业务场景下 MySQL 原生语句编写
本篇概要:
- 1. SELECT 取数行号;
- 2. 分组后在分组内排序、每个分组取前 N 条;
- 3. 纯 SQL 实现小算法、计算商品重要度;
- 4. 自连接查询;
- 5. 找出重复数据删除;
- 6. 有重复数据不插入或更新;
- 7. 更新数据技巧: update 表子查询、多条件判断;
- 8. order by 实现排名作弊;
1. SELECT 取数行号;
使用到的表
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for `products`
-- ----------------------------
DROP TABLE IF EXISTS `products`;
CREATE TABLE `products` (
`p_id` int(11) NOT NULL AUTO_INCREMENT,
`p_name` varchar(30) DEFAULT NULL,
`p_type` varchar(20) DEFAULT NULL,
`p_view` int(11) DEFAULT NULL comment '点击量',
PRIMARY KEY (`p_id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of products
-- ----------------------------
INSERT INTO `products` VALUES ('1', '西瓜', '水果类', '21');
INSERT INTO `products` VALUES ('2', '瓜子', '干果类', '32');
INSERT INTO `products` VALUES ('22', '苹果', '水果类', '32');
INSERT INTO `products` VALUES ('28', '桔子', '水果类', '33');
INSERT INTO `products` VALUES ('32', '香蕉', '水果类', '21');
INSERT INTO `products` VALUES ('35', '花生', '干果类', '3');
INSERT INTO `products` VALUES ('37', '猪肉', '生鲜类', '5');
INSERT INTO `products` VALUES ('48', '牛肉', '生鲜类', '23');
INSERT INTO `products` VALUES ('60', '开心果', '干果类', '56');
INSERT INTO `products` VALUES ('61', '鸡翅', '生鲜类', '23');
INSERT INTO `products` VALUES ('77', '樱桃', '水果类', '41');
INSERT INTO `products` VALUES ('87', '杜蕾斯', '其他类', '123');
INSERT INTO `products` VALUES ('102', '开瓶器', '其他类', '88');
INSERT INTO `products` VALUES ('114', '五花肉', '生鲜类', '4');
实操
# 需求:取出数据并显示行号(假设按 p_view 倒排序)
# 首先是排序的 sql
select p_name,p_type,p_view from products ORDER BY p_view desc
# MySQL 并没有 oracle、sqlserver 那样直接的方法
# 会话变量,基本设置方法:
set @name='hua';
select @name;
# 只要会话不结束,这个变量就一直存在
# 对变量进行赋值
# “:=” 这才是 MySQL 对变量真正赋值的方式,“=” 只是比较
set @age:=10;
select @age:=10 as name;
# 只不过使用 set 语句时 可以写成“=”
# select 赋值必须是“:=”,如果不加“as name”,会给变量赋值+打印
# 结合 sql 语句
select p_name,p_type,p_view,@rownum:=@rownum+1 from products ORDER BY p_view desc
# 此时的问题是,如果变量一上来没有定义,就一直是 null
# MySQL 的 ifnull 函数
# IFNULL(expr1, expr2)
# expr1 不为 NULL,则 IFNULL() 的返回值为 expr1; 否则其返回值为 expr2
select p_name,p_type,p_view, IFNULL(@rownum:=@rownum+1,@rownum:=1) from products a
ORDER BY p_view desc
# 问题又来了,第二次运行 @rownum 不是从 1 开始的
# 最终解决方案,用 select 对 @rownum 进行初始化
select p_name,p_type,p_view,@rownum:=@rownum+1 as row_num
from products a,(select @rownum:=0) b ORDER BY p_view desc

2. 分组后在分组内排序、每个分组取前 N 条;
实操
# 实操前:关闭 only_full_group_by
SELECT @@sql_mode;
# 如果有 ONLY_FULL_GROUP_BY 则
SET sql_mode
='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
# 需求:分组后按照 p_view 进行倒排序
# 首先是分组的 SQL
# 中文字段的排序是安装 ascii 码排序的
select a.p_type,a.p_name,a.p_view from products a GROUP BY p_type,p_name
# 为了满足 p_view 的倒排序,分组 p_type 无效了
select a.p_type,a.p_name,a.p_view from products a GROUP BY p_type,p_name
order by p_view desc
# 按照 p_type,p_view 排序
# 这里不考虑优化,优化可以在 SQL 前加 explain
# type 为 ALL,需要加索引
select a.p_type,a.p_name,a.p_view from products a
order by a.p_type desc, a.p_view desc
# 每个分类取出前 n 条,有些网站的首页就有这样的需求
# 思路就是再加一列行号,p_type 相同行号就一直排下去
# p_type 和上一个不同就重新开一个行号
# 取出行号 <= n 就行
# @pre 保存上一条的 p_type 值
select p_type,p_name,p_view from
(select p_type,p_name,p_view from products
order by p_type desc, p_view desc) a,
(select @rownum:=0,@pre:=0) b
# MySQL 中 “=” 是用来进行判断的
# 第一次执行,@pre 没有值,@rownum 就 = 1
# 第二次运行 @pre:=p_type,@rownum 就 @rownum+1
# @pre:=p_type 没用,就只是一个表达式
select p_type,p_name,p_view, IF(@pre=p_type,@rownum:=@rownum+1,@rownum:=1) as row_num,
@pre:=p_type from
(select p_type,p_name,p_view from products
order by p_type desc, p_view desc) a,
(select @rownum:=0,@pre:='') b
# 取前 n 条
select p_type,p_name,p_view,row_num from(
select p_type,p_name,p_view, IF(@pre=p_type,@rownum:=@rownum+1,@rownum:=1) as row_num,
@pre:=p_type from
(select p_type,p_name,p_view from products
order by p_type desc, p_view desc) a,
(select @rownum:=0,@pre:='') b
) c
where c.row_num <=2

3. 纯 SQL 实现小算法、计算商品重要度;
追加表 - 商品销售汇总表
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for `products_sales`
-- ----------------------------
DROP TABLE IF EXISTS `products_sales`;
CREATE TABLE `products_sales` (
`p_id` int(11) NOT NULL AUTO_INCREMENT,
`p_name` varchar(30) DEFAULT NULL,
`p_sales` int(11) DEFAULT NULL comment '销量',
PRIMARY KEY (`p_id`)
) ENGINE=InnoDB AUTO_INCREMENT=115 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of products_sales
-- ----------------------------
INSERT INTO `products_sales` VALUES ('1', '西瓜', '101');
INSERT INTO `products_sales` VALUES ('2', '瓜子', '200');
INSERT INTO `products_sales` VALUES ('22', '苹果', '90');
INSERT INTO `products_sales` VALUES ('28', '桔子', '80');
INSERT INTO `products_sales` VALUES ('35', '花生', '55');
INSERT INTO `products_sales` VALUES ('87', '杜蕾斯', '500');
INSERT INTO `products_sales` VALUES ('102', '开瓶器', '231');
INSERT INTO `products_sales` VALUES ('114', '五花肉', '77');
实操:根据商品的点击量和销量,对商品进行一个评分
- 需求 1:根据分类显示出商品的名称、点击量和销售量情况。没有销售量的置为 0
select a.p_type,a.p_name,a.p_view from products a
order by a.p_type,a.p_view desc
select a.p_type,a.p_name,a.p_view,IFNULL(b.p_sales,0) from products a
left join products_sales b on a.p_id=b.p_id
order by a.p_type,a.p_view desc
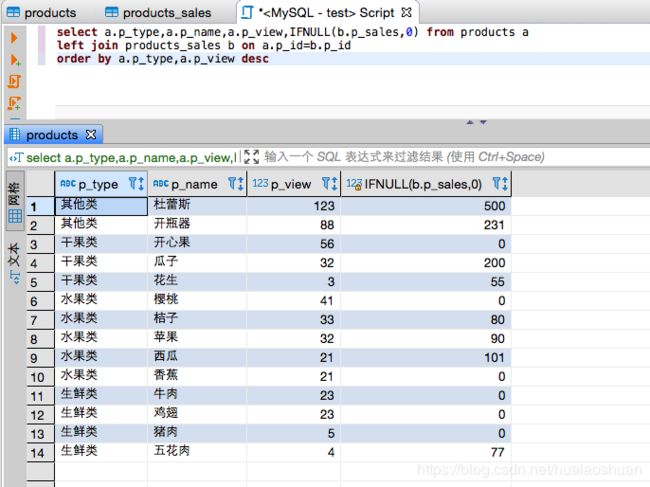
- 每一个分类的平均销量
# 0 销量不计算在内
select p_type,round(sum(sales)/count(*),0) as sales_avg from
(select a.p_type,a.p_name,a.p_view,IFNULL(b.p_sales,0) as sales from products a
left join products_sales b on a.p_id=b.p_id
order by a.p_type,a.p_view desc) a
where a.sales>0
GROUP BY p_type
- 对商品表做平均值计算
# 每一个分类的点击量平均值
select p_type,round(sum(p_view)/count(*),0) as view_avg
from products group by p_type
- 合并
# 之前写的商品点击量和销售量 a
select a.p_type,a.p_name,a.p_view,IFNULL(b.p_sales,0) as sales from products a
left join products_sales b on a.p_id=b.p_id
group by a.p_type,a.p_name order by a.p_type desc,a.p_view desc
# 每一个分类的点击量平均值 b
select p_type,round(sum(p_view)/count(*),0) as view_avg
from products group by p_type
# 销量平均值 c
select p_type,round(sum(sales)/count(*),0) as sales_avg from
(select a.p_type,a.p_name,a.p_view,IFNULL(b.p_sales,0) as sales from products a
left join products_sales b on a.p_id=b.p_id
order by a.p_type,a.p_view desc) a
where a.sales>0
GROUP BY p_type
# 合并
select a.p_type,p_name,p_view,view_avg,sales,sales_avg from
(
select a.p_type,a.p_name,a.p_view,IFNULL(b.p_sales,0) as sales from products a
left join products_sales b on a.p_id=b.p_id
group by a.p_type,a.p_name order by a.p_type desc,a.p_view desc
) a,
(
select p_type,round(sum(p_view)/count(*),0) as view_avg
from products group by p_type
) b,
(
select p_type,round(sum(sales)/count(*),0) as sales_avg from
(select a.p_type,a.p_name,a.p_view,IFNULL(b.p_sales,0) as sales from products a
left join products_sales b on a.p_id=b.p_id
order by a.p_type,a.p_view desc) a
where a.sales>0
GROUP BY p_type
) c
where a.p_type = b.p_type and a.p_type=c.p_type
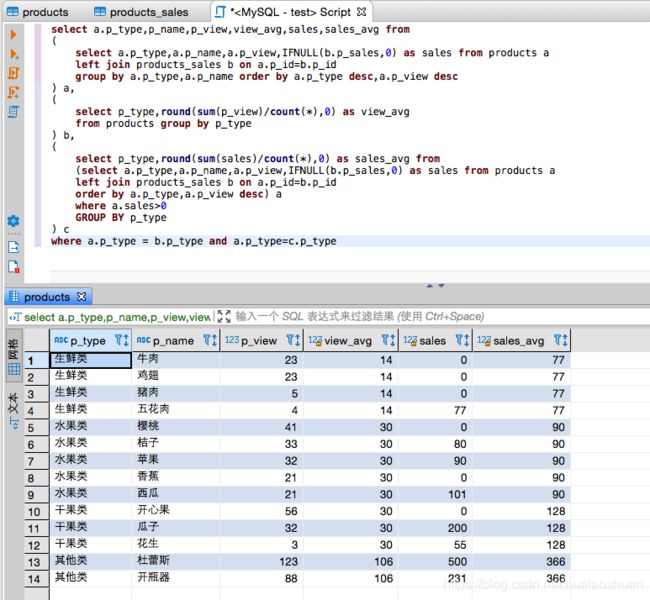
- 评分机制:可以加入权重
select a.p_type,p_name,(p_view/view_avg)*0.3+(sales/sales_avg)*0.7 from
(
select a.p_type,a.p_name,a.p_view,IFNULL(b.p_sales,0) as sales from products a
left join products_sales b on a.p_id=b.p_id
group by a.p_type,a.p_name order by a.p_type desc,a.p_view desc
) a,
(
select p_type,round(sum(p_view)/count(*),0) as view_avg
from products group by p_type
) b,
(
select p_type,round(sum(sales)/count(*),0) as sales_avg from
(select a.p_type,a.p_name,a.p_view,IFNULL(b.p_sales,0) as sales from products a
left join products_sales b on a.p_id=b.p_id
order by a.p_type,a.p_view desc) a
where a.sales>0
GROUP BY p_type
) c
where a.p_type = b.p_type and a.p_type=c.p_type

4. 自连接查询;
使用到的表
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for `webusers`
-- ----------------------------
DROP TABLE IF EXISTS `webusers`;
CREATE TABLE `webusers` (
`u_id` int(11) NOT NULL AUTO_INCREMENT,
`u_name` varchar(20) NOT NULL,
`p_id` int(11) NOT NULL comment '推荐人id',
PRIMARY KEY (`u_id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of webusers
-- ----------------------------
INSERT INTO `webusers` VALUES ('1', '张三', '0');
INSERT INTO `webusers` VALUES ('2', '大胖胖', '0');
INSERT INTO `webusers` VALUES ('3', '李四', '2');
INSERT INTO `webusers` VALUES ('4', '大长脸', '2');
INSERT INTO `webusers` VALUES ('5', '小朱', '1');
INSERT INTO `webusers` VALUES ('6', '小狗', '5');
INSERT INTO `webusers` VALUES ('7', '刘九', '5');
场景
- 比如做个用户激励注册,用户注册时可以填 “推荐人”(邀请码,连接某个用户的 id)。需求就是查询出注册用户的推荐人
- 需要使用到“自连接”。就是自己和自己进行 inner join 或 left jion
实操
# 查询
select a.u_name as username,b.u_name as referee from webusers a
INNER JOIN webusers b
on a.p_id=b.u_id;

优化
# 函数:GROUP_CONCAT
# 通常和 group by 一起使用,把相同的分组的字段值连接起来
# 举例
# 其中 order by 和 SEPARATOR 是可选的
select GROUP_CONCAT(u_name,u_id order by u_id desc SEPARATOR '|'),p_id from webusers group by p_id
# 实例
select a.referee,b.u_name from (
select GROUP_CONCAT(u_name) as referee,p_id from webusers GROUP BY p_id
) a INNER JOIN webusers b
WHERE a.p_id=b.u_id

5. 找出重复数据删除;
使用到的表
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for `reviews`
-- ----------------------------
DROP TABLE IF EXISTS `reviews`;
CREATE TABLE `reviews` (
`r_id` int(11) NOT NULL AUTO_INCREMENT,
`r_content` varchar(2000) NOT NULL comment '评论内容',
`r_userid` int(11) NOT NULL comment '评论人id',
`news_id` int(11) NOT NULL comment '对应新闻id',
PRIMARY KEY (`r_id`)
) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of reviews
-- ----------------------------
INSERT INTO `reviews` VALUES ('1', '不错啊', '101', '5');
INSERT INTO `reviews` VALUES ('2', '很好的文章', '102', '6');
INSERT INTO `reviews` VALUES ('3', '作者用心了', '103', '5');
INSERT INTO `reviews` VALUES ('4', '顶赞', '102', '7');
INSERT INTO `reviews` VALUES ('5', '不错啊', '101', '5');
INSERT INTO `reviews` VALUES ('6', '不错啊', '101', '5');
INSERT INTO `reviews` VALUES ('7', '写的不错', '105', '7');
INSERT INTO `reviews` VALUES ('8', '很好的文章', '102', '6');
INSERT INTO `reviews` VALUES ('9', '很好的文章', '102', '6');
INSERT INTO `reviews` VALUES ('10', '知道了', '108', '11');
实操
# 分组
select r_content,r_userid,count(*) from reviews
group by r_content ,r_userid
# 筛选出 count(*) > 1 的数据
# group by 可以利用聚合函数 count、sum、avg 进行分组
# having 可以对 group by 分组后的数据进一步筛选
select r_content,r_userid,count(*) as num from reviews
group by r_content ,r_userid HAVING num > 1
select a.* from reviews a inner join (
select r_content,r_userid,count(*) as num from reviews
group by r_content ,r_userid HAVING num >1
) b
on a.r_content = b.r_content and a.r_userid =b.r_userid

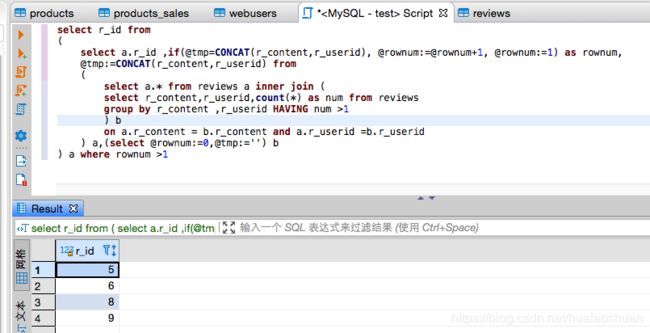
加入行号
# @tmp 分组里进行行号的区分
select r_id from
(
select a.r_id ,if(@tmp=CONCAT(r_content,r_userid), @rownum:=@rownum+1, @rownum:=1) as rownum,
@tmp:=CONCAT(r_content,r_userid) from
(
select a.* from reviews a inner join (
select r_content,r_userid,count(*) as num from reviews
group by r_content ,r_userid HAVING num >1
) b
on a.r_content = b.r_content and a.r_userid =b.r_userid
) a,(select @rownum:=0,@tmp:='') b
) a where rownum >1
# 最终删除返回的 id
delete from reviews where id in ()
或者使用 GROUP_CONCAT
select GROUP_CONCAT(r_id) as ids,r_content,r_userid,count(*) from reviews
GROUP BY r_content,r_userid
HAVING count(*)>1
# 取出的 r_id 合并
# 然后通过程序处理
select GROUP_CONCAT(ids SEPARATOR '|') as ids from (
select GROUP_CONCAT(r_id) as ids,r_content,r_userid,count(*) from reviews
GROUP BY r_content,r_userid
HAVING count(*)>1
) a
6. 有重复数据不插入或更新;
在插入数据的时候需要判断该数据是否有被插入过(并不是说主键是否重复),在这里说的是新闻数据,比如有标题、摘要等等。如果后台管理员不小心插入一条重复的,需要去判断提醒。以下是使用到的表
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for `news`
-- ----------------------------
DROP TABLE IF EXISTS `news`;
CREATE TABLE `news` (
`news_id` int(11) NOT NULL AUTO_INCREMENT,
`news_title` varchar(200),
`news_abstract` varchar(3000) comment '新闻摘要',
`news_code` varchar(100) comment '',
PRIMARY KEY (`news_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
场景:管理员后台
- 编辑在后台手工添加新闻
- 或者用爬虫抓到新闻后插入
由于一些不可描述的原因,可能会插入相同的新闻
# 插入一条新闻
insert into news(news_title,news_abstract)
VALUES('这是一条php技术资讯','php技术资讯相关的新闻摘要')
# 增加需求:如果下次插入,就不能插入重复数据
# 利用 news_code 字段
# 在程序 PHP 或者 java 通过 ORM 拼凑 SQL 语句时,会执行一个 md5 过程
# 让 news_code 值 = md5(标题的内容+摘要的内容)
# 同时设置 news_code 字段为唯一索引
insert into news(news_title,news_abstract,news_code)
VALUES('这是一条php技术资讯','php技术资讯相关的新闻摘要'
,MD5(CONCAT('这是一条php技术资讯','php技术资讯相关的新闻摘要')))
# 扩展需求
# 如果当新闻被重复插入时,需要统计次数。以此来判断管理员或爬虫是否“失误的次数太多”
# 这时加入一个字段 dupnum,int 型 (用来记录重复的次数)
# 插入重复数据 dupnum 字段就加 1
# 这是 mysql 的特有语法
ON DUPLICATE KEY UPDATE
# 一般跟在 insert 后面出现
# 如果 insert 会导致 UNIQUE 索引或 PRIMARY KEY中出现重复值,则在出现重复值的行执行 UPDATE
insert into news(news_title,news_abstract,news_code)
VALUES('这是一条PHP新闻','PHP新闻相关的新闻摘要'
,MD5(CONCAT('这是一条PHP新闻','PHP新闻相关的新闻摘要')))
on DUPLICATE key
update dupnum=dupnum+1
# 另外应用在用户信息表的更新中
# user_name 设置唯一索引
insert into users(user_name,user_qq) values('hua','123123')
# 一旦有用户更新记录,则执行以下
# user_qq=values(user_qq),这里的 value 是 ('123123') 的内容
insert into users(user_name,user_qq) values('hua','123123')
on DUPLICATE key update user_updatetime=now(),user_qq=values(user_qq)
7. 更新数据技巧: update 表子查询、多条件判断;
使用到的表
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for `user_level`
-- ----------------------------
DROP TABLE IF EXISTS `user_level`;
CREATE TABLE `user_level` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_name` varchar(50) DEFAULT NULL,
`user_total` decimal(10,2) DEFAULT NULL comment '消费总金额',
`user_rank` varchar(10) DEFAULT '吃瓜' comment '用户等级,默认吃瓜',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of user_level
-- ----------------------------
INSERT INTO `user_level` VALUES ('1', '张三', '5.00', '吃瓜');
INSERT INTO `user_level` VALUES ('2', '李四', '30.30', '吃瓜');
INSERT INTO `user_level` VALUES ('3', '赵龙', '22.00', '吃瓜');
INSERT INTO `user_level` VALUES ('4', '王五', '489.00', '吃瓜');
INSERT INTO `user_level` VALUES ('5', '刘飞', '175.00', '吃瓜');
INSERT INTO `user_level` VALUES ('6', '王菲', '123.00', '吃瓜');
INSERT INTO `user_level` VALUES ('7', '章子怡', '101.00', '吃瓜');
INSERT INTO `user_level` VALUES ('8', '陈晨', '20.00', '吃瓜');
INSERT INTO `user_level` VALUES ('9', '老蒋', '11.00', '吃瓜');
需求
- 系统运行了一段时间后,很多用户消费了
- 需要在表中对用户进行等级更新,需求是
- 只对超过平均消费金额的用户进行等级升级
- 达到平均消费金额 1 倍的用户,等级是“白金用户”
- 2 倍或以上的是黄金用户
- 其他一律是吃瓜用户
实操
# 普通操作:求平均值,后更新
select avg(user_total) from user_level
update user_level set user_rank= 'xx' where user_total >= 平均数
# 高端操作
# case when
# 往往用于 select 查询时,对字段进行特殊条件处理
case
when 表达式 then 表达式
else 表达式
end
# 举例 1:
select *,
case user_total
when 101 then '消费正好满100的用户'
else '其他'
end
from user_level
# 举例 2
select *,
case
when user_total>50 and user_total<100 then '消费超过50的用户'
when user_total>100 then '消费超过100的用户'
else '其他'
end
from user_level
# 结合 update 使用
update user_level set user_rank =
case
when ROUND(user_total / xx)>=1 and ROUND(user_total / xx)<2 then '白金用户'
when ROUND(user_total / xx)>=2 then '黄金用户'
ELSE '吃瓜'
end
where user_total > (
SELECT AVG(user_total) from user_level
)
# update 加入子查询
# 子查询得到的字段,在 case when 里可以用到
update user_level,(SELECT AVG(user_total) as avgtotal from user_level) b set user_rank =
case
when ROUND(user_total / b.avgtotal)>=1 and ROUND(user_total / b.avgtotal)<2 then '白金用户'
when ROUND(user_total / b.avgtotal)>=2 then '黄金用户'
ELSE '吃瓜'
end
where user_total > b.avgtotal