
然而,这只是缓存中间件系统的需求,再加上其他中间件及应用线,真是杯水车薪。
因此,我们只能勉强满足3天以内的使用量,面对与日俱增的需求,水涨船高的业务,显然不是长久之计。

图7. ES的硬件资源
为此,我们整理了中间件运维分析场景的一些特点,试图寻找更适合的解决方案。
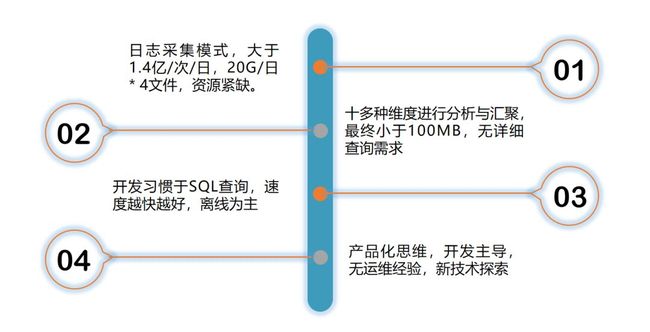
为什么选择Apache Kylin?
因一次偶然的机会,我们接触到Apache Kylin,在一番短暂的学习之后,觉得这正是我们所寻找的。
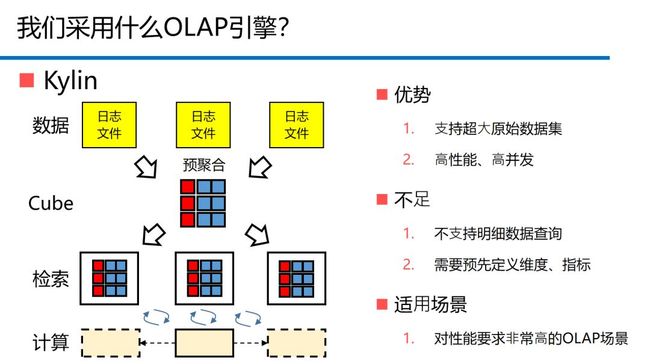
图8. Kylin的优势、不足与适用场景
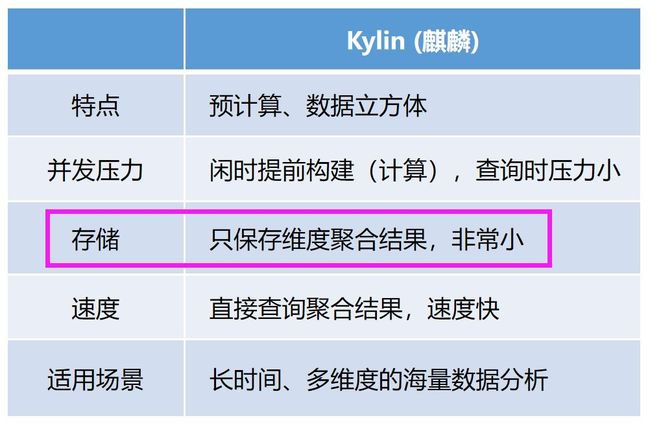
图9. Kylin的一些技术特点
当然,技术不是算卦,或者是一拍大腿的买卖,加之我的性格更偏向行动性,找几个场景开动起来,或许会有更多的收获。
随着对Kylin研究的深入,我们发现它不仅可以满足我们的需求,并且相比ELK还有很多方面的优势。
| 存储空间的优势
对我们这种体量说大不大,说小不小,且对成本又极其铭感的场景来说,最大的诱惑力是存储空间占用的非常的少,因为只保留计算的结果。
以计算了10天12亿多条的数据来举例,只需占用了不到20MB的存储空间,而原来ELK保存这些日志数据需要400G。
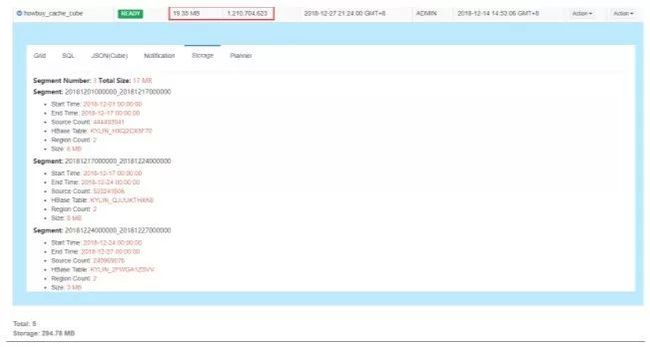
图10. Kylin - 某结果集大小快照
| 查询速度的优势
因为采用预计算技术,所以几乎所有的查询都是亚秒级响应。
但由于尝试的业务场景更偏离线分析,所以对这块暂时并不特别关注。
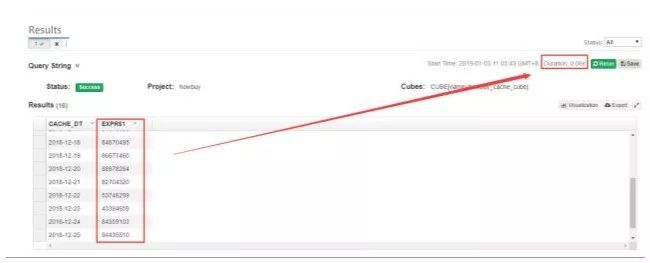
图11. Kylin - 对某结果集的查询速度
任何事物总有两面性,在短暂的尝试后,也发现了一些Kylin对我们来说的劣势。
| 技术栈比较深
由于大数据对技术深度要求高(比如hadoop生态圈),而且对技术人员的经验和阅历的要求也不低,因此,相对应的拉高了对特定人才的需求。
不仅如此,ELK部署简单,操作简便,学习成本低。而大数据技术那么热门,面对这种说高不高,说低不低的技术场景,太好的人才则不愿来,培养起来的人才又留不住。
毕竟人这东西,是世界上最难管的物件。
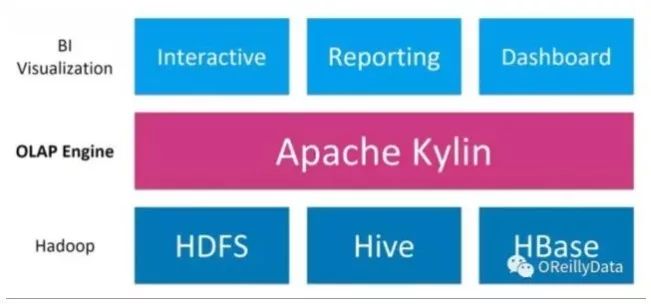
图12. Hadoop生态与Kylin
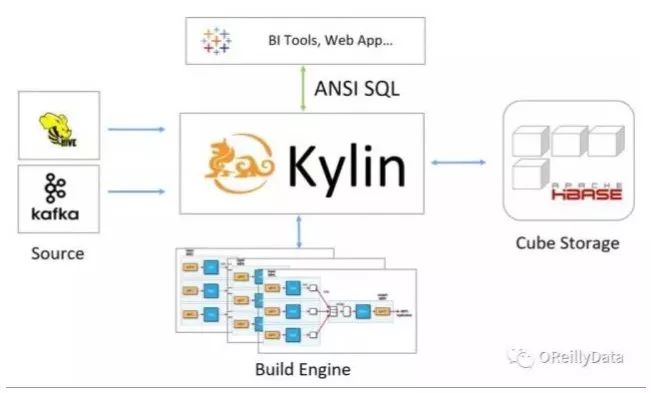
图13. Kylin的整体架构
| 更适合离现场景,实时场景欠佳
虽然Kylin有很多第三方插件,支持类似Spark这样的实时计算解决方案,但对于特定人才的要求就会更高,这也是我们无法应对的。
如果同样采用定时间隔触发这样的手段,Kylin的实时性却没有ELK高,只能满足分钟级这样的场景。
对于实时性要求较高的监控需求,显然是不合适的。
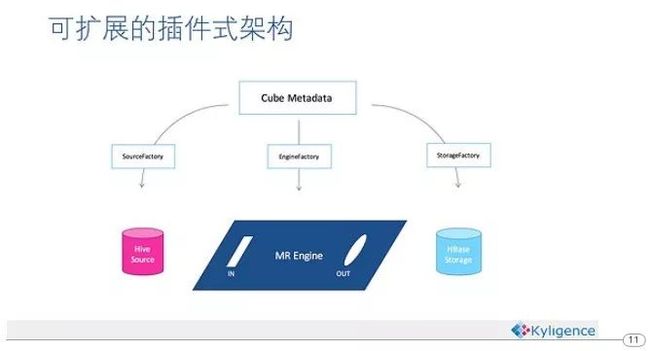
图14. Kylin的插件式架构
| 开源的不够友好,商业的成本太高
既然是开源项目,Kylin的错误显示与流程操作显然还不够友好,排错也比较困难。
当然,Kyligence提供的基于Apache Kylin的企业级大数据智能分析平台,可以满足几乎所有的场景,可以说是终极解决方案。
但对于我们现在的成本状况,显然就更不合适了。
基于Apache Kylin的阶段性成果
经过几个月的努力,基于Kylin的相关分析业务已经陆续上线。
为了不对其它业务造成影响(主要是存储池和算力池),我们把Kylin单独部署在一台独立的PC服务器上。

图15. 虚拟化节点划分
通过普通虚拟化技术,将3台4核8G作为控制节点,主要用来部署hadoop相关的控制节点、zookeeper、kafka、mysql等,还有3台8核16G的虚拟机作为计算节点,主要用来跑MapReduce任务。
技术微创新就是如此神奇,谁能想到我们居然能在相同数据量级的前提下,在这样6台虚拟机共用64G内存的情况下,跑出了5项新指标:
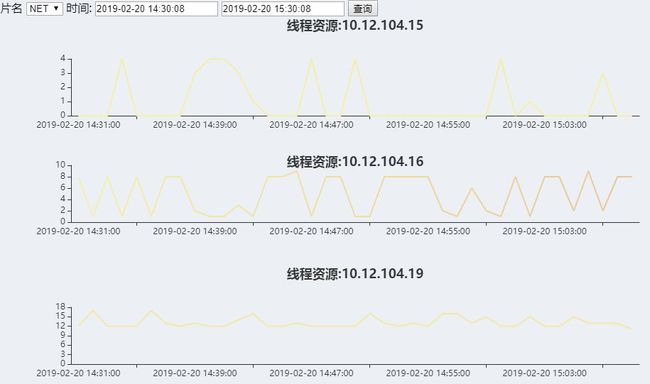
1、分布式调度系统的线程控制
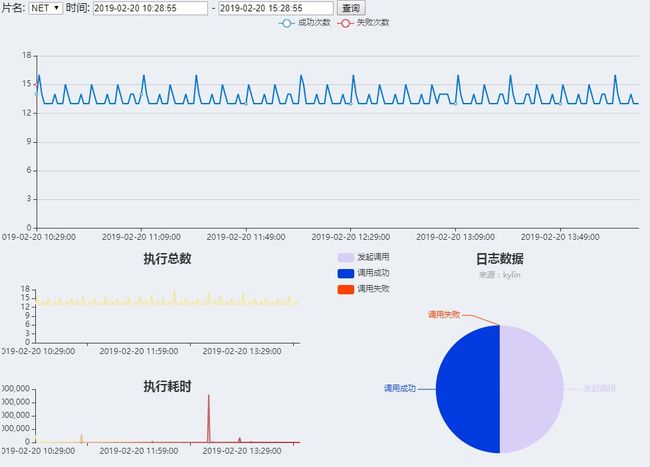
2、分布式调度系统的执行耗时趋势
3、分布式调度系统的执行计划

4、分布式缓存(A组代理层)的流量趋势(每分钟)
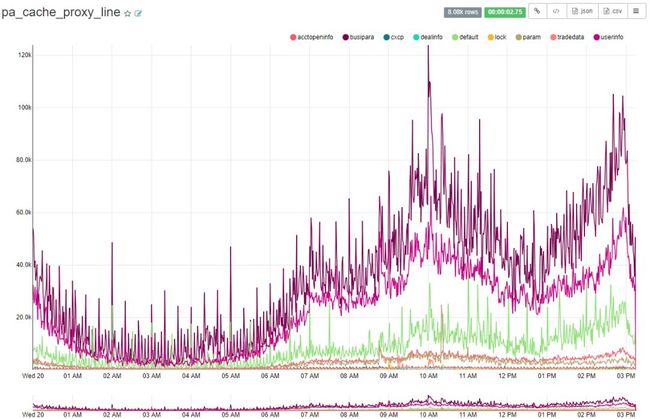
5、分布式缓存(A组客户端)的流量趋势(每分钟)
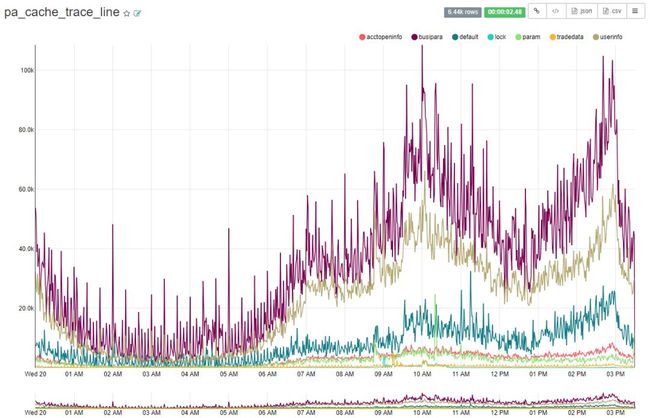
这些指标已在生产环境正常运行了100天以上,目前运行状态良好。
此外,调度系统更是利用ECharts把监控集成到了调度控制台中,不仅彻底解决了存储空间有限,无法长期分析的问题,在对cpu和内存的依赖上也降低很多。
写 在 最 后
也许有人会觉得,如果类似需求出现在他们公司,完全不需要用这样笨重的技术栈加以实现,写俩脚本,搞俩命令行就能搞定,这纯属没事找事。
总的来说,使用Apache Kylin的确存在 “为了技术而技术” 的嫌疑,毕竟中小型公司更愿意选择 “ELK+脚本” 这样轻量级的解决方案。
但在我看来,在成本受限的大背景下,与其认命,还不如选择探索,只要满足节省成本的前提下,追求功能探索与技术渴望,又何尝不是一种选择呢?
再说了,局部性尝试而已,就算失败,也是一种成长。
难道不是吗?
转载自:吃草的罗汉
资源下载
关注公众号:数据和云(OraNews)回复关键字获取
2018DTCC , 数据库大会PPT
2018DTC,2018 DTC 大会 PPT
ENMOBK,《Oracle性能优化与诊断案例》
DBALIFE ,“DBA 的一天”海报
DBA04 ,DBA 手记4 电子书
122ARCH ,Oracle 12.2体系结构图
2018OOW ,Oracle OpenWorld 资料
产品推荐云和恩墨Bethune Pro企业版,集监控,巡检,安全于一身,你的专属数据库实时监控和智能巡检平台,漂亮的不像实力派,你值得拥有!
云和恩墨zData一体机现已发布超融合版本和精简版,支持各种简化场景部署,零数据丢失备份一体机ZDBM也已发布,欢迎关注。