深度学习用于机器翻译的论文及代码集锦
[1] Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
Kyunghyun Cho et al.
Universite de Montr ´ eal ´
EMNLP 2014
https://www.aclweb.org/anthology/D14-1179
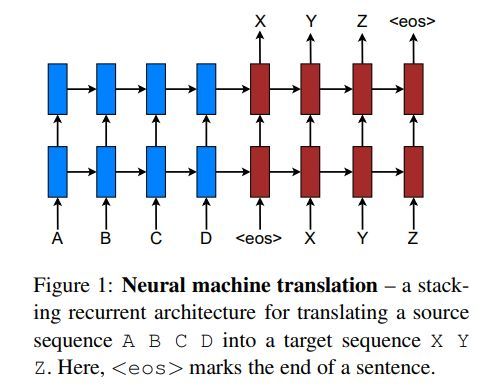
这篇文章提出由两个RNN构成的RNN Encoder-Decoder网络。其中一个RNN将符号序列编码成固定长度的向量表示,另一个RNN将向量表示解码成另一个序列。编码解码联合训练来最大化给定序列得到目标序列的条件概率。
RNN Encoder-Decoder结构示例如下
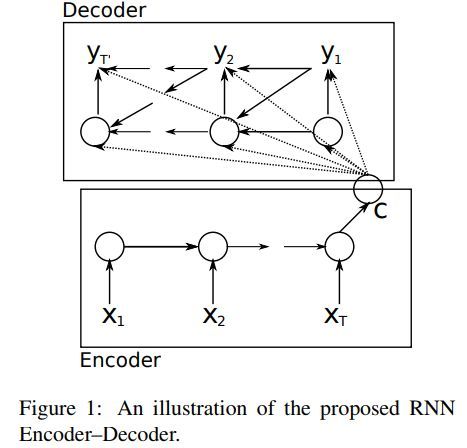
本文所提出的激活函数示例如下
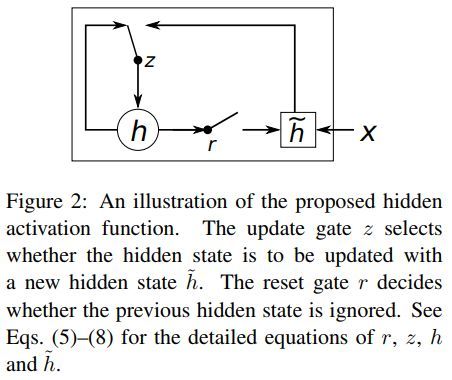
各模型结果对比如下
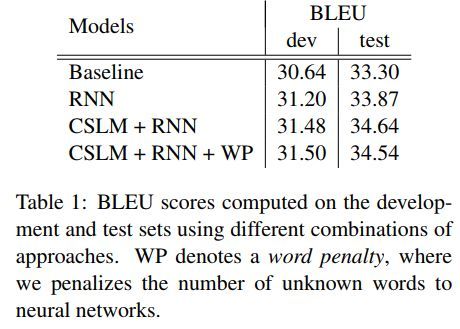
代码地址
https://github.com/pytorch/tutorials/blob/master/intermediate_source/seq2seq_translation_tutorial.py
 我是分割线
我是分割线
[2] Sequence to Sequence Learning with Neural Networks
Ilya Sutskever et al.
NIPS 2014
https://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf
这篇文章给出一种端到端的序列学习的方法。该方法利用多层LSTM将输入序列映射到固定维度的向量,然后利用深层的LSTM将向量解码到目标序列。
流程示例如下
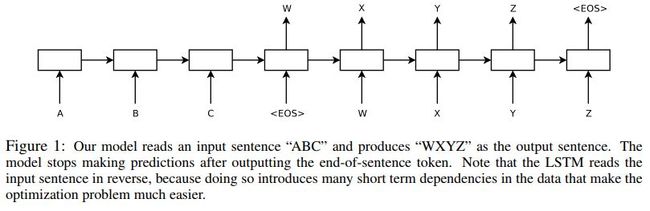
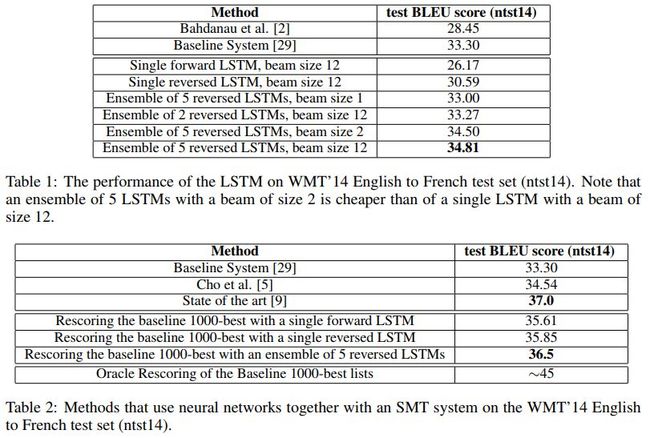
各模型效果对比如下
代码地址
https://github.com/farizrahman4u/seq2seq
我是分割线
[3] Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Yonghui Wu et al.
https://arxiv.org/pdf/1609.08144.pdf
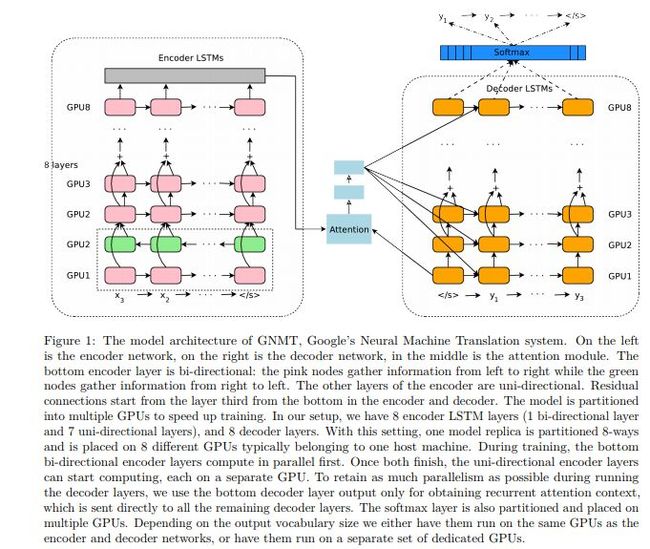
这篇文章提出了GNMT,谷歌神经机器翻译系统。该模型包含由八层编码和八层解码的深层LSTM构成,其中编码和解码用残差来连接,同时利用注意力连接。为提升并行效率缩减训练时间,注意力机制只将底层的解码层和顶层的编码层连接起来。为加速翻译速度,在推理过程中牺牲了准确率。为处理罕见词,针对输入和输出都将词进行分割,得到由公共子词构成的有限集合。这种方法能够自然的处理罕见词的翻译,提高系统的整体准确率。在beam search技巧中利用长度归一化并且利用覆盖率惩罚因子,这种做法能够使得输出句子更有可能覆盖原句中的所有单词。
网络结构如下
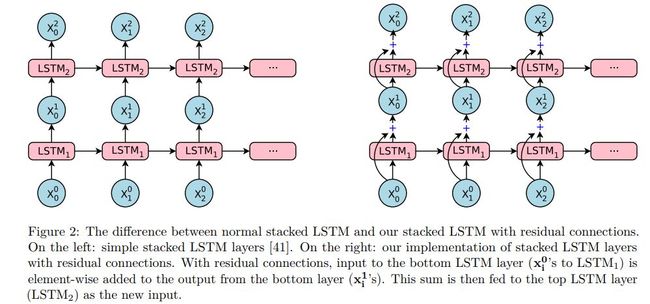
带有残差的LSTM和一般的LSTM区别如下
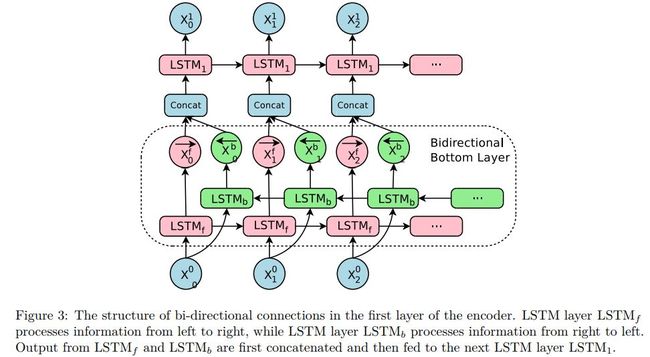
双向LSTM示例如下
CPU GPU TPU影响如下

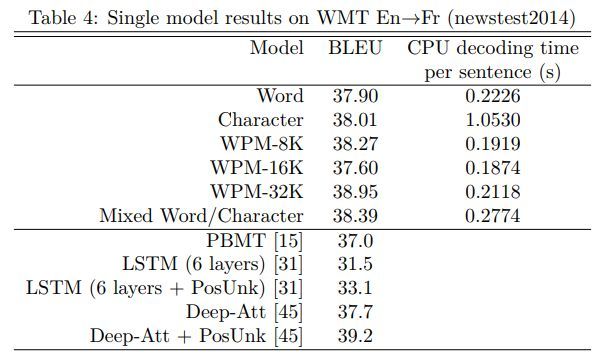
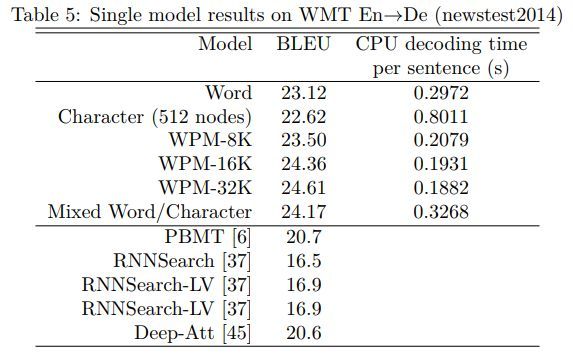
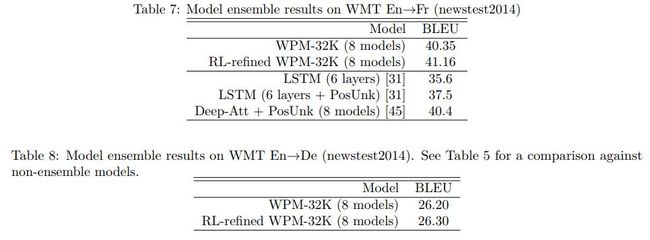
各模型效果对比如下
代码地址
https://github.com/tensorflow/nmt
我是分割线
[4] Effective Approaches to Attention-based Neural Machine Translation
Minh-Thang Luong
Stanford University
EMNLP 2015
http://aclweb.org/anthology/D15-1166
这篇文章利用注意所有源词的全局方法和每次利用源词子集的局部方法来训练模型。
神经机翻译示例如下
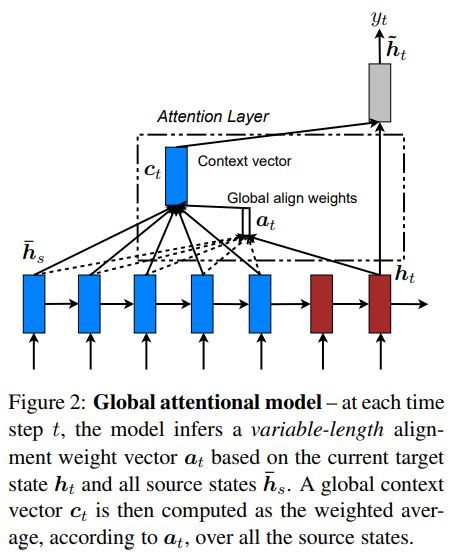
全局注意力模型如下
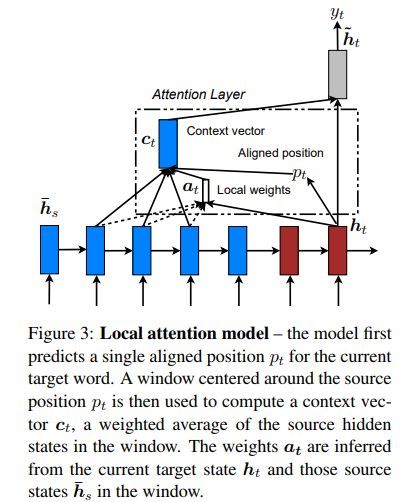
局部注意力模型如下
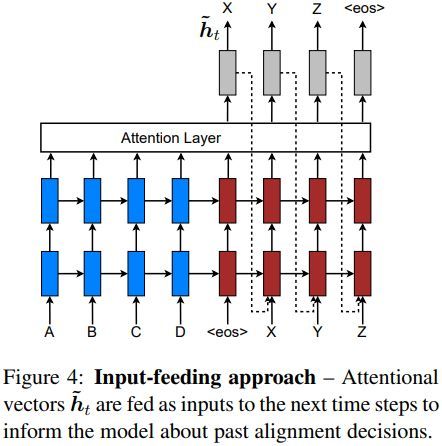
注意力向量作为下一步的输入示例如下
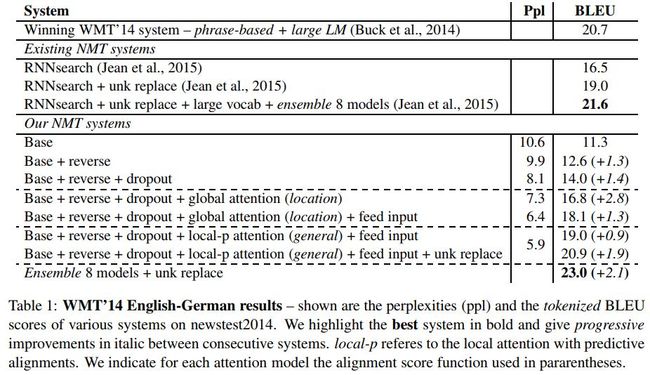
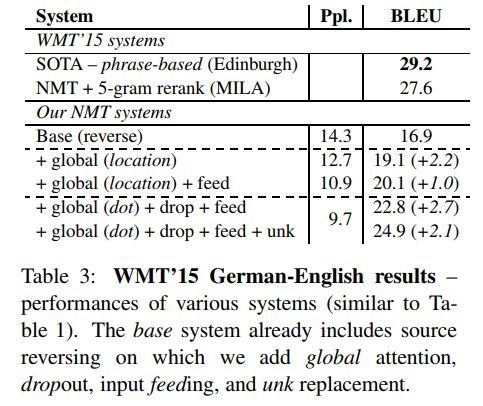
各方法效果对比如下
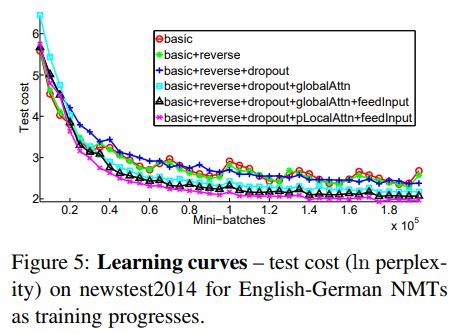
学习曲线示例如下
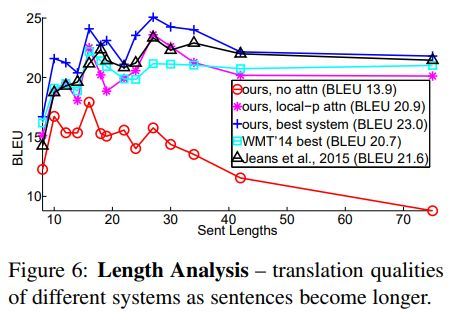
句子长度的影响如下
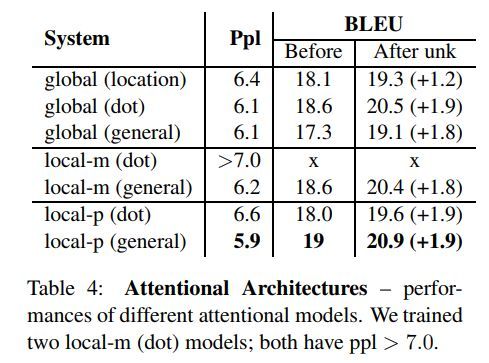
不同注意力结果如下
代码地址
https://github.com/mohamedkeid/Neural-Machine-Translation
https://github.com/lmthang/nmt.hybrid
我是分割线
[5] Convolutional Sequence to Sequence Learning
Jonas Gehring
Facebook AI Research
ICML 2017
http://proceedings.mlr.press/v70/gehring17a/gehring17a.pdf
该文的网络结构完全基于CNN,跟循环模型相比,训练时可以并行,更好地利用GPU硬件,并且非线性个数是固定的。另外,门限线性单元有利于梯度传播,并且每个解码层都有相应的注意力模块。
模型结构如下
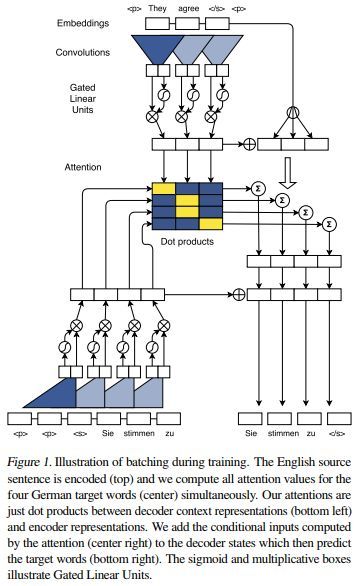
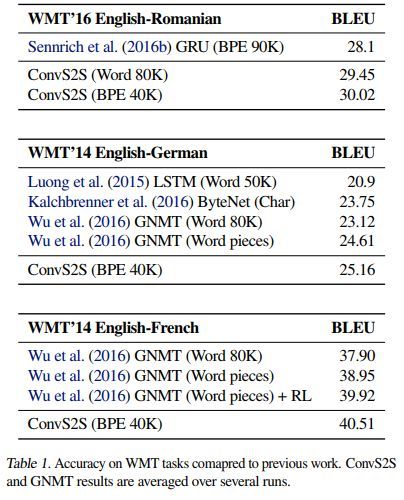
各方法结果对比如下
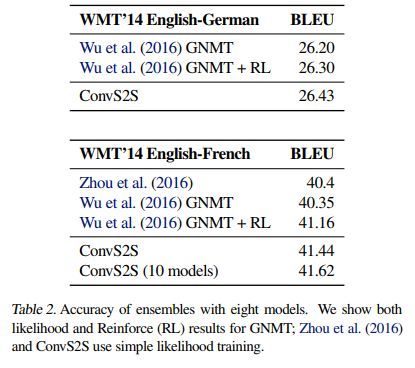
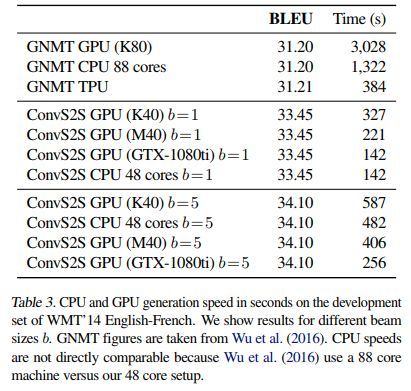
CPU GPU TPU 影响如下
注意力机制对模型结果影响如下
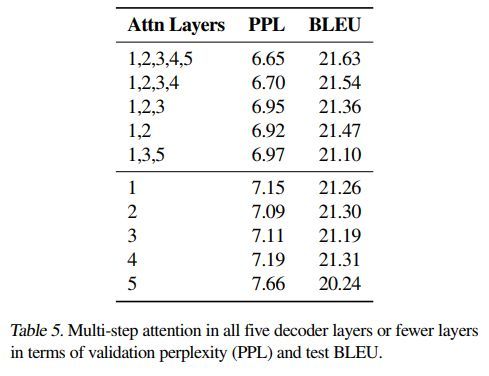
层数对模型结果影响如下
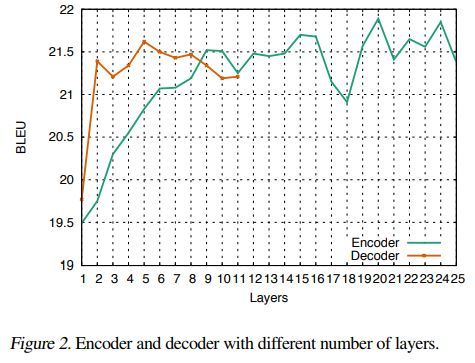
核的宽度影响如下
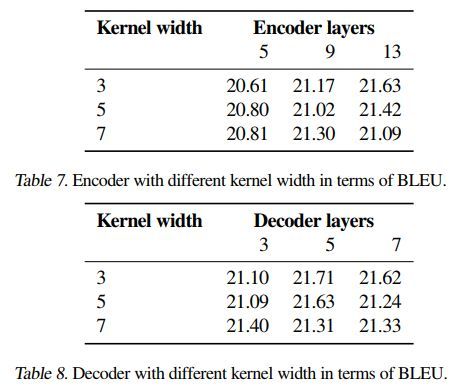
代码地址
https://github.com/facebookresearch/fairseq
https://github.com/pytorch/fairseq
我是分割线
[6] Attention Is All You Need
Ashish Vaswani
NIPS 2017
https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
这篇文章提出一种新的网络结构,Transformer,这种结构只基于注意力机制,完全避免了循环和卷积。
网络结构如下
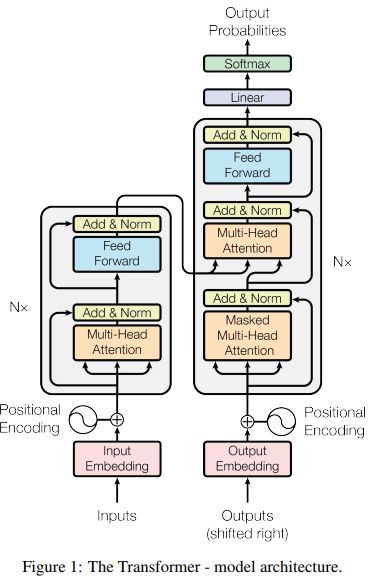
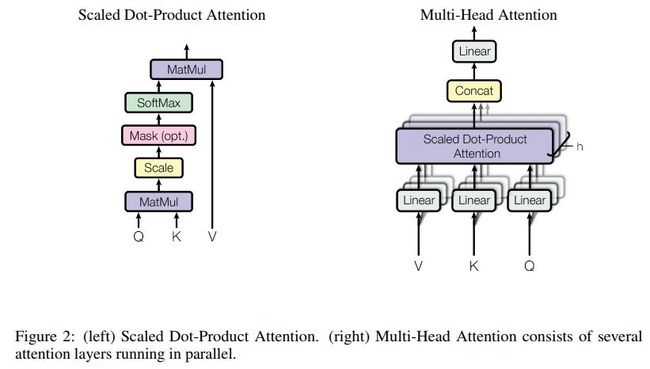
两种注意力结构如下
各类型复杂度对比如下

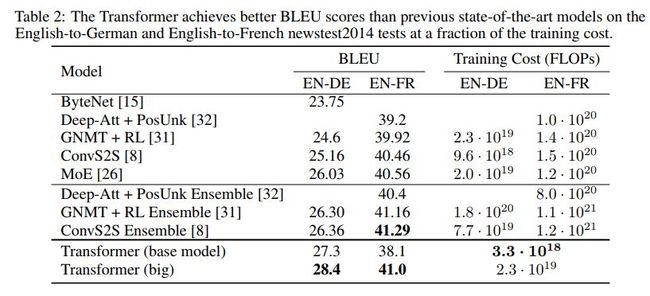
各模型结果对比如下
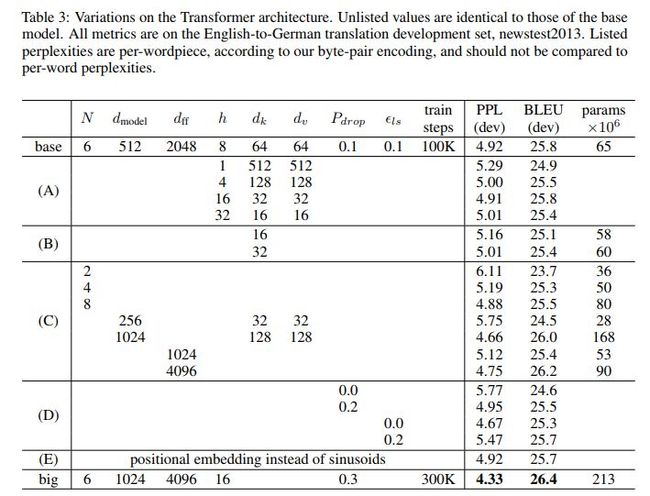
不同结构的Transformer对比如下
代码地址
https://github.com/tensorflow/tensor2tensor
https://github.com/Kyubyong/transformer
https://github.com/jadore801120/attention-is-all-you-need-pytorch
https://github.com/Lsdefine/attention-is-all-you-need-keras
我是分割线
您可能感兴趣