新闻日志实时分析项目
文章目录
- 第一章:案例需求分析与设计
- 1.案例需求分析
- 2.系统架构设计
- 3.系统数据流程设计
- 4.集群资源规划设计
- 第二章:linux环境准备
- 第三章:hadoop集群搭建
- 1.Hadoop安装及配置
- 第四章:zookeeper安装
- 第五章:HA架构与部署
- 1.详细配置
- 第六章 HBase安装配置
- 第七章 Kafka安装部署
- 第八章 Flume部署及数据采集准备
- 1.安装部署
- 2.配置文件
- 第九章 节点一 Flume+HBase+Kafka集成与开发
- 1.flume+hbase集成
- 2.flume与HBase和Kafka的集成配置
- 第十章 数据采集/存储/分发完整流程测试
- 第十一章 Mysql安装
- 第十二章 Hive安装
- 第十三章 Hive与HBase集成进行数据分析
- 第十四章 Spark2.X环境准备、编译部署及运行
- 第十五章 Spark SQL快速离线数据分析
- 第十六章 Structured Streaming业务数据实时分析
- 第十七章 大数据Web可视化分析系统开发
第一章:案例需求分析与设计
1.案例需求分析
某新闻网用户日志分析系统:
1.捕获用户浏览日志信息
2.实时分析前20名流量最高的新闻话题
3.实时统计当前线上已曝光的新闻话题
4.统计哪个时段用户浏览量最高
5.报表
2.系统架构设计
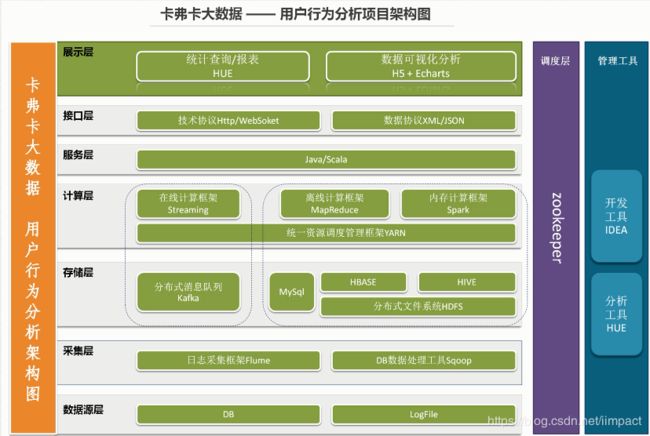
3.系统数据流程设计
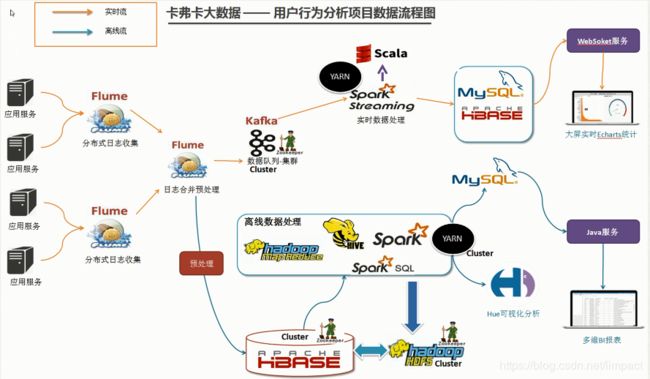
4.集群资源规划设计
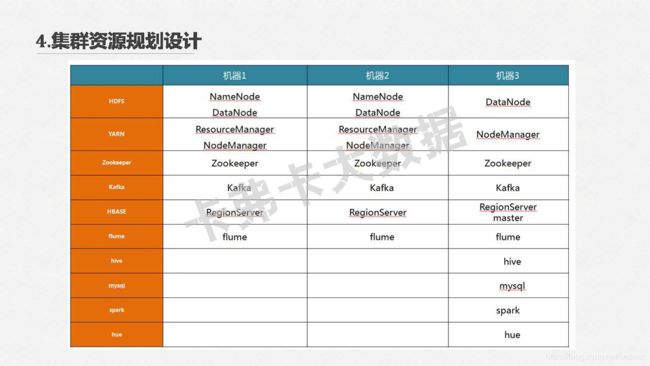
第二章:linux环境准备
参考电商数仓项目
第三章:hadoop集群搭建
前提:先安装jdk,卸载系统自带jdk.
1.Hadoop安装及配置
1)解压安装hadoop:
tar -zxvf hadoop-2.5.0.tar.gz -C /opt/module/
2)删除不必要的文件:
[hadoop@node1 share]$ rm -r doc
3)配置文件
a.hadoop-env.sh yarn-env.sh mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.7.0_67
b.配置core-site.xml
fs.defaultFS
hdfs://node1:9000
http.staticuser.user
hadoop
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
c.配置hdfs-site.xml
dfs.replication
1
dfs.permissions.enabled
true
d.配置slaves:
node1
node2
node3
e.配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
node1
f.配置mapred-site.xml
mapreduce.framework.name
yarn
g.配置/etc/profile:
## JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.7.0_67
export PATH=$PATH:$JAVA_HOME/bin
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.5.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
"/etc/profile" 85L, 2012C written
g.分发hadoop(xsync脚本参考电商项目)和/etc/profile
sudo scp /etc/profile root@node2:/etc/profile
sudo scp /etc/profile root@node3:/etc/profile
将/etc/profile追加到~/.bashrc中
cat /etc/profile >> ~/.bashrc
h.配置ssh免密登录
1)node1家目录下新建.ssh 目录(若已经存在,则先删除):
目录权限要是700
进入到.ssh目录
.ssh]$ ssh-keygen -t rsa 然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
同理在node2上配置免密登录
i.测试
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
j.检查ntp是否安装
1)rpm -qa|grep ntp
ntp-4.2.6p5-10.el6.centos.x86_64
fontpackages-filesystem-1.41-1.1.el6.noarch
ntpdate-4.2.6p5-10.el6.centos.x86_64
2)修改ntp配置文件
vi /etc/ntp.conf
修改内容如下
a)修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改/etc/sysconfig/ntpd 文件
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
service ntpd status
ntpd 已停
service ntpd start
设置ntpd服务开机启动设置ntpd服务开机启动
chkconfig ntpd on
2. 其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate node1
(2)修改任意机器时间
date -s “2017-9-11 11:11:11”
十分钟后查看机器是否与时间服务器同步
date
第四章:zookeeper安装
1)拷贝Zookeeper安装包到Linux系统下
put D:\数序建模\software\zookeeper-3.4.5-cdh5.10.0.tar.gz
(2)解压到指定目录
tar -zxvf zookeeper-3.4.5-cdh5.10.0.tar.gz -C /opt/module/
3)分发:
xsync zookeeper-3.4.5-cdh5.10.0
4)配置服务器编号
在/opt/module/zookeeper-3.4.10/这个目录下创建zkData:mkdir zkData
在/opt/module/zookeeper-3.4.10/zkData目录下创建一个myid的文件:
touch myid
编辑myid文件
vi myid
在文件中添加与server对应的编号
拷贝配置好的zookeeper到其他机器上
xsync zkData
并修改其他两台主机中myid的内容
5)配置zoo.cfg文件
重命名/opt/module/zookeeper-3.4.10/conf这个目录下的zoo_sample.cfg为zoo.cfg
mv zoo_sample.cfg zoo.cfg
打开zoo.cfg文件
vim zoo.cfg
修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.4.10/zkData
增加如下配置
#######################cluster##########################
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
分发zoo.cfg配置文件
xsync zoo.cfg
6)启动,测试
第五章:HA架构与部署
1.详细配置
1)HDFS-HA配置
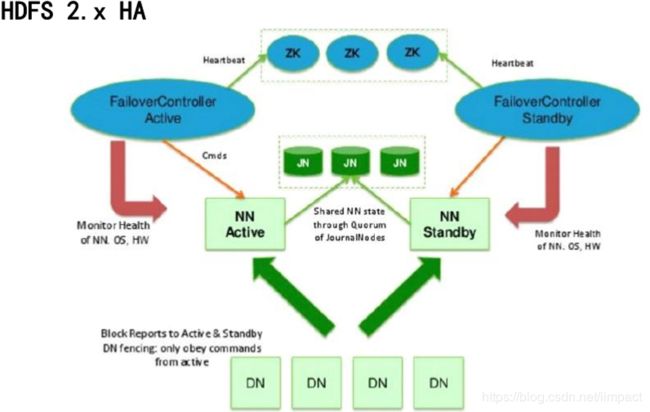
由于电脑内存限制,就不配置HA了。
第六章 HBase安装配置
1.,上传安装包,解压安装:
tar -zxvf hbase-1.3.1-bin.tar.gz -C /opt/module
2.HBase的配置文件
1)hbase-env.sh修改内容:
export JAVA_HOME=/opt/module/jdk1.8.0_144
export HBASE_MANAGES_ZK=false
2)hbase-site.xml修改内容:
hbase.rootdir
hdfs://node1:9000/hbase
hbase.cluster.distributed
true
hbase.master.port
16000
hbase.zookeeper.quorum
node1,node2,node3
hbase.zookeeper.property.dataDir
/opt/module/zookeeper-3.4.10/zkData
3)regionservers:
node1
node2
node2
4)软连接hadoop配置文件到hbase:
ln -s /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
/opt/module/hbase/conf/core-site.xml
ln -s /opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
/opt/module/hbase/conf/hdfs-site.xml
- HBase远程发送到其他集群
xsync hbase/
6)HBase服务的启停(首先启动zookeeper和hadoop )
bin/start-hbase.sh
bin/stop-hbase.sh
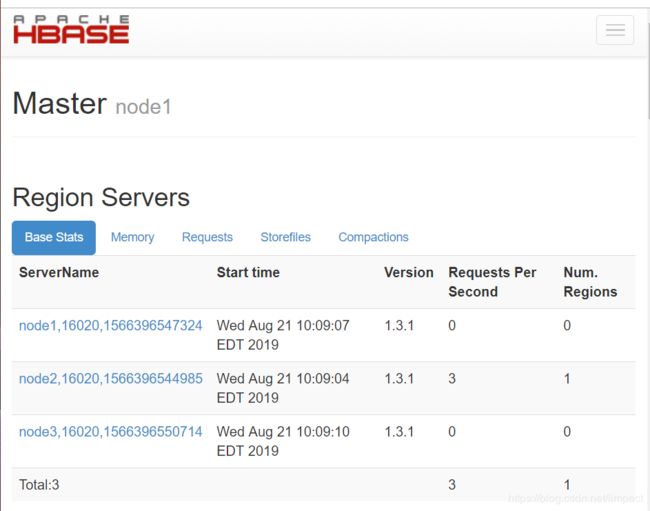
7)查看HBase页面
http://node1:16010
第七章 Kafka安装部署
1.集群规划
node1 node2 node3
zk zk zk
kafka kafka kafka
2.集群部署
1)下载解压安装包
$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module/
2)修改解压后的文件名称
module]$ mv kafka_2.11-0.11.0.0/ kafka
3)在/opt/module/kafka目录下创建logs文件夹
mkdir logs
4)修改配置文件
kafka]$ cd config/
config]$ vi server.properties
输入以下内容:
#broker的全局唯一编号,不能重复
broker.id=0
#删除topic功能使能
delete.topic.enable=true
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的现成数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志存放的路径
log.dirs=/opt/module/kafka/logs
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#配置连接Zookeeper集群地址
zookeeper.connect=node1:2181,node2:2181,node3:2181
5)配置环境变量
sudo vi /etc/profile
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH= P A T H : PATH: PATH:KAFKA_HOME/bin
source /etc/profile
6)分发安装包
xsync kafka/
注意:分发之后记得配置其他机器的环境变量
7)分别在另外两台机器上上修改配置文件/opt/module/kafka/config/server.properties中的broker.id=1、broker.id=2
注:broker.id不得重复
8)Kafka启停集群脚本
vim kf.sh
在脚本中填写如下内容
#! /bin/bash
case $1 in
"start"){
for i in node1 node2 node3
do
echo " --------启动 $i Kafka-------"
# 用于KafkaManager监控
ssh $i "export JMX_PORT=9988 && /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties "
done
};;
"stop"){
for i in node1 node2 node3
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh stop"
done
};;
esac
增加脚本执行权限
chmod 777 kf.sh
kf集群启动脚本
kf.sh start
kf集群停止脚本
kf.sh stop
第八章 Flume部署及数据采集准备
1.安装部署
1)将apache-flume-1.7.0-bin.tar.gz上传到linux的/opt/software目录下
2)解压apache-flume-1.7.0-bin.tar.gz到/opt/module/目录下
software]$ tar -zxf apache-flume-1.7.0-bin.tar.gz -C /opt/module/
3)修改apache-flume-1.7.0-bin的名称为flume
module]$ mv apache-flume-1.7.0-bin flume
4)将flume/conf下的flume-env.sh.template文件修改为flume-env.sh,并配置flume-env.sh文件
conf]$ mv flume-env.sh.template flume-env.sh
conf]$ vi flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
2.配置文件
node2与node3中flume数据采集到node1中,而且node2和node3的flume配置文件相同,,如下
a2.sources = r1
a2.sinks = k1
a2.channels = c1
a2.sources.r1.type = exec
a2.sources.r1.command = tail -F /opt/data/weblog-flume.log
a2.sources.r1.channels = c1
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 1000
a2.channels.c1.keep-alive = 5
a2.sinks.k1.type = avro
a2.sinks.k1.channel = c1
a2.sinks.k1.hostname = node5
a2.sinks.k1.port = 5555
第九章 节点一 Flume+HBase+Kafka集成与开发
1.flume+hbase集成
下载Flume源码并导入Idea开发工具
1)将apache-flume-1.7.0-src.tar.gz源码下载到本地解压
2)通过idea导入flume源码
然后找到flume-ng-hbase-sink源码
3) 模仿SimpleAsyncHbaseEventSerializer自定义KfkAsyncHbaseEventSerializer实现类,修改一下代码即可
@Override
public List getActions() {
List actions = new ArrayList();
if (payloadColumn != null) {
byte[] rowKey;
try {
/*---------------------------代码修改开始---------------------------------*/
// 解析列字段
String[] columns = new String(this.payloadColumn).split(",");
// 解析flume采集过来的每行的值
String[] values = new String(this.payload).split(",");
for(int i=0;i < columns.length;i++){
byte[] colColumn = columns[i].getBytes();
byte[] colValue = values[i].getBytes(Charsets.UTF_8);
// 数据校验:字段和值是否对应
if(colColumn.length != colValue.length) break;
// 时间
String datetime = values[0].toString();
// 用户id
String userid = values[1].toString();
// 根据业务自定义Rowkey
rowKey = SimpleRowKeyGenerator.getKfkRowKey(userid,datetime);
// 插入数据
PutRequest putRequest = new PutRequest(table, rowKey, cf,
colColumn, colValue);
actions.add(putRequest);
/*---------------------------代码修改结束---------------------------------*/
}
} catch (Exception e) {
throw new FlumeException("Could not get row key!", e);
}
}
return actions;
}
2)在SimpleRowKeyGenerator类中,根据具体业务自定义Rowkey生成方法
public static byte[] getKfkRowKey(String userid, String datetime) throws UnsupportedEncodingException {
return (userid + "-" + datetime + "-" + String.valueOf(System.currentTimeMillis())).getBytes("UTF8");
}
4)将上面自定义编译程序打成jar包
5)将打包名字替换为flume自带的包名flume-ng-hbase-sink-1.7.0.jar ,然后上传至flume/lib目录下,覆盖原有的jar包即可。
2.flume与HBase和Kafka的集成配置
node1通过flume接收node2与node3中flume传来的数据,并将其分别发送至hbase与kafka中,配置内容如下
a1.sources = r1
a1.channels = kafkaC hbaseC
a1.sinks = kafkaSink hbaseSink
a1.sources.r1.type = avro
a1.sources.r1.channels = hbaseC kafkaC
a1.sources.r1.bind = node5
a1.sources.r1.port = 5555
a1.sources.r1.threads = 5
#****************************flume + hbase******************************
a1.channels.hbaseC.type = memory
a1.channels.hbaseC.capacity = 10000
a1.channels.hbaseC.transactionCapacity = 10000
a1.channels.hbaseC.keep-alive = 20
a1.sinks.hbaseSink.type = asynchbase
a1.sinks.hbaseSink.table = weblogs
a1.sinks.hbaseSink.columnFamily = info
a1.sinks.hbaseSink.serializer = org.apache.flume.sink.hbase.KfkAsyncHbaseEventSerializer
a1.sinks.hbaseSink.channel = hbaseC
a1.sinks.hbaseSink.serializer.payloadColumn = datetime,userid,searchname,retorder,cliorder,cliurl
#****************************flume + kafka******************************
a1.channels.kafkaC.type = memory
a1.channels.kafkaC.capacity = 10000
a1.channels.kafkaC.transactionCapacity = 10000
a1.channels.kafkaC.keep-alive = 20
a1.sinks.kafkaSink.channel = kafkaC
a1.sinks.kafkaSink.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.kafkaSink.brokerList = node5:9092,node6:9092,node7:9092
a1.sinks.kafkaSink.topic = weblogs
a1.sinks.kafkaSink.zookeeperConnect = node5:2181,node6:2181,node7:2181
a1.sinks.kafkaSink.requiredAcks = 1
a1.sinks.kafkaSink.batchSize = 1
a1.sinks.kafkaSink.serializer.class = kafka.serializer.StringEncoder
第十章 数据采集/存储/分发完整流程测试
1.到搜狗实验室下载用户查询日志
1)将文件中的tab更换成逗号
cat weblog.log|tr “\t” “,” > weblog.log
2)将文件中的空格更换成逗号
cat weblog.log|tr " " “,” > weblog.log
2.在idea开发工具中构建weblogs项目,编写数据生成模拟程序。
package main.java;
import java.io.*;
public class ReadWrite {
static String readFileName;
static String writeFileName;
public static void main(String args[]){
readFileName = args[0];
writeFileName = args[1];
try {
// readInput();
readFileByLines(readFileName);
}catch(Exception e){
}
}
public static void readFileByLines(String fileName) {
FileInputStream fis = null;
InputStreamReader isr = null;
BufferedReader br = null;
String tempString = null;
try {
System.out.println("以行为单位读取文件内容,一次读一整行:");
fis = new FileInputStream(fileName);// FileInputStream
// 从文件系统中的某个文件中获取字节
isr = new InputStreamReader(fis,"GBK");
br = new BufferedReader(isr);
int count=0;
while ((tempString = br.readLine()) != null) {
count++;
// 显示行号
Thread.sleep(300);
String str = new String(tempString.getBytes("UTF8"),"GBK");
System.out.println("row:"+count+">>>>>>>>"+tempString);
method1(writeFileName,tempString);
//appendMethodA(writeFileName,tempString);
}
isr.close();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if (isr != null) {
try {
isr.close();
} catch (IOException e1) {
}
}
}
}
public static void method1(String file, String conent) {
BufferedWriter out = null;
try {
out = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(file, true)));
out.write("\n");
out.write(conent);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
2.参照前面idea工具项目打包方式,将该项目打成weblogs.jar包,然后上传至node1,node2节点的/opt/jars目录下(目录需要提前创建)
3.编写运行模拟程序的shell脚本
创建weblog-shell.sh脚本。内容为
#! /bin/bash
for i in node2 node3
do
ssh $i "java -jar /opt/jars/weblogs.jar /opt/datas/weblog.log /opt/datas/weblog-flume.log&
"
done
修改weblog-shell.sh可执行权限
chmod 777 weblog-shell.sh
4.编写启动flume服务程序的shell脚本 flume-log.sh
- node2 node3采集脚本:
#! /bin/bash
case $1 in
"start"){
for i in node2 node3
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/file
-flume1-flume2.conf --name a2 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log.txt 2>&1 &"
done
};;
"stop"){
for i in node2 node3
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file-flume1-flume2 | grep -v grep |awk '{print \$2}' | xargs kill"
done
};;
esac
2)node1聚合flume shell 脚本:flume-kfk_hbs.sh
#! /bin/bash
case $1 in
"start"){
for i in node1
do
echo " --------启动 $i 消费flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/flum
e1-flume2-hbase_kafaka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log.txt 2>&1 &
"
done
};;
"stop"){
for i in node1
do
echo " --------停止 $i 消费flume-------"
ssh $i "ps -ef | grep flume1-flume2-hbase_kafaka | grep -v grep |awk '{print \$2}' | xargs
kill"
done
};;
esac
5.编写kafka集群启停脚本,kf.sh。
#! /bin/bash
case $1 in
"start"){
for i in node1 node2 node3
do
echo " --------启动 $i Kafka-------"
# 用于KafkaManager监控
ssh $i "export JMX_PORT=9988 && /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/m
odule/kafka/config/server.properties "
done
};;
"stop"){
for i in node1 node2 node3
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh stop"
done
};;
esac
~
6.完成数据采集全流程测试
1)启动Zookeeper服务
2)启动hdfs服务
3)启动HBase服务
创建hbase业务表
create ‘weblogs’,‘info’
4)启动Kafka服务,并创建业务数据topic
kf.sh start
bin/kafka-topics.sh --create --zookeeper node1:2181,node2:2181,node3:2181 --topic weblogs --partitions 1 --replication-factor 1
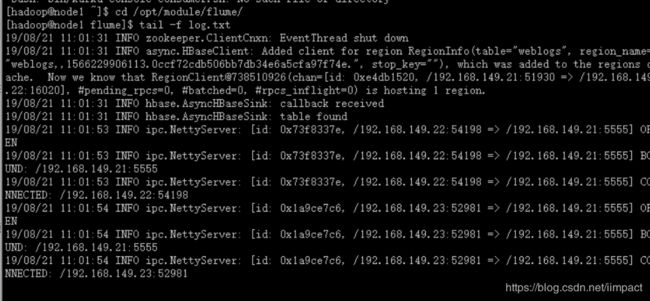
5)启动flume聚合脚本,将采集的数据分发到Kafka集群和hbase集群
flume-kfk_hbs.sh start
6)在node2和node3节点上完成数据采集。
flume-log.sh start
7)启动数据模拟脚本:
weblog-shell.sh
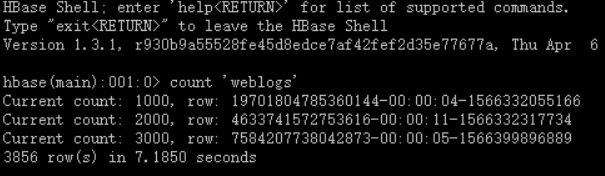
8)查看hbase数据写入情况
bin/hbase shell
count ‘weblogs’
第十一章 Mysql安装
1.查看mysql是否安装,如果安装了,卸载mysql
(1)查看
rpm -qa|grep mysql
(2)卸载
rpm -e --nodeps mysql-libs-5.1.73-7.el6.x86_64
2.解压mysql-libs.zip文件到当前目录
unzip mysql-libs.zip
3.进入到mysql-libs文件夹下
2 安装MySql服务器
安装mysql服务端
rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm
查看产生的随机密码
cat /root/.mysql_secret
查看mysql状态
service mysql status
启动mysql
service mysql start
3 安装MySql客户端
安装mysql客户端
rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm
链接mysql
mysql -uroot -p随机密码
修改密码
SET PASSWORD=PASSWORD(‘123456’);
退出mysql
exit
4 MySql中user表中主机配置
配置只要是root用户+密码,在任何主机上都能登录MySQL数据库。
进入mysql
mysql -uroot -p123456
显示数据库
show databases;
使用mysql数据库
use mysql;
展示mysql数据库中的所有表
show tables;
展示user表的结构
desc user;
查询user表
select User, Host, Password from user;
修改user表,把Host表内容修改为%
update user set host=’%’ where host=‘localhost’;
删除root用户的其他host
delete from user where Host=node1’;
delete from user where Host=‘127.0.0.1’;
delete from user where Host=’::1’;
刷新
flush privileges;
退出
quit;
第十二章 Hive安装
1.Hive安装及配置
1)把apache-hive-1.2.1-bin.tar.gz上传到linux的/opt/software目录下
(2)解压apache-hive-1.2.1-bin.tar.gz到/opt/module/目录下面
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/module/
(3)修改apache-hive-1.2.1-bin.tar.gz的名称为hive
mv apache-hive-1.2.1-bin/ hive
(4)修改/opt/module/hive/conf目录下的hive-env.sh.template名称为hive-env.sh
mv hive-env.sh.template hive-env.sh
(5)配置hive-env.sh文件
(a)配置HADOOP_HOME路径
export HADOOP_HOME=/opt/module/hadoop-2.7.2
(b)配置HIVE_CONF_DIR路径
export HIVE_CONF_DIR=/opt/module/hive/conf
2.Hadoop集群配置
(1)必须启动HDFS和YARN
sbin/start-dfs.sh
sbin/start-yarn.sh
(2)在HDFS上创建/tmp和/user/hive/warehouse两个目录并修改他们的同组权限可写
bin/hadoop fs -mkdir /tmp
bin/hadoop fs -mkdir -p /user/hive/warehouse
bin/hadoop fs -chmod g+w /tmp
bin/hadoop fs -chmod g+w /user/hive/warehouse
3.Hive元数据配置到MySql
1.在/opt/software/mysql-libs目录下解压mysql-connector-java-5.1.27.tar.gz驱动包
tar -zxvf mysql-connector-java-5.1.27.tar.gz
2.拷贝/opt/software/mysql-libs/mysql-connector-java-5.1.27目录下的mysql-connector-java-5.1.27-bin.jar到/opt/module/hive/lib/
cp mysql-connector-java-5.1.27-bin.jar
/opt/module/hive/lib/
3.配置Metastore到MySql
在/opt/module/hive/conf目录下创建一个hive-site.xml
根据官方文档配置参数,拷贝数据到hive-site.xml文件中
javax.jdo.option.ConnectionURL
jdbc:mysql://hadoop102:3306/metastore?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
123456
password to use against metastore database
hive.cli.print.header
true
hive.cli.print.current.db
true
第十三章 Hive与HBase集成进行数据分析
1)在hive-site.xml文件中配置Zookeeper,hive通过这个参数去连接HBase集群。
hbase.zookeeper.quorum
node1,node2,node3
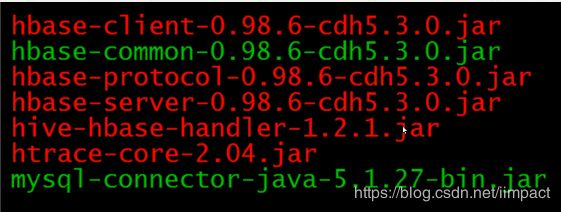
2)将hbase的9个包拷贝到hive/lib目录下。如果是CDH版本,已经集成好不需要导包。
export HBASE_HOME=/opt/modules/hbase-0.98.6-cdh5.3.0
export HIVE_HOME=/opt/modules/hive-0.13.1/lib
ln -s $HBASE_HOME/lib/hbase-server-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-server-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-client-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-client-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-protocol-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-protocol-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-it-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-it-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/htrace-core-2.04.jar$HIVE_HOME/lib/htrace-core-2.04.jar
ln -s $HBASE_HOME/lib/hbase-hadoop2-compact-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-hadoop2-compact-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/hbase-hadoop-compact-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-hadoop-compact-0.98.6-cdh5.3.0.jar
ln -s $HBASE_HOME/lib/high-scale-lib-1.1.1.jar $HIVE_HOME/lib/high-scale-lib-1.1.1.jar
ln -s $HBASE_HOME/lib/hbase-common-0.98.6-cdh5.3.0.jar $HIVE_HOME/lib/hbase-common-0.98.6-cdh5.3.0.jar
3)在hive中创建与hbase集成的外部表
CREATE EXTERNAL TABLE weblogs(
id string,
datetime string,
userid string,
searchname string,
retorder string,
cliorder string,
cliurl string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES("hbase.columns.mapping"=
":key,info:datetime,info:userid,info:searchname,info:retorder,info:cliorder,info:cliurl")
TBLPROPERTIES("hbase.table.name"="weblogs");
#查看hbase数据记录
select count(*) from weblogs;
第十四章 Spark2.X环境准备、编译部署及运行
- 1)Spark2.2源码下载到node5节点的/opt/softwares/目录下,解压
tar -zxf spark-2.2.0.tgz -C /opt/modules/
2)spark2.2编译所需要的环境:Maven3.3.9和Java8
3)Spark源码编译的方式:Maven编译、SBT编译(暂无)和打包编译make-distribution.sh
a)下载Jdk8并安装
tar -zxf jdk8u11-linux-x64.tar.gz -C /opt/modules/
b)JAVA_HOME配置/etc/profile
export JAVA_HOME=/opt/modules/jdk1.8.0_11
export PATH= P A T H : PATH: PATH:JAVA_HOME/bin
编辑退出之后,使之生效
source /etc/profile
c)如果遇到不能加载当前版本的问题
rpm -qa|grep jdk
rpm -e --nodeps jdk版本
d)下载并解压Maven
下载Maven,解压maven
tar -zxf apache-maven-3.3.9-bin.tar.gz -C /opt/modules/
配置MAVEN_HOME(/etc/profile)
export MAVEN_HOME=/opt/modules/apache-maven-3.3.9
export PATH= P A T H : PATH: PATH:MAVEN_HOME/bin
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=1024M -XX:ReservedCodeCacheSize=1024M"
编辑退出之后,使之生效
source /etc/profile
查看maven版本
mvn -version
e)编辑make-distribution.sh内容,可以让编译速度更快
VERSION=2.2.0
SCALA_VERSION=2.11.8
SPARK_HADOOP_VERSION=2.6.4
#支持spark on hive
SPARK_HIVE=1
4)编译前安装一些压缩解压缩工具
yum install -y snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop openssl openssl-devel
5)通过make-distribution.sh源码编译spark,打包后可以丢到生产环境了
./dev/make-distribution.sh --name custom-spark --tgz -Phadoop-2.6 -Dhadoop.version=2.6.4 -Phive -Phive-thriftserver -Pyarn -DskipTests
编译完成之后解压
tar -zxf spark-2.2.0-bin-custom-spark.tgz -C /opt/modules/
-
scala安装及环境变量设置
1)下载
2)解压
tar -zxf scala-2.11.8.tgz -C /opt/modules/
3)配置环境变量(/etc/profile)
export SCALA_HOME=/opt/modules/scala-2.11.8
export PATH= P A T H : PATH: PATH:SCALA_HOME/bin
4)编辑退出之后,使之生效
source /etc/profile -
spark配置standalone集群模式(spark内置的主从,master,worker)
1.上传至linux(node1,node2,node3)2.解压jar 包
tar -zxvf spark-1.6.1-bin-hadoop2.6.tgz3.修改配置文件(配置三个节点)
cp slaves.template slaves vi slaves(配置运行worker的机器) 添加如下内容: -------------------------------------------------- spark2 spark3 -------------------------------------------------- 这样使node1只运行clustercp spark-env.sh.template spark-env.sh
vi spark-env.sh
添加如下内容: -------------------------------------------------- export JAVA_HOME=/opt/soft/jdk1.8.0_11 export SPARK_MASTER_IP=node1 export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=2 export SPARK_WORKER_INSTANCES=1 export SPARK_WORKER_MEMORY=1g 注: 配置master高可用:在master节点上配置,每启动一个master都会向zk传递数据 记得配置master节点对其他节点的免密码登录,另外修改export SPARK_MASTER_IP4.运行
./sbin/start-all.sh5.测试
1)client模式
spark-1.6.1]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://spark1:7077 --executor-memory 1G --total-executor-cores 1 ./lib/spark-examples-1.6.1-hadoop2.6.0.jar 100
其中--master spark指定standlone模式
2)cluster模式(结果spark1:8080里面可见!)
spark-1.6.1]#./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://spark1:7077 --deploy-mode cluster --supervise --executor-memory 1G --total-executor-cores 1 ./lib/spark-examples-1.6.1-hadoop2.6.0.jar 100
第十五章 Spark SQL快速离线数据分析
-
Spark SQL 与Hive集成(spark-shell)
需要配置的项目1)将hive的配置文件hive-site.xml拷贝到spark conf目录,同时添加metastore的url配置。
hive.metastore.uris thrift://node1:9083 2)拷贝hive中的mysql jar包到 spark 的 lib 目录下执行操作: vi hive-site.xml,添加如下内容:
cp hive-0.13.1-bin/lib/mysql-connector-java-5.1.27-bin.jar spark-1.6-bin/lib/
3)检查spark-env.sh 文件中的配置项
执行操作: vi spark-env.sh,添加如下内容:
HADOOP_CONF_DIR=/opt/soft/hadoop-2.6.4/etc/hadoop
启动服务
1)检查mysql是否启动
# 查看状态:service mysqld status
#启动:service mysqld start
2)启动hive metastore服务
bin/hive --service metastore
3)启动hive
bin/hive,进入hive命令行
4)创建本地文件 kfk.txt,内容如下:
0001 spark
0002 hive
0003 hbase
0004 hadoop
5)执行 hive语句
hive> show databases;
hive> create database kfk;
hive> create table if not exists test(userid string,username string)ROW FORMAT DELIMITED FIELDS TERMINATED BY ’ ’ STORED AS textfile;
hive> load data local inpath “/opt/data/kfk.txt” into table test;
6)启动 spark-shell
bin/spark-shell,进入spark-shell中,执行操作,返回结果
spark.sql(“select * from kfk.test”).show
0001 spark
0002 hive
0003 hbase
0004 hadoop
-
Spark SQL 与Hive集成(spark-sql)
1)启动spark-sql,进入该命令行bin/spark-sql2)查看数据库
show databases;
default
kfk
3)使用数据库,并查询表
# 使用数据库
use kfk
# 查看表
show tables;
# 查看表数据
select * from test;
3.Spark SQL与MySQL集成
Spark SQL与HBase集成,其核心就是Spark Sql通过hive外部表来获取HBase的表数据。
1)拷贝HBase的包和hive包到 spark的 lib目录下
2)启动spark-shell,进入命令行
bin/spark-shell
val df =spark.sql("select count(1) from weblogs").show
第十六章 Structured Streaming业务数据实时分析
- Structured Streaming与kafka集成
1)Structured Streaming是Spark2.2.0新推出的,要求kafka的版本0.10.0及以上。集成时需将如下的包拷贝到Spark的jar包目录下。
kafka_2.11-0.10.1.0.jar
kafka-clients-0.10.1.0.jar
spark-sql-kafka-0-10_2.11-2.2.0.jar
spark-streaming-kafka-0-10_2.11-2.1.0.jar
2)与kafka集成代码
val df = spark
.readStream
.format(“kafka”)
.option(“kafka.bootstrap.servers”, “node1:9092”)
.option(“subscribe”, “weblogs”)
.load()
import spark.implicits._
val lines = df.selectExpr(“CAST(value AS STRING)”).as[String]
2. Structured Streaming与MySQL集成
1)mysql创建相应的数据库和数据表,用于接收数据
create database test;
use test;
CREATE TABLE webCount (
titleName varchar(255) CHARACTER SET utf8 DEFAULT NULL,
count int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2)与mysql集成代码
val url ="jdbc:mysql://node·1:3306/test"
val username="root"
val password="123456"
val writer = new JDBCSink(url,username,password)
val query = titleCount.writeStream
.foreach(writer)
.outputMode("update")
.trigger(ProcessingTime("5 seconds"))
.start()
-
Structured Streaming向mysql数据库写入中文乱码解决
修改数据库文件my.cnf(linux下)
[ client] socket=/var/lib/mysql/mysql.sock //添加 default-character-set=utf8 //添加 [mysqld] character-set-server=utf8 //添加 datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock user=mysql # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 [mysqld_safe] log-error=/var/log/mysqld.log pid-file=/var/run/mysqld/mysqld.pid
第十七章 大数据Web可视化分析系统开发
-
基于业务需求的WEB系统设计(具体参照代码)
-
基于Echart框架的页面展示层开发
3.启动各个服务
1)启动zookeeper: zk.sh start
2)启动hadoop: start-dfs.sh(node1),start-yarn.sh(node2)
3)启动hbase: start-hbase
4)启动mysql: service mysqld start
5)node2(node3)启动flume: flume-log.sh start,将数据发送到node2中
6)node1启动flume: flume-kfk_hbs.sh,将数据分别传到hbase和kafka中
7)启动kafka-0.10:
kf.sh start
8)启动node2(node3)中的脚本:weblog-shell.sh
9)启动 StructuredStreamingKafka来从kafka中取得数据,处理后存到mysql中
10)启动web项目(sparkStu),该项目会从mysql数据库中读取数据展示到页面
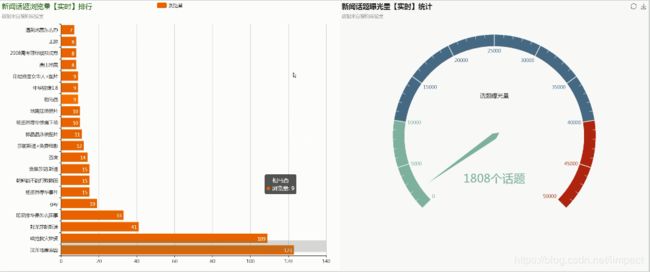
最终项目运行效果
参考博客