ICML2018|基于自注意力的序列推荐模型SASRec(已开源)
Self-Attentive Sequential Recommendation
Wang-Cheng Kang, Julian McAuley
UC San Diego
https://cseweb.ucsd.edu/~jmcauley/pdfs/icdm18.pdf
很多现代推荐系统中序列动力学是一种重要特征,序列动力学能够根据用户最近的行为来捕捉用户行动的上下文环境。
现行有两种比较流行的方法来捕捉这种模式,一种是马尔可夫链,一种是循环神经网络。马尔可夫链假设用户的下一个行为可以基于用户的最近一次或者最近几次的行为来预测,循环神经网络在原理上可以发现较长周期的语义信息。
一般而言,基于马尔可夫链的方法在非常稀疏的数据集上效果最好,循环神经网络在比较稠密的数据集中效果较好,模型复杂度也较高。
这篇文章的目标在于对上述两种方法的优势进行平衡,提出一种自注意力序列模型(SASRec),该模型可以像循环神经网络一样捕捉较长的语义信息,不同的是,加入了注意力机制,这就使其能够基于相对较少的行为来作出预测,这一点有点类似马尔可夫链。
每一步中,SASRec从用户行为历史中寻找比较相关的商品,并且利用它们来预测下一个商品。
大量实验表明,本文方法在稀疏和稠密数据集上的效果优于其他STOA序列模型,比如基于马尔可夫链的方法,基于卷积神经网络的方法,以及基于循环神经网络的方法。
并且,该模型相对基于CNN或RNN的模型效率高一个数量级。针对注意力权重的可视化表明了本文模型能够自适应处理多种数据,在行为序列中也能发现比较有意思的模式。
这篇文章的思想源于Transformer

整体结构图示如下

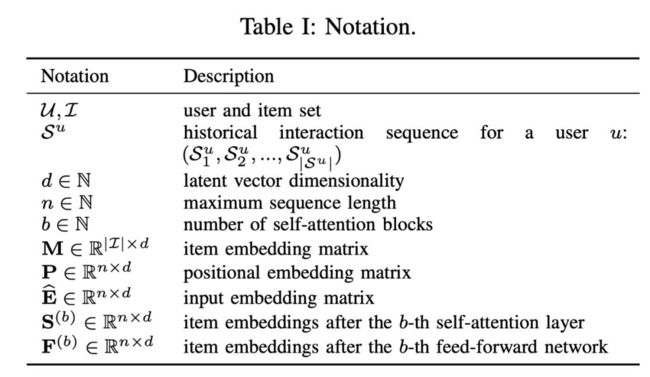
下面是一些符号约定
嵌入部分考虑了位置因素

缩放后的点积注意力定义形式如下

自注意力层形式如下

基于因果关系的改进方式如下

点式前向神经网络形式如下

得到堆叠自注意力块的方式如下

为了缓解过拟合和梯度弥散问题,作者们利用了层内归一化和dropout策略

残差连接的作用在于更好的传递低层特征

层归一化的具体形式如下

dropout的解释如下

作者们利用矩阵分解来预测得分

共享商品嵌入不仅可以降低模型复杂度,还可以缓解过拟合

目标函数及训练方法如下

其中ot的定义形式如下
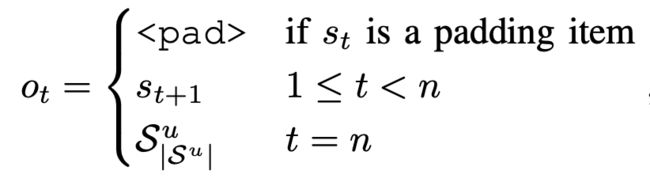
时间复杂度上的优势在于

一些相关方法有以下几个

SASRec跟这些方法的联系在于

SASRec也可以变换成FISM

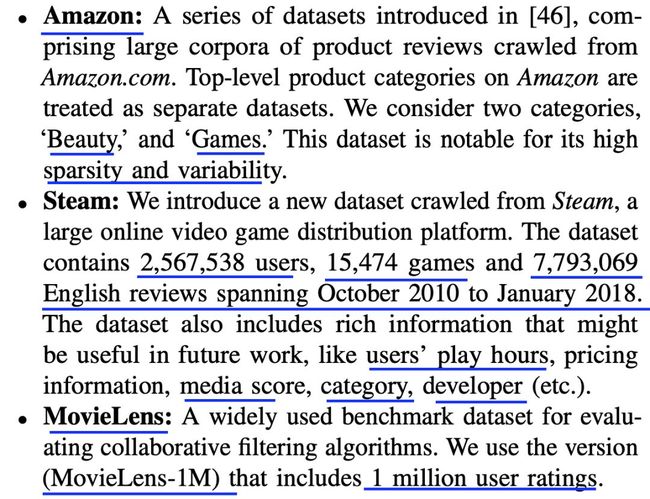
数据集信息统计如下

数据集处理及分割方式如下

参与对比的几种方法简介如下



一些参数设置如下


衡量标准有以下两个

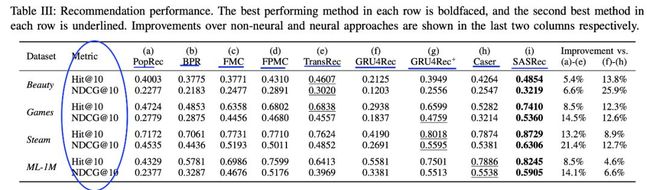
结果对比如下
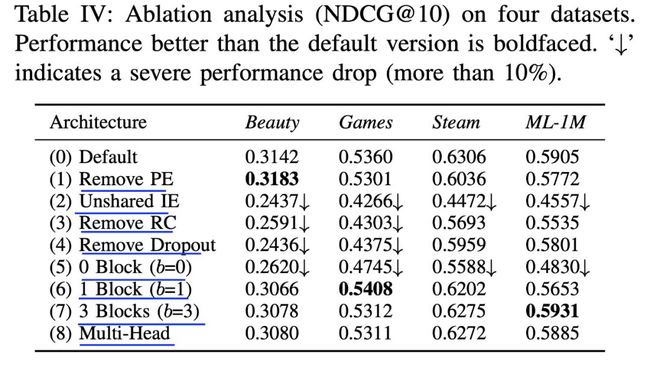
几种子结构的影响对比如下
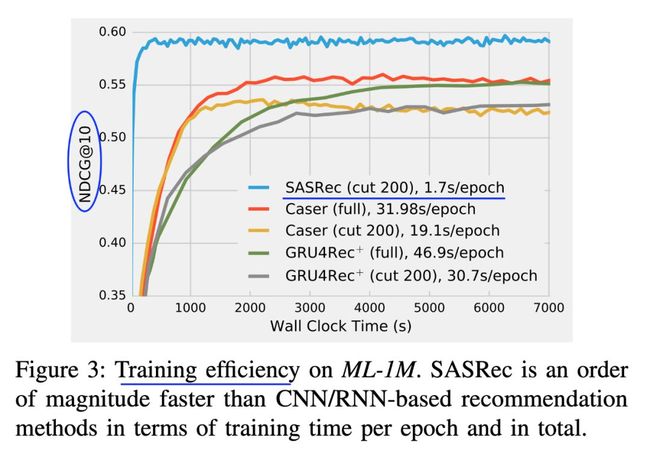
训练速度的对比如下
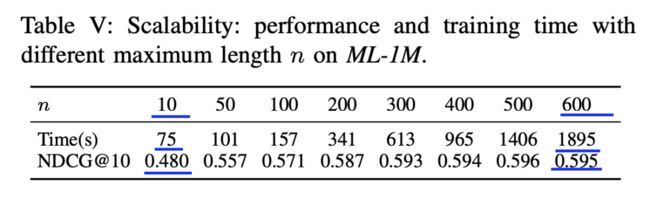
时间和效果对比如下
代码地址
https://github.com/kang205/SASRec
 我是分割线
我是分割线
您可能感兴趣
IJCAI2018|分层时空LSTM在位置预测中的应用(HST-LSTM)
IJCAI2019|基于会话和注意力机制的CTR预估模型DSIN(已开源)
AISTATS2018|密歇根大学提出新型在线boosting算法用于多标签排序(已开源)
KDD2019|基于注意力的深度学习如何实时预测购买还是浏览
AAAI2020|一种新型高效兼容多行为的推荐系统模型EHCF(已开源)
ICML2007|深度学习用于协同过滤的开篇作之一(出自深度学习鼻祖之一Hinton)
SIGIR2019|基于BERT的深度学习模型在信息检索中的应用(已开源)
SIGIR2019|基于注意力机制的新型深度学习模型(采莓树模型BIRD,已开源)
SIGIR2019|深度学习如何更好地用于学习排序(LTR)(已开源)
SIGIR2019|利用DeepSHAP来解释神经检索模型(已开源)
KDD2018|基于GBM的动态定价回归模型
KDD2018|超越deepfm的CTR预估模型深层兴趣网络DIN(已开源)
RecSys2019|优于DeepFM和XDeepFM的CTR模型FiBiNET
SIGIR2018|选择性GBDT(SelGB)用于排序学习(已开源)
IJCAI2019|基于对抗变分自编码的协同过滤框架VAEGAN
聊聊CatBoost
聊聊XGBoost CatBoost LightGBM RF GBDT
顶会中深度学习用于CTR预估的论文及代码集锦 (3)
ICML 2018 深度学习论文及代码集锦(5)
深度学习用于文本摘要的论文及代码集锦
深度学习用于机器翻译的论文及代码集锦
深度学习用于序列标注中的论文及代码集锦
深度学习在推荐系统中的应用及代码集锦(4)
深度学习在OCR中的应用论文及代码集锦 (2)