Phoenix的搭建和使用
Phoenix详细的信息可以查看: 官网 | apache/phoenix | Download | Performance | 支持的SQL语法
CDH6中集成的HBase版本为2.1.0+cdh6.2.0 ,我们从官方的镜像资源下载列表中看到最新的CDH支持到cdh5.14.2的版本,这种版本的直接有一个parcels包,可以通过Cloudera Manager的parcel页面添加资源,来安装组件。
通过查看源码git branch -a可以看到 remotes/origin/5.x-cdh6 分支,但在源码编译安装时这个分支还不完整,编译出来时会缺少一些包,因此我们直接尝试安装v5.0.0-HBase-2.0版本的Phoenix,安装方式有两种,第一种直接下载官方编译好的 apache-phoenix-5.0.0-HBase-2.0包apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz;第二种是通过编译源码的方式来安装。这里我们直接使用源码编译来进行安装。
目录
- 1 Installation
- 1.1 源码编译
- 1.2 安装
- 1.3 Cloudera Manager 的配置
- 2 Using
- 2.1 NoClassDefFoundError解决
- 2.2 原有HBase表的映射同步
- 2.3 查看表信息和插入数据
- 2.4 数据类型
- 2.5 修改表信息
- 2.6 删除库
- 2.7 执行SQL脚本
- 2.8 DDL语法
- 2.8.1 加盐表
- 2.8.2 自增ID
- 2.9 DML和DQL语法
- 2.9.1 Join
- 2.10 JDBC
- 2.10.1 新建一个Maven工程
- 2.10.2 pom.xml
- 2.10.3 JDBC Client代码
- 3 工具
- 3.1 DBeaver
- 3.2 SQuirrel SQL
- 3.2.1 下载
- 3.2.2 解压和配置
- 3.2.3 启动
- 3.2.4 配置 Phoenix 驱动
- 3.2.5 连接Phoenix
- 3.2.6 查询
- 4 资料
1 Installation
1.1 源码编译
# clone源码
git clone https://github.com/apache/phoenix.git
# 进入源码根目录
cd phoenix/
# 查看tag ,或者查看分支 git branch -a
git tag
# 选择一个版本,进入其分支,或者切换到某个分支:git checkout -b remotes/origin/5.x-cdh6
git checkout tags/v5.0.0-HBase-2.0
# 编译
mvn -T2C install -DskipTests
如果编译时报如下错误:
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 01:14 min (Wall Clock)
[INFO] Finished at: 2019-07-15T13:57:32+08:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.0:compile (scala-compile-first) on project phoenix-spark: wrap: org.apache.commons.exec.ExecuteException: Process exited with an error: 1 (Exit value: 1) -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn -rf :phoenix-spark
可以看到是phoenix-spark模块的net.alchim31.maven:scala-maven-plugin:3.2.0插件编译时发生了错误,我们可以将其原有的scala-maven-plugin注释掉,修改为如下,然后重新编译:
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
编译成功后如下:
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for Apache Phoenix 5.0.0-HBase-2.0:
[INFO]
[INFO] Apache Phoenix ..................................... SUCCESS [ 9.616 s]
[INFO] Phoenix Core ....................................... SUCCESS [03:34 min]
[INFO] Phoenix - Flume .................................... SUCCESS [01:56 min]
[INFO] Phoenix - Kafka .................................... SUCCESS [01:33 min]
[INFO] Phoenix - Pig ...................................... SUCCESS [04:59 min]
[INFO] Phoenix Query Server Client ........................ SUCCESS [ 48.315 s]
[INFO] Phoenix Query Server ............................... SUCCESS [07:59 min]
[INFO] Phoenix - Pherf .................................... SUCCESS [ 8.362 s]
[INFO] Phoenix - Spark .................................... SUCCESS [09:20 min]
[INFO] Phoenix - Hive ..................................... SUCCESS [57:28 min]
[INFO] Phoenix Client ..................................... SUCCESS [01:20 min]
[INFO] Phoenix Server ..................................... SUCCESS [ 37.906 s]
[INFO] Phoenix Assembly ................................... SUCCESS [ 19.902 s]
[INFO] Phoenix - Tracing Web Application .................. SUCCESS [ 9.255 s]
[INFO] Phoenix Load Balancer .............................. SUCCESS [ 19.176 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 01:01 h (Wall Clock)
[INFO] Finished at: 2019-07-07T11:09:10+08:00
[INFO] ------------------------------------------------------------------------
1.2 安装
将编译成功的phoenix-assembly/target/phoenix-5.0.0-HBase-2.0.tar.gz包拷贝到Phoenix的安装节点,然后解压
cp phoenix-assembly/target/phoenix-5.0.0-HBase-2.0.tar.gz /opt/
cd /opt
tar -zxf phoenix-5.0.0-HBase-2.0.tar.gz
cd phoenix-5.0.0-HBase-2.0
此时为了方便可以配置下环境变量
vim ~/.bash_profile
# 添加如下配置,并保存退出
export PHOENIX_HOME=/opt/phoenix-5.0.0-HBase-2.0
export PATH=$PATH:$PHOENIX_HOME/bin
接下来将Phoenix根目录下的phoenix-5.0.0-HBase-2.0-*.jar 包分发到每个RegionServer的lib下
scp phoenix-5.0.0-HBase-2.0-*.jar root@cdh3:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase/lib/
scp phoenix-5.0.0-HBase-2.0-*.jar root@cdh2:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase/lib/
scp phoenix-5.0.0-HBase-2.0-*.jar root@cdh1:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase/lib/
这里最好也将phoenix-5.0.0-HBase-2.0-client.jar拷贝到Phoenix安装的根目录下
cp phoenix-client/target/phoenix-5.0.0-HBase-2.0-client.jar $PHOENIX_HOME/
1.3 Cloudera Manager 的配置
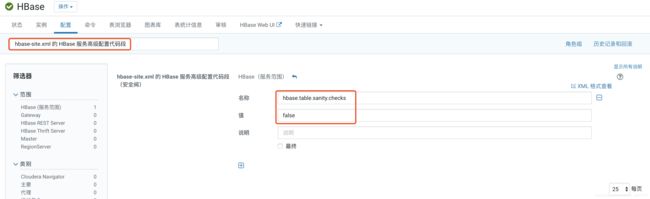
登陆Cloudera Manager页面,然后修改HBase配置,进入配置页面后搜索hbase-site.xml 的 HBase 服务高级配置代码段,然后添加如下配置,然后重启 HBase 使配置生效。
<property>
<name>hbase.table.sanity.checksname>
<value>falsevalue>
property>
2 Using
进入Phoenix的命令行执行
# 后面跟的参数为HBase配置的ZK的地址
sqlline.py cdh2:2181
2.1 NoClassDefFoundError解决
如果进入Phoenix终端时报如下错误:
Error: org.apache.phoenix.exception.PhoenixIOException: org.apache.hadoop.hbase.DoNotRetryIOException: java.lang.NoClassDefFoundError: org/apache/htrace/Trace
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:469)
at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:130)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:324)
at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:304)
Caused by: java.lang.NoClassDefFoundError: org/apache/htrace/Trace
at org.apache.phoenix.coprocessor.BaseScannerRegionObserver$RegionScannerHolder.overrideDelegate(BaseScannerRegionObserver.java:222)
at org.apache.phoenix.coprocessor.BaseScannerRegionObserver$RegionScannerHolder.nextRaw(BaseScannerRegionObserver.java:273)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.scan(RSRpcServices.java:3134)
at org.apache.hadoop.hbase.regionserver.RSRpcServices.scan(RSRpcServices.java:3383)
at org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:42002)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:413)
... 3 more
Caused by: java.lang.ClassNotFoundException: org.apache.htrace.Trace
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 9 more (state=08000,code=101)
可以看到提示缺少org.apache.htrace.Trace类,因此我们需要将htrace-core-3.2.0-incubating.jar拷贝到HBase的lib下:
# CDH环境下已经有这个包了,这里直接将其拷贝到HBase的lib下(每个RegionServer)
# 如果没有可以直接下载这包到HBase的lib下: wget https://repo1.maven.org/maven2/org/apache/htrace/htrace-core/3.2.0-incubating/htrace-core-3.2.0-incubating.jar
cp /opt/cloudera/cm/lib/cdh5/htrace-core-3.2.0-incubating.jar /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hbase/lib/
注意: 如果依旧提示缺少这个包,则需要重启HBase服务
再次进入
[root@cdh3 phoenix-5.0.0-HBase-2.0]# bin/sqlline.py cdh2
Setting property: [incremental, false]
Setting property: [isolation, TRANSACTION_READ_COMMITTED]
issuing: !connect jdbc:phoenix:cdh2 none none org.apache.phoenix.jdbc.PhoenixDriver
Connecting to jdbc:phoenix:cdh2
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/phoenix-5.0.0-HBase-2.0/phoenix-5.0.0-HBase-2.0-client.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
Connected to: Phoenix (version 5.0)
Driver: PhoenixEmbeddedDriver (version 5.0)
Autocommit status: true
Transaction isolation: TRANSACTION_READ_COMMITTED
Building list of tables and columns for tab-completion (set fastconnect to true to skip)...
133/133 (100%) Done
Done
sqlline version 1.2.0
0: jdbc:phoenix:cdh2> !tables
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+--------------+-----------------+---------------+---------------+-----------------+------------+-------------+----------------+-------------+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | INDEX_STATE | IMMUTABLE_ROWS | SALT_BUCKETS | MULTI_TENANT | VIEW_STATEMENT | VIEW_TYPE | INDEX_TYPE | TRANSACTIONAL | IS_NAMESPAC |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+--------------+-----------------+---------------+---------------+-----------------+------------+-------------+----------------+-------------+
| | SYSTEM | CATALOG | SYSTEM TABLE | | | | | | false | null | false | | | | false | false |
| | SYSTEM | FUNCTION | SYSTEM TABLE | | | | | | false | null | false | | | | false | false |
| | SYSTEM | LOG | SYSTEM TABLE | | | | | | true | 32 | false | | | | false | false |
| | SYSTEM | SEQUENCE | SYSTEM TABLE | | | | | | false | null | false | | | | false | false |
| | SYSTEM | STATS | SYSTEM TABLE | | | | | | false | null | false | | | | false | false |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+--------------+-----------------+---------------+---------------+-----------------+------------+-------------+----------------+-------------+
2.2 原有HBase表的映射同步
Phoenix对表和列名都是区分大小写的,如果不加双引号默认为大写。通过上面可以看到HBase原有的表并没有列出来,这是因为 Phoenix 无法自动识别 HBase 中原有的表,所以需要将 HBase 中已有的做映射,才能够被 Phoenix 识别并操作。
-- 其实也就是使用CREATE语句重新创建表来映射
-- 注意1:建表时一定注意大小写,如果原表小写,记得用双引号,主键最好大写
-- 注意2:建表时不推荐使用太复杂的数据类型,为了安全的映射放置出错,先使用varchar,
-- 否则会出现精度或者格式上的误差,例如时间日期类,整数型长度,小数型精度等
-- 注意3:记得加上 COLUMN_ENCODED_BYTES 否则可能类名解析无法对应到HBase的类,
-- 详细说明查看 http://phoenix.apache.org/columnencoding.html
-- 注意4:如果是创建的表来映射,在Phoenix删除表,HBase的表和数据也会删除,注意数据不要误删了
--
-- 推荐:我这里映射的是表,如果只用来做查询,最好创建一个视图来来映射:只需要将 TABLE 改为 VIEW
0: jdbc:phoenix:cdh2:2181> CREATE TABLE "m_info" (
. . . . . . . . . . . . .> "ROW" varchar primary key,
. . . . . . . . . . . . .> "cf1"."gc" double ,
. . . . . . . . . . . . .> "cf1"."id" bigint ,
. . . . . . . . . . . . .> "cf1"."jd" double ,
. . . . . . . . . . . . .> "cf1"."name" varchar ,
. . . . . . . . . . . . .> "cf1"."wd" double
. . . . . . . . . . . . .> )column_encoded_bytes=0;
1 row affected (7.282 seconds)
-- 查询数据
0: jdbc:phoenix:cdh2> select * from "m_info" ;
+------+-----------------------+-----------------------+-----------------------+-------+-------------------------+
| ROW | gc | id | jd | name | wd |
+------+-----------------------+-----------------------+-----------------------+-------+-------------------------+
| 2 | 1.1 | 2 | 3.33 | 名字1 | 5.1234 |
+------+-----------------------+-----------------------+-----------------------+-------+-------------------------+
2.3 查看表信息和插入数据
-- 查看表结构
0: jdbc:phoenix:cdh2:2181> !describe "m_info";
+------------+--------------+-------------+--------------+------------+------------+--------------+----------------+-----------------+-----------------+-----------+----------+-------------+----------------+-------------------+--------------------+-------------------+---+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | COLUMN_NAME | DATA_TYPE | TYPE_NAME | COLUMN_SIZE | BUFFER_LENGTH | DECIMAL_DIGITS | NUM_PREC_RADIX | NULLABLE | REMARKS | COLUMN_DEF | SQL_DATA_TYPE | SQL_DATETIME_SUB | CHAR_OCTET_LENGTH | ORDINAL_POSITION | I |
+------------+--------------+-------------+--------------+------------+------------+--------------+----------------+-----------------+-----------------+-----------+----------+-------------+----------------+-------------------+--------------------+-------------------+---+
| | | m_info | ROW | 12 | VARCHAR | null | null | null | null | 0 | | | null | null | null | 1 | f |
| | | m_info | gc | 8 | DOUBLE | null | null | null | null | 1 | | | null | null | null | 2 | t |
| | | m_info | id | -5 | BIGINT | null | null | null | null | 1 | | | null | null | null | 3 | t |
| | | m_info | jd | 8 | DOUBLE | null | null | null | null | 1 | | | null | null | null | 4 | t |
| | | m_info | name | 12 | VARCHAR | null | null | null | null | 1 | | | null | null | null | 5 | t |
| | | m_info | wd | 8 | DOUBLE | null | null | null | null | 1 | | | null | null | null | 6 | t |
+------------+--------------+-------------+--------------+------------+------------+--------------+----------------+-----------------+-----------------+-----------+----------+-------------+----------------+-------------------+--------------------+-------------------+---+
-- 插入数据。这里注意的是value中的值如果是字符串,必须用单引号
0: jdbc:phoenix:cdh2:2181> UPSERT INTO "m_info"("ROW", "gc", "id", "jd", "name", "wd") VALUES('2', 1.1, 2, 3.33, '名字1', 5.1234);
1 row affected (1.074 seconds)
2.4 数据类型
Data Types
| 字段类型 | 映射的类 | 值的范围 | 占用字节 |
|---|---|---|---|
| INTEGER | java.lang.Integer |
-2147483648 到 2147483647 | 4字节 |
| UNSIGNED_INT | java.lang.Integer |
0 到 2147483647 | 4字节 |
| BIGINT | java.lang.Long |
-9223372036854775808 到 9223372036854775807 | 8字节 |
| UNSIGNED_LONG | java.lang.Long |
0 到 9223372036854775807 | 8字节 |
| TINYINT | java.lang.Byte |
-128 到 127 | 1字节 |
| UNSIGNED_TINYINT | java.lang.Byte |
0 到 127 | 1字节 |
| SMALLINT | java.lang.Short |
-32768 到 32767 | 2字节 |
| UNSIGNED_SMALLINT | java.lang.Short |
0 到 32767 | 2字节 |
| FLOAT | java.lang.Float |
-3.402823466 E + 38 到 3.402823466 E + 38 | 4字节 |
| UNSIGNED_FLOAT | java.lang.Float |
0到3.402823466 E + 38 | 4字节 |
| DOUBLE | java.lang.Double |
-1.7976931348623158 E + 308 到 1.7976931348623158 E + 308 | 8字节 |
| UNSIGNED_DOUBLE | java.lang.Double |
0 到 1.7976931348623158 E + 308 | 8字节 |
| DECIMAL 或 DECIMAL(precisionInt , scaleInt) | java.math.BigDecimal |
最大精度为38位。可变长度 | |
| BOOLEAN | java.lang.Boolean |
0表示false,1表示true | 1字节 |
| TIME | java.sql.Time |
自纪元以来的毫秒数(基于时间GMT) | 8字节 |
| UNSIGNED_TIME | java.sql.Time |
格式为 yyyy-MM-dd hh:mm:ss | 8字节 |
| DATE | java.sql.Date |
自纪元以来的毫秒数(基于时间GMT) | 8字节 |
| UNSIGNED_DATE | java.sql.Date |
格式为 yyyy-MM-dd hh:mm:ss | 8字节 |
| TIMESTAMP | java.sql.Timestamp |
自纪元以来的毫秒数(基于时间GMT) | 12字节(纪元时间长8字节加纳秒的4字节整数) |
| UNSIGNED_TIMESTAMP | java.sql.Timestamp |
格式为 yyyy-MM-dd hh:mm:ss[.nnnnnnnnn] | 12字节 |
| VARCHAR 或 VARCHAR(precisionInt) | java.lang.String |
可选的最大字节长度 | |
| CHAR(precisionInt) | java.lang.String |
固定长度字符串 | |
| BINARY(precisionInt) | byte[] |
原始固定长度字节数组 | |
| VARBINARY | byte[] |
原始可变长度字节数组 | |
| ARRAY 或 ARRAY[dimensionInt] | java.sql.Array |
2.5 修改表信息
首先Phoenix对字段的映射的元数据信息如下,下面修改字段类型时可以由此进行修改
| DATA_TYPE | TYPE_NAME |
|---|---|
| INTEGER | 4 |
| UNSIGNED_INT | 4 |
| BIGINT | -5 |
| UNSIGNED_LONG | -5 |
| TINYINT | -6 |
| UNSIGNED_TINYINT | -6 |
| SMALLINT | 5 |
| UNSIGNED_SMALLINT | 5 |
| FLOAT | 6 |
| UNSIGNED_FLOAT | 6 |
| DOUBLE | 8 |
| UNSIGNED_DOUBLE | 8 |
| DECIMAL | 3 |
| BOOLEAN | 16 |
| TIME | 92 |
| UNSIGNED_TIME | 92 |
| DATE | 91 |
| UNSIGNED_DATE | 91 |
| TIMESTAMP | 93 |
| UNSIGNED_TIMESTAMP | 93 |
| VARCHAR | 12 |
| CHAR | 1 |
| BINARY | -2 |
| VARBINARY | -3 |
0: jdbc:phoenix:cdh2> CREATE TABLE "test" (
. . . . . . . . . . > "ROW" varchar primary key,
. . . . . . . . . . > "info1"."age" UNSIGNED_TINYINT ,
. . . . . . . . . . > "info1"."name" varchar ,
. . . . . . . . . . > "info1"."property" double
. . . . . . . . . . > )column_encoded_bytes=0;
3 rows affected (8.962 seconds)
-- 查看表中的字段信息
0: jdbc:phoenix:cdh2> select TENANT_ID,TABLE_SCHEM,TABLE_NAME,COLUMN_NAME,COLUMN_FAMILY,DATA_TYPE,COLUMN_SIZE,DECIMAL_DIGITS from SYSTEM.CATALOG where TABLE_NAME='test';
+------------+--------------+-------------+--------------+----------------+------------+--------------+-----------------+
| TENANT_ID | TABLE_SCHEM | TABLE_NAME | COLUMN_NAME | COLUMN_FAMILY | DATA_TYPE | COLUMN_SIZE | DECIMAL_DIGITS |
+------------+--------------+-------------+--------------+----------------+------------+--------------+-----------------+
| | | test | | | null | null | null |
| | | test | ROW | | 12 | null | null |
| | | test | age | info1 | -6 | null | null |
| | | test | name | info1 | 12 | null | null |
| | | test | property | info1 | 8 | null | null |
+------------+--------------+-------------+--------------+----------------+------------+--------------+-----------------+
5 rows selected (0.064 seconds)
-- 将name的varchar类型的长度调整为 32,前4个字段为主键
5 rows selected (0.064 seconds)
0: jdbc:phoenix:cdh2> upsert into SYSTEM.CATALOG (TENANT_ID,TABLE_SCHEM,TABLE_NAME,COLUMN_NAME,COLUMN_FAMILY,COLUMN_SIZE) values('','','test','name','info1',32);
1 row affected (0.493 seconds)
0: jdbc:phoenix:cdh2> upsert into SYSTEM.CATALOG (TENANT_ID,TABLE_SCHEM,TABLE_NAME,COLUMN_NAME,COLUMN_FAMILY,DATA_TYPE) values('','','test','age','info1',-5);
1 row affected (0.019 seconds)
0: jdbc:phoenix:cdh2> select TENANT_ID,TABLE_SCHEM,TABLE_NAME,COLUMN_NAME,COLUMN_FAMILY,DATA_TYPE,COLUMN_SIZE,DECIMAL_DIGITS from SYSTEM.CATALOG where TABLE_NAME='test';
+------------+--------------+-------------+--------------+----------------+------------+--------------+-----------------+
| TENANT_ID | TABLE_SCHEM | TABLE_NAME | COLUMN_NAME | COLUMN_FAMILY | DATA_TYPE | COLUMN_SIZE | DECIMAL_DIGITS |
+------------+--------------+-------------+--------------+----------------+------------+--------------+-----------------+
| | | test | | | null | null | null |
| | | test | ROW | | 12 | null | null |
| | | test | age | info1 | -5 | null | null |
| | | test | name | info1 | 12 | 32 | null |
| | | test | property | info1 | 8 | null | null |
+------------+--------------+-------------+--------------+----------------+------------+--------------+-----------------+
5 rows selected (0.039 seconds)
2.6 删除库
-- 如果HBase的数据和Phoenix的数据是同步的,则可以直接删除SCHEM
0: jdbc:phoenix:cdh3> DROP SCHEMA IF EXISTS my_schema;
-- 如果不能删除,可以先删除HBase的表信息
hbase(main):003:0> disable "test.Person"
Took 0.5061 seconds
hbase(main):004:0> drop "test.Person"
Took 0.2915 seconds
-- 再清除Phoenix的数据
-- 查看CATALOG信息
0: jdbc:phoenix:cdh3> select TENANT_ID,TABLE_SCHEM,TABLE_NAME,COLUMN_NAME,COLUMN_FAMILY,TABLE_SEQ_NUM,TABLE_TYPE,PK_NAME from SYSTEM.CATALOG;
-- 删除里面的表信息
| TENANT_ID | TABLE_SCHEM | TABLE_NAME | COLUMN_NAME | COLUMN_FAMILY | TABLE_SEQ_NUM | TABLE_TYPE | PK_NAME |
+------------+--------------+-------------+-------------------------------------+----------------+----------------+-------------+----------+
| | …… | …… | …… | | null | | |
| | test | Person | | | 0 | u | |
| | test | Person | | 0 | null | | |
| | test | Person | age | 0 | null | | |
| | test | Person | idcard_num | | null | | |
| | test | Person | name | 0 | null | | |
+------------+--------------+-------------+------------------------+----------------+----------------+-------------+----------+
-- 删除SCHEM信息
0: jdbc:phoenix:cdh3> DELETE FROM SYSTEM.CATALOG WHERE TABLE_SCHEM='test';
5 rows affected (0.352 seconds)
-- 再次使用 !tables 查看表,发现库以及表均已经成功删除
2.7 执行SQL脚本
我们使用Phoenix自带的样例数据演示,数据在 $PHOENIX_HOME/examples,具体执行如下:
-- 1 查看数据和脚本,其中 $PHOENIX_HOME 是Phoenix安装的目录。
-- 可以看到有STOCK_SYMBOL数据文件和sql脚本、WEB_STAT数据文件和脚本文件
[root@cdh3 ~]# ls $PHOENIX_HOME/examples
pig STOCK_SYMBOL.csv STOCK_SYMBOL.sql WEB_STAT.csv WEB_STAT_QUERIES.sql WEB_STAT.sql
-- 1.1 查看 STOCK_SYMBOL.sql。可以看到有三个SQL,分别为建表SQL、更新插入一条数据SQL、查询表数据SQL
[root@cdh3 ~]# cat $PHOENIX_HOME/examples/STOCK_SYMBOL.sql
CREATE TABLE IF NOT EXISTS STOCK_SYMBOL (SYMBOL VARCHAR NOT NULL PRIMARY KEY, COMPANY VARCHAR);
UPSERT INTO STOCK_SYMBOL VALUES ('CRM','SalesForce.com');
SELECT * FROM STOCK_SYMBOL;
-- 1.2 查看 WEB_STAT.sql。可以看到这里是一个建表SQL
[root@cdh3 ~]# cat $PHOENIX_HOME/examples/WEB_STAT.sql
CREATE TABLE IF NOT EXISTS WEB_STAT (
HOST CHAR(2) NOT NULL,
DOMAIN VARCHAR NOT NULL,
FEATURE VARCHAR NOT NULL,
DATE DATE NOT NULL,
USAGE.CORE BIGINT,
USAGE.DB BIGINT,
STATS.ACTIVE_VISITOR INTEGER
CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE, DATE)
);
-- 1.3 查看 WEB_STAT_QUERIES.sql。可以看到有三个查询 SQL
[root@cdh3 ~]# cat $PHOENIX_HOME/examples/WEB_STAT_QUERIES.sql
SELECT DOMAIN, AVG(CORE) Average_CPU_Usage, AVG(DB) Average_DB_Usage
FROM WEB_STAT
GROUP BY DOMAIN
ORDER BY DOMAIN DESC;
-- Sum, Min and Max CPU usage by Salesforce grouped by day
SELECT TRUNC(DATE,'DAY') DAY, SUM(CORE) TOTAL_CPU_Usage, MIN(CORE) MIN_CPU_Usage, MAX(CORE) MAX_CPU_Usage
FROM WEB_STAT
WHERE DOMAIN LIKE 'Salesforce%'
GROUP BY TRUNC(DATE,'DAY');
-- list host and total active users when core CPU usage is 10X greater than DB usage
SELECT HOST, SUM(ACTIVE_VISITOR) TOTAL_ACTIVE_VISITORS
FROM WEB_STAT
WHERE DB > (CORE * 10)
GROUP BY HOST;
-- 2 执行自带脚本
[root@cdh3 ~]# $PHOENIX_HOME/bin/sqlline.py localhost $PHOENIX_HOME/examples/STOCK_SYMBOL.sql
148/148 (100%) Done
Done
1/4 CREATE TABLE IF NOT EXISTS STOCK_SYMBOL (SYMBOL VARCHAR NOT NULL PRIMARY KEY, COMPANY VARCHAR);
No rows affected (2.349 seconds)
2/4 UPSERT INTO STOCK_SYMBOL VALUES ('CRM','SalesForce.com');
1 row affected (0.162 seconds)
3/4 SELECT * FROM STOCK_SYMBOL;
+---------+-----------------+
| SYMBOL | COMPANY |
+---------+-----------------+
| CRM | SalesForce.com |
+---------+-----------------+
1 row selected (0.038 seconds)
4/4
Closing: org.apache.phoenix.jdbc.PhoenixConnection
sqlline version 1.2.0
-- 也可以指定csv数据文件和执行sql脚本
[root@cdh3 ~]# psql.py localhost $PHOENIX_HOME/examples/WEB_STAT.sql $PHOENIX_HOME/examples/WEB_STAT.csv $PHOENIX_HOME/examples/WEB_STAT_QUERIES.sql
no rows upserted
Time: 2.709 sec(s)
csv columns from database.
CSV Upsert complete. 39 rows upserted
Time: 19.653 sec(s)
DOMAIN AVERAGE_CPU_USAGE AVERAGE_DB_USAGE
----------------------------- ------------------------------- --------------------------
Salesforce.com 260.727 257.636
Google.com 212.875 213.75
Apple.com 114.111 119.556
Time: 0.127 sec(s)
DAY TOTAL_CPU_USAGE MIN_CPU_USAGE MAX_CPU_USAGE
----------------------- -------------------- -------------------------- ----------------------------
2013-01-01 00:00:00.000 35 35 35
2013-01-02 00:00:00.000 150 25 125
2013-01-03 00:00:00.000 88 88 88
2013-01-04 00:00:00.000 26 3 23
2013-01-05 00:00:00.000 550 75 475
2013-01-06 00:00:00.000 12 12 12
2013-01-08 00:00:00.000 345 345 345
2013-01-09 00:00:00.000 390 35 355
2013-01-10 00:00:00.000 345 345 345
2013-01-11 00:00:00.000 335 335 335
2013-01-12 00:00:00.000 5 5 5
2013-01-13 00:00:00.000 355 355 355
2013-01-14 00:00:00.000 5 5 5
2013-01-15 00:00:00.000 720 65 655
2013-01-16 00:00:00.000 785 785 785
2013-01-17 00:00:00.000 1590 355 1235
Time: 0.045 sec(s)
HO TOTAL_ACTIVE_VISITORS
-- ----------------------------------------
EU 150
NA 1
Time: 0.022 sec(s)
-- 3 登陆 Phoenix。也可以使用Squirrel工具
[root@cdh3 ~]# $PHOENIX_HOME/bin/sqlline.py localhost
2.8 DDL语法
数据库定义语言DDL(Data Definition Language)是我们在创建表的时候用到的一些SQL,比如说:CREATE、ALTER、DROP等。DDL主要是用在定义或改变表的结构,数据类型,表之间的链接和约束等初始化工作上。
-- 1 建表,建表的语句可以看 执行SQL脚本 中的如下两个文件的建表语句
-- 基本上和一般的SQL建表差不多,支持主键,支持 NOT NULL约束,这里又不同的是,建表时可以在字段前加上列族名以区分字段信息
$PHOENIX_HOME/examples/STOCK_SYMBOL.sql
$PHOENIX_HOME/examples/WEB_STAT.sql
-- 2 ALTER一个表,例如在STOCK_SYMBOL添加一列 name
0: jdbc:phoenix:localhost> ALTER TABLE STOCK_SYMBOL ADD "name" varchar(64);
No rows affected (0.749 seconds)
-- 再次查看表数据,发现有多了一列name
0: jdbc:phoenix:localhost> SELECT * FROM STOCK_SYMBOL;
+---------+-----------------+-------+
| SYMBOL | COMPANY | name |
+---------+-----------------+-------+
| CRM | SalesForce.com | |
+---------+-----------------+-------+
3 rows selected (0.15 seconds)
-- 3 ALTER一个表,删除一列,例如将上一步在STOCK_SYMBOL表添加的name一列删除
0: jdbc:phoenix:localhost> ALTER TABLE STOCK_SYMBOL DROP COLUMN "name";
No rows affected (0.605 seconds)
-- 再次查看表数据,发现name这一列已经删除
0: jdbc:phoenix:localhost> SELECT * FROM STOCK_SYMBOL;
+---------+-----------------+
| SYMBOL | COMPANY |
+---------+-----------------+
| CRM | SalesForce.com |
+---------+-----------------+
3 rows selected (0.095 seconds)
-- 如果demo2 表是一个视图,也可以将视图中的某个列字段删去,语法如下
0: jdbc:phoenix:localhost> ALTER VIEW "demo2" DROP COLUMN "comm";
-- 4 删除库
-- 4.1 如果HBase的数据和Phoenix的数据是同步的,则可以直接删除SCHEM
0: jdbc:phoenix:cdh3> DROP SCHEMA IF EXISTS my_schema;
-- 4.2 如果不能删除,可以先删除HBase的表信息
hbase(main):003:0> disable "test.Person"
Took 0.5061 seconds
hbase(main):004:0> drop "test.Person"
Took 0.2915 seconds
-- 再清除Phoenix的数据
-- 4.3 删除SCHEM信息
0: jdbc:phoenix:cdh3> DELETE FROM SYSTEM.CATALOG WHERE TABLE_SCHEM='test';
5 rows affected (0.352 seconds)
-- 再次使用 !tables 查看表,发现库以及表均已经成功删除
2.8.1 加盐表
在密码学中,加盐是指在散列之前将散列内容(例如:密码)的任意固定位置插入特定的字符串。这个在散列中加入字符串的方式称为“加盐”。其作用是让加盐后的散列结果和没有加盐的结果不相同,在不同的应用情景中,这个处理可以增加额外的安全性。而Phoenix中加盐是指对pk对应的byte数组插入特定的byte数据。
加盐能解决HBASE读写热点问题,例如:单调递增rowkey数据的持续写入,使得负载集中在某一个RegionServer上引起的热点问题。在创建表的时候指定属性值:SALT_BUCKETS,其值表示所分buckets(region)数量, 范围是1~256。
-- 加盐表的创建格式如下
CREATE TABLE mytable (my_key VARCHAR PRIMARY KEY, col VARCHAR) SALT_BUCKETS = 8;
2.8.2 自增ID
现在有一个需求是这样的,有一批书籍,需要对其进行编号存储,要求编号要唯一,建表语句如下:
0: jdbc:phoenix:localhost> CREATE TABLE books(
. . . . . . . . . . . . .> id INTEGER NOT NULL PRIMARY KEY,
. . . . . . . . . . . . .> name VARCHAR,
. . . . . . . . . . . . .> author VARCHAR
. . . . . . . . . . . . .> )SALT_BUCKETS = 8;
No rows affected (3.250 seconds)
我们接下来需要使用自增ID,来生成上表的id,但是使用这样的自增ID,容易造成集群的热点问题,因此这里在建表时通过加盐的方式解决这个潜在的问题。下面是Phoenix中自增ID的语法,如下:
-- 自增ID的语法如下:
-- START 用于指定第一个值。如果不指定默认为1.
-- INCREMENT指定每次调用NEXT VALUE FOR后自增大小。 如果不指定默认为1。
-- MINVALUE和MAXVALUE一般与CYCLE连用, 让自增数据形成一个环,从最小值到最大值,再从最大值到最小值。
-- CACHE默认为100, 表示server端生成100个自增序列缓存在客户端,可以减少rpc次数。
-- 此值也可以通过phoenix.sequence.cacheSize来配置。
CREATE SEQUENCE [IF NOT EXISTS] SCHEMA.SEQUENCE_NAME
[START WITH number]
[INCREMENT BY number]
[MINVALUE number]
[MAXVALUE number]
[CYCLE]
[CACHE number]
现在我们使用这个语法创建自增序列,我们定初始值为10000,自增间隔为1,缓存大小为1000,实现如下:
-- 1 创建自增序列
0: jdbc:phoenix:localhost> CREATE SEQUENCE book_sequence START WITH 10000 INCREMENT BY 1 CACHE 1000;
No rows affected (0.174 seconds)
-- 2 通过自增序列,写入数据信息。这里插入两条数据,通过NEXT VALUE FOR 调用自增序列
0: jdbc:phoenix:localhost> UPSERT INTO books(id, name, author) VALUES( NEXT VALUE FOR
. . . . . . . . . . . . .> book_sequence,'Effective JavaScript', 'David Herman');
1 row affected (0.085 seconds)
-- 插入第二条数据
0: jdbc:phoenix:localhost> UPSERT INTO books(id, name, author) VALUES( NEXT VALUE FOR
. . . . . . . . . . . . .> book_sequence,'Speaking Javascript','Dr.Axel Rauschmayer');
1 row affected (0.014 seconds)
-- 3 查看书籍信息表。books没有加引号时默认为大写。发现数据已成功插入,且其ID为从10000以1位步长自增
0: jdbc:phoenix:localhost> SELECT * FROM BOOKS;
+--------+-----------------------+----------------------+
| ID | NAME | AUTHOR |
+--------+-----------------------+----------------------+
| 10001 | Speaking Javascript | Dr.Axel Rauschmayer |
| 10000 | Effective JavaScript | David Herman |
+--------+-----------------------+----------------------+
2 rows selected (0.245 seconds)
2.9 DML和DQL语法
数据操纵语言DML(Data Manipulation Language)主要对表中的数据进行插入、删除、修改的操作,在Phoenix对应的操作就是UPSERT和DELETE。数据查询语言DQL(Data Query Language)主要用于数据的查询,在Phoenix对应的操作就是SELETE。
-- 1 SELECT 。查询 STOCK_SYMBOL 表数据,取其3条
0: jdbc:phoenix:localhost> SELECT * FROM WEB_STAT LIMIT 3;
+-------+-------------+------------+--------------------------+-------+------+-----------------+
| HOST | DOMAIN | FEATURE | DATE | CORE | DB | ACTIVE_VISITOR |
+-------+-------------+------------+--------------------------+-------+------+-----------------+
| EU | Apple.com | Mac | 2013-01-01 01:01:01.000 | 35 | 22 | 34 |
| EU | Apple.com | Store | 2013-01-03 01:01:01.000 | 345 | 722 | 170 |
| EU | Google.com | Analytics | 2013-01-13 08:06:01.000 | 25 | 2 | 6 |
+-------+-------------+------------+--------------------------+-------+------+-----------------+
3 rows selected (0.132 seconds)
-- 2 UPSERT。这个是需要注意的,因为HBase本身的架构特点,没有update语法,Phoenix的插入和修改统一为 UPSERT 关键字。
-- 2.1 插入一条数据,不指定字段,直接填写插入的值,建表时有多少字段就要一一对应,不能漏
0: jdbc:phoenix:localhost> UPSERT INTO STOCK_SYMBOL VALUES('AAPL', 'APPLE Inc.');
1 row affected (0.355 seconds)
-- 2.2 插入一条数据,可以只指定我们需要插入数据的字段,其它没有约束时使用默认值
0: jdbc:phoenix:localhost> UPSERT INTO STOCK_SYMBOL(SYMBOL, COMPANY) VALUES('GOOG', 'Google');
1 row affected (0.009 seconds)
-- 2.3 更新一条数据。结合主键使用UPSERT实现。
-- 例如更新 WEB_STAT ,从建表语句可以看到其主键为 HOST、DOMAIN、FEATURE、DATE,
-- 将HOST='EU', DOMAIN='Apple.com', FEATURE='Mac', DATE='2013-01-01 01:01:01.000'的 ACTIVE_VISITOR改为33
0: jdbc:phoenix:localhost> UPSERT INTO WEB_STAT(HOST, DOMAIN, FEATURE, DATE, ACTIVE_VISITOR) VALUES('EU', 'Apple.com', 'Mac', '2013-01-01 01:01:01.000', 33);
1 row affected (0.191 seconds)
-- 查看结果。发现第一行数据的 ACTIVE_VISITOR 已经更新为33了
0: jdbc:phoenix:localhost> SELECT * FROM WEB_STAT LIMIT 3;
+-------+-------------+------------+--------------------------+-------+------+-----------------+
| HOST | DOMAIN | FEATURE | DATE | CORE | DB | ACTIVE_VISITOR |
+-------+-------------+------------+--------------------------+-------+------+-----------------+
| EU | Apple.com | Mac | 2013-01-01 01:01:01.000 | 35 | 22 | 33 |
| EU | Apple.com | Store | 2013-01-03 01:01:01.000 | 345 | 722 | 170 |
| EU | Google.com | Analytics | 2013-01-13 08:06:01.000 | 25 | 2 | 6 |
+-------+-------------+------------+--------------------------+-------+------+-----------------+
3 rows selected (0.059 seconds)
-- 3统计不同域名(DOMAIN)下访客数(ACTIVE_VISITOR)大于100的数据量
0: jdbc:phoenix:localhost> SELECT DOMAIN,COUNT(1) FROM WEB_STAT
. . . . . . . . . . . . .> WHERE ACTIVE_VISITOR>100 GROUP BY DOMAIN;
+-----------------+-----------+
| DOMAIN | COUNT(1) |
+-----------------+-----------+
| Apple.com | 3 |
| Google.com | 1 |
| Salesforce.com | 4 |
+-----------------+-----------+
3 rows selected (0.041 seconds)
-- 4 CASE,将常见的域名转成中文,其它则返回原始内容
0: jdbc:phoenix:localhost> SELECT (CASE DOMAIN WHEN 'Apple.com' THEN '苹果公司'
. . . . . . . . . . . . .> WHEN 'Google.com' THEN '谷歌'
. . . . . . . . . . . . .> ELSE DOMAIN END ) AS "域名" FROM WEB_STAT GROUP BY DOMAIN;
+-----------------+
| 域名 |
+-----------------+
| 苹果公司 |
| 谷歌 |
| Salesforce.com |
+-----------------+
3 rows selected (0.084 seconds)
-- 5 分页查询。结合order by ,排序字段最好为主键。LIMIT语法如下
-- [ LIMIT { count } ]
-- [ OFFSET start [ ROW | ROWS ] ]
-- [ FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } ONLY ]
-- 例如接下来,我们对WEB_STAT表的数据按照活跃的访客数(ACTIVE_VISITOR)倒序进行分页,
-- 每页显示20条数据,从起始的第一条数据开始显示。
-- LIMIT限制每页显示20条数据, OFFSET 为第一次数据的起始偏移量
0: jdbc:phoenix:localhost> SELECT * FROM WEB_STAT ORDER BY ACTIVE_VISITOR DESC
. . . . . . . . . . . . .> LIMIT 20 OFFSET 0;
+-------+-----------------+------------+--------------------------+-------+-------+-----------------+
| HOST | DOMAIN | FEATURE | DATE | CORE | DB | ACTIVE_VISITOR |
+-------+-----------------+------------+--------------------------+-------+-------+-----------------+
| NA | Salesforce.com | Reports | 2013-01-09 17:36:01.000 | 355 | 432 | 315 |
| NA | Salesforce.com | Login | 2013-01-17 02:20:01.000 | 1235 | 2422 | 243 |
| EU | Google.com | Search | 2013-01-09 01:01:01.000 | 395 | 922 | 190 |
| EU | Apple.com | Store | 2013-01-03 01:01:01.000 | 345 | 722 | 170 |
| NA | Apple.com | Mac | 2013-01-02 04:01:01.000 | 345 | 255 | 155 |
| NA | Salesforce.com | Login | 2013-01-10 01:01:01.000 | 345 | 252 | 150 |
| EU | Salesforce.com | Login | 2013-01-12 01:01:01.000 | 5 | 62 | 150 |
| NA | Apple.com | Login | 2013-01-04 01:01:01.000 | 135 | 2 | 110 |
| NA | Google.com | Search | 2013-01-10 01:05:01.000 | 835 | 282 | 80 |
| NA | Salesforce.com | Login | 2013-01-16 01:01:01.000 | 785 | 782 | 80 |
| NA | Google.com | Analytics | 2013-01-07 06:01:01.000 | 23 | 1 | 57 |
| NA | Google.com | Analytics | 2013-01-14 01:01:01.000 | 65 | 252 | 56 |
| EU | Salesforce.com | Reports | 2013-01-05 04:14:12.000 | 475 | 252 | 53 |
| NA | Google.com | Search | 2013-01-08 08:01:01.000 | 345 | 242 | 46 |
| NA | Salesforce.com | Reports | 2013-01-15 07:09:01.000 | 655 | 426 | 46 |
| NA | Salesforce.com | Login | 2013-01-04 11:01:11.000 | 23 | 56 | 45 |
| NA | Salesforce.com | Dashboard | 2013-01-03 11:01:01.000 | 88 | 66 | 44 |
| EU | Salesforce.com | Dashboard | 2013-01-06 05:04:05.000 | 12 | 22 | 43 |
| EU | Salesforce.com | Reports | 2013-01-02 14:32:01.000 | 125 | 131 | 42 |
| NA | Apple.com | Login | 2013-01-01 01:01:01.000 | 35 | 22 | 40 |
+-------+-----------------+------------+--------------------------+-------+-------+-----------------+
20 rows selected (0.24 seconds)
-- 第二页,LIMIT限制每页显示20条数据, OFFSET 指定为20表示第二页的数据的起始偏移量
0: jdbc:phoenix:localhost> SELECT * FROM WEB_STAT ORDER BY ACTIVE_VISITOR DESC
. . . . . . . . . . . . .> LIMIT 20 OFFSET 20;
+-------+-----------------+------------+--------------------------+-------+------+-----------------+
| HOST | DOMAIN | FEATURE | DATE | CORE | DB | ACTIVE_VISITOR |
+-------+-----------------+------------+--------------------------+-------+------+-----------------+
| EU | Apple.com | Mac | 2013-01-01 01:01:01.000 | 35 | 22 | 34 |
| NA | Salesforce.com | Login | 2013-01-17 01:01:01.000 | 355 | 242 | 33 |
| NA | Salesforce.com | Dashboard | 2013-01-11 01:01:01.000 | 335 | 32 | 30 |
| NA | Apple.com | iPad | 2013-01-05 01:01:01.000 | 85 | 2 | 18 |
| NA | Salesforce.com | Reports | 2013-01-09 16:33:01.000 | 35 | 42 | 15 |
| NA | Apple.com | iPad | 2013-01-06 01:01:01.000 | 35 | 22 | 10 |
| NA | Salesforce.com | Login | 2013-01-08 14:11:01.000 | 345 | 242 | 10 |
| NA | Salesforce.com | Login | 2013-01-01 01:01:01.000 | 35 | 42 | 10 |
| NA | Apple.com | Mac | 2013-01-08 01:01:01.000 | 3 | 2 | 10 |
| NA | Salesforce.com | Dashboard | 2013-01-14 04:07:01.000 | 5 | 2 | 9 |
| NA | Apple.com | iPad | 2013-01-07 01:01:01.000 | 9 | 27 | 7 |
| NA | Google.com | Analytics | 2013-01-11 01:02:01.000 | 7 | 2 | 7 |
| NA | Salesforce.com | Reports | 2013-01-15 04:09:01.000 | 65 | 26 | 6 |
| NA | Google.com | Search | 2013-01-12 01:01:01.000 | 8 | 7 | 6 |
| EU | Google.com | Analytics | 2013-01-13 08:06:01.000 | 25 | 2 | 6 |
| EU | Salesforce.com | Reports | 2013-01-13 08:04:04.000 | 355 | 52 | 5 |
| EU | Salesforce.com | Reports | 2013-01-05 03:11:12.000 | 75 | 22 | 3 |
| EU | Salesforce.com | Reports | 2013-01-02 12:02:01.000 | 25 | 11 | 2 |
| NA | Salesforce.com | Login | 2013-01-04 06:01:21.000 | 3 | 52 | 1 |
+-------+-----------------+------------+--------------------------+-------+------+-----------------+
19 rows selected (0.18 seconds)
-- 6 删除数据。删除时可以添加条件,也可以模糊匹配删除
-- 为了模拟,我们先添加两条数据
0: jdbc:phoenix:localhost> UPSERT INTO STOCK_SYMBOL VALUES('WAG', 'Walgreens');
1 row affected (0.116 seconds)
0: jdbc:phoenix:localhost> UPSERT INTO STOCK_SYMBOL VALUES('WMT', 'Walmart');
1 row affected (0.008 seconds)
-- 6.1 删除 SYMBOL='CRM'的一条数据
0: jdbc:phoenix:localhost> DELETE FROM STOCK_SYMBOL WHERE SYMBOL='CRM';
1 row affected (0.089 seconds)
-- 发现已成功删除
0: jdbc:phoenix:localhost> SELECT * FROM STOCK_SYMBOL;
+---------+-------------+
| SYMBOL | COMPANY |
+---------+-------------+
| AAPL | APPLE Inc. |
| GOOG | Google |
| WAG | Walgreens |
| WMT | Walmart |
+---------+-------------+
4 rows selected (0.022 seconds)
-- 6.2 删除 COMPANY 为Wal开头的所有数据
0: jdbc:phoenix:localhost> DELETE FROM STOCK_SYMBOL WHERE COMPANY LIKE 'Wal%';
2 rows affected (0.034 seconds)
-- 发现有两条满足条件的数据已被删除
0: jdbc:phoenix:localhost> SELECT * FROM STOCK_SYMBOL;
+---------+-------------+
| SYMBOL | COMPANY |
+---------+-------------+
| AAPL | APPLE Inc. |
| GOOG | Google |
+---------+-------------+
2 rows selected (0.017 seconds)
-- 6.3 删除demo表,如果demo表不是视图并,对一个的HBase的表和数据也会被删除。
0: jdbc:phoenix:cdh3> DELETE TABLE "demo";
2.9.1 Join
Phoenix本身提供了Join功能,但比较适用于大表join 小表之类的简单join,如果要做大表join大表的复杂分析可以借助Spark来做。
官方文档介绍中Phoenix支持Join类型如右图所示有两种,一种是内连接:INNER JOIN,一种是外连接:OUTER JOIN,其中OUTER JOIN支持LEFT和RIGHT两种方式。但同时其还支持UNION ALL语法,可以合并来自多个SELECT语句的行数据。

关于这几种连接文氏图(Venn diagram)如下所示,INNER JOIN 一般被译作内连接,内连接查询能将左表(表 A)和右表(表 B)中能关联起来的数据连接后返回;LEFT JOIN 一般被译作左连接,也写作 LEFT OUTER JOIN ,左连接查询会返回左表(表 A)中所有记录,不管右表(表 B)中有没有关联的数据,在右表中找到的关联数据列也会被一起返回;RIGHT JOIN 一般被译作右连接,也写作 RIGHT OUTER JOIN ,右连接查询会返回右表(表 B)中所有记录,不管左表(表 A)中有没有关联的数据,在左表中找到的关联数据列也会被一起返回。FULL OUTER JOIN 一般被译作外连接、全连接,实际查询语句中可以写作 FULL OUTER JOIN 或 FULL JOIN ,外连接查询能返回左右表里的所有记录,其中左右表里能关联起来的记录被连接后返回。

现在有两张表,一个是网站数据表websites,主要记录了网站主键id、名称、连接、网站流量排名、国家等信息。另一张表为访问日志表access_log,主要记录的有每个网站每日的访问数量,两个表通过id来关联,即websites.id=access_log.site_id ,现在我们通过Phoenix来分别演示INNER JOIN、LEFT [OUTER] JOIN、RIGHT [OUTER] JOIN、FULL [OUTER] JOIN(Phoenix虽然不支持,但可以通过UNION ALL 来实现),对两个表进行关联,并根据访问数量降序排,输出标识id、名称、数量、日期。
-- 1 建表
-- 1.1 Websites 表
0: jdbc:phoenix:> CREATE TABLE IF NOT EXISTS TEST."websites" (
. . . . . . . . > "id" UNSIGNED_LONG NOT NULL PRIMARY KEY,
. . . . . . . . > "name" varchar(255) ,
. . . . . . . . > "url" varchar(255) ,
. . . . . . . . > "alexa" UNSIGNED_INT, /*'网站流量排名'*/
. . . . . . . . > "country" varchar(32)
. . . . . . . . > );
No rows affected (0.954 seconds)
-- 1.2 access_log 表
0: jdbc:phoenix:> CREATE TABLE IF NOT EXISTS TEST."access_log" (
. . . . . . . . > "aid" UNSIGNED_LONG NOT NULL,
. . . . . . . . > "site_id" UNSIGNED_LONG NOT NULL,
. . . . . . . . > "count" UNSIGNED_INT,
. . . . . . . . > "access_date" DATE ,
. . . . . . . . > CONSTRAINT PK PRIMARY KEY ("aid", "site_id")
. . . . . . . . > );
No rows affected (0.393 seconds)
-- 1.3 查看创建的表。可以看到本次创建了SCHEM为TEST的两张表access_log、websites
0: jdbc:phoenix:> !tables
+------------+--------------+-------------+---------------+----------+------------+----------------------+-----------------+--------------+-----------------+-------------
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | INDEX_STATE | IMMUTABLE_ROWS | SALT_BUCKETS | MULTI_TENANT | VIEW_STATEMENT | VIEW_TYPE | INDEX_TYPE | TRANSACTIONAL | IS_NAMESPAC |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+--------------+-----------------+--------
| | SYSTEM | CATALOG | SYSTEM TABLE | | | | | | false | null |
| | SYSTEM | FUNCTION | SYSTEM TABLE | | | | | | false | null |
| | SYSTEM | LOG | SYSTEM TABLE | | | | | | true | 32 |
| | SYSTEM | SEQUENCE | SYSTEM TABLE | | | | | | false | null |
| | SYSTEM | STATS | SYSTEM TABLE | | | | | | false | null |
| | | BOOKS | TABLE | | | | | | false | 8 |
| | | STOCK_SYMBOL | TABLE | | | | | | false | null |
| | | WEB_STAT | TABLE | | | | | | false | null |
| | | demo | TABLE | | | | | | false | null |
| | TEST | access_log | TABLE | | | | | | false | null |
| | TEST | websites | TABLE | | | | | | false | null |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+--------------+-----------------+--------
-- 2 插入数据。注意:字符串一定用 单引号
-- 2.1 插入 websites 表测试数据
0: jdbc:phoenix:> UPSERT INTO TEST."websites" VALUES(1, 'Google', 'https://www.google.cm/', 1, 'USA');
1 row affected (0.212 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."websites" VALUES(2, '淘宝', 'https://www.taobao.com/', 4689, 'CN');
1 row affected (0.036 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."websites" VALUES(3, '豆瓣', 'https://www.douban.com/', 325, 'CN');
1 row affected (0.02 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."websites" VALUES(4, '微博', 'http://weibo.com/', 20, 'CN');
1 row affected (0.039 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."websites" VALUES(5, 'Facebook', 'https://www.facebook.com/', 3, 'USA');
1 row affected (0.027 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."websites" VALUES(7, 'stackoverflow', 'http://stackoverflow.com/', 0, 'IND');
1 row affected (0.016 seconds)
-- 2.2 插入 access_log 表测试数据
0: jdbc:phoenix:> UPSERT INTO TEST."access_log" VALUES(1, 1, 45, '2016-05-10');
1 row affected (0.049 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."access_log" VALUES(2, 3, 100, '2016-05-13');
1 row affected (0.064 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."access_log" VALUES(3, 1, 230, '2016-05-14');
1 row affected (0.054 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."access_log" VALUES(4, 2, 10, '2016-05-14');
1 row affected (0.017 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."access_log" VALUES(5, 5, 205, '2016-05-14');
1 row affected (0.021 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."access_log" VALUES(6, 4, 13, '2016-05-15');
1 row affected (0.018 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."access_log" VALUES(7, 3, 220, '2016-05-15');
1 row affected (0.038 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."access_log" VALUES(8, 5, 545, '2016-05-16');
1 row affected (0.03 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."access_log" VALUES(9, 3, 201, '2016-05-17');
1 row affected (0.019 seconds)
0: jdbc:phoenix:> UPSERT INTO TEST."access_log" VALUES(10, 6, 419, '2018-11-21');
1 row affected (0.02 seconds)
-- 3 查看表中的数据
-- 3.1 查看 websites 表数据
0: jdbc:phoenix:> SELECT * FROM TEST."websites";
+-----+----------------+----------------------------+--------+----------+
| id | name | url | alexa | country |
+-----+----------------+----------------------------+--------+----------+
| 1 | Google | https://www.google.cm/ | 1 | USA |
| 2 | 淘宝 | https://www.taobao.com/ | 4689 | CN |
| 3 | 豆瓣 | https://www.douban.com/ | 325 | CN |
| 4 | 微博 | http://weibo.com/ | 20 | CN |
| 5 | Facebook | https://www.facebook.com/ | 3 | USA |
| 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND |
+-----+----------------+----------------------------+--------+----------+
6 rows selected (0.139 seconds)
-- 3.2 查看 access_log 表数据
0: jdbc:phoenix:> SELECT * FROM TEST."access_log";
+------+----------+--------+--------------------------+
| aid | site_id | count | access_date |
+------+----------+--------+--------------------------+
| 1 | 1 | 45 | 2016-05-10 00:00:00.000 |
| 2 | 3 | 100 | 2016-05-13 00:00:00.000 |
| 3 | 1 | 230 | 2016-05-14 00:00:00.000 |
| 4 | 2 | 10 | 2016-05-14 00:00:00.000 |
| 5 | 5 | 205 | 2016-05-14 00:00:00.000 |
| 6 | 4 | 13 | 2016-05-15 00:00:00.000 |
| 7 | 3 | 220 | 2016-05-15 00:00:00.000 |
| 8 | 5 | 545 | 2016-05-16 00:00:00.000 |
| 9 | 3 | 201 | 2016-05-17 00:00:00.000 |
| 10 | 6 | 419 | 2018-11-21 00:00:00.000 |
+------+----------+--------+--------------------------+
10 rows selected (0.123 seconds)
-- 4 INNER JOIN
-- 可以看到 inner join 返回的是满足条件的A表和B表都都存在的数据
0: jdbc:phoenix:> SELECT A."name",B."count",B."access_date"
. . . . . . . . > FROM TEST."websites" AS A
. . . . . . . . > INNER JOIN TEST."access_log" AS B
. . . . . . . . > ON A."id"=B."site_id"
. . . . . . . . > ORDER BY B."count" DESC;
+-----------+----------+--------------------------+
| A.name | B.count | B.access_date |
+-----------+----------+--------------------------+
| Facebook | 545 | 2016-05-16 00:00:00.000 |
| Google | 230 | 2016-05-14 00:00:00.000 |
| 豆瓣 | 220 | 2016-05-15 00:00:00.000 |
| Facebook | 205 | 2016-05-14 00:00:00.000 |
| 豆瓣 | 201 | 2016-05-17 00:00:00.000 |
| 豆瓣 | 100 | 2016-05-13 00:00:00.000 |
| Google | 45 | 2016-05-10 00:00:00.000 |
| 微博 | 13 | 2016-05-15 00:00:00.000 |
| 淘宝 | 10 | 2016-05-14 00:00:00.000 |
+-----------+----------+--------------------------+
9 rows selected (0.276 seconds)
-- 5 LEFT JOIN
-- 可以看到 A.name=stackoverflow 在A表存在,但是B表不存在,依然返回作为结果。
-- 而 B.count=419 的数据A表没有匹配到,因此就没有返回。 总之以左表A为准
-- 注意:这里和MySQL不一样的地方是,null值排在最前面(无论是排序是 ASC 还是 DESC)
0: jdbc:phoenix:> SELECT A."name",B."count",B."access_date"
. . . . . . . . > FROM TEST."websites" AS A
. . . . . . . . > LEFT JOIN TEST."access_log" AS B
. . . . . . . . > ON A."id"=B."site_id"
. . . . . . . . > ORDER BY B."count" DESC;
+----------------+----------+--------------------------+
| A.name | B.count | B.access_date |
+----------------+----------+--------------------------+
| stackoverflow | null | |
| Facebook | 545 | 2016-05-16 00:00:00.000 |
| Google | 230 | 2016-05-14 00:00:00.000 |
| 豆瓣 | 220 | 2016-05-15 00:00:00.000 |
| Facebook | 205 | 2016-05-14 00:00:00.000 |
| 豆瓣 | 201 | 2016-05-17 00:00:00.000 |
| 豆瓣 | 100 | 2016-05-13 00:00:00.000 |
| Google | 45 | 2016-05-10 00:00:00.000 |
| 微博 | 13 | 2016-05-15 00:00:00.000 |
| 淘宝 | 10 | 2016-05-14 00:00:00.000 |
+----------------+----------+--------------------------+
10 rows selected (0.169 seconds)
-- 6 RIGHT JOIN
-- 可以看到 B.count=419 在B表存在,但是A表不存在,依然返回作为结果。
-- 而 A.name=stackoverflow 的数据B表没有匹配到,因此就没有返回。 总之以右表B为准
0: jdbc:phoenix:> SELECT A."name",B."count",B."access_date"
. . . . . . . . > FROM TEST."websites" AS A
. . . . . . . . > RIGHT JOIN TEST."access_log" AS B
. . . . . . . . > ON A."id"=B."site_id"
. . . . . . . . > ORDER BY B."count" DESC;
+-----------+----------+--------------------------+
| A.name | B.count | B.access_date |
+-----------+----------+--------------------------+
| Facebook | 545 | 2016-05-16 00:00:00.000 |
| | 419 | 2018-11-21 00:00:00.000 |
| Google | 230 | 2016-05-14 00:00:00.000 |
| 豆瓣 | 220 | 2016-05-15 00:00:00.000 |
| Facebook | 205 | 2016-05-14 00:00:00.000 |
| 豆瓣 | 201 | 2016-05-17 00:00:00.000 |
| 豆瓣 | 100 | 2016-05-13 00:00:00.000 |
| Google | 45 | 2016-05-10 00:00:00.000 |
| 微博 | 13 | 2016-05-15 00:00:00.000 |
| 淘宝 | 10 | 2016-05-14 00:00:00.000 |
+-----------+----------+--------------------------+
10 rows selected (0.205 seconds)
-- 7 UNION ALL。Phoenix不支持 FULL OUTER JOIN ,但可以通过 UNION ALL 实现
-- FULL OUTER JOIN 等价于 (LEFT OUTER JOIN) UNION ALL (RIGHT OUTER JOIN )
-- 可以看到返回左表和右表都有的所有数据.
-- 注意:目前还不支持 UNION ALL 的左右 SELECT 语句中有 ORDER BY ,否则SQL解析时会报如下错误
-- ERROR 602 (42P00): Syntax error. Missing "EOF" at line 5, column 1.
-- 如果要实现排序,可以用子查询或者视图来实现
0: jdbc:phoenix:> SELECT A."name",B."count",B."access_date"
. . . . . . . . > FROM TEST."websites" AS A
. . . . . . . . > LEFT JOIN TEST."access_log" AS B
. . . . . . . . > ON A."id"=B."site_id"
. . . . . . . . > UNION ALL
. . . . . . . . > SELECT A."name",B."count",B."access_date"
. . . . . . . . > FROM TEST."websites" AS A
. . . . . . . . > RIGHT JOIN TEST."access_log" AS B
. . . . . . . . > ON A."id"=B."site_id";
+----------------+--------+--------------------------+
| NAME | COUNT | ACCESS_DATE |
+----------------+--------+--------------------------+
| Google | 45 | 2016-05-10 00:00:00.000 |
| Google | 230 | 2016-05-14 00:00:00.000 |
| 淘宝 | 10 | 2016-05-14 00:00:00.000 |
| 豆瓣 | 100 | 2016-05-13 00:00:00.000 |
| 豆瓣 | 220 | 2016-05-15 00:00:00.000 |
| 豆瓣 | 201 | 2016-05-17 00:00:00.000 |
| 微博 | 13 | 2016-05-15 00:00:00.000 |
| Facebook | 205 | 2016-05-14 00:00:00.000 |
| Facebook | 545 | 2016-05-16 00:00:00.000 |
| stackoverflow | null | |
| Google | 45 | 2016-05-10 00:00:00.000 |
| 豆瓣 | 100 | 2016-05-13 00:00:00.000 |
| Google | 230 | 2016-05-14 00:00:00.000 |
| 淘宝 | 10 | 2016-05-14 00:00:00.000 |
| Facebook | 205 | 2016-05-14 00:00:00.000 |
| 微博 | 13 | 2016-05-15 00:00:00.000 |
| 豆瓣 | 220 | 2016-05-15 00:00:00.000 |
| Facebook | 545 | 2016-05-16 00:00:00.000 |
| 豆瓣 | 201 | 2016-05-17 00:00:00.000 |
| | 419 | 2018-11-21 00:00:00.000 |
+----------------+--------+--------------------------+
20 rows selected (0.258 seconds)
-- 7.1 子查询方式实现 UNION ALL 排序
0: jdbc:phoenix:> SELECT * FROM (
. . . . . . . . > SELECT A."name",B."count",B."access_date"
. . . . . . . . > FROM TEST."websites" AS A
. . . . . . . . > LEFT JOIN TEST."access_log" AS B
. . . . . . . . > ON A."id"=B."site_id"
. . . . . . . . > UNION ALL
. . . . . . . . > SELECT A."name",B."count",B."access_date"
. . . . . . . . > FROM TEST."websites" AS A
. . . . . . . . > RIGHT JOIN TEST."access_log" AS B
. . . . . . . . > ON A."id"=B."site_id"
. . . . . . . . > ) ORDER BY COUNT DESC;
+----------------+--------+--------------------------+
| NAME | COUNT | ACCESS_DATE |
+----------------+--------+--------------------------+
| stackoverflow | null | |
| Facebook | 545 | 2016-05-16 00:00:00.000 |
| Facebook | 545 | 2016-05-16 00:00:00.000 |
| | 419 | 2018-11-21 00:00:00.000 |
| Google | 230 | 2016-05-14 00:00:00.000 |
| Google | 230 | 2016-05-14 00:00:00.000 |
| 豆瓣 | 220 | 2016-05-15 00:00:00.000 |
| 豆瓣 | 220 | 2016-05-15 00:00:00.000 |
| Facebook | 205 | 2016-05-14 00:00:00.000 |
| Facebook | 205 | 2016-05-14 00:00:00.000 |
| 豆瓣 | 201 | 2016-05-17 00:00:00.000 |
| 豆瓣 | 201 | 2016-05-17 00:00:00.000 |
| 豆瓣 | 100 | 2016-05-13 00:00:00.000 |
| 豆瓣 | 100 | 2016-05-13 00:00:00.000 |
| Google | 45 | 2016-05-10 00:00:00.000 |
| Google | 45 | 2016-05-10 00:00:00.000 |
| 微博 | 13 | 2016-05-15 00:00:00.000 |
| 微博 | 13 | 2016-05-15 00:00:00.000 |
| 淘宝 | 10 | 2016-05-14 00:00:00.000 |
| 淘宝 | 10 | 2016-05-14 00:00:00.000 |
+----------------+--------+--------------------------+
20 rows selected (0.291 seconds)
-- 7.2 视图方式实现 UNION ALL 排序
-- 如果删除视图,语法格式为:DROP VIEW IF EXISTS my_schema.my_view
-- 注意1:目前视图中还不能包含 AS 关键字
-- 注意2:目前子句中不能选择字段,只能用*号,否则包如下错误:
-- ERROR 604 (42P00): Syntax error. Mismatched input. Expecting "ASTERISK", got "TEST" at line 2, column 8.
-- Debug:目前版本存在问题。当前视图支持的语法比较有限,SELECT中不能有复杂的语法,否则解析时会无法判断结束标记。可以反馈社区等后期修复
-- CREATE VIEW IF EXISTS TEST."websites_union_access_log" AS
-- SELECT * FROM TEST."websites" LEFT JOIN TEST."access_log"
-- ON TEST."websites"."id"=TEST."access_log"."site_id"
-- UNION ALL
-- SELECT * FROM TEST."websites"
-- RIGHT JOIN TEST."access_log"
-- ON TEST."websites"."id"=TEST."access_log"."site_id";
-- SELECT AB."name",AB."count",AB."access_date" FROM TEST."websites_union_access_log"
-- AS AB ORDER BY AB."count" DESC;
2.10 JDBC
使用JDBC方式连接Phoenix,对数据进行处理
2.10.1 新建一个Maven工程
在IDEA中新建一个Maven项目
2.10.2 pom.xml
<dependencies>
<dependency>
<groupId>org.apache.phoenixgroupId>
<artifactId>phoenix-coreartifactId>
<version>5.0.0-HBase-2.0version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>3.0.0version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
dependencies>
2.10.3 JDBC Client代码
PhoenixJdbcClient
3 工具
以下两款常用的工具都支持Win和Mac OS
3.1 DBeaver
在创建Phoenix连接,编辑驱动设那里点击 添加文件(F) ,选中前面我们编译出来的phoenix-5.0.0-HBase-2.0-client.jar包即可。

3.2 SQuirrel SQL
3.2.1 下载
进入这个页面下载 http://squirrel-sql.sourceforge.net/,这里可以下载压缩包版的 Plain zips the latest release for Windows/Linux/MacOS X/others。有三个版本,选在一个版本下载即可,例如这里下载squirrelsql-3.9.1-optional.zip
3.2.2 解压和配置
解压到安装目录,然后将phoenix-5.0.0-HBase-2.0-client.jar和phoenix-core-5.0.0-HBase-2.0.jar下载或者软连接到解压的包中的lib目录中。
Su-yuexi:squirrelsql-3.9.1-optional yoreyuan$ cd lib
Su-yuexi:lib yoreyuan$ ln -s ~/.dbeaver-drivers/phoenix-5.0.0-HBase-2.0-client.jar phoenix-5.0.0-HBase-2.0-client.jar
Su-yuexi:lib yoreyuan$ ln -s ~/soft/maven/repository/org/apache/phoenix/phoenix-core/5.0.0-HBase-2.0/phoenix-core-5.0.0-HBase-2.0.jar phoenix-core-5.0.0-HBase-2.0.jar
Su-yuexi:lib yoreyuan$ cd ../
Su-yuexi:squirrelsql-3.9.1-optional yoreyuan$ chmod +x squirrel-sql-mac.sh
3.2.3 启动
执行启动脚本,此时会弹出SQuirrel SQL Client Help和SQuirrel SQL Client窗口。如果安装或其它操作也可以查看帮助文档。
./squirrel-sql-mac.sh
3.2.4 配置 Phoenix 驱动
- 添加Driver。点击
Driver - Driver Name: 填写一个名字
- Example URL:
jdbc:phoenix:cdh2,cdh3:2181 - 在
Java Class Path选在我们前面添加的lib/phoenix-core-5.0.0-HBase-2.0.jar - 点击
List Drivers,等一会会自动在Class Name:补上org.apache.phoenix.jdbc.PhoenixDriver - OK
- 配置成功后会在左侧的
Drivers区域添加上去我们刚配置的Phoenix连接。
3.2.5 连接Phoenix
- 点击
Aliases中的➕ - Name: 连接的别名
- Driver: 选择上一步配置好的驱动。URL会自动填入。
- Test。User Name 和 Password 可以不用填写。
- OK
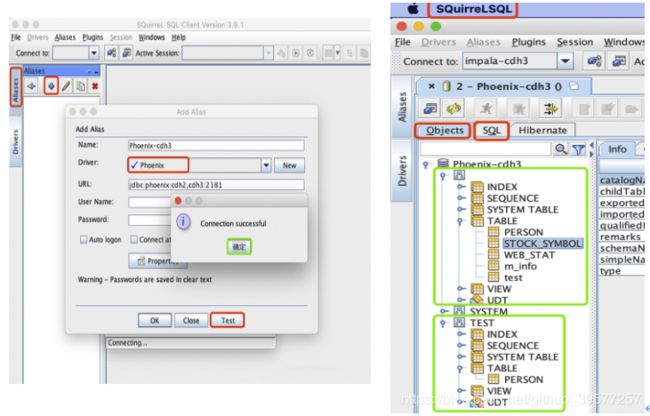
3.2.6 查询
执行SQL查询数据,如上图右,这里需要注意的如果我们建表时没有指定Schema,则创建的表都会在一个空的Schema下(DBeaver工具目前的版本无法显示空Schema下的表,但是可以正产查询),点击点击SQL,就可以编写SQL,进行数据的查询等操作,例如查询表空schema的表数据:SELECT * FROM WEB_stat;,如果有schema在表前面加上用英文点号分割,例如查询test下的person表:SELECT * FROM test.person;。

4 资料
这里推荐一份 云栖社区的一份资料,可以参考
Phoenix资料