全国人工智能大赛 行人重识别(Person ReID)赛项 季军团队方案分享

全国人工智能大赛-行人重识别(Person ReID)赛项-季军团队由5名博士生组成,该次比赛初赛和复赛阶段的代码后续将整理开源,敬请期待!
团队名称:DMT
团队成员:
罗浩、何淑婷、 古有志、 王珊珊、 张宇琪
赛题任务

给定一张含有某个行人的查询图片,行人重识别算法需要在行人图像库中查找并返回特定数量的含有该行人的图片。评测方法:50%首位准确率(Rank-1 Accuracy)+50% mAP(mean Average Precision)
和鲸科技赛事主页:
https://www.kesci.com/home/competition/5d90401cd8fc4f002da8e7be
方案分享
初赛
在初赛阶段,我们团队以之前发表在TMM和CVPRW2019的ReID strong baseline作为baseline(已开源,补充信息1),针对初赛数据集进行了适应和改进。
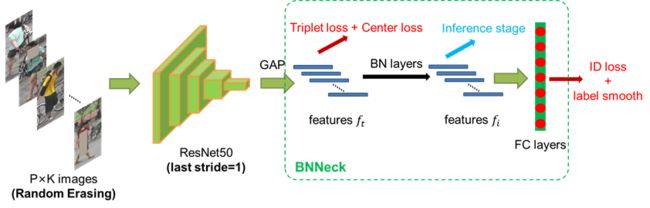
这篇ReID strong baseline主要在之前的baseline上,创新地提出了BNNeck的结构,解决了ID loss和triplet loss不会同步收敛的问题,并配合一些常见的训练技巧,使得模型的分数在Market1501可以达到94.5%的Rank1和85.9%的mAP。
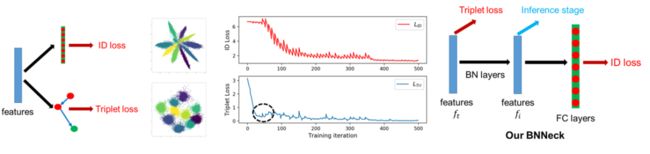
在ReID strong baseline基础上,针对初赛的数据集,进行针对性的改进,如下:
1、数据预处理:适应比赛数据集
光照增广、随机擦除、随机Crop、随机翻转等
处理长尾数据、增大Image Size
2、ID Loss:增强generalization
Cross Entropy → Arcface
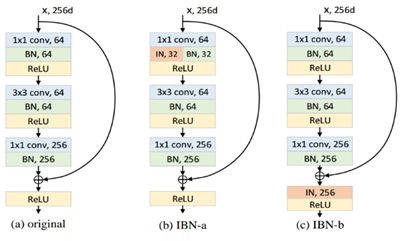
3、模型替换:增强capacity
ResNet50 → ResNet101-IBN-a, ResNet101-IBN-b
4、优化器:更快的收敛
Adam → Ranger
5、重排序:提高准确度
K-reciprocal Re-ranking & Query Expansion
Test set augmentation
复赛
问题描述
复赛阶段,我们着重解决以下3个问题问题:
1、第一个问题,也是此次比赛的核心:Unsupervised Domain Adaptation (UDA),即训练集和测试集分布不一致。
2、大规模:训练集85K图像,测试集166K图像。由于需要引入测试集进行无监督训练,所以后处理需要大量计算资源。
3、可复现:复赛赛题中,对于复现有时间和空间复杂度要求:48h,1GPU,90G内存,需要考虑如何充分利用时间和计算力。
基于数据集的情况,我们统计了三通道像素值的均值和方差,将数据分成了3个部分(ABC域),其中测试集中的C域在训练中从未出现,因为是一个UDA的问题。

UDA问题,有两大类的方法解决,一类是GAN-Based对应的是source domain,另一类是Clustering-Based对应的是target domain。GAN-Based缺点是训练稳定性较差,质量难以保证,Clustering-Based缺点是通常需要迭代式聚类整个Target Domain。考虑到Clustering-Based方法在性能上更加鲁棒,且GAN模块训练需要消耗时间,它所带来的涨点是否值得也需要考虑,所以我们聚类这种思路。学术界定义的UDA问题中测试集只有target domain,而比赛的测试集既有source domain也有target domain,并没有一个很好的方法可以直接应用在现有的数据集上。

JT-PC框架
为了UDA的问题,我们设计了渐进式无监督聚类联合训练算法(Joint Training and Progressive Clustering ,JT-PC),主要结构如下:
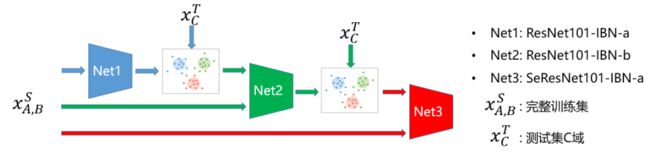
1、使用全部训练数据训练模型1,模型1使用Resnet101-ibn-a,在训练集上直接训练。
2、对图像进行均值和方差统计,将训练集分为A域和B域,将测试集分为A域和C域。利用模型1对测试集C域进行无监督聚类构造伪标签。
3、训练模型2,模型2使用Resnet101-ibn-b,训练集包括两部分,一部分为去除单张图像的无长尾训练集,一部分为步骤2中标注的C域伪标签测试集。
4、使用模型2对测试集C域再次构造伪标签。
5、训练模型3,模型3采用SeResnet-ibn-a,训练集包括两部分,一部分为无长尾训练集,一部分为步骤4中挑选的伪标签测试集。
6、对三个模型进行测试,并使用reranking重排,然后ensemble三个模型的结果。
其中构造伪标签的部分步骤为:
1、以Query为中心,根据距离阈值进行聚类得到伪标签。
2、针对被打上多个伪标签的Outlier,取距离最小的中心为伪标签。
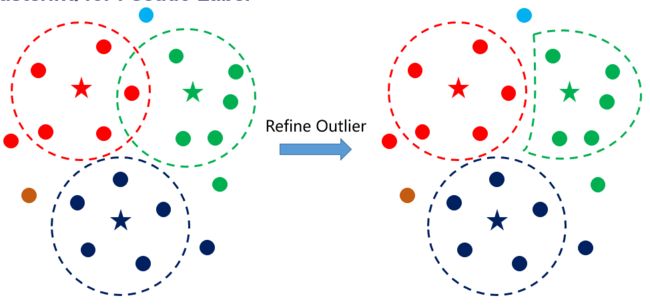
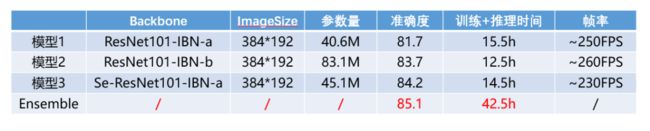
确定模型之后,我们对其需要消耗的资源和性能进行评估。我们只使用Backbone的Global Feature,最终将训练+推理耗时压缩在了42.5h。可以看到我们的JT-PC框架使得模型在测试集的分数越来越高,并且这种方式非常适合业界的产品版本迭代,随着训练数据量的增多不断对模型进行无监督更新。
工程优化
由于复赛对于程序运行时间和内存都有要求,目前开源的Re-ranking代码的资源消耗无法满足比赛要求,我们对Re-ranking的代码进行了无精度损失的工程优化。为了适合不同的使用场合,我们分为快速版和低耗版,快速版速度提升将近20倍,低耗版内存消耗减小接近7倍。最终Re-ranking算法将分数提升1.9%,16.6W测试集耗时为30分钟,内存消耗控制在30G。

复赛总结
复赛部分总结为以下几点:
1、使用了一个性能与速度均不错的基准模型,相关论文已经被顶级期刊TMM和CVPRW会议接受。
2、使用JT-PC无监督聚类的方式对测试集进行伪标签标注,并依据标签置信度将少量测试样本加入到训练集来训练模型,以增强模型的cross domain能力。
3、优化reranking代码,最终实现速度提升16倍,内存使用减少3倍以上
决赛
我们分析了决赛使用的数据集,总结出了主要的四个难点:光线变化、跨模态互搜、属性标签的使用和姿态变化。因为比赛保密协议,所以细节无法透露更多,以下示例均挑自公开的学术数据集。

针对上面四个问题,我们设计了模块化的解决方案,并将每个模块融合成为我们最终使用的模型框架,由于决赛保密协议的要求,决赛方案不能进行详细介绍:

跨模态(Cross-Modality)
CDP,Cross-Spectrum Dual-Subspace Pairing
Motivation:打乱颜色通道,让模型更加关注轮廓信息,比起只用灰图更加多样性
Inference:只对灰图的Query进行排序,彩图由正常训练的ReID网络进行排序
Performance:对于灰图Query(占比约1/6),性能提升约8%(提升~1%)
Visualization:模型对于颜色信息不太敏感
属性标签
Two-Stage Attribute-Refined Network (TAN)

姿态变化(半身图)
(比赛禁止使用姿态点、语义分割模型)
Dynamically Matching Local Information (DMLI)

决赛总结
决赛部分总结为以下几点:
1、针对主要难点,以我们开源的Baseline为基础,设计模块化的解决方案
2、针对特定数据和光线问题,进行了数据清洗与数据增强
3、针对跨模态问题,提出了CDP方法
4、针对属性标签,设计了TAN方法
5、针对姿态变化,使用了我们的DMLI方法(参考资料4)
6、相比于Baseline,性能提升明显
不同于其他队伍使用PCB、MGN等局部特征方案,DMT队伍整个比赛过程大多只使用了backbone的global feature,backbone的模型压缩在业界已经比较成熟,所以非常适合产品的部署。该次比赛初赛和复赛阶段的代码后续将整理开源,敬请期待!
补充信息:
一个更加强力的ReID Baseline
Github:
https://github.com/michuanhaohao/reid-strong-baseline
知乎专栏:
https://zhuanlan.zhihu.com/p/61831669
队长罗浩个人主页:
http://luohao.site/
![]()

往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习在线手册深度学习在线手册AI基础下载(pdf更新到25集)本站qq群1003271085,加入微信群请回复“加群”获取一折本站知识星球优惠券,请回复“知识星球”喜欢文章,点个在看
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习在线手册深度学习在线手册AI基础下载(pdf更新到25集)本站qq群1003271085,加入微信群请回复“加群”获取一折本站知识星球优惠券,请回复“知识星球”喜欢文章,点个在看