准备工作
配置和编译Linux内核
- 下载和解压Linux内核,此次实验使用的是5.4.34版本
- 使用
make menuconfig来配置内核,主要配置以下几个选项来开启内核调试功能- Kernel hacking --->
- Compile-time checks and compiler options --->
- [*] Compile the kernel with debug info
- [*] Provide GDB scripts for kernel debugging
- [*] Kernel debugging
- Compile-time checks and compiler options --->
- Processor type and features ---->
- [ ] Randomize the address of the kernel image (KASLR)
- Kernel hacking --->
- 使用
make指令编译内核
需要注意的是,内核一定要关闭KASLR功能,否则会导致打断点失败。
KASLR技术允许kernel image加载到VMALLOC区域的任何位置。当KASLR关闭的时候,kernel image都会映射到一个固定的链接地址。对于黑客来说是透明的,因此安全性得不到保证。KASLR技术可以让kernel image映射的地址相对于链接地址有个偏移。偏移地址可以通过dts设置。如果bootloader支持每次开机随机生成偏移数值,那么可以做到每次开机kernel image映射的虚拟地址都不一样。因此,对于开启KASLR的kernel来说,不同的产品的kernel image映射的地址几乎都不一样。因此在安全性上有一定的提升1。
制作根文件系统
本次实验使用busybox来生成根文件系统。
BusyBox combines tiny versions of many common UNIX utilities into a single small executable.
以上是在README文件中对busybox的介绍,它将一些常用的工具集成成为了一个可执行文件,使得开发人员不再需要一个个得手动编译安装大量的工具。如下图所示,几乎所有的二进制文件都链接到了busybox。
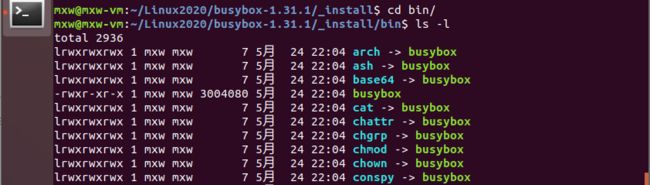
下面开始介绍如何制作根文件系统:
-
下载及配置busybox
#下载busybox源码,可以使用axel多线程下载以提高下载速度 axel -n 20 https://busybox.net/downloads/busybox-1.31.1.tar.bz2 tar -jxvf busybox-1.31.1.tar.bz2 #解压源码 cd busybox-1.31.1 #配置,注意编译成静态链接,即选中Settings选项下的Build static binary (no shared libs) make menuconfig #编译安装,默认安装到_install目录下 make -j$(nproc) && make install -
准备需要的目录及文件
mkdir rootfs cd rootfs #拷贝编译好的busybox的文件 cp ../busybox-1.31.1/_install/* ./ -rf #创建其他需要的目录 mkdir dev proc sys home #创建设备文件 sudo cp -a /dev/{null,console,tty,tty1,tty2,tty3,tty4} dev/ -
创建init脚本,其内容如下:
#!/bin/sh mount -t proc none /proc mount -t sysfs none /sys echo "Wellcome MengningOS!" echo "--------------------" cd home /bin/sh -
添加init脚本的执行权限,
chmod +x init -
打包成内存根⽂件系统镜像
find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../rootfs.cpio.gz
这里说明以下编译busybox遇到的坑,之前使用的系统是Ubuntu 20.04,编译busybox会报出如下错误:
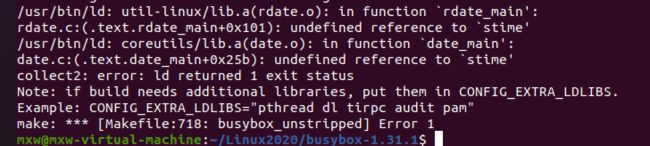
即找不到stime的定义,而在Ubuntu18.04.4中却可以正确编译。猜测问题可能出在glibc库,使用ldd --version检查glibc的版本,发现18.04中的是2.27版的,而在20.04中使用的是最新的2.31版本,去gnu网站查询glibc的版本更新信息,发现stime函数已经被弃用:
The obsolete function stime is no longer available to newly linked binaries, and its declaration has been removed from
. Programs that set the system time should use clock_settime instead.
由于本人对Linux不太熟悉,不知道如何对glibc进行降级,因此还是使用Ubuntu 18.04.4进行实验。
调试Linux内核
-
在命令行中启动编译好的Linux内核
qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz -S -s -nographic -append "console=ttyS0"其中,
-kernel参数指定了内核的位置,-initrd参数指定了根文件系统的位置,-S参数表示启动时暂停虚拟机,-s参数表示在TCP 1234端⼝上创建了⼀个gdbserver,最后的-nographic -append "console=ttyS0"表示不需要显示qemu窗口,直接在命令行中启动虚拟机。 -
虚拟机启动后,另开一个终端,启动gdb进行调试
cd linux-5.4.34/ # 加载内核符号表 gdb vmlinux # 连接调试用的虚拟机 (gdb) target remote:1234 #之后,就可以使用b,c等指令进行调试了
系统调用
为了安全,Linux 中分为用户态和内核态两种运行状态。对于普通进程,平时都是运行在用户态下,仅拥有基本的运行能力。当进行一些敏感操作,比如说要打开文件(open)然后进行写入(write)、分配内存(malloc)时,就会切换到内核态。内核态进行相应的检查,如果通过了,则按照进程的要求执行相应的操作,分配相应的资源。这种机制被称为系统调用,用户态进程发起调用,切换到内核态,内核态完成,返回用户态继续执行,是用户态唯一主动切换到内核态的合法手段2。
对于X86架构,系统调⽤的实现经历了 int $0x80/iret 到 sysenter/sysexit 再到 syscall/sysret 的演变。在64位操作系统中,主要使用syscall的方式进行系统调用,且通过寄存器来传递参数。本次实验以64位Linux为例进行分析。
在触发系统调用之前,需要将系统调用号存入eax寄存器,将参数传入rdi等寄存器,接着就可以使用syscall指令来触发系统调用。
84号系统调用-rmdir
本人学号最后两位为84,故选取第84号系统调用,查询/arch/x86/entry/syscalls/syscall_64.tbl表,可知84号系统调用为rmdir,这个系统调用是用于删除一个空目录的。
在/fs/namei.c中可以找到rmdir的定义:
SYSCALL_DEFINE1(rmdir, const char __user *, pathname)
{
return do_rmdir(AT_FDCWD, pathname);
}
它最终通过调用do_rmdir来实现相应的系统调用的功能。本次实验主要分析的是系统调用的过程,因此其具体实现就不再进行详细分析了。
系统调用过程分析
首先要先编写一个源文件来调用rmdir。在根文件系统的home目录下,新建一个myRmdir.c文件,其内容如下:
#include
int main(){
const char *path = "test";
int ret = -1;
asm volatile(
"movl $0x54, %%eax\n\t" //传递系统调用号
"movq %1, %%rdi\n\t" //传递参数
"syscall\n\t" //系统调用
"movq %%rax, %0\n\t" //保存返回值
:"=m"(ret) //输出
:"b"(path) //输入
);
if(ret == 0){
printf("rmdir success!\n");
}
else{
printf("rmdir failed!\n");
}
return 0;
}
同时,新建一个名为test的目录,如果系统调用成功执行,此目录应该会被删除。
静态编译myRmdir,此时home目录应该如下图所示:

用上面提到的方法,将此时的rootfs目录重新打包成根文件系统镜像,并运行虚拟机。
#运行虚拟机
qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz -S -s -nographic -append "console=ttyS0"
另外打开一个新的终端,进行远程调试
cd linux-5.4.34/
gdb vmlinux
#在rmdir系统调用处打断点
b __x64_sys_rmdir
#继续运行
c
虚拟机继续运行后,查看当前home目录内的内容如下图:
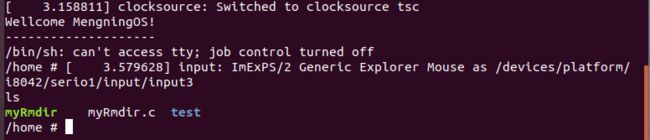
使用./myRmdir运行预先编译好的程序,切换回运行虚拟机的终端,发现停在了设置的断点处,再使用bt命令列出函数调用堆栈,如下:

发现主要的调用顺序是:entry_SYSCALL_64() -> do_syscall_64() -> __x64_sys_rmdir()。
接下来开始分析系统调用的过程。
syscall使用cpu内部的MSR寄存器来查找系统调用处理⼊⼝,可以快速切换CPU的指令指针到系统调用处理入⼝。通过查找,发现是在syscall_init函数(此函数位于arch/x86/kernel/cpu/common.c中)中,将入口地址写入相关寄存器中的:
void syscall_init(void)
{
wrmsr(MSR_STAR, 0, (__USER32_CS << 16) | __KERNEL_CS);
wrmsrl(MSR_LSTAR, (unsigned long)entry_SYSCALL_64); //系统调用处理入口
......
}
该函数的调用顺序为:start_kernel() -> trap_init() -> cpu_init() -> syscall_init()。
也即是说,在内核启动的时候,将系统调用的入口地址写入的MSR寄存器,当触发系统调用的时候,syscall指令会自动使cpu的指令指针跳转到entry_SYSCALL_64的入口处。
然后,开始分析entry_SYSCALL_64内部具体做了什么。因为内容较多,先截取前半段保护现场的部分:
ENTRY(entry_SYSCALL_64)
UNWIND_HINT_EMPTY
/*
* Interrupts are off on entry.
* We do not frame this tiny irq-off block with TRACE_IRQS_OFF/ON,
* it is too small to ever cause noticeable irq latency.
*/
swapgs
/* tss.sp2 is scratch space. */
movq %rsp, PER_CPU_VAR(cpu_tss_rw + TSS_sp2)
SWITCH_TO_KERNEL_CR3 scratch_reg=%rsp
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(cpu_tss_rw + TSS_sp2) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip */
GLOBAL(entry_SYSCALL_64_after_hwframe)
pushq %rax /* pt_regs->orig_ax */
PUSH_AND_CLEAR_REGS rax=$-ENOSYS
TRACE_IRQS_OFF
/* IRQs are off. */
movq %rax, %rdi
movq %rsp, %rsi
call do_syscall_64 /* returns with IRQs disabled */
注意第9行的swapgs指令,将一些必要的寄存器值快速保存,起到了保护现场的作用(似乎是通过交换两个特定的msr寄存器的值实现的3,具体原理不清楚)。
另外,也通过pushq指令将一些需要的寄存器手动保存在栈中。接着,调用do_syscall_64来执行对应的系统调用。执行完系统调用后,就需要返回用户态继续执行用户程序了,在这之前需要恢复现场。在恢复现场之前,会进行异常检查,没问题后再通过USERGS_SYSRET64宏恢复现场并返回,其内容如下:
#define USERGS_SYSRET64 \
swapgs; \
sysretq;
通过swapgs指令恢复现场,再通过sysretq返回用户程序。
最后,来分析一下do_syscall_64函数。
__visible void do_syscall_64(unsigned long nr, struct pt_regs *regs)
{
struct thread_info *ti;
enter_from_user_mode();
local_irq_enable();
ti = current_thread_info();
if (READ_ONCE(ti->flags) & _TIF_WORK_SYSCALL_ENTRY)
nr = syscall_trace_enter(regs);
if (likely(nr < NR_syscalls)) {
nr = array_index_nospec(nr, NR_syscalls);
regs->ax = sys_call_table[nr](regs);
#ifdef CONFIG_X86_X32_ABI
} else if (likely((nr & __X32_SYSCALL_BIT) &&
(nr & ~__X32_SYSCALL_BIT) < X32_NR_syscalls)) {
nr = array_index_nospec(nr & ~__X32_SYSCALL_BIT,
X32_NR_syscalls);
regs->ax = x32_sys_call_table[nr](regs);
#endif
}
syscall_return_slowpath(regs);
}
nr为系统调用号,regs为传递参数的寄存器。这个函数主要是通过13行的sys_call_table[nr](regs)来执行对应的系统调用。而sys_call_table是利用脚本根据syscall_64.tbl表自动生成的。
asmlinkage const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_max] = &__x64_sys_ni_syscall,
#include
};
最后include的syscalls_64.h即为自动生成的,因此sys_call_table也就被初始化成与syscall_64.tbl中相对应的指向各个内核处理函数的数组了。
调用过程至此基本分析结束了,使虚拟机继续执行,test目录被成功删除。

系统调用总结
上面就是系统调用的执行过程,可能有点乱,在此做个总结。
首先,现代的cpu的msr寄存器中,有专门的寄存器用于保存系统调用入口地址,以加快系统调用的执行速度。在内核初始化的时候,就将入口地址写入了该寄存器中。另外,在编译的时候就将各个系统调用的函数指针按照顺序存入sys_call_table中。
当用户通过syscall进行系统调用的时候,cpu借助专用的msr寄存器跳转到系统调用函数处理入口。接着使用swapgs指令保存现场,并把一些swapgs没有保存的寄存器手动压栈保存,然后就通过上述的sys_call_table执行对应的系统调用函数。执行完毕后,再通过swapgs指令恢复现场,通过sysretq指令返回用户程序。至此,依次系统调用就执行完毕了。
参考
- KASLR
- Linux syscall过程分析(万字长文)
- x86 SWAPGS