深入理解计算机系统-之-内存寻址(六)--linux中的分页机制
[注意]
如果您当前使用的系统并不是linux,或者您的系统中只有一份linux源码,而您又期待能够查看或者检索不同版本的linux源码可以使用 http://lxr.free-electrons.com/
LXR (Linux Cross Reference)是比较流行的linux源代码查看工具,而这里集成了全版本的linux源码的索引
1 linux的分页机制
1.1 四级分页机制
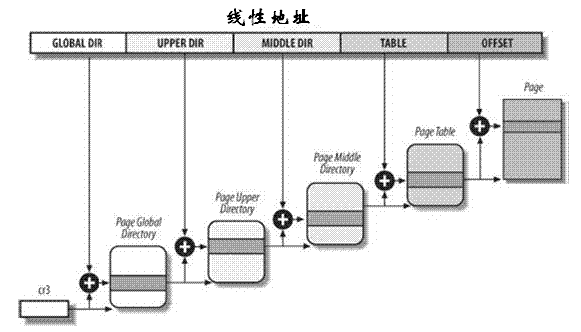
前面我们提到Linux内核仅使用了较少的分段机制,但是却对分页机制的依赖性很强,其使用一种适合32位和64位结构的通用分页模型,该模型使用四级分页机制,即
- 页全局目录(Page Global Directory)
- 页上级目录(Page Upper Directory)
- 页中间目录(Page Middle Directory)
- 页表(Page Table)
- 页全局目录包含若干页上级目录的地址;
- 页上级目录又依次包含若干页中间目录的地址;
- 而页中间目录又包含若干页表的地址;
- 每一个页表项指向一个页框。
因此线性地址因此被分成五个部分,而每一部分的大小与具体的计算机体系结构有关。
1.3 不同架构的分页机制
对于不同的体系结构,Linux采用的四级页表目录的大小有所不同:对于i386而言,仅采用二级页表,即页上层目录和页中层目录长度为0;对于启用PAE的i386,采用了三级页表,即页上层目录长度为0;对于64位体系结构,可以采用三级或四级页表,具体选择由硬件决定。
对于没有启用物理地址扩展的32位系统,两级页表已经足够了。从本质上说Linux通过使“页上级目录”位和“页中间目录”位全为0,彻底取消了页上级目录和页中间目录字段。不过,页上级目录和页中间目录在指针序列中的位置被保留,以便同样的代码在32位系统和64位系统下都能使用。内核为页上级目录和页中间目录保留了一个位置,这是通过把它们的页目录项数设置为1,并把这两个目录项映射到页全局目录的一个合适的目录项而实现的。
启用了物理地址扩展的32 位系统使用了三级页表。Linux 的页全局目录对应80x86 的页目录指针表(PDPT),取消了页上级目录,页中间目录对应80x86的页目录,Linux的页表对应80x86的页表。
最终,64位系统使用三级还是四级分页取决于硬件对线性地址的位的划分。
1.4 为什么linux热衷:分页>分段
那么,为什么Linux是如此地热衷使用分页技术而对分段机制表现得那么地冷淡呢,因为Linux的进程处理很大程度上依赖于分页。事实上,线性地址到物理地址的自动转换使下面的设计目标变得可行:
- 给每一个进程分配一块不同的物理地址空间,这确保了可以有效地防止寻址错误。
- 区别页(即一组数据)和页框(即主存中的物理地址)之不同。这就允许存放在某个页框中的一个页,然后保存到磁盘上,以后重新装入这同一页时又被装在不同的页框中。这就是虚拟内存机制的基本要素。
每一个进程有它自己的页全局目录和自己的页表集。当发生进程切换时,Linux把cr3控制寄存器的内容保存在前一个执行进程的描述符中,然后把下一个要执行进程的描述符的值装入cr3寄存器中。因此,当新进程重新开始在CPU上执行时,分页单元指向一组正确的页表。
把线性地址映射到物理地址虽然有点复杂,但现在已经成了一种机械式的任务。
2 linux中页表处理数据结构
2.1 页表类型定义pgd_t、pmd_t、pud_t和pte_t
Linux分别采用pgd_t、pmd_t、pud_t和pte_t四种数据结构来表示页全局目录项、页上级目录项、页中间目录项和页表项。这四种 数据结构本质上都是无符号长整型unsigned long
Linux为了更严格数据类型检查,将无符号长整型unsigned long分别封装成四种不同的页表项。如果不采用这种方法,那么一个无符号长整型数据可以传入任何一个与四种页表相关的函数或宏中,这将大大降低程序的健壮性。
pgprot_t是另一个64位(PAE激活时)或32位(PAE禁用时)的数据类型,它表示与一个单独表项相关的保护标志。
首先我们查看一下子这些类型是如何定义的
2.1.1 pteval_t,pmdval_t,pudval_t,pgdval_t
参照arch/x86/include/asm/pgtable_64_types.h
#ifndef __ASSEMBLY__
#include 2.1.2 pgd_t、pmd_t、pud_t和pte_t
参照 /arch/x86/include/asm/pgtable_types.h
typedef struct { pgdval_t pgd; } pgd_t;
static inline pgd_t native_make_pgd(pgdval_t val)
{
return (pgd_t) { val };
}
static inline pgdval_t native_pgd_val(pgd_t pgd)
{
return pgd.pgd;
}
static inline pgdval_t pgd_flags(pgd_t pgd)
{
return native_pgd_val(pgd) & PTE_FLAGS_MASK;
}
#if CONFIG_PGTABLE_LEVELS > 3
typedef struct { pudval_t pud; } pud_t;
static inline pud_t native_make_pud(pmdval_t val)
{
return (pud_t) { val };
}
static inline pudval_t native_pud_val(pud_t pud)
{
return pud.pud;
}
#else
#include 2.1.4 xxx_val和__xxx
参照/arch/x86/include/asm/pgtable.h
五个类型转换宏(_ pte、_ pmd、_ pud、_ pgd和__ pgprot)把一个无符号整数转换成所需的类型。
另外的五个类型转换宏(pte_val,pmd_val, pud_val, pgd_val和pgprot_val)执行相反的转换,即把上面提到的四种特殊的类型转换成一个无符号整数。
#define pgd_val(x) native_pgd_val(x)
#define __pgd(x) native_make_pgd(x)
#ifndef __PAGETABLE_PUD_FOLDED
#define pud_val(x) native_pud_val(x)
#define __pud(x) native_make_pud(x)
#endif
#ifndef __PAGETABLE_PMD_FOLDED
#define pmd_val(x) native_pmd_val(x)
#define __pmd(x) native_make_pmd(x)
#endif
#define pte_val(x) native_pte_val(x)
#define __pte(x) native_make_pte(x)这里需要区别指向页表项的指针和页表项所代表的数据。以pgd_t类型为例子,如果已知一个pgd_t类型的指针pgd,那么通过pgd_val(*pgd)即可获得该页表项(也就是一个无符号长整型数据),这里利用了面向对象的思想。
2.2 页表描述宏
参照arch/x86/include/asm/pgtable_64
linux中使用下列宏简化了页表处理,对于每一级页表都使用有以下三个关键描述宏:
| 宏字段 | 描述 |
|---|---|
| XXX_SHIFT | 指定Offset字段的位数 |
| XXX_SIZE | 页的大小 |
| XXX_MASK | 用以屏蔽Offset字段的所有位。 |
我们的四级页表,对应的宏分别由PAGE,PMD,PUD,PGDIR
| 宏字段前缀 | 描述 |
|---|---|
| PGDIR | 页全局目录(Page Global Directory) |
| PUD | 页上级目录(Page Upper Directory) |
| PMD | 页中间目录(Page Middle Directory) |
| PAGE | 页表(Page Table) |
2.2.1 PAGE宏–页表(Page Table)
| 字段 | 描述 |
|---|---|
| PAGE_SHIFT | 指定Offset字段的位数 |
| PAGE_SIZE | 页的大小 |
| PAGE_MASK | 用以屏蔽Offset字段的所有位。 |
定义如下,在/arch/x86/include/asm/page_types.h 文件中
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
#define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)
#define PAGE_MASK (~(PAGE_SIZE-1))当用于80x86处理器时,PAGE_SHIFT返回的值为12。
由于页内所有地址都必须放在Offset字段, 因此80x86系统的页的大小PAGE_SIZE是 212=4096 字节。
PAGE_MASK宏产生的值为0xfffff000,用以屏蔽Offset字段的所有位。
2.2.2 PMD-Page Middle Directory (页目录)
| 字段 | 描述 |
|---|---|
| PMD_SHIFT | 指定线性地址的Offset和Table字段的总位数;换句话说,是页中间目录项可以映射的区域大小的对数 |
| PMD_SIZE | 用于计算由页中间目录的一个单独表项所映射的区域大小,也就是一个页表的大小 |
| PMD_MASK | 用于屏蔽Offset字段与Table字段的所有位 |
当PAE 被禁用时,PMD_SHIFT 产生的值为22(来自Offset 的12 位加上来自Table 的10 位),
PMD_SIZE 产生的值为222 或 4 MB,
PMD_MASK产生的值为 0xffc00000。
相反,当PAE被激活时,
PMD_SHIFT 产生的值为21 (来自Offset的12位加上来自Table的9位),
PMD_SIZE 产生的值为 221 或2 MB
PMD_MASK产生的值为 0xffe00000。
大型页不使用最后一级页表,所以产生大型页尺寸的LARGE_PAGE_SIZE 宏等于PMD_SIZE(2PMD_SHIFT),而在大型页地址中用于屏蔽Offset字段和Table字段的所有位的LARGE_PAGE_MASK宏,就等于PMD_MASK。
2.2.3 PUD_SHIFT-页上级目录(Page Upper Directory)
| 字段 | 描述 |
|---|---|
| PUD_SHIFT | 确定页上级目录项能映射的区域大小的位数 |
| PUD_SIZE | 用于计算页全局目录中的一个单独表项所能映射的区域大小。 |
| PUD_MASK | 用于屏蔽Offset字段,Table字段,Middle Air字段和Upper Air字段的所有位 |
在80x86处理器上,PUD_SHIFT总是等价于PMD_SHIFT,而PUD_SIZE则等于4MB或2MB。
2.2.4 PGDIR_SHIFT-页全局目录(Page Global Directory)
| 字段 | 描述 |
|---|---|
| PGDIR_SHIFT | 确定页全局页目录项能映射的区域大小的位数 |
| PGDIR_SIZE | 用于计算页全局目录中一个单独表项所能映射区域的大小 |
| PGDIR_MASK | 用于屏蔽Offset, Table,Middle Air及Upper Air的所有位 |
当PAE 被禁止时,
PGDIR_SHIFT 产生的值为22(与PMD_SHIFT 和PUD_SHIFT 产生的值相同),
PGDIR_SIZE 产生的值为 222 或 4 MB,
PGDIR_MASK 产生的值为 0xffc00000。
相反,当PAE被激活时,
PGDIR_SHIFT 产生的值为30 (12 位Offset 加 9 位Table再加 9位 Middle Air),
PGDIR_SIZE 产生的值为230 或 1 GB
PGDIR_MASK产生的值为0xc0000000
PTRS_PER_PTE, PTRS_PER_PMD, PTRS_PER_PUD以及PTRS_PER_PGD
用于计算页表、页中间目录、页上级目录和页全局目录表中表项的个数。当PAE被禁止时,它们产生的值分别为1024,1,1和1024。当PAE被激活时,产生的值分别为512,512,1和4。
2.3 页表处理函数
[注意]
以下内容主要参见 深入理解linux内核第二章内存寻址中页表处理
内核还提供了许多宏和函数用于读或修改页表表项:
如果相应的表项值为0,那么,宏pte_none、pmd_none、pud_none和 pgd_none产生的值为1,否则产生的值为0。
宏pte_clear、pmd_clear、pud_clear和 pgd_clear清除相应页表的一个表项,由此禁止进程使用由该页表项映射的线性地址。ptep_get_and_clear( )函数清除一个页表项并返回前一个值。
set_pte,set_pmd,set_pud和set_pgd向一个页表项中写入指定的值。set_pte_atomic与set_pte作用相同,但是当PAE被激活时它同样能保证64位的值能被原子地写入。
如果a和b两个页表项指向同一页并且指定相同访问优先级,pte_same(a,b)返回1,否则返回0。
如果页中间目录项指向一个大型页(2MB或4MB),pmd_large(e)返回1,否则返回0。
宏pmd_bad由函数使用并通过输入参数传递来检查页中间目录项。如果目录项指向一个不能使用的页表,也就是说,如果至少出现以下条件中的一个,则这个宏产生的值为1:
页不在主存中(Present标志被清除)。
页只允许读访问(Read/Write标志被清除)。
Acessed或者Dirty位被清除(对于每个现有的页表,Linux总是
强制设置这些标志)。
pud_bad宏和pgd_bad宏总是产生0。没有定义pte_bad宏,因为页表项引用一个不在主存中的页,一个不可写的页或一个根本无法访问的页都是合法的。
如果一个页表项的Present标志或者Page Size标志等于1,则pte_present宏产生的值为1,否则为0。
前面讲过页表项的Page Size标志对微处理器的分页部件来讲没有意义,然而,对于当前在主存中却又没有读、写或执行权限的页,内核将其Present和Page Size分别标记为0和1。
这样,任何试图对此类页的访问都会引起一个缺页异常,因为页的Present标志被清0,而内核可以通过检查Page Size的值来检测到产生异常并不是因为缺页。
如果相应表项的Present标志等于1,也就是说,如果对应的页或页表被装载入主存,pmd_present宏产生的值为1。pud_present宏和pgd_present宏产生的值总是1。
2.3.1 查询页表项中任意一个标志的当前值
下表中列出的函数用来查询页表项中任意一个标志的当前值;除了pte_file()外,其他函数只有在pte_present返回1的时候,才能正常返回页表项中任意一个标志。
| 函数名称 | 说明 |
|---|---|
| pte_user( ) | 读 User/Supervisor 标志 |
| pte_read( ) | 读 User/Supervisor 标志(表示 80x86 处理器上的页不受读的保护) |
| pte_write( ) | 读 Read/Write 标志 |
| pte_exec( ) | 读 User/Supervisor 标志( 80x86 处理器上的页不受代码执行的保护) |
| pte_dirty( ) | 读 Dirty 标志 |
| pte_young( ) | 读 Accessed 标志 |
| pte_file( ) | 读 Dirty 标志(当 Present 标志被清除而 Dirty 标志被设置时,页属于一个非线性磁盘文件映射) |
2.3.2 设置页表项中各标志的值
下表列出的另一组函数用于设置页表项中各标志的值
| 函数名称 | 说明 |
|---|---|
| mk_pte_huge( ) | 设置页表项中的 Page Size 和 Present 标志 |
| pte_wrprotect( ) | 清除 Read/Write 标志 |
| pte_rdprotect( ) | 清除 User/Supervisor 标志 |
| pte_exprotect( ) | 清除 User/Supervisor 标志 |
| pte_mkwrite( ) | 设置 Read/Write 标志 |
| pte_mkread( ) | 设置 User/Supervisor 标志 |
| pte_mkexec( ) | 设置 User/Supervisor 标志 |
| pte_mkclean( ) | 清除 Dirty 标志 |
| pte_mkdirty( ) | 设置 Dirty 标志 |
| pte_mkold( ) | 清除 Accessed 标志(把此页标记为未访问) |
| pte_mkyoung( ) | 设置 Accessed 标志(把此页标记为访问过) |
| pte_modify(p,v) | 把页表项 p 的所有访问权限设置为指定的值 |
| ptep_set_wrprotect() | 与 pte_wrprotect( ) 类似,但作用于指向页表项的指针 |
| ptep_set_access_flags( ) | 如果 Dirty 标志被设置为 1 则将页的访问权设置为指定的值,并调用flush_tlb_page() 函数 |
| ptep_mkdirty() | 与 pte_mkdirty( ) 类似,但作用于指向页表项的指针。 |
| ptep_test_and_clear_dirty( ) | 与 pte_mkclean( ) 类似,但作用于指向页表项的指针并返回 Dirty 标志的旧值 |
| ptep_test_and_clear_young( ) | 与 pte_mkold( ) 类似,但作用于指向页表项的指针并返回 Accessed标志的旧值 |
2.3.3 宏函数-把一个页地址和一组保护标志组合成页表项,或者执行相反的操作
现在,我们来讨论下表中列出的宏,它们把一个页地址和一组保护标志组合成页表项,或者执行相反的操作,从一个页表项中提取出页地址。请注意这其中的一些宏对页的引用是通过 “页描述符”的线性地址,而不是通过该页本身的线性地址。
| 宏名称 | 说明 |
|---|---|
| pgd_index(addr) | 找到线性地址 addr 对应的的目录项在页全局目录中的索引(相对位置) |
| pgd_offset(mm, addr) | 接收内存描述符地址 mm 和线性地址 addr 作为参数。这个宏产生地址addr 在页全局目录中相应表项的线性地址;通过内存描述符 mm 内的一个指针可以找到这个页全局目录 |
| pgd_offset_k(addr) | 产生主内核页全局目录中的某个项的线性地址,该项对应于地址 addr |
| pgd_page(pgd) | 通过页全局目录项 pgd 产生页上级目录所在页框的页描述符地址。在两级或三级分页系统中,该宏等价于 pud_page() ,后者应用于页上级目录项 |
| pud_offset(pgd, addr) | 参数为指向页全局目录项的指针 pgd 和线性地址 addr 。这个宏产生页上级目录中目录项 addr 对应的线性地址。在两级或三级分页系统中,该宏产生 pgd ,即一个页全局目录项的地址 |
| pud_page(pud) | 通过页上级目录项 pud 产生相应的页中间目录的线性地址。在两级分页系统中,该宏等价于 pmd_page() ,后者应用于页中间目录项 |
| pmd_index(addr) | 产生线性地址 addr 在页中间目录中所对应目录项的索引(相对位置) |
| pmd_offset(pud, addr) | 接收指向页上级目录项的指针 pud 和线性地址 addr 作为参数。这个宏产生目录项 addr 在页中间目录中的偏移地址。在两级或三级分页系统中,它产生 pud ,即页全局目录项的地址 |
| pmd_page(pmd) | 通过页中间目录项 pmd 产生相应页表的页描述符地址。在两级或三级分页系统中, pmd 实际上是页全局目录中的一项 |
| mk_pte(p,prot) | 接收页描述符地址 p 和一组访问权限 prot 作为参数,并创建相应的页表项 |
| pte_index(addr) | 产生线性地址 addr 对应的表项在页表中的索引(相对位置) |
| pte_offset_kernel(dir,addr) | 线性地址 addr 在页中间目录 dir 中有一个对应的项,该宏就产生这个对应项,即页表的线性地址。另外,该宏只在主内核页表上使用 |
| pte_offset_map(dir, addr) | 接收指向一个页中间目录项的指针 dir 和线性地址 addr 作为参数,它产生与线性地址 addr 相对应的页表项的线性地址。如果页表被保存在高端存储器中,那么内核建立一个临时内核映射,并用 pte_unmap 对它进行释放。 pte_offset_map_nested 宏和 pte_unmap_nested 宏是相同的,但它们使用不同的临时内核映射 |
| pte_page( x ) | 返回页表项 x 所引用页的描述符地址 |
| pte_to_pgoff( pte ) | 从一个页表项的 pte 字段内容中提取出文件偏移量,这个偏移量对应着一个非线性文件内存映射所在的页 |
| pgoff_to_pte(offset ) | 为非线性文件内存映射所在的页创建对应页表项的内容 |
2.3.4 简化页表项的创建和撤消
下面我们罗列最后一组函数来简化页表项的创建和撤消。当使用两级页表时,创建或删除一个页中间目录项是不重要的。如本节前部分所述,页中间目录仅含有一个指向下属页表的目录项。所以,页中间目录项只是页全局目录中的一项而已。然而当处理页表时,创建一个页表项可能很复杂,因为包含页表项的那个页表可能就不存在。在这样的情况下,有必要分配一个新页框,把它填写为 0 ,并把这个表项加入。
如果 PAE 被激活,内核使用三级页表。当内核创建一个新的页全局目录时,同时也分配四个相应的页中间目录;只有当父页全局目录被释放时,这四个页中间目录才得以释放。当使用两级或三级分页时,页上级目录项总是被映射为页全局目录中的一个单独项。与以往一样,下表中列出的函数描述是针对 80x86 构架的。
| 函数名称 | 说明 |
|---|---|
| pgd_alloc( mm ) | 分配一个新的页全局目录。如果 PAE 被激活,它还分配三个对应用户态线性地址的子页中间目录。参数 mm( 内存描述符的地址 )在 80x86 构架上被忽略 |
| pgd_free( pgd) | 释放页全局目录中地址为 pgd 的项。如果 PAE 被激活,它还将释放用户态线性地址对应的三个页中间目录 |
| pud_alloc(mm, pgd, addr) | 在两级或三级分页系统下,这个函数什么也不做:它仅仅返回页全局目录项 pgd 的线性地址 |
| pud_free(x) | 在两级或三级分页系统下,这个宏什么也不做 |
| pmd_alloc(mm, pud, addr) | 定义这个函数以使普通三级分页系统可以为线性地址 addr 分配一个新的页中间目录。如果 PAE 未被激活,这个函数只是返回输入参数 pud 的值,也就是说,返回页全局目录中目录项的地址。如果 PAE 被激活,该函数返回线性地址 addr 对应的页中间目录项的线性地址。参数 mm 被忽略 |
| pmd_free(x) | 该函数什么也不做,因为页中间目录的分配和释放是随同它们的父全局目录一同进行的 |
| pte_alloc_map(mm, pmd, addr) | 接收页中间目录项的地址 pmd 和线性地址 addr 作为参数,并返回与 addr 对应的页表项的地址。如果页中间目录项为空,该函数通过调用函数 pte_alloc_one( ) 分配一个新页表。如果分配了一个新页表, addr 对应的项就被创建,同时 User/Supervisor 标志被设置为 1 。如果页表被保存在高端内存,则内核建立一个临时内核映射,并用 pte_unmap 对它进行释放 |
| pte_alloc_kernel(mm, pmd, addr) | 如果与地址 addr 相关的页中间目录项 pmd 为空,该函数分配一个新页表。然后返回与 addr 相关的页表项的线性地址。该函数仅被主内核页表使用 |
| pte_free(pte) | 释放与页描述符指针 pte 相关的页表 |
| pte_free_kernel(pte) | 等价于 pte_free( ) ,但由主内核页表使用 |
| clear_page_range(mmu, start,end) | 从线性地址 start 到 end 通过反复释放页表和清除页中间目录项来清除进程页表的内容 |
3 线性地址转换
3.1 分页模式下的的线性地址转换
线性地址、页表和页表项线性地址不管系统采用多少级分页模型,线性地址本质上都是索引+偏移量的形式,甚至你可以将整个线性地址看作N+1个索引的组合,N是系统采用的分页级数。在四级分页模型下,线性地址被分为5部分,如下图:
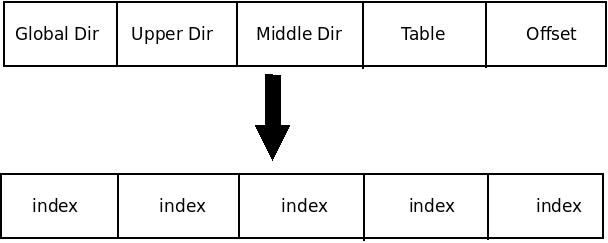
在线性地址中,每个页表索引即代表线性地址在对应级别的页表中中关联的页表项。正是这种索引与页表项的对应关系形成了整个页表映射机制。
3.1.1 页表
多个页表项的集合则为页表,一个页表内的所有页表项是连续存放的。页表本质上是一堆数据,因此也是以页为单位存放在主存中的。因此,在虚拟地址转化物理物理地址的过程中,每访问一级页表就会访问一次内存。
3.1.2 页表项
页表项从四种页表项的数据结构可以看出,每个页表项其实就是一个无符号长整型数据。每个页表项分两大类信息:页框基地址和页的属性信息。在x86-32体系结构中,每个页表项的结构图如下:
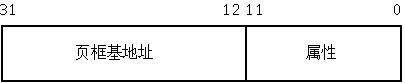
这个图是一个通用模型,其中页表项的前20位是物理页的基地址。由于32位的系统采用4kb大小的 页,因此每个页表项的后12位均为0。内核将后12位充分利用,每个位都表示对应虚拟页的相关属性。
不管是那一级的页表,它的功能就是建立虚拟地址和物理地址之间的映射关系,一个页和一个页框之间的映射关系体现在页表项中。上图中的物理页基地址是 个抽象的说明,如果当前的页表项位于页全局目录中,这个物理页基址是指页上级目录所在物理页的基地址;如果当前页表项位于页表中,这个物理页基地址是指最 终要访问数据所在物理页的基地址。
3.1.3 地址转换过程
地址转换过程有了上述的基本知识,就很好理解四级页表模式下如何将虚拟地址转化为逻辑地址了。基本过程如下:
1.从CR3寄存器中读取页目录所在物理页面的基址(即所谓的页目录基址),从线性地址的第一部分获取页目录项的索引,两者相加得到页目录项的物理地址。
2.第一次读取内存得到pgd_t结构的目录项,从中取出物理页基址取出(具体位数与平台相关,如果是32系统,则为20位),即页上级页目录的物理基地址。
3.从线性地址的第二部分中取出页上级目录项的索引,与页上级目录基地址相加得到页上级目录项的物理地址。
4.第二次读取内存得到pud_t结构的目录项,从中取出页中间目录的物理基地址。
5.从线性地址的第三部分中取出页中间目录项的索引,与页中间目录基址相加得到页中间目录项的物理地址。
6.第三次读取内存得到pmd_t结构的目录项,从中取出页表的物理基地址。
7.从线性地址的第四部分中取出页表项的索引,与页表基址相加得到页表项的物理地址。
8.第四次读取内存得到pte_t结构的目录项,从中取出物理页的基地址。
9.从线性地址的第五部分中取出物理页内偏移量,与物理页基址相加得到最终的物理地址。
10.第五次读取内存得到最终要访问的数据。
整个过程是比较机械的,每次转换先获取物理页基地址,再从线性地址中获取索引,合成物理地址后再访问内存。不管是页表还是要访问的数据都是以页为单 位存放在主存中的,因此每次访问内存时都要先获得基址,再通过索引(或偏移)在页内访问数据,因此可以将线性地址看作是若干个索引的集合。


3.2 Linux中通过4级页表访问物理内存
linux中每个进程有它自己的PGD( Page Global Directory),它是一个物理页,并包含一个pgd_t数组。
进程的pgd_t数据见 task_struct -> mm_struct -> pgd_t * pgd;
PTEs, PMDs和PGDs分别由pte_t, pmd_t 和pgd_t来描述。为了存储保护位,pgprot_t被定义,它拥有相关的flags并经常被存储在page table entry低位(lower bits),其具体的存储方式依赖于CPU架构。
前面我们讲了页表处理的大多数函数信息,在上面我们又讲了线性地址如何转换为物理地址,其实就是不断索引的过程。
通过如下几个函数,不断向下索引,就可以从进程的页表中搜索特定地址对应的页面对象
| 宏函数 | 说明 |
|---|---|
| pgd_offset | 根据当前虚拟地址和当前进程的mm_struct获取pgd项 |
| pud_offset | 参数为指向页全局目录项的指针 pgd 和线性地址 addr 。这个宏产生页上级目录中目录项 addr 对应的线性地址。在两级或三级分页系统中,该宏产生 pgd ,即一个页全局目录项的地址 |
| pmd_offset | 根据通过pgd_offset获取的pgd 项和虚拟地址,获取相关的pmd项(即pte表的起始地址) |
| pte_offset | 根据通过pmd_offset获取的pmd项和虚拟地址,获取相关的pte项(即物理页的起始地址) |
根据虚拟地址获取物理页的示例代码详见mm/memory.c中的函数follow_page
不同的版本可能有所不同,早起内核中存在follow_page,而后来的内核中被follow_page_mask替代,目前最新的发布4.4中未查找到此函数
我们从早期的linux-3.8的源代码中, 截取的代码如下
/**
* follow_page - look up a page descriptor from a user-virtual address
* @vma: vm_area_struct mapping @address
* @address: virtual address to look up
* @flags: flags modifying lookup behaviour
*
* @flags can have FOLL_ flags set, defined in
*
* Returns the mapped (struct page *), %NULL if no mapping exists, or
* an error pointer if there is a mapping to something not represented
* by a page descriptor (see also vm_normal_page()).
*/
struct page *follow_page(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *ptep, pte;
spinlock_t *ptl;
struct page *page;
struct mm_struct *mm = vma->vm_mm;
page = follow_huge_addr(mm, address, flags & FOLL_WRITE);
if (!IS_ERR(page)) {
BUG_ON(flags & FOLL_GET);
goto out;
}
page = NULL;
pgd = pgd_offset(mm, address);
if (pgd_none(*pgd) || unlikely(pgd_bad(*pgd)))
goto no_page_table;
pud = pud_offset(pgd, address);
if (pud_none(*pud))
goto no_page_table;
if (pud_huge(*pud) && vma->vm_flags & VM_HUGETLB) {
BUG_ON(flags & FOLL_GET);
page = follow_huge_pud(mm, address, pud, flags & FOLL_WRITE);
goto out;
}
if (unlikely(pud_bad(*pud)))
goto no_page_table;
pmd = pmd_offset(pud, address);
if (pmd_none(*pmd))
goto no_page_table;
if (pmd_huge(*pmd) && vma->vm_flags & VM_HUGETLB) {
BUG_ON(flags & FOLL_GET);
page = follow_huge_pmd(mm, address, pmd, flags & FOLL_WRITE);
goto out;
}
if (pmd_trans_huge(*pmd)) {
if (flags & FOLL_SPLIT) {
split_huge_page_pmd(mm, pmd);
goto split_fallthrough;
}
spin_lock(&mm->page_table_lock);
if (likely(pmd_trans_huge(*pmd))) {
if (unlikely(pmd_trans_splitting(*pmd))) {
spin_unlock(&mm->page_table_lock);
wait_split_huge_page(vma->anon_vma, pmd);
} else {
page = follow_trans_huge_pmd(mm, address,
pmd, flags);
spin_unlock(&mm->page_table_lock);
goto out;
}
} else
spin_unlock(&mm->page_table_lock);
/* fall through */
}
split_fallthrough:
if (unlikely(pmd_bad(*pmd)))
goto no_page_table;
ptep = pte_offset_map_lock(mm, pmd, address, &ptl);
pte = *ptep;
if (!pte_present(pte))
goto no_page;
if ((flags & FOLL_WRITE) && !pte_write(pte))
goto unlock;
page = vm_normal_page(vma, address, pte);
if (unlikely(!page)) {
if ((flags & FOLL_DUMP) ||
!is_zero_pfn(pte_pfn(pte)))
goto bad_page;
page = pte_page(pte);
}
if (flags & FOLL_GET)
get_page(page);
if (flags & FOLL_TOUCH) {
if ((flags & FOLL_WRITE) &&
!pte_dirty(pte) && !PageDirty(page))
set_page_dirty(page);
/*
* pte_mkyoung() would be more correct here, but atomic care
* is needed to avoid losing the dirty bit: it is easier to use
* mark_page_accessed().
*/
mark_page_accessed(page);
}
if ((flags & FOLL_MLOCK) && (vma->vm_flags & VM_LOCKED)) {
/*
* The preliminary mapping check is mainly to avoid the
* pointless overhead of lock_page on the ZERO_PAGE
* which might bounce very badly if there is contention.
*
* If the page is already locked, we don't need to
* handle it now - vmscan will handle it later if and
* when it attempts to reclaim the page.
*/
if (page->mapping && trylock_page(page)) {
lru_add_drain(); /* push cached pages to LRU */
/*
* Because we lock page here and migration is
* blocked by the pte's page reference, we need
* only check for file-cache page truncation.
*/
if (page->mapping)
mlock_vma_page(page);
unlock_page(page);
}
}
unlock:
pte_unmap_unlock(ptep, ptl);
out:
return page;
bad_page:
pte_unmap_unlock(ptep, ptl);
return ERR_PTR(-EFAULT);
no_page:
pte_unmap_unlock(ptep, ptl);
if (!pte_none(pte))
return page;
no_page_table:
/*
* When core dumping an enormous anonymous area that nobody
* has touched so far, we don't want to allocate unnecessary pages or
* page tables. Return error instead of NULL to skip handle_mm_fault,
* then get_dump_page() will return NULL to leave a hole in the dump.
* But we can only make this optimization where a hole would surely
* be zero-filled if handle_mm_fault() actually did handle it.
*/
if ((flags & FOLL_DUMP) &&
(!vma->vm_ops || !vma->vm_ops->fault))
return ERR_PTR(-EFAULT);
return page;
} 以上代码可以精简为
unsigned long v2p(int pid unsigned long va)
{
unsigned long pa = 0;
struct task_struct *pcb_tmp = NULL;
pgd_t *pgd_tmp = NULL;
pud_t *pud_tmp = NULL;
pmd_t *pmd_tmp = NULL;
pte_t *pte_tmp = NULL;
printk(KERN_INFO"PAGE_OFFSET = 0x%lx\n",PAGE_OFFSET);
printk(KERN_INFO"PGDIR_SHIFT = %d\n",PGDIR_SHIFT);
printk(KERN_INFO"PUD_SHIFT = %d\n",PUD_SHIFT);
printk(KERN_INFO"PMD_SHIFT = %d\n",PMD_SHIFT);
printk(KERN_INFO"PAGE_SHIFT = %d\n",PAGE_SHIFT);
printk(KERN_INFO"PTRS_PER_PGD = %d\n",PTRS_PER_PGD);
printk(KERN_INFO"PTRS_PER_PUD = %d\n",PTRS_PER_PUD);
printk(KERN_INFO"PTRS_PER_PMD = %d\n",PTRS_PER_PMD);
printk(KERN_INFO"PTRS_PER_PTE = %d\n",PTRS_PER_PTE);
printk(KERN_INFO"PAGE_MASK = 0x%lx\n",PAGE_MASK);
//if(!(pcb_tmp = find_task_by_pid(pid)))
if(!(pcb_tmp = findTaskByPid(pid)))
{
printk(KERN_INFO"Can't find the task %d .\n",pid);
return 0;
}
printk(KERN_INFO"pgd = 0x%p\n",pcb_tmp->mm->pgd);
/* 判断给出的地址va是否合法(va<vm_end)*/
if(!find_vma(pcb_tmp->mm,va))
{
printk(KERN_INFO"virt_addr 0x%lx not available.\n",va);
return 0;
}
pgd_tmp = pgd_offset(pcb_tmp->mm,va);
printk(KERN_INFO"pgd_tmp = 0x%p\n",pgd_tmp);
printk(KERN_INFO"pgd_val(*pgd_tmp) = 0x%lx\n",pgd_val(*pgd_tmp));
if(pgd_none(*pgd_tmp))
{
printk(KERN_INFO"Not mapped in pgd.\n");
return 0;
}
pud_tmp = pud_offset(pgd_tmp,va);
printk(KERN_INFO"pud_tmp = 0x%p\n",pud_tmp);
printk(KERN_INFO"pud_val(*pud_tmp) = 0x%lx\n",pud_val(*pud_tmp));
if(pud_none(*pud_tmp))
{
printk(KERN_INFO"Not mapped in pud.\n");
return 0;
}
pmd_tmp = pmd_offset(pud_tmp,va);
printk(KERN_INFO"pmd_tmp = 0x%p\n",pmd_tmp);
printk(KERN_INFO"pmd_val(*pmd_tmp) = 0x%lx\n",pmd_val(*pmd_tmp));
if(pmd_none(*pmd_tmp))
{
printk(KERN_INFO"Not mapped in pmd.\n");
return 0;
}
/*在这里,把原来的pte_offset_map()改成了pte_offset_kernel*/
pte_tmp = pte_offset_kernel(pmd_tmp,va);
printk(KERN_INFO"pte_tmp = 0x%p\n",pte_tmp);
printk(KERN_INFO"pte_val(*pte_tmp) = 0x%lx\n",pte_val(*pte_tmp));
if(pte_none(*pte_tmp))
{
printk(KERN_INFO"Not mapped in pte.\n");
return 0;
}
if(!pte_present(*pte_tmp)){
printk(KERN_INFO"pte not in RAM.\n");
return 0;
}
pa = (pte_val(*pte_tmp) & PAGE_MASK) | (va & ~PAGE_MASK);
printk(KERN_INFO"virt_addr 0x%lx in RAM is 0x%lx t .\n",va,pa);
printk(KERN_INFO"contect in 0x%lx is 0x%lx\n", pa, *(unsigned long *)((char *)pa + PAGE_OFFSET)
}