java多线程初探(三)并发容器
这里记录一些并发容器的概念。
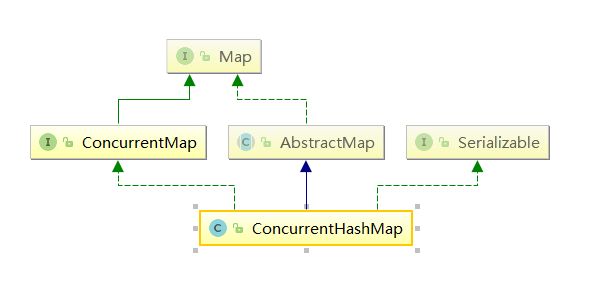
一、ConcurrentHashMap
ConcurrentHashMap(CHM)是在java1.5作为Hashtale的代替选择新引入的。
java1.5前在多线程和并发环境下使用Map只能选择Hashtable或者synchronizedMap(HashMap不是线程安全的所以不能使用)。
java1.5后可以使用ConcurrentHashMap,它大量的利用了volatile,final,CAS等lock-free技术来减少锁竞争对于性能的影响所以性能比Hashtable这种直接加内置锁synchronized来换取线程安全要性能高的多。
volatile:禁制指令重排序
CAS:compare and swap的缩写,中文翻译成比较并交换。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值 。否则,处理器不做任何操作。类似于 CAS 的指令,允许算法执行读-修改-写操作,而无需害怕其他线程同时修改变量,因为如果其他线程修改变量,那么 CAS 会检测它(并失败),算法可以对该操作重新计算。
二、CopyOnWriteArrayList
从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到。
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
CopyOnWrite并发容器用于读多写少的并发场景,比如白名单,黑名单,商品类目的访问和更新场景.
比较:
1、ArrayList是线程不安全的;2、Vector是比较老的线程安全的,但性能不行(同步方法);
3、CopyOnWriteArrayList在兼顾了线程安全的同时,又提高了并发性,性能比Vector高
注意点:
1,内存占用问题。因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,那么这个时候很有可能造成频繁的Yong GC和Full GC。
处理:不使用CopyOnWrite容器,而使用其他的并发容器,如ConcurrentHashMap。
Yong GC:清理年轻代。(垃圾回收)Full GC:清理整个堆空间—包括年轻代和老年代。
2,数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。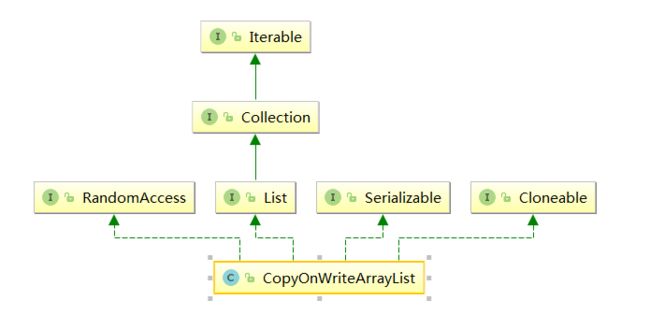
三、阻塞队列和生产者-消费者模式
生产者-消费者模式:
在线程里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这种生产消费能力不均衡的问题,所以有了生产者和消费者模式。
生产者-消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。
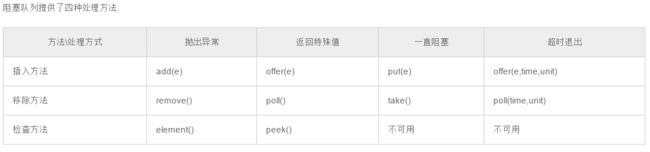
阻塞队列:
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
四、内存模型
计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,为了提供效率,因此在CPU里面就有了高速缓存。(两者不好解决时,通过第三者解决问题的思路)
也就是,当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,CPU进行计算时直接从它的高速缓存读取数据,当运算结束后,再将高速缓存中的数据刷新到主存当中。举个简单的例子,比如下面的这段代码:
i=i+1
当线程执行这个语句时,会先从主存当中读取i的值,然后复制一份到高速缓存当中,然后CPU执行指令对i进行加1操作,然后将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。
多线程条件下,缓存一致性问题:
可能存在这样一种情况:初始时,两个线程分别读取i的值存入各自所在的CPU(多核)的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存。最终结果i的值是1,而不是2。
为了解决缓存不一致问题,通常来说有以下2种解决方法:
1)通过在总线加LOCK#锁的方式(性能低)2)通过缓存一致性协议
这里解释第二种:最出名的是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。
它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
最后附上《java并发编程实战》的基础小结:
