前言
最近看到一篇非常不错的关于新词发现的论文--互联网时代的社会语言学:基于SNS的文本数据挖掘,迫不及待的想小试牛刀。得先有语料啊……
本文将爬取爱思助手官网的苹果咨询专栏。通过这里现学了点Scrapy。
安装
具体安装细节就不说了,度娘和Google都知道。
1、Python2.7
Scrapy需要用python编程。
2、anaconda
anaconda里面集成了很多关于python科学计算的第三方库,主要是安装方便,而python是一个编译器,如果不使用anaconda,那么安装起来会比较痛苦,各个库之间的依赖性就很难连接的很好。
3、MySQL
将爬取到的数据直接落地MySQL。需要新建一个表为后面存数据做准备。
CREATE TABLE `i4` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`title` VARCHAR(150) NOT NULL,
`time` VARCHAR(15) NOT NULL,
`content` LONGTEXT NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
4、Scrapy
pip install scrapy
实战
通过观察该页面发现图二才是我们真正需要爬取的网页,但是该网页没有需要跟进的链接,所有链接都在图一的网页里,所以我们需要做两件事,第一,在图一里拿URL,再通过URL到图二的网页里面爬取所需的内容(标题、发表时间、正文)。
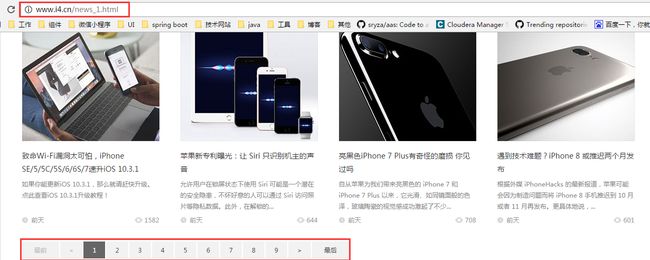
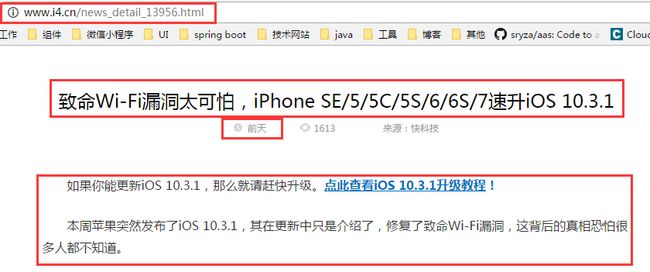
通过scrapy命令创建了一个名为i4的Scrapy项目。
scrapy startproject i4
该命令将会创建包含下列内容的i4目录:
这些文件分别是:
scrapy.cfg: 项目的配置文件
i4/: 该项目的python模块。之后您将在此加入代码。
i4/items.py: 项目中的item文件.
i4/pipelines.py: 项目中的pipelines文件.
i4/settings.py: 项目的设置文件.
i4/spiders/: 放置spider代码的目录.
定义提取的Item,Item是保存爬取到的数据的容器;
class I4Item(scrapy.Item):
title = scrapy.Field() #标题
time = scrapy.Field() #发布时间
content=scrapy.Field() #内容
pass
编写爬取网站的spider并提取Item,Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
class MySpider(scrapy.Spider):
name = "i4" #设置name
allowed_domains = ["www.i4.cn"] #设定域名
start_urls = ["http://www.i4.cn/news_1_0_0_2.html"] #填写爬取地址
#编写爬取方法
def parse(self, response):
for box in response.xpath('//div[@class="kbox"]//div[@class="news_list"]'): #爬取图二的网页内容
link=box.xpath('./a[@class="img"]/@href').extract()[0]
prefix='http://www.i4.cn/'
link = prefix+link
print(link)
yield scrapy.Request(url = link, callback=self.parse_item)
for box in response.xpath('//div[@class="paging"]'): #爬取图一的URL
link=box.xpath('./a[last()-1]/@href').extract()[0]
prefix='http://www.i4.cn/'
link = prefix+link
print(link)
yield scrapy.Request(url = link, callback=self.parse)
def parse_item(self, response):
item = I4Item() #实例一个容器保存爬取的信息
#这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
for box in response.xpath('//div[@class="block_l"]'):
item['title'] = box.xpath('.//h1[@class="title"]/text()').extract() #获取title
item['time'] = box.xpath('.//div[@class="info"]/div[@class="time "]').xpath('string(.)').extract() #获取time
item['content'] = box.xpath('./div[@class="content"]').xpath('string(.)').extract() #获取content
yield item #返回信息
编写Item Pipeline来存储提取到的Item(即数据)
class MySQLPipeline(object):
def __init__(self):
self.conn = MySQLdb.connect(host="192.168.0.103",user="root",passwd="123456",db="ufo",charset="utf8")
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = "insert ignore into i4(title, time, content) values(%s, %s, %s)"
param = (item['title'], item['time'], item['content'])
self.cursor.execute(sql,param)
self.conn.commit()
可以设置多个Pipeline,需要在settings.py里设置,数字大小意为先后顺序。
ITEM_PIPELINES = {
'i4.MyPipelines.MyPipeline': 1,
'i4.MySQLPipelines.MySQLPipeline': 2,
}
运行爬虫
scrapy crawl i4
结果会保存到MySQL数据库
