PyTorch中Linear层的原理 | PyTorch系列(十六)
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
文 |AI_study
原标题:PyTorch Callable Neural Networks - Deep earning In Python
Linear 层是如何实现的
在上一篇文章中,我们学习了 Linear 层如何使用矩阵乘法将它们的输入特征转换为输出特征。
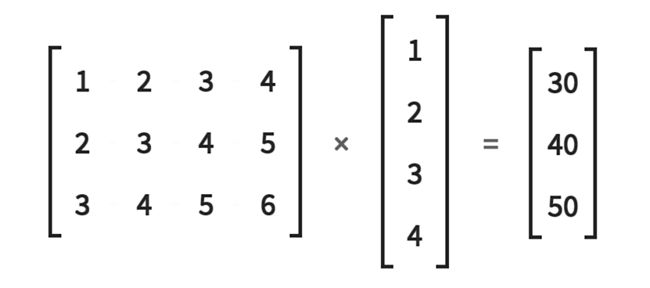
当输入特征被一个Linear 层接收时,它们以一个 展平成一维张量的形式接收,然后乘以权重矩阵。这个矩阵乘法产生输出特征。
让我们看看代码中的一个例子。
一、使用矩阵进行变换
in_features = torch.tensor([1,2,3,4], dtype=torch.float32)
weight_matrix = torch.tensor([
[1,2,3,4],
[2,3,4,5],
[3,4,5,6]
], dtype=torch.float32)
> weight_matrix.matmul(in_features)
tensor([30., 40., 50.])
在这里,我们创建了一个一维张量,叫做in_features。我们还创建了一个权重矩阵当然是一个二维张量。然后,我们使用matmul()函数来执行生成一维张量的矩阵乘法运算。
一般来说,权重矩阵定义了一个线性函数,它把一个有四个元素的一维张量映射成一个有三个元素的一维张量。
这也是Linear 层的工作原理。它们使用权重矩阵将一个in_feature空间映射到一个out_feature空间。
二、使用PyTorch线性层进行转换
让我们看看如何创建一个PyTorch的 Linear 层来完成相同的操作。
fc = nn.Linear(in_features=4, out_features=3, bias=False)
这里,我们有了。我们已经定义了一个线性层,它接受4个输入特征并把它们转换成3个输出特征,所以我们从4维空间转换到3维空间。我们知道需要一个权重矩阵被用执行这个操作,但是在这个例子中权重矩阵在哪里呢?
我们将权重矩阵放在PyTorch LinearLayer类中,是由PyTorch创建。PyTorch LinearLayer类使用传递给构造函数的数字4和3来创建一个3 x 4的权重矩阵。让我们通过查看PyTorch源代码来验证这一点。
# torch/nn/modules/linear.py (version 1.0.1)
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
正如我们所看到的,当我们用一个3×4矩阵乘以一个4×1矩阵时,结果是一个3×1矩阵。这就是PyTorch以这种方式构建权重矩阵的原因。这些是矩阵乘法的线性代数规则。
我们来看看如何通过传递in_features张量来调用我们的层。
> fc(in_features)
tensor([-0.8877, 1.4250, 0.8370], grad_fn=)
我们可以这样调用对象实例,因为PyTorch神经网络模块是可调用的Python对象。稍后我们将更详细地研究这个重要的细节,但是首先,检查这个输出。我们确实得到了一个包含三个元素的一维张量。然而,产生了不同的值。
callable Python objects. :https://en.wikipedia.org/wiki/Callable_object
这是因为PyTorch创建了一个权值矩阵,并使用随机值初始化它。这意味着这两个例子中的线性函数是不同的,所以我们使用不同的函数来产生这些输出。

记住权矩阵中的值定义了线性函数。这演示了在训练过程中,随着权重的更新,网络的映射是如何变化的。
让我们显式地将线性层的权值矩阵设置为与我们在另一个示例中使用的权值矩阵相同。
fc.weight = nn.Parameter(weight_matrix)
PyTorch模块的权值需要是参数。这就是为什么我们把权矩阵张量放在一个参数类实例中。现在让我们看看这一层如何使用新的权重矩阵转换输入。我们希望看到与前面示例相同的结果。
> fc(in_features)
tensor([30.0261, 40.1404, 49.7643], grad_fn=)
这一次我们更接近于30、40和50的值。然而,我们确切。这是为什么呢?这是不精确的因为线性层在输出中加入了一个偏置张量。观察当我们关闭偏差时会发生什么。我们通过向构造函数传递一个假标记来做到这一点。
fc = nn.Linear(in_features=4, out_features=3, bias=False)
fc.weight = nn.Parameter(weight_matrix)
> fc(in_features)
tensor([30., 40., 50.], grad_fn=)
现在,我们有一个精确的匹配。这就是Linear 层的工作原理。
三、线性变换的数学符号
有时我们会看到 Linear 层操作被称为
y=Ax+b.
在这个方程中,我们有:

我们会注意到这与直线方程相似
y=mx+b.
可调用的层和神经网络
我们之前指出过,我们把层对象实例当作一个函数来调用是多么奇怪。
> fc(in_features)
tensor([30.0261, 40.1404, 49.7643], grad_fn=)
使这成为可能的是PyTorch模块类实现了另一个特殊的Python函数,称为__call__()。如果一个类实现了__call__()方法,那么只要对象实例被调用,这个特殊的调用方法就会被调用。
这个事实是一个重要的PyTorch概念,因为在我们的层和网络中,__call __()与forward()方法交互的方式是用的。
我们不直接调用forward()方法,而是调用对象实例。在对象实例被调用之后,在底层调用了__ call __方法,然后调用了forward()方法。这适用于所有的PyTorch神经网络模块,即网络和层。
让我们在PyTorch源代码中看看这一点。
# torch/nn/modules/module.py (version 1.0.1)
def __call__(self, *input, **kwargs):
for hook in self._forward_pre_hooks.values():
hook(self, input)
if torch._C._get_tracing_state():
result = self._slow_forward(*input, **kwargs)
else:
result = self.forward(*input, **kwargs)
for hook in self._forward_hooks.values():
hook_result = hook(self, input, result)
if hook_result is not None:
raise RuntimeError(
"forward hooks should never return any values, but '{}'"
"didn't return None".format(hook))
if len(self._backward_hooks) > 0:
var = result
while not isinstance(var, torch.Tensor):
if isinstance(var, dict):
var = next((v for v in var.values() if isinstance(v, torch.Tensor)))
else:
var = var[0]
grad_fn = var.grad_fn
if grad_fn is not None:
for hook in self._backward_hooks.values():
wrapper = functools.partial(hook, self)
functools.update_wrapper(wrapper, hook)
grad_fn.register_hook(wrapper)
return result
PyTorch在__ call __()方法中运行的额外代码就是我们从不直接调用forward()方法的原因。如果我们这样做,额外的PyTorch代码将不会被执行。因此,每当我们想要调用forward()方法时,我们都会调用对象实例。这既适用于层,也适用于网络,因为它们都是PyTorch神经网络模块。
现在可以实现网络的forward()方法了。
文章中内容都是经过仔细研究的,本人水平有限,翻译无法做到完美,但是真的是费了很大功夫,希望小伙伴能动动你性感的小手,分享朋友圈或点个“在看”,支持一下我 ^_^
英文原文链接是:
https://deeplizard.com/learn/video/rcc86nXKwkw



加群交流
 欢迎小伙伴加群交流,目前已有交流群的方向包括:AI学习交流群,目标检测,秋招互助,资料下载等等;加群可扫描并回复感兴趣方向即可(注明:地区+学校/企业+研究方向+昵称)
欢迎小伙伴加群交流,目前已有交流群的方向包括:AI学习交流群,目标检测,秋招互助,资料下载等等;加群可扫描并回复感兴趣方向即可(注明:地区+学校/企业+研究方向+昵称)


谢谢你看到这里! ????