mp4格式介绍
时间基
系统默认的H264的time_base= num=1/den=90000
mp4文件的time_base= num=1/den=12800 flv文件的time_base=num=1/den=1000
本节重点讲stbl,跟实践两部分。

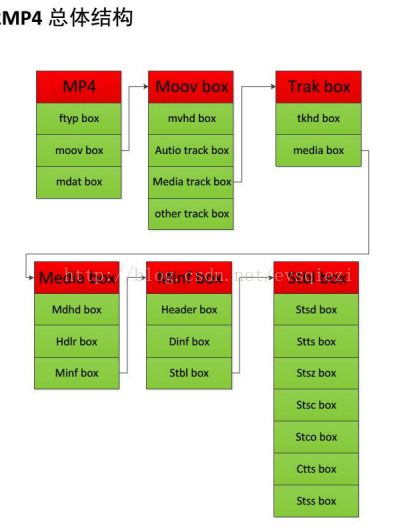
详细结构如下:
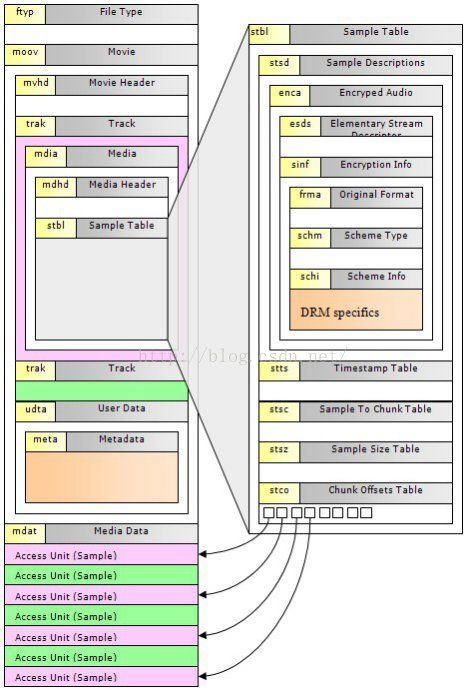
常见概念
box
MP4文件中的所有数据都装在box(QuickTime中为atom)中,也就是说MP4文件由若干个box组成,每个box有类型和长度,可以将 box理解为一个数据对象块。box中可以包含另一个box,这种box称为container box。一个MP4文件首先会有且只有一个“ftyp”类型的box,作为MP4格式的标志并包含关于文件的一些信息;之后会有且只有一个“moov”类 型的box(Movie Box),它是一种container box,子box包含了媒体的metadata信息;MP4文件的媒体数据包含在“mdat”类型的box(Midia Data Box)中,该类型的box也是container box,可以有多个,也可以没有(当媒体数据全部引用其他文件时),媒体数据的结构由metadata进行描述。
标 准的box开头的4个字节(32位)为box size,该大小包括box header和box body整个box的大小,这样我们就可以在文件中定位各个box。如果size为1,则表示这个box的大小为large size,真正的size值要在largesize域上得到。(实际上只有“mdat”类型的box才有可能用到large size。)如果size为0,表示该box为文件的最后一个box,文件结尾即为该box结尾。(同样只存在于“mdat”类型的box中。)
象块。box中可以包含另一个box,这种box称为container box。
size后面紧跟的32位为box type,一般是4个字符,如“ftyp”、“moov”等,这些box type都是已经预定义好的,分别表示固定的意义。如果是“uuid”,表示该box为用户扩展类型。如果box type是未定义的,应该将其忽略。
“ftyp” body依次包括1个32位的major brand(4个字符),1个32位的minor version(整数)和1个以32位(4个字符)为单位元素的数组compatiblebrands。这些都是用来指示文件应用级别的信息。该box的字节实例如下:
![]()
Movie Box(moov)
该box包含了文件媒体的metadata信息,“moov”是一个container box,具体内容信息由子box诠释。同File Type Box一样,该box有且只有一个,且只被包含在文件层。一般情况下,“moov”会紧随“ftyp”出现。
一般情况下(限于篇幅,本文只讲解常见的MP4文件结构),“moov”中会包含1个“mvhd”和若干个“trak”。其中“mvhd”为header box,一般作为“moov”的第一个子box出现(对于其他container box来说,header box都应作为首个子box出现)。“trak”包含了一个track的相关信息,是一个container box。下图为部分“moov”的字节实例,其中红色部分为box header,绿色为“mvhd”,黄色为一部分“trak”。
“mvhd”结构如下表。
| 字段 |
字节数 |
意义 |
| box size |
4 |
box大小 |
| box type |
4 |
box类型 |
| version |
1 |
box版本,0或1,一般为0。(以下字节数均按version=0) |
| flags |
3 |
|
| creation time |
4 |
创建时间(相对于UTC时间1904-01-01零点的秒数) |
| modification time |
4 |
修改时间 |
| time scale |
4 |
文件媒体在1秒时间内的刻度值,可以理解为1秒长度的时间单元数 |
| duration |
4 |
该 track的时间长度,用duration和time scale值可以计算track时长,比如audio track的time scale = 8000, duration = 560128,时长为70.016,video track的time scale = 600, duration = 42000,时长为70 |
| rate |
4 |
推荐播放速率,高16位和低16位分别为小数点整数部分和小数部分,即[16.16] 格式,该值为1.0(0x00010000)表示正常前向播放 |
| volume |
2 |
与rate类似,[8.8] 格式,1.0(0x0100)表示最大音量 |
| reserved |
10 |
保留位 |
| matrix |
36 |
视频变换矩阵 |
| pre-defined |
24 |
|
| next track id |
4 |
下一个track使用的id号 |
“mvhd”的字节实例如下图,各字段已经用颜色区分开:

track
表示一些sample的集合,对于媒体数据来说,track表示一个视频或音频序列。
hint track
这个特殊的track并不包含媒体数据,而是包含了一些将其他数据track打包成流媒体的指示信息。
sample
对于非hint track来说,video sample即为一帧视频,或一组连续视频帧,audio sample即为一段连续的压缩音频,它们统称sample。对于hint track,sample定义一个或多个流媒体包的格式。
sample table 指明sampe时序和物理布局的表。
chunk
一个track的几个sample组成的单元。
1、 ftypbox,在文件的开始位置,描述的文件的版本、兼容协议等;
2、 moovbox,这个box中不包含具体媒体数据,但包含本文件中所有媒体数据的宏观描述信息,moov box下有mvhd和trak box。
>>mvhd中记录了创建时间、修改时间、时间度量标尺、可播放时长等信息。
>>trak中的一系列子box描述了每个媒体轨道的具体信息。
3、 moofbox,这个box是视频分片的描述信息。并不是MP4文件必须的部分,但在我们常见的可在线播放的MP4格式文件中(例如Silverlight Smooth Streaming中的ismv文件)确是重中之重。
4、 mdatbox,实际媒体数据。我们最终解码播放的数据都在这里面。
5、 mfrabox,一般在文件末尾,媒体的索引文件,可通过查询直接定位所需时间点的媒体数据。

“stbl”包含了关于track中sample所有时间和位置的信息,以及sample的编解码等信息。利用这个表,可以解释sample的时序、类 型、大小以及在各自存储容器中的位置。“stbl”是一个container box,其子box包括:sample description box(stsd)、time to sample box(stts)、sample size box(stsz或stz2)、sample tochunk box(stsc)、chunk offsetbox(stco或co64)、composition time to sample box(ctts)、sync sample box(stss)等。
Sample Description Box(stsd)
box header和version字段后会有一个entry count字段,根据entry的个数,每个entry会有type信息,如“vide”、“sund”等,根据type不同sample description会提供不同的信息,例如对于video track,会有“VisualSampleEntry”类型信息,对于audio track会有“AudioSampleEntry”类型信息。
视频的编码类型、宽高、长度,音频的声道、采样等信息都会出现在这个box中,详见实践部分的例子。
“stsd”必不可少,且至少包含一个条目,该box包含了datareference box进行sample数据检索的信息。没有“stsd”就无法计算media sample的存储位置。“stsd”包含了编码的信息,其存储的信息随媒体类型不同而不同。
Time To Sample Box(stts)
“stts” 存储了sample的duration,描述了sample时序的映射方法,我们通过它可以找到任何时间的sample。“stts”可以包含一个压缩的 表来映射时间和sample序号,用其他的表来提供每个sample的长度和指针。表中每个条目提供了在同一个时间偏移量里面连续的sample序号,以及samples的偏移量。递增这些偏移量,就可以建立一个完整的time tosample表。
Sample Size Box(stsz)
“stsz” 定义了每个sample的大小,包含了媒体中全部sample的数目和一张给出每个sample大小的表。这个box相对来说体积是比较大的。
Sample To Chunk Box(stsc)
用chunk组织sample可以方便优化数据获取,一个chunk包含一个或多个sample。“stsc”中用一个表描述了sample与chunk的映射关系,查看这张表就可以找到包含指定sample的chunk,从而找到这个sample。
Sync Sample Box(stss)
“stss” 确定media中的关键帧。对于压缩媒体数据,关键帧是一系列压缩序列的开始帧,其解压缩时不依赖以前的帧,而后续帧的解压缩将依赖于这个关键帧。 “stss”可以非常紧凑的标记媒体内的随机存取点,它包含一个sample序号表,表内的每一项严格按照sample的序号排列,说明了媒体中的哪一个 sample是关键帧。如果此表不存在,说明每一个sample都是一个关键帧,是一个随机存取点。
Chunk Offset Box(stco)
“stco” 定义了每个thunk在媒体流中的位置。位置有两种可能,32位的和64位的,后者对非常大的电影很有用。在一个表中只会有一种可能,这个位置是在整个文 件中的,而不是在任何box中的,这样做就可以直接在文件中找到媒体数据,而不用解释box。需要注意的是一旦前面的box有了任何改变,这张表都要重新 建立,因为位置信息已经改变了。
5、Free Space Box(free或skip)
“free”中的内容是无关紧要的,可以被忽略。该box被删除后,不会对播放产生任何影响。
6、Meida Data Box(mdat)
该box包含于文件层,可以有多个,也可以没有(当媒体数据全部为外部文件引用时),用来存储媒体数据。数据直接跟在box type字段后面,具体数据结构的意义需要参考metadata(主要在sample table中描述)。
普通MP4文件的结构就讲完了。
另一篇文章讲的更清楚。
MP4,全称是MPEG4 Part 14,是一种使用MPEG-4的多媒体文件格式,扩展名为.mp4。
MOV,是QuickTime影片格式,它是Apple公司开发的一种音频、视频文件格式,用于存储常用数字媒体类型。其扩展名为.mov。
在MOV和MP4文件格式中包括几个重要的Table,对应的atoms分别为:stts、ctts、stss、stsc、stsz以及stco/co64。
1、Sample时间表stts
stts:Time-To-Sample Atoms,存储了媒体sample的时常信息,提供了时间和相关sample之间的映射关系。该atom包含了一个表,关于time和sample号之间的索引关系。表的每个entry给出了具有相同时间间隔的连续的sample的个数和这些sample的时间间隔值。将这些时间间隔相加在一起,就可以得到一个完整的time与sample之间的映射。将所有的时间间隔相加在一起,就可以得到该track的时间总长。
每个sample的显示时间可以通过如下的公式得到:
D(n+1) = D(n) + STTS(n)
其中,STTS(n)是sample n的时间间隔,包含在表格中;D(n)是sample n的显示时间,应该是显示时长。
Time-To-Sample的table entry布局如图1-1所示:
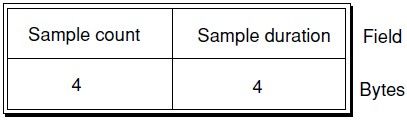
图1-1 Time-To-Sample的table entry布局
Table entries根据每个sample在媒体流中的顺序和时长对他们进行描述。如果连续的samples有相同的时长,他们会被放在同一个table entry中。特别的,如果所有的sample具有相同的时长,那么table中就只有一个entry。
一个简单的例子如图1-2所示。这个媒体流包括9个samples,通过3个entries来描述。需要说明的一点是,这里的entry和chunk不是对应的。比如,sample 4、5和6在同一个chunk中,但是,由于他们的时长不一样,sample 4的时长为3,而sample 5和6的时长为1,因此,通过不同的entry来描述。

图1-2 关于Time-To-Sample的一个简单例子
2、时间合成偏移表ctts
ctts:Composition Offset Atom。每一个视频sample都有一个解码顺序和一个显示顺序。对于一个sample来说,解码顺序和显示顺序可能不一致,比如H.264格式,因此,Composition Offset Atom就是在这种情况下被使用的。
(1)如果解码顺序和显示顺序是一致的,Composition Offset Atom就不会出现。Time-To-Sample Atoms既提供了解码顺序也提供了显示顺序,并能够计算出每个sample的开始时间和结束时间。
(2)如果解码顺序和显示顺序不一致,那么Time-To-Sample Atoms既提供解码顺序,Composition Offset Atom则通过差值的形式来提供显示时间。
Composition Offset Atom提供了一个从解码时间到显示时间的sample一对一的映射,具有如下的映射关系:
CT(n) = DT(n) + CTTS(n)
其中,CTTS(n)是sample n在table中的entry(这里假设一个entry只对应一个sample)可以是正值也可是负值;DT(n)是sample n的解码时间,通过Time-To-Sample Atoms计算获得;CT(n)便是sample n的显示时间。
Composition Offset Atom的table entry的布局和Time-To-Sample Atoms的一样,如图2-1所示:

图2-1 Composition Offset Atom的table entry布局
3、同步Sample表stss
stss:Sync Sample Atom,标识了媒体流中的关键帧,提供了随机访问点标记。Sync Sample Atom包含了一个table,table的每个entry标识了一个sample,该sample是媒体流的关键帧。Table中的sample号是严格按照增长的顺序排列的,如果该table不存在,那么每一个sample都可以作为随机访问点。换句话说,如果Sync Sample Atom不存在,那么所有的sample都是关键帧。
Sync Sample Table的布局如图3-1所示:
图3-1 Sync Sample Table的布局
4、Chunk中的Sample信息表stsc
stsc:Sample-To-Chunk Atom。为了优化数据访问,通常把sample封装到chunk中,一个chunk可能会包含一个或者几个sample。每个chunk会有不同的size,每个chunk中的sample也会有不同的size。在Sample-To-Chunk Atom中包含了个table,这个table提供了从sample到chunk的一个映射,每个table entry可能包含一个或者多个chunk。Table entry包含的内容包括第一个chunk号、每个chunk包含的sample的个数以及sample的描述ID。Sample-To-Chunk Atom的table entry布局如图4-1所示。

图4-1 Sample-To-Chunk Atom的table entry布局
每个table entry包含一组chunk,enrty中的每个chunk包含相同数目的sample。而且,这些chunk中的每个sample都必须使用相同的sample description。任何时候,如果chunk中的sample数目或者sample description改变,必须创建一个新的table entry。如果所有的chunk包含的sample数目相同,那么该table只有一个entry。
一个简单的例子,如图4-2所示。图中看不出来总共有多少个chunk,因为entry中只包含第一个chunk号,因此,对于最后一个entry,在某些情况下需要特殊的处理,因为无法判断什么时候结束。

图4-2 一个关于Sample-To-Chunk table的例子
5、Sample大小表stsz
stsz:Sample Size Atom,指定了每个sample的size。Sample Size Atom给出了sample的总数和一张表,这个表包含了每个sample的size。如果指定了默认的sampe size,那么这个table就不存在了。即每个sample使用这个默认的sample size。sample size table的布局如图5-1所示。

图5-1 sample size table的布局
6、Chunk的偏移量表stco/co64
stco/co64:Chunk Offset Atom,指定了每个chunk在文件中的位置。Chunk Offset Atom包含了一个table,表中的每个entry给出了每个chunk在文件中的位置。有两种形式来表示每个entry的值,即chunk的偏移量,32位和64位。如果Chunk Offset Atom的类型为stco,则使用的是32位的,如果是co64,那么使用的就是64位的。chunk offset table的布局如图6-1所示。

图6-1 chunk offset table的布局
需要注意的是,table中只是给出了每个chunk的偏移量,并没有给出每个sample的偏移量。因此,如果要获得每个sample的偏移量,还需要用到Sample Size Table和Sample-To-Chunk Table。
实践
以下是ISO/IEC14496-12 4.2对于box的定义。
aligned(8) class Box(unsigned int(32) boxtype, optional unsigned int(8)[16]extended_type) { unsigned int(32) size;
unsigned int(32) type =boxtype;
if (size==1) { unsigned int(64)largesize;
} else if (size==0){
// box extends to end offile
}
if (boxtype==‘uuid’) {
unsigned int(8)[16] usertype =extended_type;
}
}
stss解析
/////////////////Begin sync Sample Box(stss)部分的解析 /////////////////////////////
00 00 00 70 //4字节 Box size /*0x70=112*/
73 74 73 73 //4字节 Box type /*0x73747373=’stss’*/
00 //1字节 version
00 00 00 //3字节 flag
00 00 00 18 //4字节 Number of entries /*数量*/
00 00 00 01 00 00 00 FB
00 00 01 F5 00 00 02 EF 00 00 03 E9 00 00 04 E3
00 00 05 DD 00 00 06 D7 00 00 07 D1 00 00 08 CB
00 00 09 C5 00 00 0A BF 00 00 0B B9 00 00 0C B3
00 00 0D AD 00 00 0E A7 00 00 0F A100 00 10 9B
00 00 11 95 00 00 12 8F 00 00 13 89 00 00 14 83
00 00 15 7D 00 00 16 77
/////////////////end sync Sample Box(stss)部分的解析 /////////////////////////////
![]()
如上图,24标识共有32个字节,05标识由5个关键帧,01标识视频第一个帧,A3标识视频第163个帧。
stsd
首先熟悉stsd box的标准规范,参考ISO/IEC 14496-12,stsd box(The sample description table gives detailed information about the coding type used, and any initialization information needed for that coding. 即定义了视频/音频解码相关的参数,如h264的sps,pps)。stsd box的数据结构用类SampleDescriptionBox去描述。SampleDescriptionBox定义在ISO/IEC 14496-12中
结构如下:

例子如下,96为阴影部分的长度。
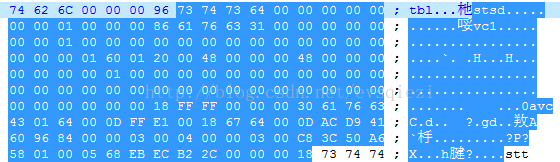
这个box中包含的音频的采样率,声道,样本,视频的sps,pps等信息,这些信息的结构可以看官方文档
如图:

视频:AVC sequence header就是AVCDecoderConfigurationRecord结构,该结构在标准文档“ISO-14496-15 AVC file format”中有详细说明。
stts
结构如下:

如果多个sample有相同的duration,可以只用一项描述所有这些samples,数量字段说明sample的个数。例如,如果一个视 频媒体的帧率保持不变,整个表可以只有一项,数量就是全部的帧数。
例1: 视频
entry_count:1
sample_count:37 //上面已经有duration时间了,duration指整个mdat中video的时长,这里37却为chunks数目
sample_delta:1001 //1001 * 37=37037 sample_delta*sample_count=duration
例2: 音频
sentry_count:1
sample_count:67 //音频分了67个chunks
sample_delta:1024 //同上
例子:
![]()
stsc
字段
| 长度(字节) |
描述 |
|
| 尺寸 |
4 |
这个atom的字节数 |
| 类型 |
4 |
stsc |
| 版本 |
1 |
这个atom的版本 |
| 标志 |
3 |
这里为0 |
| 条目数目 |
4 |
sample-to-chunk的数目 |
| sample-to-chunk |
|
sample-to-chunk表的结构 |
| First chunk |
4 |
这个table使用的第一个chunk序号 |
| Samples per chunk |
4 |
当前trunk内的sample数目 |
| Sample description ID |
4 |
与这些sample关联的sample description的序号 |
例子:

问题:如何区分mp4格式里面mdat中的音频和视频数据
首先在minf里面有个vmhd和smhd,那么vmhd代表视频,smhd代表音频
然后在stsz中
stsz Box
00 00 73 D8 size of stsz,20
73 74 73 7A: stsz
00 00 00 00: version
00 00 00 00: sample-size
00 00 1C F1: sample-count
00 00 86 24(从此开始,为当前chunk中每帧视频数据的字节大小,此大小与offset相对应,用offset找到偏移的绝对地址(指向mdat box中)后,从000001B6的第一个字节开始,加上对应的视频字节数,就是本帧的大小。一个视频chunk中首先是连续的视频帧,然后也包含其他数据,暂不清楚视频数据后面的数据类型)
00 00 08 F9 //第一个视频帧的位置
00 00 3B 04 //第二个视频帧的位置
00 00 1D F2
面试题目
为何moov头在尾部的mp4可以快速播放、拖动
根据moov box得到的关键帧的字节偏移量,采用range请求来请求