Pytorch学习笔记之训练词向量(三)
Pytorch学习笔记之Pytorch训练词向量(三)
学习目标
- 学习词向量的概念
- 用Skip-thought模型训练词向量
- 学习使用PyTorch dataset和dataloader
- 学习定义PyTorch模型
- 学习torch.nn中常见的Module
- Embedding
- 学习常见的PyTorch operations
- bmm
- logsigmoid
- 保存和读取PyTorch模型
使用的训练数据可以从以下链接下载到。
链接:https://pan.baidu.com/s/1tFeK3mXuVXEy3EMarfeWvg 密码:v2z5
在这一份notebook中,我们会(尽可能)尝试复现论文Distributed Representations of Words and Phrases and their Compositionality中训练词向量的方法. 我们会实现Skip-gram模型,并且使用论文中noice contrastive sampling的目标函数。
这篇论文有很多模型实现的细节,这些细节对于词向量的好坏至关重要。我们虽然无法完全复现论文中的实验结果,主要是由于计算资源等各种细节原因,但是我们还是可以大致展示如何训练词向量。
以下是一些我们没有实现的细节
- subsampling:参考论文section 2.3
1. 引入pytorch相关包
import torch
import torch.nn as nn # neural Network
import torch.nn.functional as F # functional
import torch.utils.data as tud #
from torch.nn.parameter import Parameter
from collections import Counter
import numpy as np
import random
import math
import pandas as pd
import scipy
import sklearn
from sklearn.metrics.pairwise import cosine_similarity
# 配置参数
# 是否有GPU
USE_CUDA = torch.cuda.is_available()
# 固定随机数种子,保证程序复现
seed_numder = 1
random.seed(seed_numder)
np.random.seed(seed_numder)
torch.manual_seed(seed_numder)
if USE_CUDA:
torch.cuda.manual_seed(seed_numder)
# 设置超参数
K = 100 # 负样本随机采样与正样本的比例
C = 3 # 上下文窗口数目
NUM_EPOCHS = 10 # 迭代轮数
MAX_VOCAB_SIZE = 30000 # 词汇表大小
BATCH_SIZE = 128 #每次迭代的batch数目
LEARNING_RATE = 0.2 # 学习率
EMBEDDING_SIZE = 100 # 词向量维度
LOG_FILE = 'word_embedding.log'
2. 预处理
- 从文本文件中读取所有的文字,通过这些文本创建一个vocabulary
- 由于单词数量可能太大,我们只选取最常见的MAX_VOCAB_SIZE个单词
- 我们添加一个UNK单词表示所有不常见的单词
- 我们需要记录单词到index的mapping,以及index到单词的mapping,单词的count,单词的(normalized) frequency,以及单词总数。
def word_tokenize(text):
return text.split()
# 读取训练文本
with open("./text8/text8/text8.train.txt", "r") as fin: #读入文件
text = fin.read()
# 分词后转换为列表
text = [w for w in word_tokenize(text.lower())]
# 获取出现频率最高的前 (MAX_VOCAB_SIZE - 1)个词
# 返回是一个字典类型 {word_1: frequency_1}
vocab = dict(Counter(text).most_common(MAX_VOCAB_SIZE - 1))
# 统计剩余的其他词出现的频率
vocab["" ] = len(text) - np.sum(list(vocab.values()))
#
idx_to_word = [w for w in vocab.keys()]
#
word_to_idx = {word:i for i, word in enumerate(idx_to_word)}
# 记录单词出现的频数
word_counts = np.array([v for v in vocab.values()], dtype=np.float32)
# 正则化
word_freqs = word_counts / np.sum(word_counts)
# 3/4次之后,会将高概率的单词的概率值,分一部分给低概率的单词。
word_freqs = word_freqs ** (3./4.)
#
word_freqs = word_freqs / np.sum(word_freqs)
# 词汇表数目
VOCAB_SIZE = len(idx_to_word)
确认一下词表大小
VOCAB_SIZE
> 30000
3. 实现Dataloader
一个dataloader需要以下内容:
- 把所有text编码成数字,然后用subsampling预处理这些文字。
- 保存vocabulary,单词count,normalized word frequency
- 每个iteration sample一个中心词
- 根据当前的中心词返回context单词
- 根据中心词sample一些negative单词
- 返回单词的counts
这里有一个好的tutorial介绍如何使用PyTorch dataloader.
为了使用dataloader,我们需要定义以下两个function:
__len__function需要返回整个数据集中有多少个item__getitem__根据给定的index返回一个item
有了dataloader之后,我们可以轻松随机打乱整个数据集,拿到一个batch的数据等等。
class WordEmbeddingDataset(tud.Dataset):
def __init__(self, text, word_to_idx, idx_to_word, word_freqs):
''' text: a list of words, all text from the training dataset
word_to_idx: the dictionary from word to idx
idx_to_word: idx to word mapping
word_freq: the frequency of each word
word_counts: the word counts
'''
super().__init__() #初始化模型
# 将文本编码成数目
self.text_encoded = [word_to_idx.get(t, word_to_idx["" ]) for t in text]
self.text_encoded = torch.LongTensor(self.text_encoded)
#
self.word_to_idx = word_to_idx
self.idx_to_word = idx_to_word
self.word_freqs = torch.Tensor(word_freqs)
def __len__(self):
''' 返回整个数据集(所有单词)的长度
'''
return len(self.text_encoded)
def __getitem__(self, idx):
''' 这个function返回以下数据用于训练
- 中心词
- 这个单词附近的(positive)单词
- 随机采样的K个单词作为negative sample
'''
# 获取中心词
center_word = self.text_encoded[idx]
# 获取中心词上下文的词
pos_indices = list(range(idx-C, idx)) + list(range(idx+1, idx+C+1))
# 超出长度的部分,取余(一个圆环)
pos_indices = [p%self.__len__() for p in pos_indices]
pos_words = self.text_encoded[pos_indices]
# 获取负样本, 精细时应该考虑去掉抽取出中心词或者上下文词的情况
neg_words = torch.multinomial(self.word_freqs, K * pos_words.shape[0], True)
return center_word, pos_words, neg_words
4. 创建一个dataset对象及使用DataLoader加载数据
dataset = WordEmbeddingDataset(text, word_to_idx, idx_to_word, word_freqs)
# windows系统设置 num_workers=0(因为windows系统下pytorch的多线程执行有bug),其他系统可以增加线程数
dataloader = tud.DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
看一下dataloader返回的数据
# dataloader 每次返回的训练数据 batch_size
showNextData = next(iter(dataloader))
print(showNextData[0].size())
print(showNextData[1].size())
print(showNextData[2].size())
运行结果
torch.Size([128])
torch.Size([128, 6])
torch.Size([128, 600])
5. 定义Pytorch模型
loss函数如下
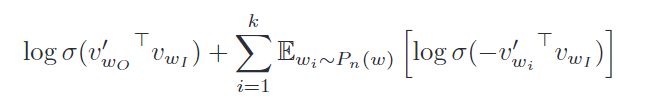
class EmbeddingModel(nn.Module):
def __init__(self, vocab_size, embed_size):
''' 初始化输出和输出embedding
'''
super().__init__()
self.vocab_size = vocab_size # 30000
self.embed_size = embed_size # 100
initrange = 0.5 / self.embed_size
# [30000, 100] matrix
self.in_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
# 初始化权重分布设为均匀分布[-5e-3, 5e-3]
self.in_embed.weight.data.uniform_(-initrange, initrange)
self.out_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
self.out_embed.weight.data.uniform_(-initrange, initrange)
def forward(self, input_labels, pos_labels, neg_labels):
'''
input_labels: 中心词, [batch_size]
pos_labels: 中心词周围 context window 出现过的单词 [batch_size * (window_size * 2)]
neg_labelss: 中心词周围没有出现过的单词,从 negative sampling 得到 [batch_size, (window_size * 2 * K)]
return: loss, [batch_size]
'''
input_embedding = self.in_embed(input_labels) # [b, embed_size] [128, 100]
pos_embedding = self.out_embed(pos_labels) # [b, 2*C, embed_size] [128, 6, 100]
neg_embedding = self.out_embed(neg_labels) # [b, 2*C*K, embed_size] [128, 600, 100]
# unsqueeze(dim) 在指定维度插入一维,squeeze(dim)在指定维度去掉一维。dim属于[-x.dim-1 ,x.dim+1) 左闭右开
# squeeze() 压缩所有维度为1的维度 (3, 1, 2, 1, 5) -> (3, 2, 5)
# torch.bmm()为batch矩阵乘法(b, n, m)*(b, m, p)=(b, n, p)
# [b, 2*C] [128, 6]
log_pos = torch.bmm(pos_embedding, input_embedding.unsqueeze(2)).squeeze()
# [b, 2*C*K] [128, 600]
log_neg = torch.bmm(neg_embedding, input_embedding.unsqueeze(2)).squeeze()
# b
log_pos = F.logsigmoid(log_pos).sum(1)
log_neg = F.logsigmoid(log_neg).sum(1)
loss = log_pos + log_neg
return -loss
def input_embeddings(self):
# 取出权重,计算相似度
weight = self.in_embed.weight.data.cpu().numpy()
# 通常也可以取 两个Embedding的平均值
weight1 = ((self.in_embed.weight.data + self.out_embed.weight.data) / 2.).cpu().numpy()
# 两个都返回,看看哪种情况好
return weight, weight1
6. 创建模型对象
model = EmbeddingModel(VOCAB_SIZE, EMBEDDING_SIZE)
if USE_CUDA:
model = model.to('cuda:0')
查看一下模型结构
model
# 一下为输出结果
EmbeddingModel(
(in_embed): Embedding(30000, 100)
(out_embed): Embedding(30000, 100)
)
7. 评估词向量的代码
- evaluate(filename, embedding_weight_1, embedding_weight_2) 函数利用训练好的词向量计算单词序列之间的相似度,与人类主观上单词相似度进行对比。一致率越高,数值接近1,反之,为-1。
- find_nearest(word, embedding_weight_1, embedding_weight_2) 利用相似度,找出与指定单词意思最近的十个单词。
- embedding_weight_1 指从in_embed权重矩阵中取
- embedding_weight_2 指将in_embed权重矩阵 和 out_embed权重矩阵相加,再取平均后的结果。
- 科学研究就是要做实验,试一下两者那个效果好
def evaluate(filename, embedding_weight_1, embedding_weight_2):
if filename.endswith(".csv"):
data = pd.read_csv(filename, sep=',')
else:
data = pd.read_csv(filename, sep='\t')
human_similarity = []
# in_embed权重相似度
model_similarity_1 = []
# in_embed 和 out_embed 两个Embedding的平均值
model_similarity_2 = []
for i in data.iloc[:, 0:2].index:
word1, word2 = data.iloc[i, 0], data.iloc[i, 1]
if word1 not in word_to_idx or word2 not in word_to_idx:
continue
else:
# 取出索引值
word1_idx, word2_idx = word_to_idx.get(word1), word_to_idx.get(word2)
# 取出训练好的 词向量值
word1_embed_1, word2_embed_1 = embedding_weight_1[[word1_idx]], embedding_weight_1[[word2_idx]]
word1_embed_2, word2_embed_2 = embedding_weight_2[[word1_idx]], embedding_weight_2[[word2_idx]]
# 计算相似度度 两个单词相似度越高,夹角应该越小,sklearn.metrics.pairwise.cosine_similarity (相似度)增大
model_similarity_1.append(float(cosine_similarity(word1_embed_1, word2_embed_1)))
model_similarity_2.append(float(cosine_similarity(word1_embed_2, word2_embed_2)))
human_similarity.append(float(data.iloc[i, 2]))
# 统计预测值与真实值序列之间的相关系数
# spearman秩相关系数是度量两个变量之间的统计相关性的指标,用来评估当用单调函数来描述两个变量之间的关系有多好。
# 在没有重复数据的情况下,如果一个变量是另外一个变量的严格单调函数,那么二者之间的spearman秩相关系数就是1或+1,称为完全spearman相关
return scipy.stats.spearmanr(human_similarity, model_similarity_1), scipy.stats.spearmanr(human_similarity, model_similarity_2)
def find_nearest(word, embedding_weight_1, embedding_weight_2):
index = word_to_idx.get(word)
embed_1 = embedding_weight_1[index]
embed_2 = embedding_weight_2[index]
# 1 - cosine_sklearn = cosine_scipy scipy库和是sklearn库关于余弦线相似度的计算是不一样的
# 两个单词相似度越高,夹角应该越小,cosine_sklearn (相似度)增大,cosine_scipy (夹角)减小
cos_dis_1 = np.array([scipy.spatial.distance.cosine(e, embed_1) for e in embedding_weight_1])
cos_dis_2 = np.array([scipy.spatial.distance.cosine(e, embed_2) for e in embedding_weight_2])
# argsort()函数是将x中的元素从小到大排列,返回其对应的index(索引号)
lst_1 = [idx_to_word[i] for i in cos_dis_1.argsort()[:10]]
lst_2 = [idx_to_word[i] for i in cos_dis_2.argsort()[:10]]
return lst_1, lst_2
8. 训练模型:
- 模型一般需要训练若干个epoch
- 每个epoch我们都把所有的数据分成若干个batch
- 把每个batch的输入和输出都包装成cuda tensor
- forward pass,通过输入的句子预测每个单词的下一个单词
- 用模型的预测和正确的下一个单词计算cross entropy loss
- 清空模型当前gradient
- backward pass
- 更新模型参数
- 每隔一定的iteration输出模型在当前iteration的loss,以及在验证数据集上做模型的评估
# 优化器采用SGD
optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE)
#
for e in range(NUM_EPOCHS):
for i, (input_labels, pos_labels, neg_labels) in enumerate(dataloader):
#
input_labels = input_labels.long()
pos_labels = pos_labels.long()
neg_labels = neg_labels.long()
if USE_CUDA:
input_labels = input_labels.cuda()
pos_labels = pos_labels.cuda()
neg_labels = neg_labels.cuda()
# 梯度归零
optimizer.zero_grad()
# loss返回 [128] 求平均
loss = model(input_labels, pos_labels, neg_labels).mean()
loss.backward() # 反向传播
optimizer.step() # 更新梯度
# 每100次打印结果。
if i % 100 == 0:
with open(LOG_FILE, "a") as fout:
fout.write("epoch: {}, iter: {}, loss: {}\n".format(e, i, loss.item()))
print("epoch: {}, iter: {}, loss: {}".format(e, i, loss.item()))
# 每2000次计算一次相似度
if i % 2000 == 0:
embedding_weights_1, embedding_weights_2 = model.input_embeddings()
sim_simlex_1, sim_simlex_2 = evaluate("simlex-999.txt", embedding_weights_1, embedding_weights_2)
sim_men_1, sim_men_2 = evaluate("men.txt", embedding_weights_1, embedding_weights_2)
sim_353_1, sim_353_2 = evaluate("wordsim353.csv", embedding_weights_1, embedding_weights_2)
with open(LOG_FILE, "a") as fout:
print(f"epoch: {e}, iteration: {i}, \n simlex-999_1: {sim_simlex_1}, \n simlex-999_2: {sim_simlex_2}, \n men_1: {sim_men_1}, \n men_2: {sim_men_2}, \n sim353_1: {sim_353_1}, \n sim353_2: {sim_353_2}, \n nearest to monster: {find_nearest('monster', embedding_weights_1, embedding_weights_2)}\n")
fout.write(f"epoch: {e}, iteration: {i}, simlex-999_1: {sim_simlex_1},simlex-999_2: {sim_simlex_2}, men_1: {sim_men_1}, men_2: {sim_men_2}, sim353_1: {sim_353_1}, sim353_2: {sim_353_2}, nearest to monster: {find_nearest('monster', embedding_weights_1, embedding_weights_2)}\n")
运行结果示例如下(训练轮次自己设定)
epoch: 0, iter: 0, loss: 142.8716583251953
epoch: 0, iteration: 0,
simlex-999_1: SpearmanrResult(correlation=-0.035259516920833865, pvalue=0.27660953700886737),
simlex-999_2: SpearmanrResult(correlation=-0.047682561919958094, pvalue=0.14110938770590917),
men_1: SpearmanrResult(correlation=0.04988050229600173, pvalue=0.011246409260567655),
men_2: SpearmanrResult(correlation=0.04000382686226847, pvalue=0.0420970874212936),
sim353_1: SpearmanrResult(correlation=0.026812442387097967, pvalue=0.633297026852052),
sim353_2: SpearmanrResult(correlation=-0.0034262533468499058, pvalue=0.9513952103438084),
nearest to monster: (['monster', 'maltese', 'watershed', 'correspond', 'flops', 'yellowstone', 'gamal', 'tolstoy', 'aquitaine', 'denoting'], ['monster', 'etc', 'services', 'abraham', 'slightly', 'sexual', 'andrew', 'legal', 'nobel', 'broken'])
epoch: 0, iter: 100, loss: 102.23202514648438
epoch: 0, iter: 200, loss: 93.51679229736328
epoch: 0, iter: 300, loss: 91.04571533203125
epoch: 0, iter: 400, loss: 85.10859680175781
epoch: 0, iter: 500, loss: 73.21339416503906
epoch: 0, iter: 600, loss: 82.36524200439453
epoch: 0, iter: 700, loss: 71.56480407714844
epoch: 0, iter: 800, loss: 47.44879913330078
epoch: 0, iter: 900, loss: 49.65077209472656
epoch: 0, iter: 1000, loss: 53.81517028808594
epoch: 0, iter: 1100, loss: 37.037811279296875
epoch: 0, iter: 1200, loss: 49.845680236816406
epoch: 0, iter: 1300, loss: 44.053367614746094
epoch: 0, iter: 1400, loss: 29.414356231689453
epoch: 0, iter: 1500, loss: 41.82801818847656
epoch: 0, iter: 1600, loss: 35.28537368774414
epoch: 0, iter: 1700, loss: 26.633563995361328
epoch: 0, iter: 1800, loss: 31.498106002807617
epoch: 0, iter: 1900, loss: 29.859540939331055
epoch: 0, iter: 2000, loss: 31.989009857177734
epoch: 0, iteration: 2000,
simlex-999_1: SpearmanrResult(correlation=-0.030601859820272474, pvalue=0.3450785890869934),
simlex-999_2: SpearmanrResult(correlation=-0.0463389472461431, pvalue=0.15267173464395575),
men_1: SpearmanrResult(correlation=0.031088156058363608, pvalue=0.11426469625155944),
men_2: SpearmanrResult(correlation=0.02383281291831326, pvalue=0.226044371368817),
sim353_1: SpearmanrResult(correlation=-0.04833420023275394, pvalue=0.38957379699663996),
sim353_2: SpearmanrResult(correlation=-0.03349780564943204, pvalue=0.55110266180645),
nearest to monster: (['monster', 'a', 'but', 'he', 'home', 'empire', 'that', '' , 'one', 'time'], ['monster', 'has', 'are', 'etc', 'part', 'were', 'been', 'state', 'that', 'his'])
epoch: 0, iter: 2100, loss: 29.90845489501953
epoch: 0, iter: 2200, loss: 30.369483947753906
epoch: 0, iter: 2300, loss: 24.405258178710938