吴恩达Coursera深度学习课程 deeplearning.ai (4-2) 深度卷积网络:实例探究--课程笔记
本课主要讲解了一些典型的卷积神经网络的思路,包括经典神经网络的leNet/AlexNet/VGG, 以及残差网络ResNet和Google的Inception网络,顺便讲解了1x1卷积核的应用,便于我们进行学习和借鉴。
2.1 为什么要进行实例探究
神经网络有些是相通的,学习他人是如何构建神经网络的,对自己也是一个提升。
- 经典神经网络
- LeNet-5:针对灰度图像,conv-pool-conv-pool-fc-fc-output,使用avg池化和sigmoid激活函数。
- AlexNet:针对彩色图像, 参数更多,使用max池化、Relu激活函数和softmax的output。
- VGG:使用3×3,stride=1,SAME的卷积和2×2,stride=2 减半的池化。
- ResNet:残差网络,将a[l]同时作为a[l+2]的参数,减少衰减。
- Inception: 分别运用SAME方式的各个不同大小的卷积核和SAME的池化层,最后将结果叠加起来, 多个Inception 模块的堆叠构成Inception Network。
2.2 经典网络
经典卷积神经网络:LeNet, AlexNet, VGGNet
LeNet-5
LeNet-5主要是针对灰度设计的,所以其输入较小,为32×32×1,其结构如下:
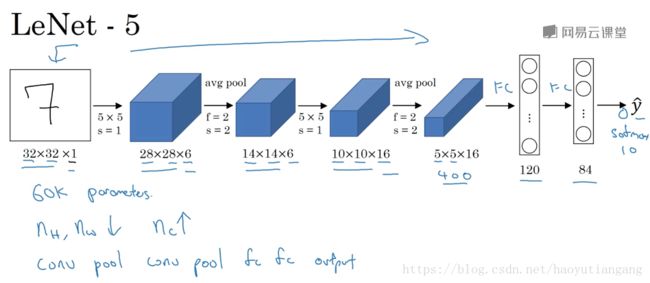
在LetNet中,存在的经典模式:
- 随着网络的深度增加,图像的大小在缩小,与此同时,通道的数量却在增加;
- 每个卷积层后面接一个池化层。
AlexNet
AlexNet直接对彩色的大图片进行处理,其结构如下:
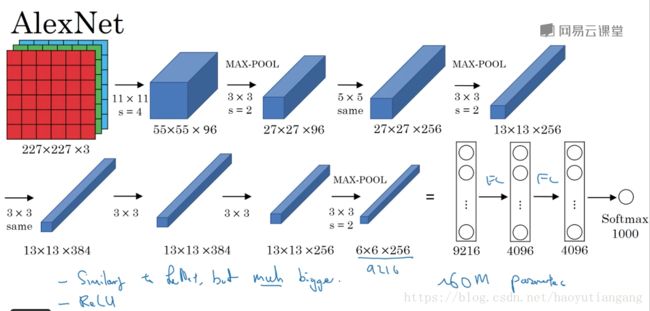
- 与LeNet相似,但网络结构更大,参数更多,表现更加出色;
- 使用了Relu;
- 使用了多个GPUs;
- LRN(后来发现用处不大,丢弃了)
AlexNet使得深度学习在计算机视觉方面受到极大的重视。
VGG-16
VGG卷积层和池化层均具有相同的卷积核大小,都使用3×3,stride=1,SAME的卷积和2×2,stride=2 的池化。其结构如下:

[CONV 64] x2: 表示每层用64个卷积核,重复两次
2.3 残差网络
残差块
将A[l]跳过一层或几层增加到A[l+c]层的输入(线性之后,非线性之前),从A[l]到A[l+c]这个范围共同构成一个残差块(Residual Block)
跳转连接称为: short cut/skip connection
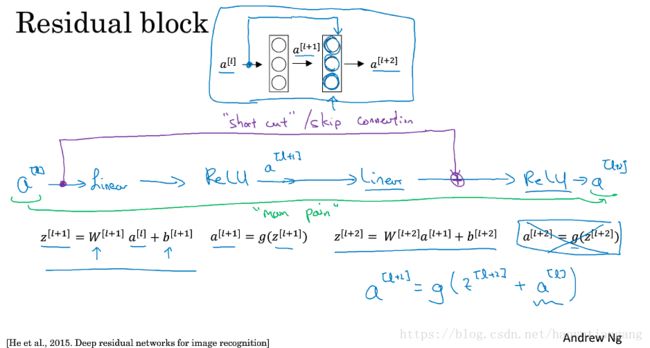
残差网络及其表现
由残差块构建的神经网络成为残差网络(ResNet)
- 在没有残差的普通神经网络中,训练的误差实际上是随着网络层数的加深,先减小再增加;
- 在有残差的ResNet中,即使网络再深,训练误差都会随着网络层数的加深逐渐减小。

ResNet对于中间的激活函数来说,有助于能够达到更深的网络,解决梯度消失和梯度爆炸的问题。
2.4 残差网络为什么有用
通常,随着网络深度的加大,训练的错误可能会越来越多,效果越来越差,也即a[l+2]层的效果可能还不如a[l]层的效果好。
使用L2正则化或者权重衰减,会压缩W和b的值,如果 W = 0,b = 0, 那么a[l+2] = a[l]
可以看到,增加了残差块的网络,a[l+2] 即使没有学到内容,也不会比a[l]更差,如果学到了内容,则进一步提升了效果。
- 由于 a[l+2] = g(z[l+2] + a[l])
- 一般要求 a[l]与a[l+2]具有相同的维度
- 利用same卷积方式保持维度不变。
如果a[l]与a[l+2]维度不一样,则需要给a[l]乘上一个矩阵转变成 W_s x a[l]的维度与a[l+2]一致。
2.5 网络中的网络以及 1x1 卷积
1x1 conv 又称为 network in network
1x1 conv
- 图像只有一个通道时,仅相当于乘以一个数(卷积核的值),用处不大
图像有多个通道时,相当于每次输入为1x1xn_c, 相当于一个深度切片,输出为每个通道的对应值与卷积核的对应值点乘家和再relu后的值。
1×1卷积核相当于对一个切片上的 nc n c 个单元都应用了一个全连接的神经网络
- 多个不同的卷积核则相当于下层多个节点与输入层的全连接神经网络
应用
- 改变通道数:可以用于在保持图片长/宽不变的情况下,通过1x1的卷积核的数量来压缩/扩充/保持图片的通道数
- 增加非线性:保持与原维度相同的1×1的卷积核个数,再维度不变的情况下增加了非线性。

2.6 谷歌 Inception 网络简介
结构简介
- 功能: 代替人工决定卷积核的大小以及是否需要添加池化层
- 实现: 分别运用SAME方式的各个不同大小的卷积核和SAME的池化层,最后将结果叠加起来。

通过保持维度的各种叠加,增加了通道的数量。
降低计算成本
对于上面的5×5大小卷积核的计算成本:输出*卷积核 = 120M
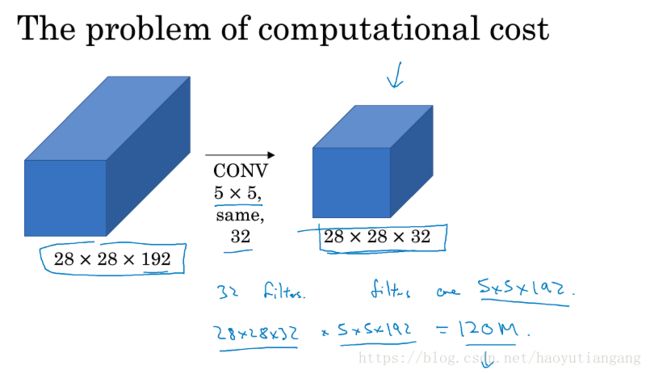
可以增加中间层(瓶颈层bottle-neck),利用1x1xc 先将图片的深度进行压缩(长/宽不变),然后再进行inception从而减少计算量。

添加瓶颈层后计算量: 输出1*卷积核1+输出2*卷积核2 = 12.4M, 计算量变为原来的十分之一。
事实证明,只要合理地设置“bottleneck layer”,既可以显著减小上层的规模,同时又能降低计算成本,从而不会影响网络的性能。
2.7 Inception 网络
Inception 块
将上面说介绍的两种主要思想和模式结合到一起构成 Inception 模块

- 1x1 层不需要再加1x1了
- 其他卷积核层(3x3,5x5,7x7)都是先用1x1压缩图片深度,再进行卷积核操作的
- 池化层利用Padding达到SAME,不过由于池化层针对每个通道,所以深度不变,需要在池化之后添加1x1降低深度。
Inception 网络
多个Inception 模块的堆叠构成Inception Network,下面是GoogleNet的结构

注意:Inception网络不只包含各个Inception块,中途和最后都包含了一些全连接到输出softmax来保证结果不会过拟合。
2.8 使用开源的实现方案
当你准备实现一个神经网络或者再看一篇论文时,先搜索一下类似的开源项目(比如在github上),拿到他们的代码,通常会比你自己从头训练要快的多,因为他们已经经过长时间的训练,可以供我们进行迁移学习。
2.9 迁移学习
利用别人类似开源项目中的神经网络结构和参数训练我们自己的网络,在计算机识别领域用处广泛。
网上有很多开源的数据集:ImageNet/MS COCO/Pascal
小数据集
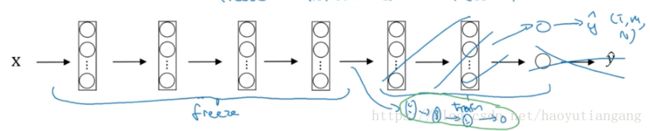
- 冻结所有隐藏层,利用已有的网络隐藏层,仅训练自己的输出层。
- 可以将数据输入,将隐藏层的输出存到硬盘上,然后利用这些数据来训练仅有输出层的简单网络,避免每次训练都遍历原始输入数据

大数据集
- 冻结前面的部分隐藏层,后面的隐藏层加上自己的隐藏层(可以没有)和输出层用来训练,需要训练的这些隐藏层的初始值设置为别人训练好的参数值。
- 数据量越大则冻结的隐藏层越少,需要自己训练的隐藏层越多。
超大数据集
- 所有的网络参数都重新训练,将网络各层的初始值设置为别人训练好的参数值。
- 很少从头自己训练,除非有超大量的数据集和超大量的运算预算。

2.10 数据扩充
与其他机器学习问题相比,在计算机视觉领域当下最主要的问题是没有办法得到充足的数据。
数据扩充的方法
- 垂直镜像对称(Mirroring)
- 随机剪裁(Random Cropping)
- 色彩转换(Color shifting) 给RGB三个通道分别加减一些值。如 RGB(+20,-20,+20)
- PCA颜色增强:对图片的主色的变化较大,图片的次色变化较小,使总体的颜色保持一致。
其他一些不常用的方法
- 旋转(Rotation)
- 变形(Shearing)
- 局部弯曲(Local warping)
数据扩充实践
一个线程用来变形数据,然后传给其他线程进行神经网络训练,可以并行执行。

2.11 计算机视觉现状
机器学习获取知识的两种方式:
- 标记数据,(x,y);
- 手工特征工程/网络结构/其他构建。
- 大量数据时更倾向于使用简单的算法和更少的手工工程
- 在有少量数据的时候,我们从事更多的是手工工程。
在基准研究和比赛中,下面的tips可能会有较好的表现:
- Ensembling:独立地训练多个网络模型,输出平均结果或加权平均结果;
- 测试时的 Multi-crop:在测试图片的多种版本上运行分类器,输出平均结果。
- 10-crop