【分析】Ceph:RGW基本原理
Ceph提供了三种存储类型:块存储、文件存储和对象存储,本文主要介绍对象存储的RGW基本原理和应用场景。
1 什么是分布式存储
对象存储(云存储)是面向对象/文件的、海量的互联网存储。对象存储里的对象是经过封装了的文件,在对象存储系统里, 不能直接打开/修改文件,但可以像ftp一样上传文件,下载文件等。
另外,对象存储没有像文件系统那样有一个很多层级的文件结构,而是只有一个“桶”的概念(也就是存储空间),“桶”里面全部都是对象,是一种非常扁平化的存储方式。 其最大的特点就是它的对象名称就是一个域名地址,一旦对象被设置为“公开”,所有网民都可以访问到。
对象存储最主流的使用场景,就是存储网站、移动app等互联网/移动互联网应用的静态内容(视频、图片、文件、软件安装包等等)。
2 什么是RGW
RGW为Rados Gateway的缩写,ceph通过RGW为互联网云服务提供商提供对象存储服务。RGW在librados之上向应用提供访问ceph集群的RestAPI,支持Amazon S3和openstack swift两种接口。对RGW最直接的理解就是一个协议转换层,把从上层应用符合S3或Swift协议的请求转换成rados的请求,将数据保存在rados集群中。
3 几个内部概念
- zone:包含多个RGW实例的一个逻辑概念。zone不能跨集群,同一个zone的数据保存在同一组pool中。
- zonegroup:一个zonegroup如果包含1个或多个zone。如果一个zonegroup包含多个zone,必须指定一个zone作为master zone,用来处理bucket和用户的创建。一个集群可以创建多个zonegroup,一个zonegroup也可以跨多个集群。
- realm:一个realm包含1个或多个zonegroup。如果realm包含多个zonegroup,必须指定一个zonegroup为master zonegroup, 用来处理系统操作。一个系统中可以包含多个realm,多个realm之间资源完全隔离。
4 几个外部概念
- user:对象存储的使用者,默认情况下,一个用户只能创建1000个存储桶。
- bucket:存储桶,用来管理对象的容器。
- object:对象,泛指一个文档、图片或视频文件等,尽管用户可以直接上传一个目录,但是ceph并不按目录层级结构保存对象, ceph所有的对象扁平化的保存在bucket中。
5 访问流程
下图展示了应用、RGW、ceph集群的关系:
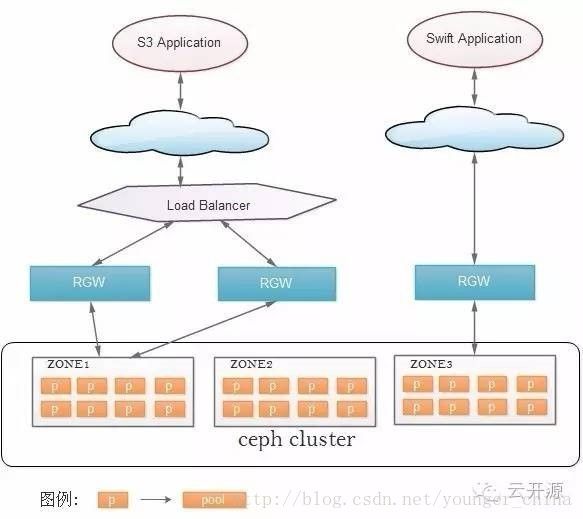
应用通过RGW访问集群流程如下:
● S3或Swift 应用通过http协议发送请求到RGW。
● RGW从http请求中解析出s3或swift协议数据,调用librados接口,将对应的请求发送到rados集群中。
注:图中load balance非必须,只要在存在多个RGW做负荷分担时需要。
6 数据存储位置
对象存储涉及各种类型的数据,ceph将不同类型的数据存储在不同的pool中,RGW涉及的pool分为两大类:
● 保存集群数据的pool,比如用来保存realm信息,zonegroup信息,zone信息,使用哪个pool来保存哪个信息在配置文件中指定, 默认保存在.rgw.zone中。
● 保存跟单个zone相关数据的pool,在创建zone时指定,默认情况下,pool名以zone名+rgw+保存数据类型来命名,例如下面名为z1的zone默认pool如下:
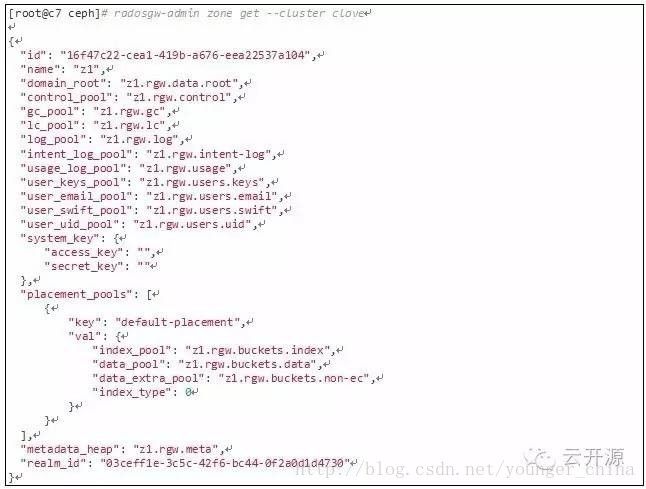
* 注:RGW需要用到的这些pool最好在使用之前手动创建,如果不手动创建,RGW会在需要时自动创建。手动创建的好处是 我们可以根据需要指定pool的PG数,crush规则等。*
下面详细说明RGW涉及到的各个pool的作用:
domain_root:
保存bucket和bucket元数据。
control_pool:
在RGW上电时,在control pool创建若干个对象用于watch-notify,主要作用为当一个zone对应多个RGW,且cache使能时, 保证数据的一致性,其基本原理为利用librados提供的对象watch-notify功能,当有数据更新时,通知其他RGW刷新cache, 后面会有文档专门描述RGW cache。
gc_pool:
RGW中大文件数据一般在后台删除,该pool用于记录那些待删除的文件对象。
lc_pool:
保存对象生命周期执行状态。
log_pool:
各种log信息,如op log、数据同步log、过期对象等。
intent_log_pool:
目前没用。
usage_log_pool:
存储计量数据统计,比如上传文件多少次,下载多少次,遍历bucket多少次之类。
user_keys_pool:
存储用户AK和uid的对应关系,方便通过用户restful请求的ak找到用户id。
user_email_pool:
存储swift key和uid的对应关系。
user_swift_pool:
存储用户email和uid的对应关系。
user_uid_pool:
存储用户信息,和用户下bucket列表。
index_pool:
保存bucket中对象列表,index_pool可以配置多个,跟data_pool、data_extra_pool一起组成placement_pool, 在创建bucket时指定数据保存到哪一组placement_pool中。
data_pool:
保存对象数据,data_pool可以有多个。
data_extra_pool:
Multipart upload过程中一些中间态的数据,会存在该pool上。这些数据可以帮助用户进行断点续传及垃圾数据回收。
7 应用场景
● 频繁IO的网盘。
● 有海量数据归档和备份需求的互联网应用企业云备份的企业用户。