【学习】Hadoop大数据平台架构与实践--基础篇上
文章来源于:
http://blog.csdn.net/huanglong8/article/details/62884525
视频教程来自:
http://www.imooc.com/learn/391
算是比较基础入门的hadoop学习,比较适合我,虽然不是干这个的,但经常听到这个大数据,云计算的东西,所以简单也学习一下,学习嘛,就要稍微做下笔记,做做功课,有助于记忆嘛。
1. 初识Hadoop
2. Hadoop的安装
3. Hadoop的核心-HDFS简介
4. Hadoop核心—MapReduce
5. 统计示例WordCount
6. 利用MapReduce进行排序
当然你也可以通过这个总结,大致了解这个视频的讲解内容的大体构成,帮助理解。
1. 初识Hadoop
大数据是什么,大数据应用又是什么?比如,对于某家上市公司,我们可以对它以往的资产迭代进行分析,从而预测出今后公司的一个发展情况。还比如现在动不动就扫二维码,获取个人信息的,可以分析出您个人平时上网的喜好和方向是什么。尤其是百度,腾讯什么的主页,都会给你推荐你感兴趣的广告内容。还有想起我本科毕业论文时,当时研究的CA模拟,其实有一些数学模型也是建立在大数据分析之下的。
大数据应用通俗点讲就是利用大量的数据信息,从中提取你所关心的或分析出潜在信息的一成套系统应用。它可以是软硬件产品,也可以是解决方案报告。
在学习Hadoop前,讲解人建议需要 学习下 linux命令基础和java基础哦。
那么课程的组成在这里也阐述了一下,了解–原理–搭建–开发。
hadoop由来
大数据的出现伴随解决问题时考虑到,如何对大数据进行存储与分析?系统的性能?计算效率?都是面临的难题。
那么google提出了三大革命性技术:
MapReduce BigTable GFS
特点:
1. 降低成本,能用PC,不用高端机器。
2. 软件容错,硬件故障常态,保证软件高可靠性。
3. 简化并行分布式计算,不关注节点同步和存储。
但是google只是发表了论文,没开源。。。
然后有一个牛逼的人看了论文,写了hadoop。。。

Hadoop的功能与优势
Hadoop=分布式存储+分布式计算平台
HDFS:海量数据存储
MapReduce:并行处理框架,控制调度。
可以用来做大型数据仓库。
优势:
1. 高扩展
2. 低成本
3. 成熟的生态圈,一堆工具集

工作机会:hadoop开发 和 hadoop运维。。。
生态系统和版本
开源工具:
HIVE:SQL语句转Hadoop任务
HBASE:放弃事务,高扩展,提供数据随机和实时读写。
zookeeper:监控Hadoop的节点状态和维护。
版本:
ver1.x ver2.x 差别较大,讲解人建议用ver1.2 因为更稳定。
2. Hadoop的安装
- 准备Linux环境
- 安装JDK
- 配置Hadoop
讲解人建议直接租云主机。。。这里就不记了。居然还要收费,额。。。。我还是用虚拟机吧。
下载官网16.04LTS最新版,安装到VMWare中,由于ubuntu很多配置和源都不可用了,所以跟着视频一起学习时,需要中途卡一下,来解决这些问题。
启用root权限,关闭图形界面启动,然后重启
sudo passwd root //开启root用户,因为默认密码是随机的,然后根据提示输入密码
su root //切换root权限
systemctl disable lightdm.service //关闭图形界面启动
reboot先更新一下源
sudo apt-get update安装sshd,这里习惯用sshd,用了一下vm,有时候还要装那个什么vmtools的,所以这里我安装了ssh服务
sudo apt-get install openssh-server如果报 Could not get lock 的错 可以先解锁更新一下
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lockubuntu 16.04默认是没有jdk7的,视频教程里用的是jdk7所以咱们尽量用一样的。。。
sudo add-apt-repository ppa:openjdk-r/ppa
sudo apt-get update
sudo apt-get install openjdk-7-jdk配置静态IP。。。。
配置ROOT ssh可登录
vi /etc/ssh/sshd_config
----------------
#PermitRootLogin Prohibit-password
PermitRootLogin yes
-----------------
service ssh restart好,终于可以用xshell登录了,这样像办公环境。。。额。。。
下来配置JAVA环境变量,注意这里视频内容的配置仅针对ubuntu旧版本的,以下是针对16.04的配置方法。
vim /etc/profile
-----------
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH下载 hadoop 然后解压缩
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
tar -zxvf hadoop-1.2.1.tar.gz解压缩完后,这里大概讲述一下配置的四个文件 主要都是什么作用的。
hadoop-env.sh
这个文件主要是给hd提供相关环境配置,也可以理解为hd的自由环境配置文件,所以这里也要配置java_home的环境
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64core-site.xml
hd会有两个这种配置文档,一个是core-default.xml,如果这个core-site文档里为空,则会去寻找core-default中的内容,所以两个是类似的。具体参数配置可以参考:
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/core-default.xml
那么视频里配置内容如下:(对应name意思可以自己查)
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>/hadoopvalue>
property>
<property>
<name>dfs.name.dirname>
<value>/hadoop/namevalue>
property>
<property>
<name>fs.default.namename>
<value>hdfs://ubuntu:9000value>
property>
configuration>
hdfs-site.xml
这个文件同理配置
<configuration>
<property>
<name>dfs.data.dirname>
<value>/hadoop/datavalue>
property>
configuration>
mapred-site.xml
同样,这是任务调度器的相关,hd就这三个配置文件比较重要。
<configuration>
<property>
<name>mapred.job.trackername>
<value>ubuntu:9001value>
property>
configuration>
然后配置系统环境 /etc/profile
export HADOOP_HOME=/opt/hadoop-1.2.1
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:${HADOOP_HOME}/bin:$PATH配置完后source生效下
然后格式化hadoop
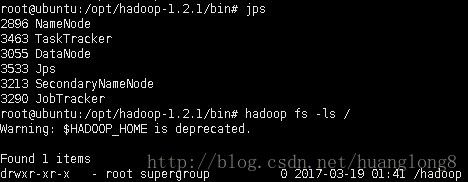
hadoop namenode -format格式化完,可以通过jps和命令行查看hadoop是否工作正常