spring cloud Greenwich 学习笔记(十二)spring cloud sleuth 集成zipkin持久化存储 MySQL Elasticsearch
欢迎关注本人公众号

文章目录
- 欢迎关注本人公众号
- 持久化到mysql
- 初始化mysql表脚本
- 使用zipkin官方提供的jar包
- 自己搭建zipkin服务
- 异常:Failed to determine a suitable driver class
- 异常:`log4j-slf4j-impl-2.11.1`和`log4j-api-2.11.1`导致的StackOverflowError
- 持久化到Elasticsearch
- 安装Elasticsearch和kibana
- 在kibana中查看zipkin数据
- 欢迎关注本人公众号
springcloud系列学习笔记目录参见博主专栏 spring boot 2.X/spring cloud Greenwich。
由于是一系列文章,所以后面的文章可能会使用到前面文章的项目。文章所有代码都已上传GitHub:https://github.com/liubenlong/springcloudGreenwichDemo
本系列环境:Java11;springboot 2.1.1.RELEASE;springcloud Greenwich.RELEASE;MySQL 8.0.5;
持久化到mysql
zipkin默认会将链路请求信息保存到内存中,这样肯定是不可以应用到真实生产环境的,一是服务重启信息会丢失,而是都存储到内存也太浪费资源了,内存多贵啊。
官方文档中介绍到zipkin可以将数据保存到Cassandra、Elasticsearch、MySQL。接下来以mysql为例演示一下。
环境说明:mysql服务器采用8.0.13版本。mysql连接池需要使用比较新的8.*版本。
初始化mysql表脚本
新建数据库:zipkin,因为他默认数据库名称是zipkin。
如果想使用其他名称也可以。下面会介绍如何配置自定义的数据库名称。
SQL语句参见:https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
直接执行即可。
有的同学可能打不开,我这里直接贴一下
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);
使用zipkin官方提供的jar包
到官网(https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/)下载zipkin-server-2.12.2-exec.jar.
具体名称含义请参见官方文档描述:https://github.com/openzipkin/zipkin/tree/master/zipkin-server#mysql-storage。我这里从官方文档copy了关于mysql的内容:
MySQL Storage
The following apply when STORAGE_TYPE is set to mysql:
* `MYSQL_DB`: The database to use. Defaults to "zipkin".
* `MYSQL_USER` and `MYSQL_PASS`: MySQL authentication, which defaults to empty string.
* `MYSQL_HOST`: Defaults to localhost
* `MYSQL_TCP_PORT`: Defaults to 3306
* `MYSQL_MAX_CONNECTIONS`: Maximum concurrent connections, defaults to 10
* `MYSQL_USE_SSL`: Requires `javax.net.ssl.trustStore` and `javax.net.ssl.trustStorePassword`, defaults to false.
Alternatively you can use MYSQL_JDBC_URL and specify the complete JDBC url yourself. Note that the URL constructed by using the separate settings above will also include the following parameters: ?autoReconnect=true&useSSL=false&useUnicode=yes&characterEncoding=UTF-8. If you specify the JDBC url yourself, add these parameters as well.
Example usage:
$ STORAGE_TYPE=mysql MYSQL_USER=root java -jar zipkin.jar
- 执行命令启动(Linux):
java -jar zipkin-server-2.12.2-exec.jar --STORAGE_TYPE=mysql --MYSQL_JDBC_URL=jdbc:mariadb://127.0.0.1:3306/zipkin?pass=lbl0168\&user=root\&charset=utf8mb4\&password=lbl0168\&useSSL=false\&useUnicode=yes\&characterEncoding=UTF-8 - 执行命令启动(windows):
java -jar zipkin-server-2.12.1-exec.jar --zipkin.collector.rabbitmq.addresses=localhost --zipkin.collector.rabbitmq.username=lbl --zipkin.collector.rabbitmq.password=123456 --STORAGE_TYPE=mysql --MYSQL_JDBC_URL=jdbc:mariadb://127.0.0.1:3306/zipkin?pass=lbl0168^&user=root^&charset=utf8mb4^&password=lbl0168^&useSSL=false^&useUnicode=yes^&characterEncoding=UTF-8
上面给出Linux和Windows的原因是这两个系统的shell(cmd)URL拼接符不同,windows是^ linux 是\
启动成功后,访问http://127.0.0.1:9411/zipkin:
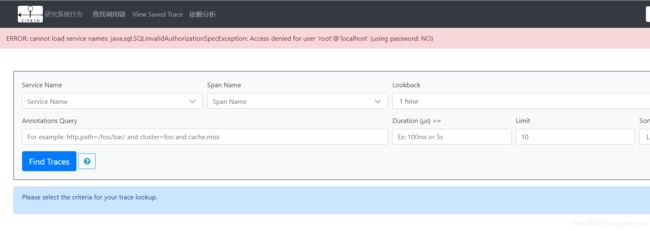
是的,这里出现了错误:
Caused by: java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: NO)
Current charset is GBK. If password has been set using other charset, consider using option 'passwordCharacterEncoding'
at org.mariadb.jdbc.internal.protocol.AbstractConnectProtocol.authentication(AbstractConnectProtocol.java:847) ~[mariadb-java-client-2.4.0.jar!/:?]
at org.mariadb.jdbc.internal.protocol.AbstractConnectProtocol.handleConnectionPhases(AbstractConnectProtocol.java:752) ~[mariadb-java-client-2.4.0.jar!/:?]
at org.mariadb.jdbc.internal.protocol.AbstractConnectProtocol.connect(AbstractConnectProtocol.java:412) ~[mariadb-java-client-2.4.0.jar!/:?]
at org.mariadb.jdbc.internal.protocol.AbstractConnectProtocol.connectWithoutProxy(AbstractConnectProtocol.java:1124) ~[mariadb-java-client-2.4.0.jar!/:?]
... 110 more
这里尝试了其他几个不同的包,启动都失败。查看源码也没有找到合适的解决办法。
待解决
自己搭建zipkin服务
由于上面在使用zipkin-server-2.12.2-exec.jar启动时,连接不上mysql服务器,一时也没有找到合适的解决办法,固采取自己手动搭建项目的方式,这样也便于我们查看源码,排除问题。
搭建springcloud-zipkin-server服务:
首先引入相关依赖,这里需要引入rabbitmq收集器依赖、zipkin server依赖、以及mysql存储依赖:
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-collector-rabbitmqartifactId>
<version>2.12.1version>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-storage-mysqlartifactId>
<version>2.12.1version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.13version>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-uiartifactId>
<version>2.12.1version>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-serverartifactId>
<version>2.12.1version>
dependency>
配置文件中需要指明使用mysql存储zipkin.storage.type=mysql,并且配置好mysql的连接,完整配置如下:
server:
port: 9411
# 最佳实践:springcloud应用都要指定application.name
spring:
application:
name: springcloud-zipkin-server
main:
allow-bean-definition-overriding: true
# 配置mysql
datasource:
url: jdbc:mysql://127.0.0.1:3306/zipkin?zeroDateTimeBehavior=convertToNull&serverTimezone=GMT%2b8&charset=utf8mb4&useSSL=false
username: root
password: lbl0168
eureka:
client:
serviceUrl:
# 指定服务注册中心的地址
defaultZone: http://localhost:8080/eureka/
# 上面是eureka单机注册中心。下面是eureka集群模式
# defaultZone: http://admin:123456@eureka2:8001/eureka/,http://admin:123456@eureka3:8002/eureka/,http://admin:123456@eureka2:8003/eureka/
#指明使用mysql存储
zipkin:
storage:
type: mysql
编写启动类:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import zipkin2.server.internal.EnableZipkinServer; //由于我使用的比较新的zipkin 2.12版本,所以这里的包是zipkin2
@SpringBootApplication
@EnableEurekaClient
@EnableZipkinServer //启用zipkin服务
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
OK,到此,服务搭建完成。启动springcloud-zipkin-server服务。
然后启动springcloud-eureka-serviceprovider和springcloud-eureka-serviceconsumer-feign两个服务作为zipkin的两个消息来源。访问http://127.0.0.1:8086/?name=allpxasz。就可以在zipkin的控制台看到相关请求数据了。
zipkin控制台截图:
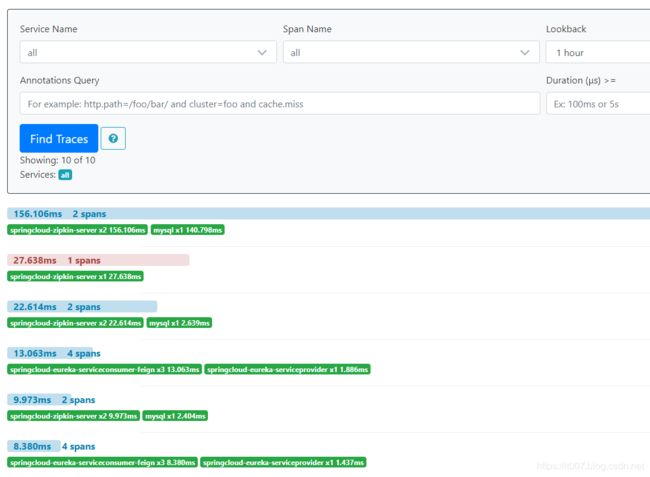
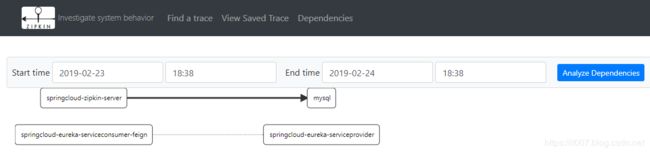
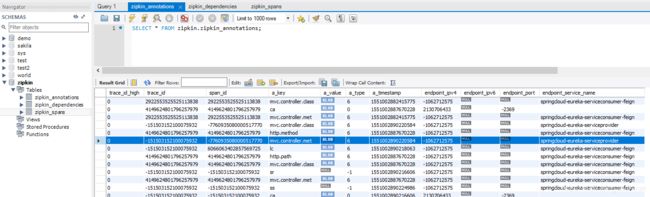
然后再mysql数据库中也会看到相关数据:
异常:Failed to determine a suitable driver class
完整异常如下:
Description:
Failed to auto-configure a DataSource: 'spring.datasource.url' is not specified and no embedded datasource could be auto-configured.
Reason: Failed to determine a suitable driver class
Action:
Consider the following:
If you want an embedded database (H2, HSQL or Derby), please put it on the classpath.
If you have database settings to be loaded from a particular profile you may need to activate it (no profiles are currently active).
我遇到这个问题是由于springcloud-zipkin-server项目中配置文件中的jdbc的URL配置有误,在没有指定连接池的时候,spring会根据URL的前缀jdbc:mysql自动选择驱动。所以这个URL一定要写对:jdbc:mysql://127.0.0.1:3306/zipkin?zeroDateTimeBehavior=convertToNull&serverTimezone=GMT%2b8&charset=utf8mb4&useSSL=false
异常:log4j-slf4j-impl-2.11.1和log4j-api-2.11.1导致的StackOverflowError
异常堆栈:
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Exception in thread "main" java.lang.StackOverflowError
at java.base/java.lang.StackStreamFactory$FrameBuffer.get(StackStreamFactory.java:911)
at java.base/java.lang.StackStreamFactory$AbstractStackWalker.peekFrame(StackStreamFactory.java:265)
at java.base/java.lang.StackStreamFactory$AbstractStackWalker.hasNext(StackStreamFactory.java:351)
at java.base/java.lang.StackStreamFactory$StackFrameTraverser.tryAdvance(StackStreamFactory.java:593)
at java.base/java.util.stream.ReferencePipeline.forEachWithCancel(ReferencePipeline.java:127)
at java.base/java.util.stream.AbstractPipeline.copyIntoWithCancel(AbstractPipeline.java:502)
at java.base/java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:488)
at java.base/java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:474)
at java.base/java.util.stream.FindOps$FindOp.evaluateSequential(FindOps.java:150)
at java.base/java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.base/java.util.stream.ReferencePipeline.findFirst(ReferencePipeline.java:543)
at org.apache.logging.log4j.util.StackLocator.lambda$getCallerClass$3(StackLocator.java:49)
at java.base/java.lang.StackStreamFactory$StackFrameTraverser.consumeFrames(StackStreamFactory.java:534)
at java.base/java.lang.StackStreamFactory$AbstractStackWalker.doStackWalk(StackStreamFactory.java:306)
at java.base/java.lang.StackStreamFactory$AbstractStackWalker.callStackWalk(Native Method)
at java.base/java.lang.StackStreamFactory$AbstractStackWalker.beginStackWalk(StackStreamFactory.java:370)
at java.base/java.lang.StackStreamFactory$AbstractStackWalker.walk(StackStreamFactory.java:243)
at java.base/java.lang.StackWalker.walk(StackWalker.java:498)
at org.apache.logging.log4j.util.StackLocator.getCallerClass(StackLocator.java:47)
at org.apache.logging.log4j.util.StackLocatorUtil.getCallerClass(StackLocatorUtil.java:55)
at org.apache.logging.slf4j.Log4jLoggerFactory.getContext(Log4jLoggerFactory.java:42)
at org.apache.logging.log4j.spi.AbstractLoggerAdapter.getLogger(AbstractLoggerAdapter.java:46)
at org.apache.logging.slf4j.Log4jLoggerFactory.getLogger(Log4jLoggerFactory.java:29)
......
当pom文件的依赖如下所示时,就会抛出异常:
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-collector-rabbitmqartifactId>
<version>2.12.1version>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-uiartifactId>
<version>2.12.1version>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-serverartifactId>
<version>2.12.1version>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-storage-mysqlartifactId>
<version>2.12.1version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.13version>
dependency>
这个问题的原因就是jar包冲突,不同的开源框架件依赖了不同的日志组件甚至不同的版本导致的,通常的解决办法即使查找到对应的依赖将其加入或者移除或者依据maven的包管理就近原则来选择加载正确的包。
我这里使用的是就近原则,调整一下jar包的顺序即可,正确的jar包引用顺序为:
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-netflix-eureka-clientartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-collector-rabbitmqartifactId>
<version>2.12.1version>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-storage-mysqlartifactId>
<version>2.12.1version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.13version>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-zipkinartifactId>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-autoconfigure-uiartifactId>
<version>2.12.1version>
dependency>
<dependency>
<groupId>io.zipkin.javagroupId>
<artifactId>zipkin-serverartifactId>
<version>2.12.1version>
dependency>
持久化到Elasticsearch
安装Elasticsearch和kibana
安装步骤请参考笔者文章: Elasticsearch学习笔记(八)Elasticsearch6.6 及 Kibana 6.6 安装(Windows)
首先启动Elasticsearch和kibana服务。
由于之前使用mysql存储时,启动java -jar 的方式连接不上mysql数据库,才自己搭建的项目。这里还是直接使用zipkin官方提供的exec的jar包来启动服务。
首先将我们自己搭建的springcloud-zipkin-server服务关闭。然后使用zipkin-server-2.10.1-exec.jar启动zipkin。完整的启动命令:java -jar zipkin-server-2.10.1-exec.jar --zipkin.collector.rabbitmq.addresses=localhost --zipkin.collector.rabbitmq.username=lbl --zipkin.collector.rabbitmq.password=123456 --STORAGE_TYPE=elasticsearch --ES_HOSTS=http://127.0.0.1:9200
当然springcloud-eureka-serviceprovider,springcloud-eureka-serviceconsumer-feign,springcloud-eureka-server这几个服务是要启动的,不要关闭。
访问几次接口http://127.0.0.1:8086/?name=allpxasz,这样数据就保存到Elasticsearch了。
在kibana中查看zipkin数据
首先要添加一个pattern:

点击next,然后创建。创建完成后,在discover页面选择刚刚创建的zipkin*:
如此一来,就可以查看到我们的zipkin的数据了:
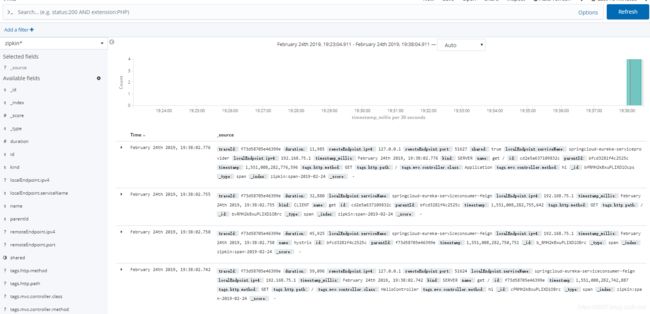
一般来说,使用zipkin不会将其持久化到mysql中,效率比较低,一般都是存储到Elasticsearch
springcloud系列学习笔记目录参见博主专栏 spring boot 2.X/spring cloud Greenwich。
由于是一系列文章,所以后面的文章可能会使用到前面文章的项目。文章所有代码都已上传GitHub:https://github.com/liubenlong/springcloudGreenwichDemo
欢迎关注本人公众号