详解nginx原理与反向代理、负载均衡实战
文章目录
- 相关基础
- 事件驱动模型详解
- 三种编程模型的比较
- 事件驱动模型I/O为什么不阻塞呢
- I/O结束怎么切换回来
- 事件驱动模型逻辑图
- I/O多路复用
- 概念说明
- 用户空间与内核空间
- 文件描述符
- 缓存I/O
- socket粘包也是因为缓存I/O?
- IO模型
- 阻塞IO
- 非阻塞I/O
- IO多路复用
- select
- poll
- epoll
- nginx介绍
- nginx的请求处理流程
- Apache与nginx的区别
- 为什么nginx支持高并发
- nginx实战
- Nginx的组成部分
- nginx的语法配置规则
- 使用信号管理nginx父子进程
- nginx重载配置文件文件的真相
- 反向代理
- 负载均衡
- 动静分离
- nginx原理与优化参数
- nginx的master-workers机制的好处
相关基础
事件驱动模型详解
通常,我们写服务器处理模型的程序时,有以下几种模型:
- (1)每收到一个请求,创建一个新的进程,来处理该请求;
- (2)每收到一个请求,创建一个新的线程,来处理该请求;
- (3)每收到一个请求,放入一个事件列表,让主进程通过非阻塞I/O方式来处理请求
上面的几种方式,各有千秋,
- 第(1)中方法,由于创建新的进程的开销比较大,所以,会导致服务器性能比较差,但实现比较简单。
- 第(2)种方式,由于要涉及到线程的同步,有可能会面临死锁等问题。
- 第(3)种方式,在写应用程序代码时,逻辑比前面两种都复杂。
综合考虑各方面因素,一般普遍认为第(3)种方式是大多数网络服务器采用的方式
什么是事件驱动模型
事件驱动模型是指:有一个事件队列,或者说消息队列,我们的事件源往这个队列里面添加任务,然后有个循环,一直在这个队列里面取出事件,根据不同的事件调用不同的函数,就叫事件驱动模型,它是一种编程范式。
我们的UI编程,大部分都是事件驱动模型,比如我们写JavaScript的onClick(),鼠标按下的时候,鼠标点击的事件添加到队列里面,然后取到这个事件后,调用onClick()函数。如下图

让我们用例子来比较和对比一下单线程、多线程以及事件驱动编程模型。下图展示了随着时间的推移,这三种模式下程序所做的工作。这个程序有3个任务需要完成,每个任务都在等待I/O操作时阻塞自身。阻塞在I/O操作上所花费的时间已经用灰色框标示出来了。

三种编程模型的比较
单线程模型是阻塞的,如果每个任务之间都是没有关联的,很显然它降低了运行速度,因为只要一个任务阻塞了,其他任务都要等待,等它运行完,其他任务才能运行,阻塞的这段时间严重影响了运行速度。
多线程模型,多个任务分别在多个独立的线程之间执行,程序最终的运行时间约等于运行时间最长的那个线程。多线程模型在多处理器的系统中可以并行执行,在单处理器系统中交错执行,这使得当某个线程阻塞的时候,其他线程可以继续执行,但是当多个线程同时修改同一份数据的时候,往往要考虑线程安全问题,必须写代码保护共享数据,防止被多个线程同时访问,,需要加锁等机制处理线程安全问题
事件驱动模型里面3个任务交错执行,但是还是在同一个线程里面(协程),当处理I/O或者其他昂贵的操作时,注册一个回调到事件循环中,然后当I/O操作完成时继续执行。简单来讲,事件驱动模型是一遇到IO就注册一个事件,然后主程序就可以干其他事情,直到IO处理完,继续恢复之前中断的任务。
事件驱动模型I/O为什么不阻塞呢
因为IO操作是用操作系统完成的,咋们用户读一个文件,并不是我们自己的程序打开一个文件,然后去把文件的内容读出来。而是操作系统的调度接口打开这个文件,然后把这个数据读会开,其实是操作系统负责IO的控制。
I/O结束怎么切换回来
加一个回调函数,就是我去切换之前,调操作系统IO接口的时候,告诉操作系统,说你处理完了之后,调一下这个回调函数,这个回调函数就会通知我,通知我了就代表执行完了,我就回来把这个IO拿到了,所以就是通过这个事件驱动的方式。出现这个IO操作,我就注册这个事件,就是IO事件交给操作系统,操作系统内部有一个队列,处理完了吧结果返回给你,通知回调函数通知你。
事件驱动模型逻辑图

I/O多路复用
概念说明
用户空间与内核空间
为了保证用户不能直接操作操作系统的内核,保证内核的安全,操作系统把虚拟空间分成内核空间和用户空间,这个划分不是一刀切的,而是通过CPU指令集里面的寄存器的状态位来区分的,在CPU里面有一块指令集,这个指令集里面有一个寄存器,这个寄存器的状态位是0,代表是内核态,是1代表是用户态
文件描述符
文件描述符是指向文件引用的概念,文件描述符在形式上一般是一个非负整数,其实他是一个索引值,当程序打开一个文件,或者创建一个文件的时候,内核会向进程返回一个文件描述符
缓存I/O
缓存I/O又叫标准I/O,大多数文件系统的默认I/O操作都是缓存I/O,在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据要先copy到操作系统内核的缓冲区,然后才会从操作系统内核冲区copy到应用程序的地址空间
缓存I/O的缺点:数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的
socket粘包也是因为缓存I/O?
为了减少从内核态到用户态的数据来回的copy,因为如果你打开一个文件,你读到内存里,你以为是直接读到你的用户的内存里面,其实是先读到缓存里面,也就是内核的缓存里面,然后再由内核帮你把这份数据copy到用户的内存里面。就是为了避免这里的来回copy,耗资源,这样的话效率就高。
IO模型
阻塞IO
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:

当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
非阻塞I/O
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:

当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。,返回error,用户进程就知道数据还没有准备好,就可以去处理其他任务了,然后过一小段时间,它再次发送read操作,如果内核的数据准备好了,就可以把数据copy到用户空间,返回给用户进程。
特点:它的特点是,相比阻塞IO,在等待数据的这个阶段是不阻塞的,因为它收到error之后,就可以处理其他任务,然后再次发送read操作,当然它的那个从数据从内核空间copy到用户空间这个过程还是阻塞的。
它的缺点是发了很多次的系统调用,用户进程需要不断地去询问内核,说,内核你的数据准备好了吗,这是它的缺点
IO多路复用
IO multiplexing就是我们说的select,poll,epoll,select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。

当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
说明:IO多路复用中包括 select、pool、epoll,这些都属于同步,还不属于异步。
select
select:select最早于1983年出现在4.2BSD中,它通过一个select()系统调用来监视多个文件描述符的数组,但调用select()会对所有socket进行一次线性扫描,所以这也浪费了一定的开销。也就是说,假设select监视100个连接,这100个连接其中一个有数据了,到底是谁,不知道,只自己循环一遍
poll
poll:它和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制。他是一个过渡。
epoll
epoll:epoll是Linux2.6以上的内核才支持的,window不支持epoll,只支持select,epoll它使用了事件的就绪通知方式,只去循环活跃的连接,不像select一样,所有监视的连接都去循环一遍,所以效率很高,
nginx介绍
nginx是高性能的web服务器,相比Apache,它可以支持更大的并发,资源占用小,支持异步模型epoll,因为他的性能,经常用做负载均衡,反向代理服务器。
nginx的请求处理流程
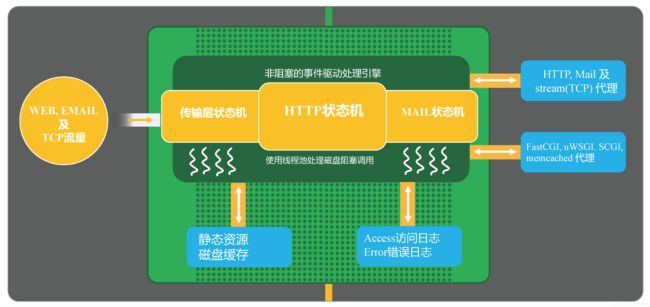
由上图,我们的请求流量主要分为三类,WEB,EMAIL和TCP,在nginx中有三个状态机,传输层状态机,HTTP状态机,以及MAIL状态机,因为 Nginx 核心的这个大绿色的框他是用非阻塞的事件驱动处理引擎就是用我们所熟知的 epoll,那么一旦我们使用这种异步处理引擎以后,通常都是需要用状态机来把这个请求正确的识别和处理。
基于这样的一种事件状态处理机,我们在解析出请求需要访问静态资源的时候,我们看到走左下方的这个箭头,那么它就找到了静态资源,如果我们去做反向代理的时候呢,那么对反向代理的内容,我可以做磁盘缓存,缓存到磁盘上,也在下面左下方这条线,但是我们在处理静态资源的时候,会有一个问题就是当整个内存已经不足以完全的缓存所有的文件和信息的时候,那么像 send File 这样的调用或者 AIO 会退化成阻塞的磁盘调用,所以在这里我们需要有一个线程池来处理,对于每一个处理完成的请求呢,我们会进入 access 日志或 error 日志。
那么这里也是进入了磁盘中的,当然我们可以通过 syslog 协议把它进入到远程的机器上,那么更多的时候我们的 Nginx 是作为负载均衡或者反向代理来使用的,就是我们可以把请求通过协议级(HTTP,Mail 及 stream(TCP))传输到后面的服务器,也可以通过例如应用层的一些协议(FastCGI、uWSGI、SCGI、memcached)代理到相应的应用服务器。以上就是 Nginx 的请求处理流程。
Apache与nginx的区别
参考:
Apache与nginx有什么区别
apache与nginx区别总结
Apache和Nginx最核心的区别在于 apache 是同步多进程模型,一个连接对应一个进程;而 nginx 是异步的,多个连接(万级别)可以对应一个进程,
Apache:
缺点:资源占用率高,并发性能差
优点:
- 稳定,Apache最主要的优点是稳定,bug少,它出现要比nginx早。
- rewrite功能强大,Apache的rewrite功能比nginx强大。
- 模块多
原理:使用阻塞+多进程
nginx
优点:
- 抗并发能力强,但是没有LVS强
- 模块丰富
- 可以做http反向代理及加速缓存,即负载均衡
- 支持异步IO模型epoll
原理:使用IO多路复用,Epoll
为什么nginx支持高并发
相比Apache,nginx的并发能力非常强,Apache一般超过一万个并发,就很难抗的住,但是nginx一般情况下,500万并发是
nginx实战
Nginx的组成部分
- nginx二进制可执行文件,由各个模块的源码编译出来的文件,nginx最好使用源码安装,这样我们可以选择使用什么模块

nginx的语法配置规则
1.nginx配置文件的语法规则
- nginx的配置文件由指令和指令块组成
- 指令块通过{}把指令组织起来
- 指令之间以分号分隔
- nginx的配置文件可以使用include指令把其他配置文件引用进来,组合多个配置文件来提高可维护性
- nginx的变量使用$,注释使用#
- 部分指令的参数支持正则表达式
2.nginx的指令块
根据下面nginx的配制文件代码,可以很明显的分为三个部分
nginx的四个指令块
- http
- server
- location
- upstream
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
使用信号管理nginx父子进程
- Master进程是主进程,不用来处理连接,它主要做一些特权级别的操作,比如重载配置文件,管理worker进程等等,它通过CHLD信号监控worker进程,因为worker进程终止的时候,会向它的父进程也就是master进程发送CHLD信号,如果worker进程有一些模块出现了bug,导致worker进程终止掉,那么master进程可以立刻通过CHLD发现这个事件,然后重新把worker进程拉起,
- master进程可以接受的信号有TERM,INT(立刻关闭),QUIT优雅关闭,HUP重新加载配置文件,USR1重新打开配置文件,做日志文件切割,USR2和WINCH只能用kill发送信号,没有对应的命令行,这两个是专门针对做热部署的
- worker进程也可以接受信号,一般情况下,我们不直接向它发送信号,worker进程接收的master进程的信号。

nginx重载配置文件文件的真相
反向代理
反向代理的配置是在location区块里面使用proxy_pass 指令进行配置。
我这里有两台虚拟机做实验,第一台IP为10.10.31.8,配置了Apache服务。

然后现在我使用另一台虚拟机(IP为10.10.31.10),配置nginx服务,使用proxy_pass 指令,当我们访问10.10.31.10的时候,把请求转给10.10.31.8

进行访问测试,访问10.10.31.10跳转到了10.10.31.8,实现了反向代理的功能

反向代理实验二

负载均衡
因为我的配置文件配置了比较多东西,所以直接贴核心代码给大家。
负载均衡配置是在http块里面使用upstream指令,在upstream指令后面写我们这个负载均衡集群的名字
# 负载均衡配置
upstream myserver{
ip_hash;
server 10.10.31.28:80 weight=1;
server 10.10.31.26:80 weight=2;
}
然后在server块里面使用upstream定义的集群的名字,注意这里要对应,不然会访问不到的。
location / {
proxy_pass http://myserver;
proxy_connect_timeout 10;
动静分离
动静分离指的是将动态请求和静态请求分开,一般有两种方法配置,一种是把静态文件独立成单独的域名,放在独立的服务器上,(比较推崇的方式),另一种是动态和静态内容在同一个服务器上,通过location指定不同的后缀名来分开,下面配置的重点是增加了一个location配置
location /www/ {
root /data/;
index index.html index.htm;
}
location /image/ {
root /data/;
autoindex on;
}
nginx原理与优化参数
nginx的master-workers机制的好处
首先,对于每个 worker 进程来说,独立的进程,不需要加锁,所以省掉了锁带来的开销,同时在编程以及问题查找时,也会方便很多。其次,采用独立的进程,可以让互相之间不会
影响,一个进程退出后,其它进程还在工作,服务不会中断,master 进程则很快启动新的 worker 进程。当然,worker 进程的异常退出,肯定是程序有 bug 了,异常退出,会导致当前 worker 上的所有请求失败,不过不会影响到所有请求,所以降低了风险。