HashMap在Jdk1.7和1.8中的实现
文章目录
- 一、初窥HashMap
- 二、jdk1.7中HashMap的实现
- 三、jdk1.8中HashMap的实现
- 四、分析Hashtable、HashMap、TreeMap的区别
Java集合类的源码是深入学习Java非常好的素材,源码里很多优雅的写法和思路,会让人叹为观止。HashMap的源码尤为经典,是非常值得去深入研究的,jdk1.8中HashMap发生了比较大的变化,这方面的东西也是各个公司高频的考点。网上也有很多应对面试的标准答案,我之前也写过类似的面试技巧,应付一般的面试应该是够了,但个人觉得这还是远远不够,毕竟我们不能只苟且于得到offer,更应去勇敢的追求诗和远方(源码)。
jdk版本目前更新的相对频繁,好多小伙伴说jdk1.7才刚真正弄明白,1.8就出现了,1.8还用都没开始用,更高的jdk版本就又发布了。很多小伙伴大声疾呼:臣妾真的学不动啦!这也许就是技术的最大魅力吧,活到老学到老,没有人能说精通所有技术。不管jdk版本如何更新,目前jdk1.7和1.8还是各个公司的主力版本。不管是否学得动,难道各位小伙伴忘记了《倚天屠龙记》里九阳真经里的口诀:他强由他强,清风拂山岗;他横由他横,明月照大江。他自狠来他自恶,我自一口真气足。(原谅我插入广告缅怀金庸大师,年少时期读的最多的书就是金庸大师的,遍布侠骨柔情大义啊)。这里的“真气”就是先掌握好jdk1.7和1.8,其它学不动的版本以后再说。
一、初窥HashMap
HashMap是应用更广泛的哈希表实现,而且大部分情况下,都能在常数时间性能的情况下进行put和get操作。要掌握HashMap,主要从如下几点来把握:
- jdk1.7中底层是由数组(也有叫做“位桶”的)+链表实现;jdk1.8中底层是由数组+链表/红黑树实现
- 可以存储null键和null值,线程不安全
- 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
- 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
- 插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容)
- 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素需分配更均匀
- 1.7中是先扩容后插入新值的,1.8中是先插值再扩容
为什么说HashMap是线程不安全的?在接近临界点时,若此时两个或者多个线程进行put操作,都会进行resize(扩容)和reHash(为key重新计算所在位置),而reHash在并发的情况下可能会形成链表环。总结来说就是在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。为什么在并发执行put操作会引起死循环?是因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。jdk1.7的情况下,并发扩容时容易形成链表环,此情况在1.8时就好太多太多了。因为在1.8中当链表长度大于阈值(默认长度为8)时,链表会被改成树形(红黑树)结构。
在HashMap中,null可以作为键,这样的键只有一个,但可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示HashMap中没有该key,也可以表示该key所对应的value为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个key,应该用containsKey()方法来判断。而在Hashtable中,无论是key还是value都不能为null。
二、jdk1.7中HashMap的实现
HashMap底层维护的是数组+链表,我们可以通过一小段源码(为jdk1.8的)来看看:
/**
* The default initial capacity - MUST be a power of two.
* 即 默认初始大小,值为16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
* 即 最大容量,必须为2^30
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
* 负载因子为0.75
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
* 大致意思就是说hash冲突默认采用单链表存储,当单链表节点个数大于8时,会转化为红黑树存储
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
* hash冲突默认采用单链表存储,当单链表节点个数大于8时,会转化
为红黑树存储。
* 当红黑树中节点少于6时,则转化为单链表存储
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
* hash冲突默认采用单链表存储,当单链表节点个数大于8时,会转化为红黑树存储。
* 但是有一个前提:要求数组长度大于64,否则不会进行转化
*/
static final int MIN_TREEIFY_CAPACITY = 64;
通过以上代码可以看出初始容量(16)、负载因子以及对数组的说明。数组中的每一个元素其实就是Entry
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
当向 HashMap 中 put一对键值时,它会根据 key的 hashCode 值计算出一个位置, 该位置就是此对象准备往数组中存放的位置。 该计算过程参看如下代码:
transient int hashSeed = 0;
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
通过hash计算出来的值将会使用indexFor方法找到它应该所在的table下标。当两个key通过hashCode计算相同时,则发生了hash冲突(碰撞),HashMap解决hash冲突的方式是用链表(拉链法)。当发生hash冲突时,则将存放在数组中的Entry设置为新值的next(这里要注意的是,比如A和B都hash后都映射到下标i中,之前已经有A了,当map.put(B)时,将B放到下标i中,A则为B的next,所以新值存放在数组中,旧值在新值的链表上)。即将新值作为此链表的头节点,为什么要这样操作?据说后插入的Entry被查找的可能性更大(因为get查询的时候会遍历整个链表),此处有待考究,如果有哪位大神知道,请留言告知。有一种说法就是链表查找复杂度高,可插入和删除性能高,如果将新值插在末尾,就需要先经过一轮遍历,这个时间复杂度高,开销大,如果是插在头结点,省去了遍历的开销,还发挥了链表插入性能高的优势。
如果该位置没有对象存在,就将此对象直接放进数组当中;如果该位置已经有对象存在了,则顺着此存在的对象的链开始寻找(为了判断是否值相同,map不允许
添加节点到链表中:找到数组下标后,会先进行key判重,如果没有重复,就准备将新值放入到链表的表头。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果当前 HashMap 大小已经达到了阈值,并且新值要插入的数组位置已经有元素了,那么要扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩容
resize(2 * table.length);
// 扩容以后,重新计算 hash 值
hash = (null != key) ? hash(key) : 0;
// 重新计算扩容后的新的下标
bucketIndex = indexFor(hash, table.length);
}
// 往下看
createEntry(hash, key, value, bucketIndex);
}
// 这个很简单,其实就是将新值放到链表的表头,然后 size++
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
这个方法的主要逻辑就是先判断是否需要扩容,需要带的话先扩容,然后再将这个新的数据插入到扩容后的数组的相应位置处的链表的表头。
扩容就是用一个新的大数组替换原来的小数组,并将原来数组中的值迁移到新的数组中。由于是双倍扩容,迁移过程中,会将原来table[i]中的链表的所有节点,分拆到新的数组的newTable[i]和newTable[i+oldLength]位置上。如原来数组长度是16,那么扩容后,原来table[0]处的链表中的所有元素会被分配到新数组中newTable[0]和newTable[16]这两个位置。
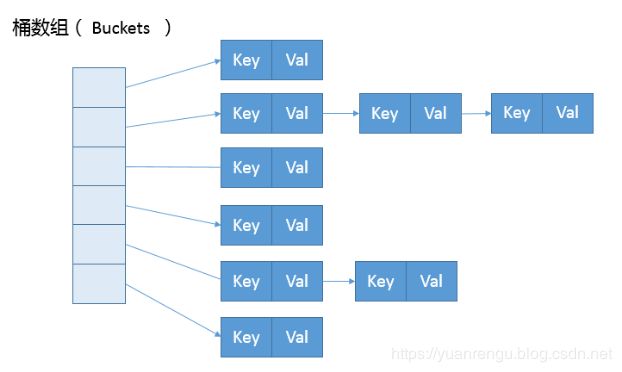
图中,左边部分即代表哈希表,也称为哈希数组(默认数组大小是16,每对key-value键值对其实是存在map的内部类entry里的),数组的每个元素都是一个单链表的头节点,跟着的蓝色链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
前面说过HashMap的key是允许为null的,当出现这种情况时,会放到table[0]中。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
当size>=threshold( threshold等于“容量*负载因子”)时,会发生扩容。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
jdk1.7中resize,只有当 size>=threshold并且 table中的那个槽中已经有Entry时,才会发生resize。即有可能虽然size>=threshold,但是必须等到相应的槽至少有一个Entry时,才会扩容,可以通过上面的代码看到每次resize都会扩大一倍容量(2 * table.length)。
三、jdk1.8中HashMap的实现
在jdk1.8中HashMap的内部结构可以看作是数组(Node
transient Node<K,V>[] table;
Entry的名字变成了Node,原因是和红黑树的实现TreeNode相关联。1.8与1.7最大的不同就是利用了红黑树,即由数组+链表(或红黑树)组成。
在分析jdk1.7中HashMap的hash冲突时,不知大家是否有个疑问就是万一发生碰撞的节点非常多怎么办?如果说成百上千个节点在hash时发生碰撞,存储一个链表中,那么如果要查找其中一个节点,那就不可避免的花费O(N)的查找时间,这将是多么大的性能损失。这个问题终于在JDK1.8中得到了解决,在最坏的情况下,链表查找的时间复杂度为O(n),而红黑树一直是O(logn),这样会提高HashMap的效率。
jdk1.7中HashMap采用的是位桶+链表的方式,即我们常说的散列链表的方式,而jdk1.8中采用的是位桶+链表/红黑树的方式,也是非线程安全的。当某个位桶的链表的长度达到某个阀值的时候,这个链表就将转换成红黑树。
jdk1.8中,当同一个hash值的节点数不小于8时,将不再以单链表的形式存储了,会被调整成一颗红黑树(上图中null节点没画)。这就是jdk1.7与jdk1.8中HashMap实现的最大区别。
HashMap根据链地址法(拉链法)来解决冲突,在jdk1.8中,如果链表长度大于8且节点数组长度大于64的时候,就把链表下所有的节点转为红黑树。
通过分析put方法的源码,可以让这种区别更直观:
static final int TREEIFY_THRESHOLD = 8;
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
//如果当前map中无数据,执行resize方法。并且返回n
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果要插入的键值对要存放的这个位置刚好没有元素,那么把他封装成Node对象,放在这个位置上即可
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//否则的话,说明这上面有元素
else {
Node<K,V> e; K k;
//如果这个元素的key与要插入的一样,那么就替换一下。
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//1.如果当前节点是TreeNode类型的数据,执行putTreeVal方法
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//还是遍历这条链子上的数据,跟jdk7没什么区别
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//2.完成了操作后多做了一件事情,判断,并且可能执行treeifyBin方法
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) //true || --
e.value = value;
//3.
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判断阈值,决定是否扩容
if (++size > threshold)
resize();
//4.
afterNodeInsertion(evict);
return null;
}
以上代码中的特别之处如下:
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
treeifyBin()就是将链表转换成红黑树。
树化操作的过程有点复杂,可以结合源码来看看。将原本的单链表转化为双向链表,再遍历这个双向链表转化为红黑树。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//树形化还有一个要求就是数组长度必须大于等于64,否则继续采用扩容策略
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;//hd指向首节点,tl指向尾节点
do {
TreeNode<K,V> p = replacementTreeNode(e, null);//将链表节点转化为红黑树节点
if (tl == null) // 如果尾节点为空,说明还没有首节点
hd = p; // 当前节点作为首节点
else { // 尾节点不为空,构造一个双向链表结构,将当前节点追加到双向链表的末尾
p.prev = tl; // 当前树节点的前一个节点指向尾节点
tl.next = p; // 尾节点的后一个节点指向当前节点
}
tl = p; // 把当前节点设为尾节点
} while ((e = e.next) != null); // 继续遍历单链表
//将原本的单链表转化为一个节点类型为TreeNode的双向链表
if ((tab[index] = hd) != null) // 把转换后的双向链表,替换数组原来位置上的单向链表
hd.treeify(tab); // 将当前双向链表树形化
}
}
大家要特别注意一点,树化有个要求就是数组长度必须大于等于MIN_TREEIFY_CAPACITY(64),否则继续采用扩容策略。
总的来说,HashMap默认采用数组+单链表方式存储元素,当元素出现哈希冲突时,会存储到该位置的单链表中。但是单链表不会一直增加元素,当元素个数超过8个时,会尝试将单链表转化为红黑树存储。但是在转化前,会再判断一次当前数组的长度,只有数组长度大于64才处理。否则,进行扩容操作。
将双向链表转化为红黑树的实现:
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null; // 定义红黑树的根节点
for (TreeNode<K,V> x = this, next; x != null; x = next) { // 从TreeNode双向链表的头节点开始逐个遍历
next = (TreeNode<K,V>)x.next; // 头节点的后继节点
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x; // 头节点作为红黑树的根,设置为黑色
}
else { // 红黑树存在根节点
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) { // 从根开始遍历整个红黑树
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h) // 当前红黑树节点p的hash值大于双向链表节点x的哈希值
dir = -1;
else if (ph < h) // 当前红黑树节点的hash值小于双向链表节点x的哈希值
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) // 当前红黑树节点的hash值等于双向链表节点x的哈希值,则如果key值采用比较器一致则比较key值
dir = tieBreakOrder(k, pk); //如果key值也一致则比较className和identityHashCode
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) { // 如果当前红黑树节点p是叶子节点,那么双向链表节点x就找到了插入的位置
x.parent = xp;
if (dir <= 0) //根据dir的值,插入到p的左孩子或者右孩子
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x); //红黑树中插入元素,需要进行平衡调整(过程和TreeMap调整逻辑一模一样)
break;
}
}
}
}
//将TreeNode双向链表转化为红黑树结构之后,由于红黑树是基于根节点进行查找,所以必须将红黑树的根节点作为数组当前位置的元素
moveRootToFront(tab, root);
}
然后将红黑树的根节点移动端数组的索引所在位置上:
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash; //找到红黑树根节点在数组中的位置
TreeNode<K,V> first = (TreeNode<K,V>)tab[index]; //获取当前数组中该位置的元素
if (root != first) { //红黑树根节点不是数组当前位置的元素
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) != null) //将红黑树根节点前后节点相连
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
if (first != null) //将数组当前位置的元素,作为红黑树根节点的后继节点
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}
putVal方法处理的逻辑比较多,包括初始化、扩容、树化,近乎在这个方法中都能体现,针对源码简单讲解下几个关键点:
- 如果Node
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
- resize方法兼顾两个职责,创建初始存储表格,或者在容量不满足需求的时候,进行扩容(resize)。
在放置新的键值对的过程中,如果发生下面条件,就会发生扩容。
if (++size > threshold)
resize();
- 具体键值对在哈希表中的位置(数组index)取决于下面的位运算:
i = (n - 1) & hash
仔细观察哈希值的源头,会发现它并不是key本身的hashCode,而是来自于HashMap内部的另一个hash方法。为什么这里需要将高位数据移位到低位进行异或运算呢?这是因为有些数据计算出的哈希值差异主要在高位,而HashMap里的哈希寻址是忽略容量以上的高位的,那么这种处理就可以有效避免类似情况下的哈希碰撞。
在jdk1.8中取消了indefFor()方法,直接用(tab.length-1)&hash,所以看到这个,代表的就是数组的下角标。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
为什么HashMap为什么要树化?
之前在极客时间的专栏里看到过一个解释。本质上这是个安全问题。因为在元素放置过程中,如果一个对象哈希冲突,都被放置到同一个桶里,则会形成一个链表,我们知道链表查询是线性的,会严重影响存取的性能。而在现实世界,构造哈希冲突的数据并不是非常复杂的事情,恶意代码就可以利用这些数据大量与服务器端交互,导致服务器端CPU大量占用,这就构成了哈希碰撞拒绝服务攻击,国内一线互联网公司就发生过类似攻击事件。
用哈希碰撞发起拒绝服务攻击(DOS,Denial-Of-Service attack),常见的场景是攻击者可以事先构造大量相同哈希值的数据,然后以JSON数据的形式发送给服务器,服务器端在将其构建成为Java对象过程中,通常以Hashtable或HashMap等形式存储,哈希碰撞将导致哈希表发生严重退化,算法复杂度可能上升一个数据级,进而耗费大量CPU资源。
四、分析Hashtable、HashMap、TreeMap的区别
HashMap是继承自AbstractMap类,而HashTable是继承自Dictionary类。不过它们都实现了同时实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。存储的内容是基于key-value的键值对映射,不能由重复的key,而且一个key只能映射一个value。HashSet底层就是基于HashMap实现的。- Hashtable的key、value都不能为null;HashMap的key、value可以为null,不过只能有一个key为null,但可以有多个null的value;TreeMap键、值都不能为null。
- Hashtable、HashMap具有无序特性。TreeMap是利用
红黑树实现的(树中的每个节点的值都会大于或等于它的左子树中的所有节点的值,并且小于或等于它的右子树中的所有节点的值),实现了SortMap接口,能够对保存的记录根据键进行排序。所以一般需求排序的情况下首选TreeMap,默认按键的升序排序(深度优先搜索),也可以自定义实现Comparator接口实现排序方式。
一般情况下我们选用HashMap,因为HashMap的键值对在取出时是随机的,其依据键的hashCode和键的equals方法存取数据,具有很快的访问速度,所以在Map中插入、删除及索引元素时其是效率最高的实现。而TreeMap的键值对在取出时是排过序的,所以效率会低点。
TreeMap是基于红黑树的一种提供顺序访问的Map,与HashMap不同的是它的get、put、remove之类操作都是o(log(n))的时间复杂度,具体顺序可以由指定的Comparator来决定,或者根据键的自然顺序来判断。
对HashMap做下总结:
HashMap基于哈希散列表实现 ,可以实现对数据的读写。将键值对传递给put方法时,它调用键对象的hashCode()方法来计算hashCode,然后找到相应的bucket位置(即数组)来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决hash冲突问题,当发生冲突了,对象将会储存在链表的头节点中。HashMap在每个链表节点中储存键值对对象,当两个不同的键对象的hashCode相同时,它们会储存在同一个bucket位置的链表中,如果链表大小超过阈值(TREEIFY_THRESHOLD,8),链表就会被改造为树形结构。
有个问题要特别声明下:
- HashMap在jdk1.7中采用表头插入法,在扩容时会改变链表中元素原本的顺序,以至于在并发场景下导致链表成环的问题。
- 在jdk1.8中采用的是尾部插入法,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
我们可以简单列下HashMap在1.7和1.8之间的变化:
- 1.7中采用数组+链表,1.8采用的是数组+链表/红黑树,即在1.7中链表长度超过一定长度后就改成红黑树存储。
- 1.7扩容时需要重新计算哈希值和索引位置,1.8并不重新计算哈希值,巧妙地采用和扩容后容量进行&操作来计算新的索引位置。
- 1.7是采用表头插入法插入链表,1.8采用的是尾部插入法。
- 在1.7中采用表头插入法,在扩容时会改变链表中元素原本的顺序,以至于在并发场景下导致链表成环的问题;在1.8中采用尾部插入法,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。