汇编原理自我总结(一)
汇编原理自我总结(一)
文章目录
- 汇编原理自我总结(一)
- 第一章 基础知识
- 1.1 机器语言
- 1.2 汇编语言的产生
- 1.3 汇编语言的组成
- 1.4 存储器
- 1.5 指令和数据
- 1.6 存储单元
- 1.7 CPU对存储器的读写
- 1.8 地址总线
- 1.9 地址总线
- 1.10 控制总线
- 1.11 内存地址空间
- 1.12 主板
- 1.13 接口卡
- 1.14 各类存储器芯片
- 1.15 地址内存空间
- 第二章 寄存器
- 2.1 通用寄存器
- 2.2 字在寄存器中的存储
- 2.3 几条汇编指令
- 2.4 物理地址
- 2.5 16位结构的CPU
- 2.6 8086CPU给出物理地址的方法
- 2.7 本质含义
- 2.8 段的概念
- 2.9 段寄存器
- 2.10 CS和IP(指令指针寄存器)
- 2.11 修改CS和IP
- 2.12 代码段
- 实验一
- 第三章 寄存器(内存访问)
- 3.1 内存中字的存储
- 3.2 DS和[ADDRESS]
- 3.3 字的传送
- 3.4 mov add sub
- 3.5 数据段
- 3.6 栈
- 3.7 CPU提供的栈机制
- 3.8 栈顶超界的问题
- 3.9 posh 和 pop
- 3.10 栈段
- 实验二
- 第四章
- 4.1 从写出到执行
- 4.2源程序
- 4.3 编辑源程序
- 4.4 编译
- 4.5 链接
- 4.6 简化编译,链接
- 4.7 运行.exe
- 4.8 将可执行文件载入内存并使它运行
- 4.9 执行文件跟踪
- 实验三
- 第五章 [BX] 和loop指令
- 5.1 [bx]
- 5.2 loop指令
- 5.3 另一程序
- 5.4 debug 与编译器的一点不同
- 5.5 loop和[bx]的联合应用
- 5.6 段前缀
- 5.7 一段安全的内存空间
- 5.8 段前缀的使用
- 实验四
- 第六章 包含多个段的程序
- 6.1 在代码段中使用数据
- 6.2 在程序中使用栈
- 6.3 将数据、代码、栈放入不同的段
- 实验五
- 第七章 更灵活的定位内存地址的方法
- 7.1 and 和 or
- 7.2 ASCII码
- 7.4 以字符形式给出的数据
- 7.5 大小写转换问题
- 7.6 [bx+idata]
- 7.7 改进上述转换大小写的代码
- 7.8 si 和 di
- 7.9 [bx+si] [bx+di]
- 7.10 [bx+si+idata] [bx+di+idata]
- 7.11 不同寻址方式的灵活运用
- 实验六
- 第八章 数据处理的两个基础问题
- 8.1 bx bp si di
- 8.2 机器指令处理的数据在哪里
- 8.3 汇编语言中数据位置的表达
- 8.4 寻址方式
- 8.5 指令要处理的数据有多长
- 8.6 寻址方式的综合应用
- 8.7 div除法指令
- 8.7 伪指令dd
- 8.8 dup
- 实验七
第一章 基础知识
1.1 机器语言
1.2 汇编语言的产生
1.3 汇编语言的组成
3类指令:
- 汇编指令
- 伪指令
- 其它符号,由编译器识别。
1.4 存储器
存储计算机的数据和指令,要运行计算就必须将数据和指令在内存中存储。
1.5 指令和数据
二者只有应用上的区别。本质上并无区别,都是计算机内存中的二进制信息。
1.6 存储单元
存储器被划分为多个存储单元,并进行编号。不同的机器存储单元的大小不同。微型机存储器的存储单元为一个字节(Byte),即8个bit。
1.7 CPU对存储器的读写
要进行的信息交互:
- 存储单元的地址(地址信息)
- 器件的选择,读或写的命令(控制信息)
- 读或写的数据(数据信息)
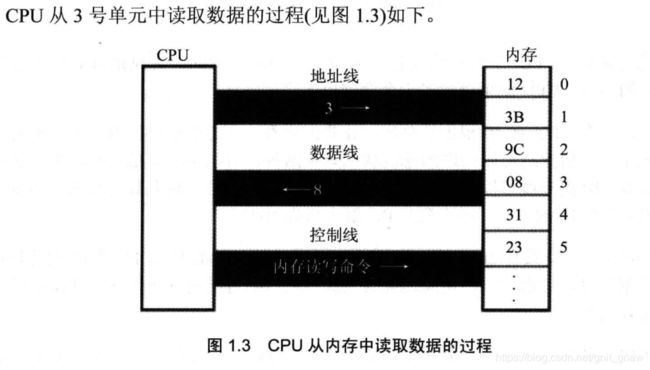
- CPU通过地址线将地址信息3发出;
- CPU通过控制线发出内存读命令,选中存储器芯片,通知它,将要从它那里读取数据;
- 存储器将3号单元的数据8通过数据线送到CPU;
1.8 地址总线
寻址能力:CPU的地址总线宽度为N,则它最多能寻到2的N次方个内存单元。

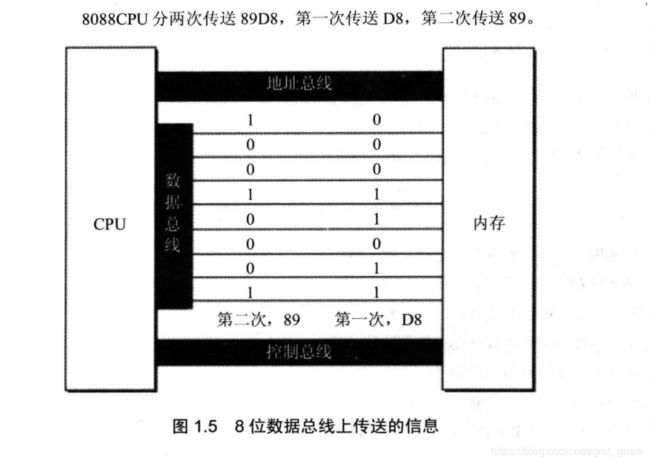
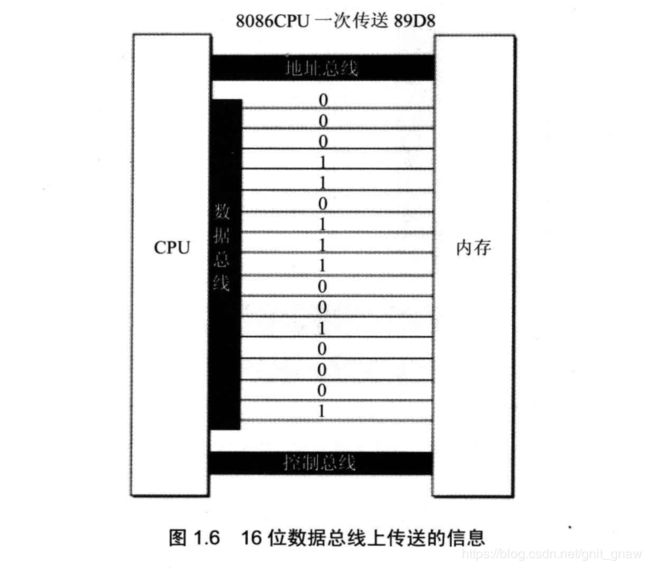
1.9 地址总线
地址总线的宽度决定了CPU和外界数据的传输速度。8根数据总线一次可以传输1个字节,而16根则可以一次传输2个字节。
1.10 控制总线
有多少根控制总线就意味着CPU对外部器件有多少种控制。


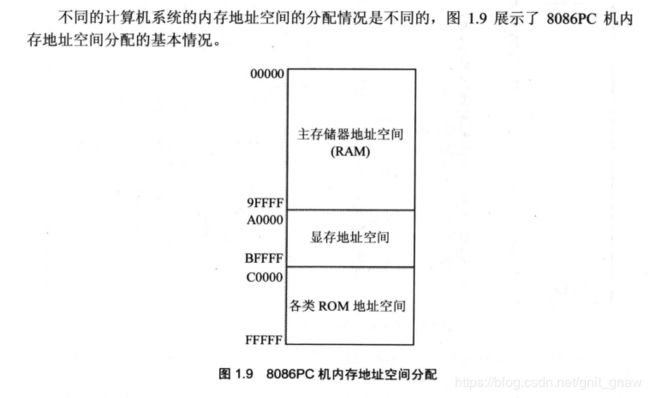
1.11 内存地址空间
寻址能力可寻到的地址单元的总和。
1.12 主板
主板上有核心器件和主要器件,一般由总线连接。CPU、存储器、外围芯片组、扩展插槽等。扩展插槽上一般由RAM内存条和各类接口卡。
1.13 接口卡
所有可用程序控制其工作的设备,必须受到CPU的控制。CPU对外部设备不能直接控制,由CPU直接控制接口卡,发送命令到接口卡,接口卡直接控制外设。从而大到CPU间接控制外设。
1.14 各类存储器芯片
从物理连接上看,这些存储器芯片是各自独立的,但是从读写属性上看,它们可以分为两类:
- RAM
- ROM
从功能和连接上又可有以下分类:
- 随机存储器;
- BIOS(Basic Input/Output System)(就是硬件上的软件系统,存储在ROM);
- 接口卡上的RAM;(显卡:将要显示的内容数据写入显存。)

1.15 地址内存空间
上述存储器物理上是独立的,但是以下有两点相同:
- 都和CPU的总线相连
- 对它们进行读或写的时候,都通过控制总线发出内存读写命令。
即将它们当成一个总的逻辑上是由若干存储单元组成的地址内存空间。

第二章 寄存器
一个典型的CPU由运算器、寄存器、控制器等器件组成,由内部总线连接。运算器进行信息处理,控制器控制各种器件工作,寄存器存储信息。内部总线连接各种器件,在它们之间进行数据的传送。
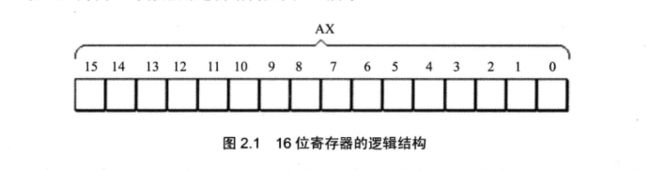
2.1 通用寄存器
以8086CPU为例,其寄存器是16位的。通用寄存器有:AX、BX、CX、DX。这些寄存器由于要兼容以前的8位寄存器下写的程序,可以拆分位两个寄存器:高位和低位。如:AH、AL、BH、BL这些。
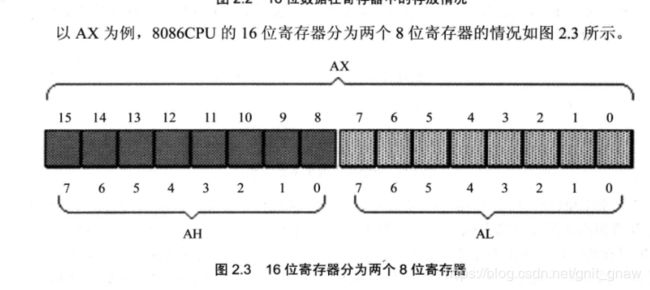
2.2 字在寄存器中的存储
1Byte = 8Bit
1Word = 2Byte(8086CPU)
2.3 几条汇编指令
mov ax, 2000
add bx, 4E20H
汇编指令和寄存器名称不区分大小写。另外应注意操作寄存器的一致性。例如:
mov ax, bx
mov ah, al
mov ah, bl
;“Right”
mov ax,bh
mov ah,bx
;“Wrong”
拆分后的寄存器独立于其它寄存器,并不会将进位存储在高位寄存器中。
“最多使用4条指令,计算2的4次方”
mov al, 2;
add al, al;
add al, al;
add al, al;
2.4 物理地址
内存单元唯一的地址标识。
2.5 16位结构的CPU
意义:
- 运算器最多可以一次处理16位数据;
- 寄存器的最大宽度是16位;
- 寄存器和运算器之间的通路是16位;
2.6 8086CPU给出物理地址的方法
由于CPU的地址总线是20根,故寻址能力可达1M。用两个寄存器来标识物理地址(段地址,偏移地址)。物理地址 = 段地址 x 16 +偏移地址;
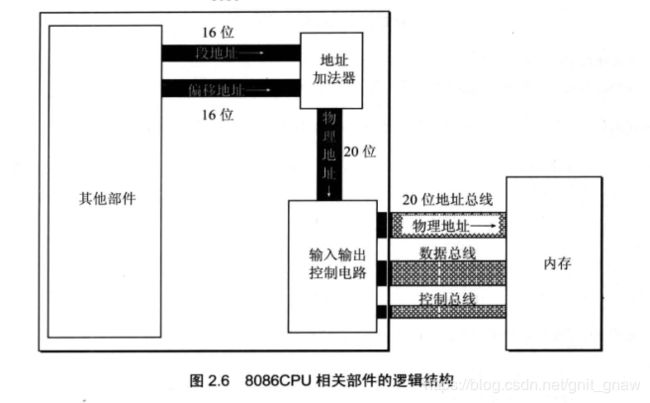
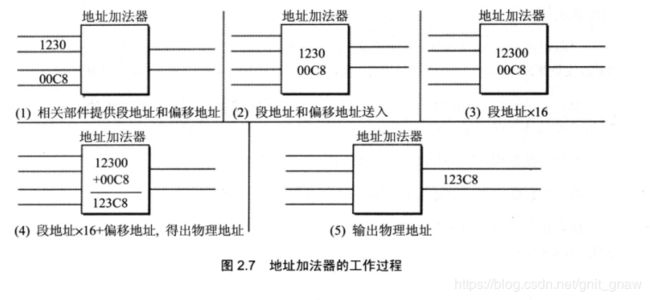
2.7 本质含义
将段地址 x 16当作基础地址,则在此基础地址上加上偏移地址就是物理地址。
2.8 段的概念
不要以为内存真的分了段,这只是CPU管理内存的一种方法。任何连续的内存可以按照需求来分段。CPU管理内存,而你可以控制CPU。说到底,是人在管理内存地址。由于偏移地址最大为16位,所以一个段最大为64KB。另外,基础地址是16的倍数,所以基础地址的起始位置必是16的倍数。
8086CPU物理地址表示:2140F = 2000:140F
2.9 段寄存器
4个段寄存器:CS(code segment)、DS(data segment)、SS(stack segment)、ES;
2.10 CS和IP(指令指针寄存器)
- 从CS:IP的指向的内存单元读取指令,读取的指令进入指令缓冲器。
- IP = IP + 已读取指令的长度。
- 执行指令。返回1。
2.11 修改CS和IP
转移指令(jmp);
jmp 2AE3,3
;“执行指令后,将读取2AE33处的指令”
jmp ax
;“仅修改IP,用ax中的值作为IP的值,逻辑上相当于 mov IP, ax;”
2.12 代码段
将代码放在某一地址单元,人为认定该部分是代码段。要使的CPU认定,需将指令指针指向第一条指令的首地址。
实验一
debug 的使用
-
R 查看、改变寄存器的内容
-
D 查看内存中的内容
-
E 改写内存的内容
-
U 将内存中的机器指令翻译成汇编指令
-
T 执行一条机器指令
-
A 以汇编指令的格式在内存中写入一条机器指令
(debug的命令有20多个,以上为常用的)
第三章 寄存器(内存访问)
3.1 内存中字的存储
一个字为16位,存储在两个连续的内存单元中,高位存储在高地址单元,低位就相应的在低地址单元,叫做一个字单元。如数据2000(4E20H),存储在地址单元100处,则字单元为地址100,大小是两个内存单元。100处为20H(低位),102处为4EH(高位)。
3.2 DS和[ADDRESS]
首先,明确一点:CPU不支持将数据直接送进段寄存器。传送指令mov可以将数据直接送进通用寄存器,也可以将寄存器的数据送进寄存器。如何实现将内存单元的数据送进寄存器呢?就需要段寄存器DS。以下指令:
mov ax,1000H
mov ds,ax
mov bl, [0]
;将内存单元1000:0000处的数据送进bx的低位寄存器bl
;不能直接将1000H送进ds
ds中存储段地址,[address]则是偏移地址。
3.3 字的传送
mov ax,1000H
mov ds,ax
mov bx,[0]
;1000:0000中高8位存在bh,低8位在al中
3.4 mov add sub
已知的指令形式:
mov 寄存器 ,数据;
mov 寄存器,寄存器;
mov 寄存器,内存单元;
mov 内存单元,寄存器;
mov 段寄存器,寄存器;
- 既然有寄存器到段寄存器的通路,则段寄存器到寄存器也可行。事实正是如此。(mov 寄存器,段寄存器)
- 类似地,mov 内存单元,段寄存器可行
- mov 段寄存器,内存单元;
add, sub 与mov 的形式相同,不过诸如add 段寄存器 数据/寄存器,add 寄存器 段寄存器不能存在。
3.5 数据段
可以在编程时根据需要将一段开始地址编号为16的倍数的地址放在段寄存器中,这样就能使用偏移地址访问数据了。该段寄存器的功能就是如此。但是必须要记得数据段的长度,不能越界访问不是自己安排的内存,否则可能导致程序崩溃(Segment Default);
3.6 栈
具有特殊访问方式(LIFO,Last In First Out)的存储空间。
从程序化的角度来说,得有一个指针始终指向出栈的数据。
3.7 CPU提供的栈机制
push ax(将ax中的字数据压栈),pop ax(将栈中字数据放到ax中)。记住,栈出栈与入栈的对象是以字为单位的。如同CS:IP一样,CPU要知道将那段地址作为栈段,必须有地址,要知道栈顶,就得有偏移地址;在这里,SS段寄存器里存放栈顶段地址,SP存放栈顶偏移地址。任意时刻,SS:SP指向栈顶元素。
3.8 栈顶超界的问题
sp指向不属于栈段的内存空间,再使用push 或 pop时,会覆盖原来的数据。就像CPU执行指令时一样,它只知道执行当前指令,而不知道以后指令的具体信息。即只处理当前信息。因此必须规划好栈段的内存空间大小,以防栈顶越界。另外,当栈为空时,sp指向栈空间最高地址单元的下一地址。

3.9 posh 和 pop
push ax;
sp = sp - 2;
将ax中的数据送入栈中;
pop ax;
将栈中的数据送入ax中;
sp = sp + 2;
push/pop 寄存器/段寄存器/内存单元
3.10 栈段
首先,栈段只是我们的安排,必须将SS,SP设置成相应的值才能使CPU知道这个段用于栈。且必须自己操心栈顶越界的事情,所以说汇编是真的难受。
实验二
运用Debug中的D命令,A命令,U命令。可以将段寄存器DS,CS,SS作为它们的参数。如:-d ds:0 -a cs:0 -u ss:0 ;诸如此类。
另外,该处实验还提到了中断机制,即mov ss,ax;mov sp,0010;使用t命令执行第一条指令之后,就紧接着执行另外一条而不用t命令。最后,将一段内存用作栈之后,该内存的内容会恢复以前的内容(猜想)?
第四章
第一个程序
4.1 从写出到执行
- 编写源程序
- 编译(.obj),链接(.exe)
可执行文件包括:1.程序(翻译后的机器码和定义的数据)2.相关信息(程序大小,占用多少内存空间)
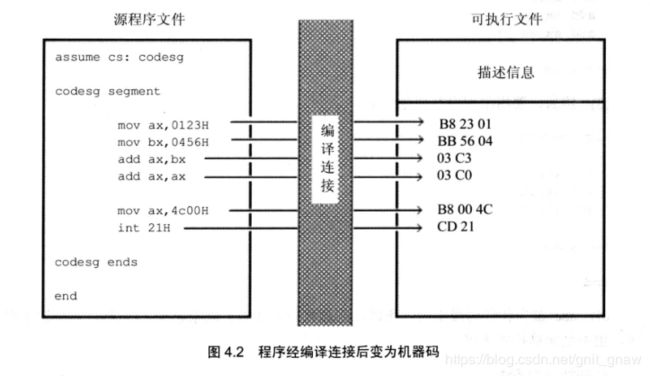
4.2源程序
;一个例子
assume cs:SegmentName ;伪指令:将CS与代码段联系
SegmentName segment ;段开始,SegmentName是标号,作为段的标号,指代了段的地址
mov ax,520H
mov bx,1314H
add ax, bx
mov ax,4c00H
int 21H ;"程序返回"
SegmentName ends ;"段结束"
end ;"程序结束"
4.3 编辑源程序
assume cs:code
code segment
mov ax,01H
mov bx,02H
add ax,bx
mov ax,4c00H
int 21H
code ends
end
4.4 编译
产生obj(没有错误的话)文件,列表文件,交叉引用文件。
列表文件:
Microsoft (R) Macro Assembler Version 5.00 3/5/20 21:50:52
Page 1-1
1 assume cs:code
2 0000 code segment
3
4 0000 B8 0001 mov ax,01H
5 0003 BB 0002 mov bx,02H
6 0006 03 C3 add ax,bx
7
8 0008 B8 4C00 mov ax,4c00H
9 000B CD 21 int 21H
10 000D code ends
11
12 end
Microsoft (R) Macro Assembler Version 5.00 3/5/20 21:50:52
Symbols-1
Segments and Groups:
N a m e Length Align Combine Class
CODE . . . . . . . . . . . . . . 000D PARA NONE
Symbols:
N a m e Type Value Attr
@FILENAME . . . . . . . . . . . TEXT a_test
12 Source Lines
12 Total Lines
3 Symbols
50720 + 465824 Bytes symbol space free
0 Warning Errors
0 Severe Errors
(我只能打开列表文件)
4.5 链接
link a_test.obj
输入可执行文件名称,映像文件名称,要链接的库文件(若程序中调用了某一库文件的子程序)
产生可执行文件。
映像文件:
LINK : warning L4021: no stack segment
Start Stop Length Name Class
00000H 0000CH 0000DH CODE
- 有时候程序很大时,将其分为多个程序进行编译,每个程序成为目标文件之后,再将它们链接起来。
- 调用某个库文件中的子程序,要将其与该目标文件链接。
- 链接程序将存有机器代码的目标文件处理成可执行信息。
4.6 简化编译,链接
简言之,在文件名后加分号;
4.7 运行.exe
没啥可写,因为看不出来。
4.8 将可执行文件载入内存并使它运行
我这里是DOS Box的命令行环境载入并使其运行的。所以运行结束后,回到原来的环境(等待输入);
4.9 执行文件跟踪
debug a_test.exe
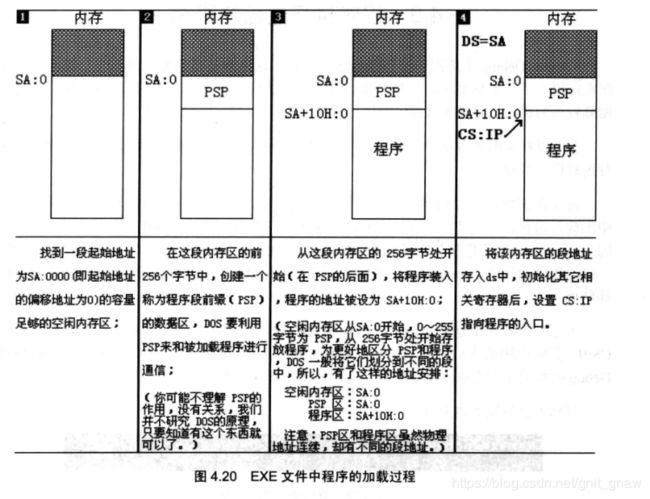
PSP物理地址:SA(ds中):0;
程序:SA x 16 +256 = SA x 16+16 x 16 = (SA+16) x 16 = SA+10H : 0;
ps: 执行int 21H时要用P命令。
实验三
编程,编译,链接,跟踪;
psp的头两个字节时CD20;
第五章 [BX] 和loop指令
5.1 [bx]
以前我们要将某一内存的内容送入寄存器,就要指定该内存的物理地址,其中段地址SA由DS提供,偏移地址SE由自己给出,为一常数。但是,我们也可以指定其在某个寄存器中(bx)。如:
mov ax,[bx];
就是将物理地址为(dx):(bx)的内容送入ax。其中()的含义为内容。如(bx)表示寄存器bx中的数据内容。
inc自增指令;
5.2 loop指令
- 设置标号。标号指代了一个内存地址,将标号指定循环代码的开始处。
- 每次循环结束后,(cx) = (cx) -1;
- 判断(cx)是否为0,为0就结束,否则跳转到标号处执行。
例子:计算256 x 345,结果存于ax中
assume cs:codeseg
codeseg segment
mov ax,0
mov cx,256
mark: add ax,345
loop mark
mov 4c00H
int 21H
codeseg ends
end
5.3 另一程序
例:计算将ffff:0006单元中的数 x 3,存储在dx中;
首先,该单元中的数是一个字节型的数,最大为256,256*3并不超过25536,故dx可以存储该结果。另外,将一个字节型数据赋给字型数据:mov ah, 0;mov al,[0];
assume cs:codename
codename segment
mov ax,0ffffH
;"汇编程序中,数据不能以字母开头"
mov ds,ax
mov bx,6
mov ah,0
mov al,[bx]
mov dx,0
mov cx,3
s: add dx,ax
loop s
mov ax,4c00H
int 21H
codename ends
end
debug 命令 :G命令,-g 0012 执行命令到IP = 0012处;P命令,-p;遇到loop指令时,p指令会自动执行循环,直到(cx) = 0;
5.4 debug 与编译器的一点不同
在debug中,诸如mov ax,[0];这样得指令会被解释为从某个段的地址取偏移地址为0的内存单元的内容。但是在编译器中,这样的指令解释为将常数0送入寄存器。即mov ax,[0] = mov ax,0;为达到取内存单元的数据,需要将偏移地址放到bx中,再用mov ax,[bx]这样的指令,也可以用mov ax,ds:[0]这样显式的将段地址放到idata前面。
5.5 loop和[bx]的联合应用
将物理地址ffff:0~ffff:b的字节型数据相加,结果存到dx中。
assume cs:codeseg
codeseg segment
mov ax,0ffffH
mov ds,ax
mov bx,0
mov dx,0
mov cx,12
s: mov ah,0
mov al,ds:[bx]
add dx,ax
inc bx
loop s
mov ax,4c00H
int 21H
codeseg ends
end
5.6 段前缀
诸如mov ax,ds:[bx] mov ax,es:[bx] mov ax,ss:[bx] mov ax,cs:[bx]中的ds、es、ss、cs叫做段前缀。标识段地址。
5.7 一段安全的内存空间
一般的PC机中,DOS和合法的程序都不会使用0:200~0:2ff这256个KB的地址空间。所以使用这段空间是安全的。

5.8 段前缀的使用
将ffff:0~ffff:b的内容复制到内存地址为0200:0~0200:b。
assume cs:code
code segment
mov cx,12
mov bx,0
s: mov ax,0ffffH
mov ds,ax
mov dl,ds:[bx]
mov ax,0200H
mov ds,ax
mov ds:[bx],dl
inc bx
loop s
mov ax,4c00H
int 21H
code ends
end
好吧,为何不利用两个段寄存器呢?
assume cs:code
code segment
mov ax,0ffffH
mov ds,ax
mov ax,0200H
mov es,ax
mov bx,0
mov cx,12
s:
mov al,ds:[bx]
mov es:[bx],al
inc bx
loop s
mov 4c00H
int 21H
code ends
ends
实验四
- 编程,向内存0200:0~0200:3f传输数据0~3fH;但只使用9条指令,其中包括mov 4c00H 和 int 21H。
- 编程,将mov 4c00H之前的指令复制到内存0200:0处。
- 指令(1)
assume cs:code
code segment
mov ax,0200H
mov ds,ax
mov bx,0
mov cx,64
s: mov ds:[bx],bl
inc bx
loop s
mov ax,4c00H
int 21H
code ends
end
(2)
assume cs:codeseg
codeseg segment
mov dx,cs
mov es,dx
mov ax,0200H
mov ds,ax
mov bx,0
mov cx,21
s: mov al,es:[bx]
mov ds:[bx],al
inc bx
loop s
mov 4c00H
int 21H
codeseg ends
end
第六章 包含多个段的程序
将代码、数据、栈存放在不同的段中
6.1 在代码段中使用数据
将这8个数据:1234H,2345H,3456H,4567H,5678H,6789H,789aH,89abH累加,结果放在ax中;
代码:
assume cs:codeseg
codeseg segment
dw 1234H,2345H ,3456H,4567H,5678H,6789H,789aH,89abH
;define word定义字型数据,大小16字节
start:mov ax,0;程序入口
mov bx,0
mov cx,8
s: add ax,cs:[bx]
add bx,2
loop s
mov ax,4c00H
int 21H
codeseg ends
end start ;用end指明了程序入口在标号start处
CPU是如何得知程序入口的呢?每一个程序都有描述信息,其中的许多信息是编译器,链接器对源程序的伪指令处理而成的。因此,伪指令end start标记了程序的入口。在程序载入内存后,读取描述信息后,就知道哪里是入口了,将CS:IP指向入口地址。
6.2 在程序中使用栈
任务:将上一节程序中的数据逆序存放
assume cs:codeseg
codeseg segment
dw 1234H,2345H ,3456H,4567H,5678H,6789H,789aH,89abH
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
start: mov ax,cs
mov ss,ax
mov sp,30H ;将栈的大小设为16个字
mov bx,0
mov cx,8
s: push cs:[bx]
add bx,2
loop s
mov cx,8
mov bx,0
s1: pop cs:[bx]
add bx,2
loop s1
mov ax,4c00H
int 21H
codeseg ends
end start
下面的程序实现用0:0~15的数据改变程序中的数据:
assume cs:codename
codename segment
dw 1234H,2345H ,3456H,4567H,5678H,6789H,789aH,89abH
start: mov ax,0
mov ds,ax
mov bx,0
mov cx,8
s: mov ax,[bx]
mov cs:[bx],ax
add bx,2
loop s
mov ax,4c00h
int 21h
codename ends
start end
使用栈来传输数据:
assume cs:codename
codename segment
dw 1234H,2345H ,3456H,4567H,5678H,6789H,789aH,89abH
dw 0,0,0,0,0,0,0,0,0,0
start: mov ax,0
mov ds,ax
mov ax,cs
mov ss,ax
mov sp,25h
mov bx,0
mov cx,8
s: push ds:[bx]
pop cs:[bx]
add bx,2
loop s
mov ax,4c00h
int 21h
codename ends
end start
6.3 将数据、代码、栈放入不同的段
实现数据逆序存放:
assume cs:codeseg,ss:stackseg,ds:dataseg
dataseg segment
dw 1234H,2345H ,3456H,4567H,5678H,6789H,789aH,89abH
dataseg ends
stackseg segment
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
stackseg ends
codeseg segment
start:
mov ax,stackseg
mov ss,ax
mov sp,20h
mov ax,dataseg
mov ds,ax
mov bx,0
mov cx,8
s: push [bx]
add bx,2
loop s
mov bx,0
mov cx,8
s0: pop [bx]
add bx,2
loop s0
mov ax,4c00h
int 21h
codeseg ends
end start
实验五
将a段的数据与b段的数据分别相加,结果存入c段中:
assume cs:code
a segment
db 1,2,3,4,5,6,7,8
a ends
b segment
db 1,2,3,4,5,6,7,8
b ends
c segment
db 0,0,0,0,0,0,0,0
c ends
code segment
start:
mov ax,a
mov ds,ax
mov bx,0
mov ax,c
mov es,ax
mov cx,8
s:
mov al,ds:[bx]
mov es:[bx],al
inc bx
loop s
mov ax,b
mov ds,ax
mov bx,0
mov cx,8
s:
mov al,ds:[bx]
add es:[bx],al
inc bx
loop s
mov ax,4c00h
int 21h
code ends
end start
若一个段有N个字节,则编译器会分配(N/16+1)*16个字节;
用push命令将a段中的前8个数据逆序存入b段中:
assume cs:code
a segment
dw 1,2,3,4,5,6,7,8,9,ah,bh,ch,dh,eh,10h
a ends
b segment
dw 0,0,0,0,0,0,0,0
b ends
code segment
start:
mov ax,a
mov ds,ax
mov ax,b
mov ss,ax
mov sp,10h
mov bx,0
mov cx,8
s:
push [bx]
add bx,2
loop s
mov ax,4c00h
int 21h
code ends
end start
第七章 更灵活的定位内存地址的方法
7.1 and 和 or
and逻辑与指令。将相应的位设置为0,其它设置为1,与上别的数,将该数的相应位设置为0。
or逻辑或指令,与上述逻辑与相反。
7.2 ASCII码
计算机中还算通用的编码方式。将字符与数字进行映射,使信息得以在计算机中存储和传输。
7.4 以字符形式给出的数据
通过’…'的形式可以将字符以ASCII编码的数据存入内存;
assume cs:code ds:data
data segment
db 'Unix'
db 'Foxk'
data ends
code segment
start:mov al,'a'
mov bh,'b'
mov ax,4c00h
int 21h
code ends
end start
7.5 大小写转换问题
将data段中的"BaSiC"大写转换成小写,"iNfOrMaTiOn"小写转换成大写;
assume cs:code ds:data
data segment
db 'BaSiC'
db 'iNfOrMaTiOn'
data ends
code segment
start:;具体算法是用and or.因为大小写的二进制的第5位(32)不一致。
mov ax,data
mov ds,ax
mov cx,5
mov bx,0
s:
mov al,00100000b
or ds:[bx],al
inc bx
loop s
mov cx,11
mov bx,5
s0:
mov al,11011111b;书上的代码是mov al,[bx] add al,11011111
;mov [bx],al 我直接将20h与内存中的值运算 上同
and ds:[bx],al
inc bx
loop s0
mov ax,4c00h
mov 21h
code ends
end start
7.6 [bx+idata]
内存地址的标识:段地址在ds中,偏移地址为bx中的值+idata,即:
(ds)*16+(bx)+idata,代码可写为:
mov ax,[bx+200]
mov ax,[200+bx];常用,类似于c语言的数组
mov ax,200[bx];更像数组
mov ax,[bx].200
7.7 改进上述转换大小写的代码
assume cs:code ds:data
data segment
dw 'BaSiC'
dw 'MinIX'
data ends
code segment
start:
mov ax,data
mov ds,ax
mov bx,0
mov cx,5
s:
mov al,00100000b
mov ah,11011111b
or 0[bx],al
and 5[bx],ah
inc bx
loop s
mov ax,4c00h
int 21h
code ends
end start
7.8 si 和 di
si和di是8086计算机中于bx功能相近的寄存器,si和di不能分成两个8位寄存器来使用。下面的指令实现相同功能:
mov bx,0
mov ax,[bx]
mov si,0
mov ax,[si]
mov di,0
mov ax,[di]
mov bx,0
mov ax,[bx+123]
mov si,0
mov ax,123[si]
mov di,0
mov ax,[si].123
7.9 [bx+si] [bx+di]
内存地址为
(bx)+(si/di)即mov ax,[bx+si/di]
常用指令:
mov ax,[bx][si/di]
7.10 [bx+si+idata] [bx+di+idata]
内存地址为(bx)+(si/di)+idata,即mov ax,[bx+si+idata]
常用指令:mov ax,200[bx][si] mov ax,[200+bx+si]
7.11 不同寻址方式的灵活运用

将数据段中的前4个字母转换成大写:
assume cs:code ds:data ss:stack
data segment
db '1. display '
db '2. brows '
db '3. replays '
db '4. modifly '
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
start:
mov ax,data
mov ds,ax
mov ax,ss
mov ss,ax
mov sp,10h
mov bx,0
mov cx,4
s:
push cx
mov cx,3
mov si,0
s0:
mov al,11011111b
and 3[bx][si],al
inc si
loop s0
add bx,10h
pop cx
loop s
mov ax,4c00h
int 21h
code ends
end start
实验六
实践以上的程序
第八章 数据处理的两个基础问题
- 数据在哪里?
- 数据有多长?
8.1 bx bp si di
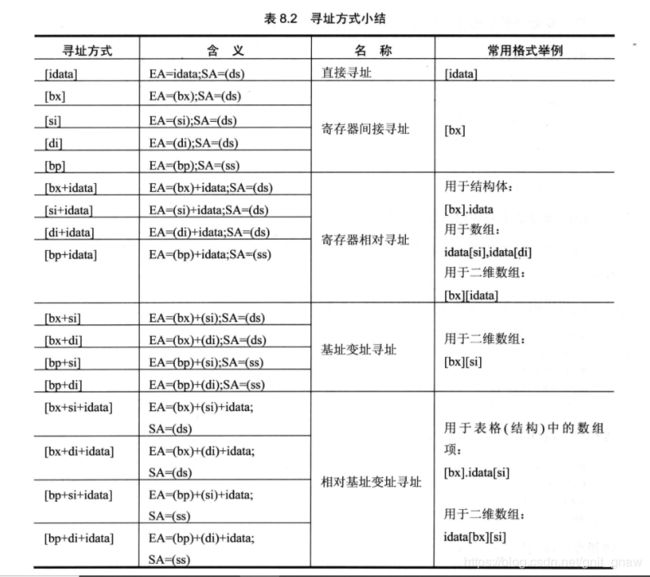
只有这4个寄存器能在[…]里进行内存单元的寻址。有以下指令:
mov ax,[bx]
mov ax,[bp]
mov ax,[si]
mov ax,[di]
mov ax,[bx+si]
mov ax,[bx+di]
mov ax,[bp+si]
mov ax,[bp+di]
mov ax,[bx+si+idata]
mov ax,[bx+di+idata]
mov ax,idata[bp+si]
mov ax,idata[bp+di]
另外,bp和bx,si和di不能两两组合。
bp的默认段寄存器是ss。
8.2 机器指令处理的数据在哪里
- CPU内部
- 内存
- 端口
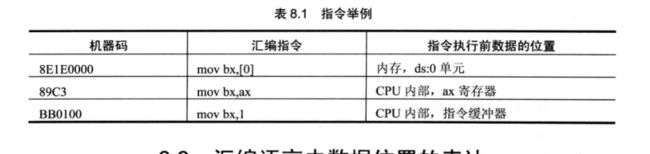
8.3 汇编语言中数据位置的表达
- 立即数:直接包含在指令中的数据,执行前在指令缓冲器中。
- 寄存器:在指令中指定寄存器
- 段地址*16+偏移地址
8.4 寻址方式
8.5 指令要处理的数据有多长
- 通过寄存器指明处理的数据有多长
- 在没有寄存器指明的情况下,用操作符 X ptr指定 word ptr/byte ptr
- 其它指令:如栈的默认处理数据是字
8.6 寻址方式的综合应用
修改在seg:60H的内存内容:
assume cs:code ,ds:iseg
iseg segment
db 'DEC'
db 'Ken Oslen'
dw 137,40
db 'PDP'
iseg ends
code segment
start:
mov ax,iseg
mov ds,ax
mov bx,0
mov word ptr [bx+0ch],38
add word ptr [bx+0eh],70
mov si,4
mov byte ptr [0ch+si],'W'
inc si
mov byte ptr [0ch+si],'A'
inc si
mov byte ptr [0ch+si],'X'
mov ax,4c00H
int 21h
code ends
end start
8.7 div除法指令
- 除数:有8位或16位,存储在寄存器或内存中
- 被除数:存储在ax或ax+dx中,若除数为8位,则被除数为16位,在ax中,若除数为16位,则被除数为32位,高16位存储在dx中,低16位存储在ax中。
- 结果:8位的计算,商在ah中,余在al中;16位,商在ax中,余在dx中;
计算100001/100;
assume cs:code
code segment;100001 = 186a1h
start:
mov dx,1h
mov ax,86a1h
mov bx,100
div bx
mov ax,4c00h
int 21h
code ends
end start
8.7 伪指令dd
dd: 两个字,4个字节,32位
将第一段数据除以第二段数据,结果存在第三段中:
assume cs:codeseg ds:data
data segment
dd 100001
dw 100
dw 0
data ends
codeseg segment
start:
mov ax,data
mov ds,ax
mov ax,[0]
mov dx,[2]
div word ptr [4]
mov [6],ax
mov ax,4c00h
int 21h
codeseg ends
end start
8.8 dup
用于配合dd、db、dw,用法如下:
db 3 dup (0); = db 0,0,0
dw 9 dup (1,2,3); = dw 1,2,3,1,2,3,1,2,3
dd 9 dup ('abc'); = dd 'abc','abc','abc'
db/dw/dd n dup (xxx)
实验七
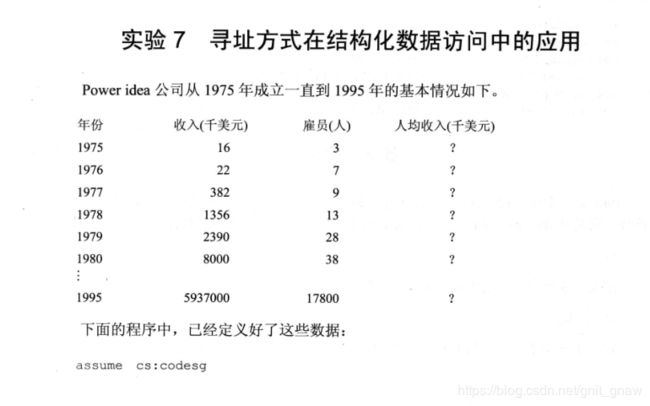

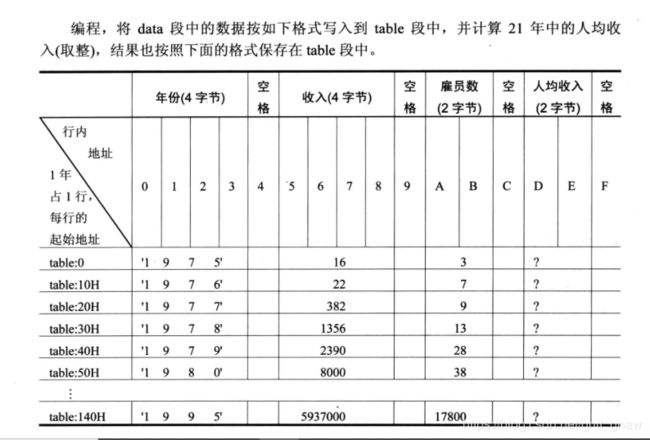
代码:
assume cs:codeseg, ds:dataseg,ss:stack
dataseg segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983','1984','1985','1986'
db '1987','1988','1989','1990','1991','1992','1993','1994','1995'
;以上是表示21年的21个字符串
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;以上是表示21年公司总收入的21个dword型数据
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;以上是表示21年公司雇员人数的21个word型数据
dataseg ends
table segment
db 21 dup ('year summ ne ?? ')
table ends
;之所以不写注释,是感觉要注释的太多了,有一点细节,怕麻烦
;可能写的太杂了,很多东西没考虑清楚
;多次使用同一寄存器,应该不需要那么多的
;程序调试过,能行,还好能行,要吐了,不想碰它了
stack segment
db 8 dup (0)
stack ends
codeseg segment
start:
mov ax,dataseg
mov ds,ax
mov ax,table
mov es,ax
mov ax,stack
mov ss,ax
mov sp,0ah
mov cx,21
mov bx,0;
mov dx,0
mov bp,0
mov si,0
mov di,0
s:
push cx
mov cx,4
mov bx,dx
s0:
mov al,0[bx]
mov es:[bp],al
inc bx
inc bp
loop s0
mov dx,bx
inc bp
pop cx
push dx
mov bx,si
mov ax,84[bx]
mov es:[bp],ax
add bx,2
add bp,2
mov dx,84[bx]
mov es:[bp],dx
add bp,2
add bx,2
mov si,bx
inc bp
push si
mov bx,di
mov si,168[bx]
mov es:[bp],si
div word ptr es:[bp]
add bp,2
pop si
pop dx
inc bp
add bx,2
mov di,bx
mov es:[bp],ax
add bp,2
inc bp
loop s
mov ax,4c00h
int 21h
codeseg ends
end start
;2020 3 9 0:46
以上内容绝大部分来自:《汇编语言(第三版)》王爽著
仅作自己复习之用,如有错误,请指正