Python3.5 queue模块详解 和 进程间通讯
queue — A synchronized queue class:https://docs.python.org/3/library/queue.html
菜鸟教程 - Python3 多线程:http://www.runoob.com/python3/python3-multithreading.html
python3 队列:https://cloud.tencent.com/developer/information/python3%20%E9%98%9F%E5%88%97
Python 多进程 multiprocessing 使用示例:https://blog.csdn.net/freeking101/article/details/52511837
Python Queue模块详解:https://www.jb51.net/article/58004.htm
queue 介绍
- queue 是 python 中的标准库,俗称队列,可以直接 import 引用,在 python2.x 中,模块名为 Queue。
Python2.x 是 import Queue 注意Q是大写。 Python3.x 变成了queue。 - 在 python 中,多个线程之间的数据是共享的,多个线程进行数据交换的时候,不能够保证数据的安全性和一致性,所以当多个线程需要进行数据交换的时候,队列就出现了,队列可以完美解决线程间的数据交换,保证线程间数据的安全性和一致性
- queue 是多线程中的使用的栈,但是Python 解释器有一个全局解释器锁(PIL),导致每个 Python 进程中最多同时运行一个线程,因此 Python 多线程程序并不能改善程序性能,不能发挥多核系统的优势。
- multiprocessing.Queue 是Python 2.6 引入的用来实现多进程的一种高性能栈。
- collections.deque 是为了高效实现插入和删除操作的双向列表,适合用于队列和栈。
Python 虽然不能利用 多线程 实现多核任务,但可以通过 多进程 实现多核任务。
多个 Python 进程 有 各自独立的GIL锁,互不影响。
python 2.x Queue 使用示例:
import Queque
a = [1, 2, 3]
q = Queque.queue()
q.put(a)
get_item = q.get()python 3.x queue 使用示例:
import queue
a = [1, 2, 3]
q = queue.Queue()
q.put(a)
get_item = q.get()
print(get_item)
Python 队列 模块 queue 多应用在多线程应用中,多线程访问共享变量。对于多线程而言,访问共享变量时,python 队列 queue 是线程安全的。从queue 队列的具体实现中,可以看出 queue 使用了1个 线程互斥锁(pthread.Lock()),以及3个条件标量 (pthread.condition()) ,来保证了线程安全。即 python 的 queue 设计的是 线程安全 的。
Python 的 queue 模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列PriorityQueue。这些队列都实现了锁原语,能够在多线程中直接使用。可以使用队列来实现线程间的同步。
queue队列的互斥锁和条件变量 - python线程中同步锁:https://blog.csdn.net/hehe123456zxc/article/details/52264829
Python 中的 Queue 实现了一个同步队列,并且该类实现了所有需要的锁原语。Queue实现了三种队列:普通的FIFO队列(Queue)、LIFO队列(LifoQueue)、优先级队列(PriorityQueue)。其使用方法类似。
下面以普通的 先进先出队列 Queue 为例谈一下 Queue 中的主要方法:
#引入Queue类
from Queue import Queue
#得到队列的大小
Queue.qsize()
#判断队列是否为空
Queue.empty()
#判断队列是否已满
Queue.full()
#从队列头获取元素,默认为阻塞
Queue.get([block[,timeout]])
#从队列头获取元素,非阻塞方式
Queue.get_nowait()
#或者
Queue.get(block=False)
#阻塞写入队列
Queue.put(item)
#非阻塞写入队列
Queue.put_nowait(item)
#或者
Queue.put(item,block=False)
#向队列中已完成的元素发送join信号
Queue.task_done()
上面从队列中获取元素和向队列中添加元素都有阻塞和非阻塞的方式,采用阻塞方式,如果从队列中取元素而元素为空,则线程会停下来等待知道队列中有元素可以取出;如果向队列中添加元素而此时队列已满,则同样线程会停下来直到停止。如果采用非阻塞方式,取元素时一旦队列为空,则会引发Empty异常,放元素时一旦队列已满,就会引发Full异常。
下面是采用 Queue 实现的经典生产者消费者问题的代码:http://blog.itpub.net/22664653/viewspace-764044/
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author :
# @File : text.py
# @Software : PyCharm
# @description : XXX
from queue import Queue
import random
import threading
import time
# Producer thread
class Producer(threading.Thread):
def __init__(self, t_name, queue):
threading.Thread.__init__(self, name=t_name)
self.data = queue
def run(self):
for i in range(5):
print("%s: %s is producing %d to the queue!" % (time.ctime(), self.getName(), i))
self.data.put(i)
time.sleep(random.randrange(10) / 5)
print("%s: %s finished!" % (time.ctime(), self.getName()))
# Consumer thread
class Consumer(threading.Thread):
def __init__(self, t_name, queue):
threading.Thread.__init__(self, name=t_name)
self.data = queue
def run(self):
for i in range(5):
val = self.data.get()
print("%s: %s is consuming. %d in the queue is consumed!" % (time.ctime(), self.getName(), val))
time.sleep(random.randrange(10))
print("%s: %s finished!" % (time.ctime(), self.getName()))
# Main thread
def main():
queue = Queue()
producer = Producer('Pro.', queue)
consumer = Consumer('Con.', queue)
producer.start()
consumer.start()
producer.join()
consumer.join()
print('All threads terminate!')
if __name__ == '__main__':
main()
python 中有三种 Queue
import Queue
myqueue = Queue.Queue() # python 自带库 的 队列
from multiprocessing import Queue # multiprocessing 模块中队列
myqueue = Queue.Queue()
import multiprocessing
manager = multiprocessing.Manager() # multiprocessing 模块中 manager 的队列
myqueue=manager.Queue()
Queue.Queue 是进程内非阻塞队列,且各自进程私有。multiprocess.Queue 是跨进程通信队列,各子进程共有。
Manager 是 multiprocessing 的封装 .Manager.Queue 和 Queue, multiprocessing.Queue 没有太大关系。
测试 示例 1(各自进程私有):
from multiprocessing import Process
import queue
# import os
def f():
q.put([3, None, 'dasda'])
print(q.get())
if __name__ == '__main__':
q = queue.Queue()
p = Process(target=f,)
p.start()
print(q.get(block=False))可以看到这里用的队列 queue,主进程 生成一个空队列实例,然后在主进程中再开一个进程,在子进程里对队列q进行操作,这段代码在不同的环境中运行结果不同,在windows下当程序运行到f函数里的q.put([3, None, 'dasda'])的时候就会抛出错误:q没有定义,这里也好理解,就是子进程无法访问主进程的一些数据,但是在mac、ubuntu或者win下的anaconda下运行的时候子进程可以对q进程put和get操作,然后程序会在最后一行get的时候抛出队列为空的错误,这里我的理解方式就是子进程数据拷贝自父进程,也就是子进程存在一个定义了的q,但是进程间数据又不共享,所以主进程里的q还是为空。
测试 示例 2(进程间 通讯:生产者 - 消费者):
import random
import time
from multiprocessing import Queue
from multiprocessing import Process
q_1 = Queue()
q_2 = Queue()
def run():
q_1.put(3)
# print(q.get())
def consumer(share_q):
while True:
t = share_q.get()
if t:
print('consumer : {0}'.format(t))
else:
time.sleep(0.5)
def producer(share_q):
while True:
t = random.randint(1, 100)
share_q.put(t)
print('producer : {0}'.format(t))
time.sleep(1)
pass
def test_1():
t = Process(target=run)
t.start()
# time.sleep(1)
print(q_1.get())
def test_2():
p_producer = Process(target=producer, args=(q_2,))
p_consumer = Process(target=consumer, args=(q_2,))
p_producer.start()
p_consumer.start()
pass
if __name__ == '__main__':
# test_1()
test_2()
Python 自带库 中 queue 模块有三种队列及构造函数:
- Python queue 模块的 FIFO 队列 先进先出。 class queue.Queue(maxsize)
- LIFO 类似于堆,即先进后出。 class queue.LifoQueue(maxsize)
- 还有一种是优先级队列,级别越低越先出来。 class queue.PriorityQueue(maxsize)
queue.Queue(maxsize=0):构造一个FIFO(先进先出)的队列
queue.LifoQueue(maxsize=0):构造一个LIFO(后进先出)的队列
queue.PriorityQueue(maxsize=0):构造一个具有优先级的队列,存储的是一个元组(n, value),n为数字代表优先级,数字越小,级别越高
queue 模块中的常用方法:
- queue.qsize() : 返回队列的大小
- queue.empty() : 如果队列为空,返回True,反之False
- queue.full() : 如果队列满了,返回True,反之False
- queue.full : 与 maxsize 大小对应
- queue.get([block[, timeout]]) : 获取队列,timeout等待时间。从队列中获取任务,并且从队列中移除此任务。首先尝试获取互斥锁,获取成功则队列中get任务,如果此时队列为空,则wait等待生产者线程添加数据。get到任务后,会调用self.not_full.notify()通知生产者线程,队列可以添加元素了。最后释放互斥锁
- queue.get_nowait() : 相当queue.get(False)。无阻塞的向队列中get任务,当队列为空时,不等待,而是直接抛出empty异常,重点是理解block=False
- queue.put(item) : 写入队列,timeout 等待时间。申请获得互斥锁,获得后,如果队列未满,则向队列中添加数据,并通知notify其它阻塞的某个线程,唤醒等待获取require互斥锁。如果队列已满,则会wait等待。最后处理完成后释放互斥锁。其中还有阻塞block以及非阻塞,超时等逻辑
- queue.put_nowait(item) : 相当queue.put(item, False)。无阻塞的向队列中添加任务,当队列为满时,不等待,而是直接抛出full异常,重点是理解block=False
- queue.task_done() 在完成一项工作之后,queue.task_done()函数向任务已经完成的队列发送一个信号
- queue.join() 实际上意味着等到队列为空,再执行别的操作。待队列中任务全部处理完毕,需要配合queue.task_done使用
这个模块定义了两个异常
queue.Empty:如果队列中为空,继续调用非阻塞的get_nowait()会抛出异常
queue.Full:如果队列已满,继续调用非阻塞的put_nowait()会抛出异常
类 和 异常
import Queue
#类
Queue.Queue(maxsize = 0) #构造一个FIFO队列,maxsize设置队列大小的上界, 如果插入数据时, 达到上界会发生阻塞, 直到队列可以放入数据. 当maxsize小于或者等于0, 表示不限制队列的大小(默认)
Queue.LifoQueue(maxsize = 0) #构造一LIFO队列,maxsize设置队列大小的上界, 如果插入数据时, 达到上界会发生阻塞, 直到队列可以放入数据. 当maxsize小于或者等于0, 表示不限制队列的大小(默认)
Queue.PriorityQueue(maxsize = 0) #构造一个优先级队列,,maxsize设置队列大小的上界, 如果插入数据时, 达到上界会发生阻塞, 直到队列可以放入数据. 当maxsize小于或者等于0, 表示不限制队列的大小(默认). 优先级队列中, 最小值被最先取出
#异常
Queue.Empty #当调用非阻塞的get()获取空队列的元素时, 引发异常
Queue.Full #当调用非阻塞的put()向满队列中添加元素时, 引发异常
队列对象
三种队列对象提供的公共的方法
Queue.empty() #如果队列为空, 返回True(注意队列为空时, 并不能保证调用put()不会阻塞); 队列不空返回False(不空时, 不能保证调用get()不会阻塞)
Queue.full() #如果队列为满, 返回True(不能保证调用get()不会阻塞), 如果队列不满, 返回False(并不能保证调用put()不会阻塞)
Queue.put(item[, block[, timeout]]) #向队列中放入元素, 如果可选参数block为True并且timeout参数为None(默认), 为阻塞型put(). 如果timeout是正数, 会阻塞timeout时间并引发Queue.Full异常. 如果block为False为非阻塞put
Queue.put_nowait(item) #等价于put(itme, False)
Queue.get([block[, timeout]]) #移除列队元素并将元素返回, block = True为阻塞函数, block = False为非阻塞函数. 可能返回Queue.Empty异常
Queue.get_nowait() #等价于get(False)
Queue.task_done() #在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
Queue.join() #实际上意味着等到队列为空,再执行别的操作
queue 使用示例
下面是官方文档给多出的多线程模型:
def worker():
while True:
item = q.get()
do_work(item)
q.task_done()
q = Queue()
for i in range(num_worker_threads):
t = Thread(target=worker)
t.daemon = True
t.start()
for item in source():
q.put(item)
q.join() # block until all tasks are done改写的官方文档代码 :
控制线程退出 可以参考:http://bbs.chinaunix.net/forum.php?mod=viewthread&tid=4131893
import queue
import threading
# 要开启 的 线程 数
num_worker_threads = 3
source = [100, 200, 300, 400, 500, 600, 700, 800, 900]
def do_work(*args):
info = '[ thread id {0}]:{1}'.format(args[0], args[1])
print(info)
def worker(t_id):
while True:
item = q.get()
if item is None:
break
do_work(t_id, item)
q.task_done()
q = queue.Queue()
threads = []
for index in range(num_worker_threads):
t = threading.Thread(target=worker, args=(index,))
t.start()
threads.append(t)
for item in source:
q.put(item)
# block until all tasks are done
q.join()
# stop workers
for i in range(num_worker_threads):
q.put(None)
for t in threads:
t.join()基本使用示例:
import queue
# 以下三个队列都可以设置最大长度maxsize,默认是无限大
print("-------------queue.Queue----------------")
# 线程消息队列,FIFO(先进先出)
q = queue.Queue()
q.put("one")
q.put("two")
q.put("three")
print(q.get())
print(q.get())
print(q.get())
try:
# 队列中没有数据, 会阻塞。
# 阻塞时间到了还没有数据 抛出 queue.Empty 异常
print(q.get(timeout=3))
except queue.Empty as q_e:
print('queue empty')
print("-------------queue.LifoQueue----------------")
# 线程消息队列,LIFO(后进先出)
lq = queue.LifoQueue()
lq.put("one")
lq.put("two")
lq.put("three")
print(lq.get())
print(lq.get())
print(lq.get())
print("-------------queue.PriorityQueue----------------")
# 线程消息队列,PriorityQueue(优先级的队列:数字越小优先级越高)
pq = queue.PriorityQueue()
pq.put((1, "Jet"))
pq.put((3, "Jack"))
pq.put((2, "Judy"))
print(pq.get())
print(pq.get())
print(pq.get())执行结果:
-------------queue.Queue----------------
one
two
three
queue empty
-------------queue.LifoQueue----------------
three
two
one
-------------queue.PriorityQueue----------------
(1, 'Jet')
(2, 'Judy')
(3, 'Jack')
多线程 和 queue
python 多线程的一种简单的实现如下:
import threading
import time
def fun(argv):
print('thread : {0}'.format(argv))
time.sleep(2)
threads = [] # 用于保存线程
for i in range(5): # 开5个线程
t = threading.Thread(target=fun, args=str(i))
threads.append(t)
if __name__ == '__main__':
# 开始所有的线程
for i in threads:
i.start()
# 保证线程执行完
for i in threads:
i.join()
print('all over')Python2.7 Queue模块学习(生产者 - 消费者):https://my.oschina.net/guol/blog/93275
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author :
# @File : text.py
# @Software : PyCharm
# @description : XXX
import queue
import threading
Thread_id = 1
Thread_num = 3
class MyThread(threading.Thread):
def __init__(self, q):
global Thread_id
super(MyThread, self).__init__()
self.q = q
self.Thread_id = Thread_id
Thread_id = Thread_id + 1
def run(self):
while True:
try:
# 不设置阻塞的话会一直去尝试获取资源
task = self.q.get(block=True, timeout=1)
except queue.Empty as e:
info_e = 'Thread ' + str(self.Thread_id) + ' end'
print(info_e)
break
# 取到数据,开始处理(依据需求加处理代码)
info_d = "Starting " + str(self.Thread_id)
print(info_d)
print(task)
self.q.task_done()
info_end = "Ending " + str(self.Thread_id)
print(info_end)
q_test = queue.Queue(10)
# 向资源池里面放10个数用作测试
for i in range(10):
q_test.put(i)
# 开Thread_num个线程
for i in range(0, Thread_num):
worker = MyThread(q_test)
worker.start()
# 等待所有的队列资源都用完
q_test.join()
print("Exiting Main Thread")
q.task_done是表明当前的资源处理完了,q.join()会等到所有的资源都被处理了才会向下继续执行,这就是一种同步。
python 多线程 和 优先级队列(Queue)
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author :
# @File : text.py
# @Software : PyCharm
# @description : XXX
import queue
import threading
import time
exitFlag = 0
class MyThread(threading.Thread):
def __init__(self, thread_id, name, q):
super(MyThread, self).__init__()
self.thread_id = thread_id
self.name = name
self.q = q
def run(self):
print("Starting {0}".format(self.name))
process_data(self.name, self.q)
print("Exiting {0}".format(self.name))
def process_data(thread_name, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print("%s processing %s" % (thread_name, data))
else:
queueLock.release()
time.sleep(1)
thread_list = ["Thread-1", "Thread-2", "Thread-3"]
name_list = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = queue.Queue(10)
threads = []
threadID = 1
# 创建新线程
for tName in thread_list:
thread = MyThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# 填充队列
queueLock.acquire()
for word in name_list:
workQueue.put(word)
queueLock.release()
# 等待队列清空
while not workQueue.empty():
pass
# 通知线程是时候退出
exitFlag = 1
# 等待所有线程完成
for t in threads:
t.join()
print("Exiting Main Thread")
multiprocessing.Queue
The Queue class is a near clone of queue.Queue. For example:Queue 是 queue.Queue 的近似克隆。Queues是进程和线程安全的,也就是说,同一时间,只能由一个进程或者线程操作 Queues。
from multiprocessing import Process, Queue
"""
Queues are thread and process safe.
Queues 是 进程 和 线程 安全 的
"""
def f(q):
q.put([42, None, 'hello'])
if __name__ == '__main__':
q = Queue()
p = Process(target=f, args=(q,))
p.start()
print(q.get()) # prints "[42, None, 'hello']"
p.join()用于多进程,multiprocess.Queue 是跨进程通信队列。Manager 是 multiprocessing 的封装 ,Manager.Queue 和 Queue, multiprocessing.Queue 没有太大关系。先来看官方文档:
from multiprocessing import Pool
def f(x):
return x * x
if __name__ == '__main__':
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))
"""
输出:
[1, 4, 9]
"""multiprocessing supports two types of communication channel between processes:
multiprocessing 支持两种类型的进程间通信方式 queues 和 pips。
使用 ping 命令同时检查多个域名/IP :
from subprocess import Popen, PIPE
from multiprocessing import Pool, Manager
def ping(host, q):
# ping 发 4 个包,超时时间为 1 秒。
p = Popen(['ping', '-c', '4', '-W', '1', host], stdout=PIPE, stderr=PIPE)
p.communicate()
q.put([host, p.returncode == 0 and 'good' or 'bad'])
if __name__ == '__main__':
test_hosts = [
'www.baidu.com',
'www.taobao.com',
'www.bad123host.com',
'1.2.3.4',
]
m = Manager()
q = m.Queue()
p = Pool(3)
for host in test_hosts:
p.apply_async(ping, (host, q))
p.close()
for i in range(len(test_hosts)):
item = q.get()
print(f'{i:03d} {item[0]} is {item[1]}')
p.join()multiprocessing.Queue 使用示例(此程序是在队列中加入10个数字,然后用2个进程来取出):
#!/usr/bin/env python3
import time
from multiprocessing import Process, Queue
def func_a(share_q):
while True:
try:
num = share_q.get_nowait()
print('我是进程A,取出数字:%d' % num)
time.sleep(1)
except BaseException as e:
break
def func_b(share_q):
while True:
try:
num = share_q.get_nowait()
print('我是进程B,取出数字:%d' % num)
time.sleep(1)
except BaseException as e:
break
if __name__ == '__main__':
q = Queue() # 创建列队,不传数字表示列队不限数量
for i in range(11):
q.put(i)
p1 = Process(target=func_a, args=(q,))
p2 = Process(target=func_b, args=(q,))
p1.start()
p2.start()使用进程池 Pool时,Queue 会出错,需要使用 Manager.Queue:
#!/usr/bin/env python3
import time
from multiprocessing import Pool, Manager, Queue
def func_a(p_id, share_q):
num = share_q.get_nowait()
print('我是进程%d, 取出数字:%d' % (p_id, num))
time.sleep(1)
if __name__ == '__main__':
q = Manager().Queue()
for i in range(11):
q.put(i)
pool = Pool(3)
for i in range(10):
pool.apply_async(func_a, (i, q))
pool.close()
pool.join()
主进程定义了一个 Queue 类型的变量,并作为 Process 的 args 参数传给子进程 processA 和 processB
两个进程一个向队列中写数据,一个读数据。
import time
from multiprocessing import Process, Queue
MSG_QUEUE = Queue(5)
def start_a(msgQueue):
while True:
if msgQueue.empty() > 0:
print('queue is empty %d' % (msgQueue.qsize()))
else:
msg = msgQueue.get()
print('get msg %s' % (msg,))
time.sleep(1)
def start_b(msgQueue):
while True:
msgQueue.put('hello world')
print('put hello world queue size is %d' % (msgQueue.qsize(),))
time.sleep(3)
if __name__ == '__main__':
processA = Process(target=start_a, args=(MSG_QUEUE,))
processB = Process(target=start_b, args=(MSG_QUEUE,))
processA.start()
print('processA start..')
processB.start()
print('processB start..')
collections.deque
先来看官方文档:
有人对比过以上三者的性能,deque 作为一种双向队列性能完胜其他两者。
from collections import deque
d = deque('ghi') # 使用 'ghi' 创建一个具有3个元素的队列
for elem in d: # 迭代 队列中的元素
print(elem.upper())
d.append('j') # 在队列 右边 添加一个元素
d.appendleft('f') # 在队列 左边 添加一个元素
print(d)
d = deque(['f', 'g', 'h', 'i', 'j'])
print(d.pop()) # return and remove the rightmost item
print(d.popleft()) # return and remove the leftmost item
print(list(d)) # list the contents of the deque
print(d[0]) # peek at leftmost item
print(d[-1]) # peek at rightmost item
print(list(reversed(d))) # list the contents of a deque in reverse
print('h' in d) # search the deque
d.extend('jkl') # add multiple elements at once
print(d)
d = deque(['g', 'h', 'i', 'j', 'k', 'l'])
d.rotate(1) # right rotation
print(d)
d = deque(['l', 'g', 'h', 'i', 'j', 'k'])
d.rotate(-1) # left rotation
print(d)
d = deque(['g', 'h', 'i', 'j', 'k', 'l'])
print(deque(reversed(d))) # make a new deque in reverse order
d = deque(['l', 'k', 'j', 'i', 'h', 'g'])
d.clear() # empty the deque
# print(d.pop()) # cannot pop from an empty deque
d.extendleft('abc') # extendleft() reverses the input order
print(d)
Python 并发之 queue 模块 爬虫 示例
来源:https://www.imooc.com/article/44268
多线程 抓取 半次元(https://bcy.net/coser) Cos 频道 的 所有今日热门图片
大蕾姆镇楼:

引言:
本来是准备写multiprocessing进程模块的,然后呢,白天的时候随手想写一个爬半次元COS频道小姐姐的脚本,接着呢,就遇到了一个令人非常困扰的问题:国内免费的高匿代理ip都被玩坏了(很多站点都锁了),几千个里可能就十个不到能用的,对于这种情况,有一种应付的策略就是:写While True死循环,一直换代理ip直到能拿到数据为止。但是,假如是我们之前的那种单线程的话,需要等待非常久的时间,想想一个个代理去试,然后哪怕你设置了5s的超时,也得花上不少时间,而你抓取的网页不止一个的话,这个时间就不是一般的长了,这个时候不用多线程还等什么?我们可以把要请求的页面都丢到一个容器里,然后加锁,然后新建页面数量 x 访问线程,然后每个线程领取一个访问任务,然后各自执行任访问,直到全部访问完毕,最后反馈完成信息。在学完threading模块后,相信你第一个想到的会是条件变量Contition,acquire对集合加锁,取出一枚页面链接,notify唤醒一枚线程,然后release锁,接着重复这个操作,直到集合里的不再有元素为止,大概套路就是这样,如果你有兴趣可以自己试着去写下,在Python的queue模块里已经实现了一个线程安全的多生产者,多消费者队列,自带锁,多线程并发数据交换必备。
1.语法简介
内置三种类型的队列
Queue:FIFO(先进先出);LifoQueue:LIFO(后进先出);PriorityQueue:优先级最小的先出;
构造函数的话,都是(maxsize=0),设置队列的容量,如果设置的maxsize小于1,则表示队列的长度无限长
两个异常:
Queue.Empty:当调用非堵塞的get()获取空队列元素时会引发;
Queue.Full:当调用非堵塞的put()满队列里添加元素时会引发;
相关函数:
qsize():返回队列的近似大小,注意:qsize()> 0不保证随后的get()不会阻塞也不保证qsize() < maxsize后的put()不会堵塞;empty():判断队列是否为空,返回布尔值,如果返回True,不保证后续调用put()不会阻塞,同理,返回False也不保证get()调用不会被阻塞;full():判断队列是否满,返回布尔值如果返回True,不保证后续调用get()不会阻塞,同理,返回False也不保证put()调用不会被阻塞;put(item, block=True, timeout=None):往队列中放入元素,如果block为True且timeout参数为None(默认),为堵塞型put(),如果timeout是正数,会堵塞timeout时间并引发Queue.Full异常,如果block为False则为非堵塞put()put_nowait(item):等价于put(item, False),非堵塞put()get(block=True, timeout=None):移除一个队列元素,并返回该元素,如果block为True表示堵塞函数,block = False为非堵塞函数,如果设置了timeout,堵塞时最多堵塞超过多少秒,如果这段时间内没有可用的项,会引发Queue.Empty异常,如果为非堵塞状态,有数据可用返回数据无数据立即抛出Queue.Empty异常;- get_nowait():等价于get(False),非堵塞get()
- task_done():完成一项工作后,调用该方法向队列发送一个完成信号,任务-1;
- join():等队列为空,再执行别的操作;
2.Queue实战:多线程抓取半次元Cos频道的所有今日热门图片
抓取源:https://bcy.net/coser/toppost100?type=lastday

拉到底部(中途加载了更多图片,猜测又是ajax,确实是 ajax 加载),嗯,直接是日期耶,应该是请求参数里的一个,F12打开开发者模式,Network,抓包开起来,随手点开个02月08日,看下打开新链接的相关信息。
现在使用 fiddler 抓包查看报信息:
1. 打开并设置好 fiddler
2. 点击半次元Cos频道的所有今日热门图片。拉动滚动条到底部(中间会 ajax 加载图片)。点击底部的日期。
3. 查看 fiddler 抓到的包。删除无用的包
以第二个包为例分析:
包的请求信息
GET https://bcy.net/coser/index/ajaxloadtoppost?p=2&type=lastday&date= HTTP/1.1
Host: bcy.net
Connection: keep-alive
Accept: */*
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36
Referer: https://bcy.net/coser/toppost100?type=lastday
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: PHPSESSID=2f54ae530f1bead9f138e9c83784b503; lang_set=zh; mobile_set=no; _ga=GA1.2.1940319333.1546948186; _gid=GA1.2.1052000854.1546948186; tt_webid=6644099861280015885; __tea_sdk__ssid=c3130ac4-23a8-4098-b77c-eacf362114af; Hm_lvt_330d168f9714e3aa16c5661e62c00232=1546998281,1546999707,1546999809,1546999846; _csrf_token=1ceefb8344cd5573cfe6b2e456da6a38; Hm_lpvt_330d168f9714e3aa16c5661e62c00232=1547000028
URL https://bcy.net/coser/index/ajaxloadtoppost?p=2&type=lastday&date= 中 有 3 个参数,p 猜测代表 页码(page), type 值固定,date 代表日期。
把 URL 地址放到 postman 里面模拟请求(也可以直接浏览器中打开),同时把 head 信息放到 postman 中
可以看到 请求中的 p 设置为 1 ,照样可以返回数据,和第一个包对比,发现返回信息是一样的,说明猜测正确。
这样可以构建一个通用的 URL 地址:https://bcy.net/coser/index/ajaxloadtoppost?p=页码&type=lastday&date=日期
只需要把 URL 中 '页码' 和 '日期' 换成对应 值,就可以得到 对应日期的对应页码的 URL 地址。
代码实现环节
原作者 github:https://github.com/coder-pig/ReptileSomething
CatchBcyCosPic.py:https://github.com/coder-pig/ReptileSomething/blob/master/code/meizi/CatchBcyCosPic.py
原作者是使用 threading 来实现 多线程抓取,但是 python 因为 GIL 原因,多线程其实还是单线程,Python 虽然不能利用 多线程 实现多核任务,但是可以通过 多进程 实现多核任务,因为 多个 Python 进程 有 各自独立的GIL锁,互不影响。
下面 使用 multiprocessing 模块 重写 threading 版本 程序:(重写的程序 没有 设置请求头 和 代理):
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author :
# @File : test.py
# @Software : PyCharm
# @description : XXX
import time
import datetime
import requests
import multiprocessing
from lxml import etree
# 如果 使用 反斜杠 \ , 的使用 两个\。即 E:\\cos\\
img_save_dir = 'E:/cos/'
def init_date_list(begin_date, end_date):
"""
# 构造生成一个从20150918到今天的日期
:param begin_date:
:param end_date:
:return:
"""
date_list = []
begin_date = datetime.datetime.strptime(begin_date, "%Y%m%d")
end_date = datetime.datetime.strptime(end_date, "%Y%m%d")
while begin_date <= end_date:
date_str = begin_date.strftime("%Y%m%d")
date_list.append(date_str)
begin_date += datetime.timedelta(days=1)
return date_list
def work_1(args):
"""
线程执行的方法。
作为 消费者,消费 日期队列 里面 日期
作为 生产者,生产 图片 url 到 img_info_queue 队列中
:param args: (date_queue, img_info_queue) 日期队列 和 图片信息 队列
:return:
"""
date_queue, img_info_queue = args
print('work_1')
while not date_queue.empty():
date_str = date_queue.get()
print("抓取:" + date_str)
# get_toppost100({'type': 'lastday', 'date': data}) # 第一次请求
# get_ajax_data({'p': '1', 'type': 'lastday', 'date': data}) # 第二次 Ajax 请求
img_url_list = get_date_all_img_url(date_str)
for url_info in img_url_list:
img_info_queue.put(url_info)
date_queue.task_done()
def get_date_all_img_url(date_str=None):
"""
得到 对应日期 所有 图片 的 URL 地址
:param date_str: 日期 。格式示例:20190110
:return: 图片 的 URL 列表
示例: [('20190110_Milk酱__', 'https://xxx.jpg'), ('20190110_Milk酱__', 'https://xxx.jpg'), ...]
"""
if not date_str:
return
# 一次 常规请求,一次 Ajax 加载,所以 循环两次
img_url_list = list()
for page_num in range(1, 3):
# https://bcy.net/coser/index/ajaxloadtoppost?p=1&type=lastday&date=20190110
url = 'https://bcy.net/coser/index/ajaxloadtoppost?p={0}&type=lastday&date={1}'.format(page_num, date_str)
r = requests.get(url)
if r.status_code == 200:
s_html = etree.HTML(text=r.text)
all_img_title_xpath = '//li/footer/a[@class="name"]/span/text()'
all_img_title = s_html.xpath(all_img_title_xpath)
# 加上 日期 字符串
all_img_title = [date_str + '_' + title for title in all_img_title]
all_img_url_xpath = '//li/a//img/@src'
all_img_url = s_html.xpath(all_img_url_xpath)
zipped = zip(all_img_title, all_img_url)
img_url_list.extend(zipped)
# print(len(all_img_title), len(all_img_url))
else:
print('status code : {0}'.format(r.status_code))
print(img_url_list)
return img_url_list
def work_2(img_info_queue):
"""
线程执行的方法
:return:
"""
temp = img_info_queue[0]
while not temp.empty():
# img_name, img_url = temp.get()
img_info = temp.get()
print("下载图片[{0}]:{1}".format(img_info[0], img_info[1]))
download_img(img_info)
temp.task_done()
def download_img(img_info):
img_name, img_url = img_info
r = requests.get(img_url)
if r.status_code == 200:
with open(img_save_dir + img_name + '.jpg', "wb+") as f:
f.write(r.content)
print('download img success')
else:
print('download img fail and status code : {0}'.format(r.status_code))
class CosSpiderProcess(multiprocessing.Process):
def __init__(self, group=None, target=None, name=None, args=(), kwargs={}):
"""
初始化
:param name: 进程名
:param target: 进程 执行的方法
"""
super(CosSpiderProcess, self).__init__(group=group, target=target, name=name, args=args, kwargs=kwargs)
self.args = args
self.func = target
pass
def run(self):
self.func(self.args)
if __name__ == '__main__':
cos_date_queue = multiprocessing.Manager().Queue() # 用来保存 日期 队列
cos_img_info_queue = multiprocessing.Manager().Queue() # 用来 保存 要下载 图片 的 URL 队列
# cos_date_queue = multiprocessing.Queue() # 用来保存 日期 队列
# cos_img_url_queue = multiprocessing.Queue() # 用来 保存 要下载 图片 的 URL 队列
start_date = '20190105'
today_date = '20190110'
date_str_list = init_date_list(start_date, today_date)
for date_s in date_str_list:
cos_date_queue.put(date_s)
########################################################################
p_id_list = list()
p_id = CosSpiderProcess(name='[ 进程 : 解析图片URL]', target=work_1, args=(cos_date_queue, cos_img_info_queue))
p_id_list.append(p_id)
# t.daemon = True
p_id.start()
# cos_date_queue.join()
########################################################################
time.sleep(3) # 睡眠 3 秒,防止 cos_img_info_queue 队列 中 没数据 work_2 直接跳出 while 循环
for i in range(5):
p_id = CosSpiderProcess(name='[ 进程 : 下载图片]', target=work_2, args=(cos_img_info_queue,))
p_id_list.append(p_id)
# t.daemon = True
p_id.start()
for p_id in p_id_list:
p_id.join()
pass
下载图片截图:
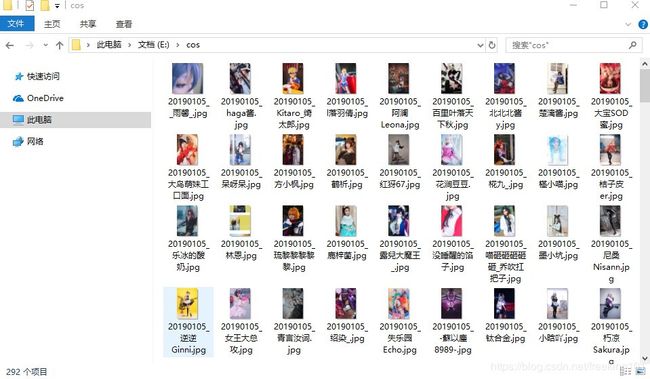
最后附上Queue模块的源码
直接点进去queue.py,源码只有249行,还好,看下源码结构

点开两个异常,非常简单,继承Exception而已,我们更关注__all__

1) all
all:在模块级别暴露公共接口,比如在导库的时候不建议写 from xxx import *,因为会把xxx模块里所有非下划线开头的成员都
引入到当前命名空间中,可能会污染当前命名空间。如果显式声明了 all*,import 就只会导入 all 列出的成员。
(不建议使用:from xxx import *** 这种语法!!!)
接着看下Queue类结构,老规矩,先撸下init方法

文档注释里写了:创建一个maxsize大小的队列,如果<=0,队列大小是无穷的。设置了maxsize,然后调用self._init(maxsize),点进去看下:

这个deque是什么?
2) deque类
其实是collections模块提供的双端队列,可以从队列头部快速增加和取出对象,对应两个方法:popleft()与appendleft(),时间复杂度只有O(1),相比起list对象的insert(0,v)和pop(0)的时间复杂度为O(N),列表元素越多,元素进出耗时会越长!
回到源码,接着还定义了:
mutex:threading.Lock(),定义一个互斥锁
not_empty = threading.Condition(self.mutex):定义一个非空的条件变量
not_full = threading.Condition(self.mutex):定义一个非满的条件变量
all_tasks_done = threading.Condition(self.mutex):定义一个任务都完成的条件变量
unfinished_tasks = 0:初始化未完成的任务数量为0
接着到task_done()方法:

with加锁,未完成任务数量-1,判断未完成的任务数量,小于0,抛出异常:task_done调用次数过多,等于0则唤醒所有等待线程,修改未完成任务数量;
再接着到join()方法:
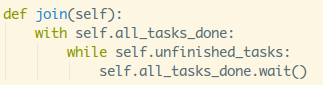
with加锁,如果还有未完成的任务,wait堵塞调用者进程;
接下来是qsize,empty和full函数,with加锁返回大小而已:
接着是put()函数: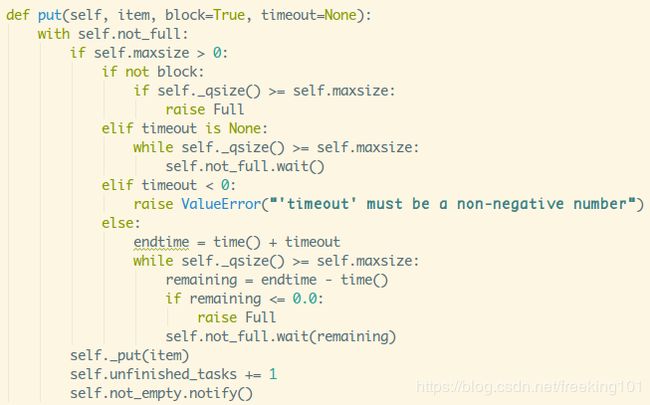
with加锁,判断maxsize是否大于0,上面也讲了maxsize<=0代表队列是可以无限扩展的,那就不存在队列满的情况,maxsize<=0的话直接就往队列里放元素就可以了,同时未完成任务数+1,随机唤醒等待线程。
如果maxsize大于0代表有固定容量,就会出现队列满的情况,就需要进行细分了:
- 1.block为False:非堵塞队列,判断当前大小是否大于等于容量,是,抛出Full异常;
- 2.block为True,没设置超时:堵塞队列,判断当前大小是否大于等于容量,
是,堵塞线程; - 3.block为True,超时时间<0:直接抛出ValueError异常,超时时间应为非负数;
- 4.block为True,超时时间>=0,没倒时间堵塞线程,到时间抛出Full异常;
再接着是get()函数,和put()类似,只是抛出的异常为:Empty
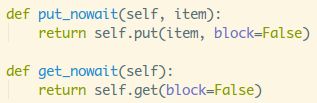
这两个就不用说了,非堵塞put()和get(),最后就是操作双端队列的方法而已;

另外两种类型的队列也非常简单,继承Queue类,然后重写对应的四个方法而已~

3) heapq模块
PriorityQueue优先级队里的heappush()和heappop()是heapq模块提供的两个方法,heap队列,q队列,堆一般可看做是一棵树的数组对象(二叉树堆),规则如下:某个节点的值总是不大于或不小于其孩子节点的值
然后又分最大堆和最小堆:
利用:heappush()可以把数据放到堆里,会自动按照二叉树的结构进行存储;
利用:heappop(heap):从heap堆中删除最小元素,并返回,heap再按完全二叉树规范重排;
queue.py模块大概的流程就是这个样子咯,总结下套路把:
关键点核心:三个条件变量,
not_empty:get的时候,队列空或在超时时间内,堵塞读取线程,非空唤醒读取线程;
not_full:put的时候,队列满或在超时时间内,堵塞写入线程,非满唤醒写入线程;
all_tasks_done:未完成任务unfinished_tasks不为0的时候堵塞调用队列的线程,
未完成任务不为0时唤醒所有调用队列的线程;
源码:
"""A multi-producer, multi-consumer queue."""
from time import time as _time
try:
import threading as _threading # 导入threading模块
except ImportError:
import dummy_threading as _threading # 该模块的接口和thread相同,在没有实现thread模块的平台上提供thread模块的功能。
from collections import deque # https://github.com/BeginMan/pythonStdlib/blob/master/collections.md
import heapq # 堆排序 https://github.com/qiwsir/algorithm/blob/master/heapq.md
__all__ = ['Empty', 'Full', 'Queue', 'PriorityQueue', 'LifoQueue'] # 模块级别暴露接口
class Empty(Exception):
"""当调用Queue.get(block=0)/get_nowait()时触发Empty异常
调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block,默认为True。
如果队列为空且block为True,get()就使调用线程暂停,直至有项目可用。
如果队列为空且block为False,队列将引发Empty异常
"""
pass
class Full(Exception):
"""当调用Queue.put(block=0)/put_nowait()时触发Full异常
如果队列当前为空且block为1,put()方法就使调用线程暂停,直到空出一个数据单元。
如果block为0,put方法将引发Full异常。
"""
pass
class Queue:
"""创建一个给定的最大大小的队列对象.
FIFO(先进先出)队列, 第一加入队列的任务, 被第一个取出
If maxsize is <= 0, the queue size is 无限大小.
"""
def __init__(self, maxsize=0):
self.maxsize = maxsize
self._init(maxsize) # 初始化queue为空
# 所有获取锁的方法必须在返回之前先释放,互斥锁在下面三个Condition条件共享
# 从而获取和释放的条件下也获得和释放互斥锁。
self.mutex = _threading.Lock() # Lock锁
# 当添加queue元素时通知`not_empty`,之后线程等待get
self.not_empty = _threading.Condition(self.mutex) # not_empty Condition实例
# 当移除queue元素时通知`not_full`,之后线程等待put.
self.not_full = _threading.Condition(self.mutex) # not_full Condition实例
# 当未完成的任务数为0时,通知`all_tasks_done`,线程等待join()
self.all_tasks_done = _threading.Condition(self.mutex) # all_tasks_done Condition实例
self.unfinished_tasks = 0
def task_done(self):
"""表明,以前排队的任务完成了
被消费者线程使用. 对于每个get(),随后调用task_done()告知queue这个task已经完成
"""
self.all_tasks_done.acquire()
try:
# unfinished_tasks 累减
unfinished = self.unfinished_tasks - 1
if unfinished <= 0:
# 调用多次task_done则触发异常
if unfinished < 0:
raise ValueError('task_done() called too many times')
self.all_tasks_done.notify_all() # 释放所有等待该条件的线程
self.unfinished_tasks = unfinished
finally:
self.all_tasks_done.release()
def join(self):
"""阻塞直到所有任务都处理完成
未完成的task会在put()累加,在task_done()累减, 为0时,join()非阻塞.
"""
self.all_tasks_done.acquire()
try:
# 一直循环检查未完成数
while self.unfinished_tasks:
self.all_tasks_done.wait()
finally:
self.all_tasks_done.release()
def qsize(self):
"""返回队列的近似大小(不可靠!)"""
self.mutex.acquire()
n = self._qsize() # len(queue)
self.mutex.release()
return n
def empty(self):
"""队列是否为空(不可靠)."""
self.mutex.acquire()
n = not self._qsize()
self.mutex.release()
return n
def full(self):
"""队列是否已满(不可靠!)."""
self.mutex.acquire()
n = 0 < self.maxsize == self._qsize()
self.mutex.release()
return n
def put(self, item, block=True, timeout=None):
"""添加元素.
如果可选参数block为True并且timeout参数为None(默认), 为阻塞型put().
如果timeout是正数, 会阻塞timeout时间并引发Queue.Full异常.
如果block为False为非阻塞put
"""
self.not_full.acquire()
try:
if self.maxsize > 0:
if not block:
if self._qsize() == self.maxsize:
raise Full
elif timeout is None:
while self._qsize() == self.maxsize:
self.not_full.wait()
elif timeout < 0:
raise ValueError("'timeout' must be a non-negative number")
else:
endtime = _time() + timeout
while self._qsize() == self.maxsize:
remaining = endtime - _time()
if remaining <= 0.0:
raise Full
self.not_full.wait(remaining)
self._put(item)
self.unfinished_tasks += 1
self.not_empty.notify()
finally:
self.not_full.release()
def put_nowait(self, item):
"""
非阻塞put
其实就是将put第二个参数block设为False
"""
return self.put(item, False)
def get(self, block=True, timeout=None):
"""移除列队元素并将元素返回.
block = True为阻塞函数, block = False为非阻塞函数. 可能返回Queue.Empty异常
"""
self.not_empty.acquire()
try:
if not block:
if not self._qsize():
raise Empty
elif timeout is None:
while not self._qsize():
self.not_empty.wait()
elif timeout < 0:
raise ValueError("'timeout' must be a non-negative number")
else:
endtime = _time() + timeout
while not self._qsize():
remaining = endtime - _time()
if remaining <= 0.0:
raise Empty
self.not_empty.wait(remaining)
item = self._get()
self.not_full.notify()
return item
finally:
self.not_empty.release()
def get_nowait(self):
"""
非阻塞get()
也即是get()第二个参数为False
"""
return self.get(False)
# Override these methods to implement other queue organizations
# (e.g. stack or priority queue).
# These will only be called with appropriate locks held
# 初始化队列表示
def _init(self, maxsize):
self.queue = deque() # 将queue初始化为一个空的deque对象
def _qsize(self, len=len): # 队列长度
return len(self.queue)
# Put a new item in the queue
def _put(self, item):
self.queue.append(item)
# Get an item from the queue
def _get(self):
return self.queue.popleft()
class PriorityQueue(Queue):
"""
继承Queue
构造一个优先级队列
maxsize设置队列大小的上界, 如果插入数据时, 达到上界会发生阻塞, 直到队列可以放入数据.
当maxsize小于或者等于0, 表示不限制队列的大小(默认).
优先级队列中, 最小值被最先取出
"""
def _init(self, maxsize):
self.queue = []
def _qsize(self, len=len):
return len(self.queue)
def _put(self, item, heappush=heapq.heappush):
heappush(self.queue, item)
def _get(self, heappop=heapq.heappop):
return heappop(self.queue)
class LifoQueue(Queue):
"""
构造一LIFO(先进后出)队列
maxsize设置队列大小的上界, 如果插入数据时, 达到上界会发生阻塞, 直到队列可以放入数据.
当maxsize小于或者等于0, 表示不限制队列的大小(默认)
"""
def _init(self, maxsize):
self.queue = []
def _qsize(self, len=len):
return len(self.queue)
def _put(self, item):
self.queue.append(item)
def _get(self):
return self.queue.pop() # 与Queue相比,仅仅是 将popleft()改成了pop()