Ceph 基础入门
文章目录
- Ceph 基础
- 一、什么是Ceph?
- 二、ceph历史
- 三、在国内的使用情况以及常见问答
- 四、Ceph核心概念
- 五、Ceph核心组件
- 六、Ceph三种存储类型
- 1. 块存储(RBD)
- 2. 文件存储(CephFS)
- 3. 对象存储(Object)(适合更新变动较少的数据)
- 七、Ceph和Swift、HDFS对比
- 八、体系结构
Ceph 基础
一、什么是Ceph?
官网: https://docs.ceph.com/docs/master/
http://docs.ceph.org.cn/
Ceph架构介绍
参考URL: https://www.cnblogs.com/passzhang/p/12148933.html
干货|非常详细的 Ceph 介绍、原理、架构
参考URL: https://blog.csdn.net/mingongge/article/details/100788388
Ceph是当前非常流行的开源分布式存储系统,具有高扩展性、高性能、高可靠性等优点,同时提供块存储服务(rbd)、对象存储服务(rgw)以及文件系统存储服务(cephfs),Ceph在存储的时候充分利用存储节点的计算能力,在存储每一个数据时都会通过计算得出该数据的位置,尽量的分布均衡。目前也是OpenStack的主流后端存储。
有别于其他分布式系统就在于它采用Crush(Controlled Replication Under Scalable Hashing)算法使得数据的存储位置都是计算出来的而不是去查询专门的元数据服务器得来的。
它将文件分割后均匀随机地分散在各个节点上,Ceph采用了CRUSH算法来确定对象的存储位置,只要有当前集群的拓扑结构,Ceph客户端就能直接计算出文件的存储位置,直接跟OSD节点通信获取文件而不需要询问中心节点获得文件位置,这样就避免了单点风险。
作者:张兴凯
链接:https://www.zhihu.com/question/21718731/answer/21545274
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
-
高性能
a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据 -
高可扩展性
a. 去中心化
b. 扩展灵活
c. 随着节点增加而线性增长 -
特性丰富
a. 支持三种存储接口:块存储、文件存储、对象存储
b. 支持自定义接口,支持多种语言驱动
二、ceph历史
Ceph 入门系列(一):ceph历史
参考URL: https://blog.csdn.net/don_chiang709/article/details/90298128?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-3&utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-3
Ceph 项目起源于其创始人Sage Weil在加州大学Santa Cruz分校攻读博士期间的研究课题。项目的起始时间为2004年,在2006年基于开源协议开源了Ceph的源代码。Sage Weil也相应成立了Inktank公司专注于Ceph的研发。在2014年5月,该公司被Red Hat收购。
2014年,红帽收购Inktank(Inktank主要提供基于Ceph的企业级产品),此次收购后,红帽成为最大的开源存储产品提供商,包括对象存储、块存储和文件存储。红帽在Ceph开源项目上的代码贡献量上可以说是一骑绝尘。
三、在国内的使用情况以及常见问答
社区访谈: 为何Ceph在中国发展如日中天?
参考URL: https://www.sohu.com/a/225450264_100068148
Ceph在国内的应用从2014年开始走强。迄今为止,Ceph在金融(如恒丰银行,平安科技)、政府行业、互联网(如金山云、阿里、腾讯、京东、携程)、能源行业(如国家电网)、交通行业(如中铁总)、运营商(中国联通、中国移动、中国电信)、高校(上海交大、武汉大学)、媒体娱乐(人民日报、今日头条、YY直播、虎牙直播等)、公益(福彩)、游戏等行业得到了广泛的应用。
用户自行下载Ceph发行版使用,需要注意哪些问题?
答:用户下载源代码,或者是发行版,都离不开一些优化工作,需要多去借鉴别人的经验,让它更好的部署在自己工作的环境里。实际上,部署不是难事,难点是调优与运维,后者需要更多的精力。
笔者:Ceph在一个统一的系统中同时提供了对象、块和文件存储功能,在实际使用中,这些功能是否能够拆分出独立的系统?
答:统一提供这三个功能,这正是Ceph的巧妙之处。自然,单独采用其中某一个功能,就更加没有问题的了。
在不同技术领域的公司,有专注于块的,有专注于对象的,还有擅长文件的。在实际的使用过程中,很多案例都是独立的使用的。Ceph最早是对块级别层面的支持,然后支持文件系统项目,再后来支持对象存储。在对象存储领域,Ceph大有替代Swift的趋势。
笔者:与传统SAN、NAS相比,Ceph的主要优势在哪里?
答:去年曾有一家银行客户说,在未来三年之内,银行80%的NAS场景将会被替换为对象存储。对NAS来说,可扩展性是一个硬伤,而这正是Ceph所具备的天然优势。
可扩展性面临的挑战,一方面是资金不足的问题,因为扩容成本比较高,而且厂商之间的不同产品还存在兼容性问题,另一方面是技术问题。在以往的某些场景中,系统接近满载时候,存取的效率就会很低,低到让人无法忍受。
Ceph的分布式存储方式实现无缝的扩容。这对于商业化存储而言是最大的一个冲击点。
四、Ceph核心概念
-
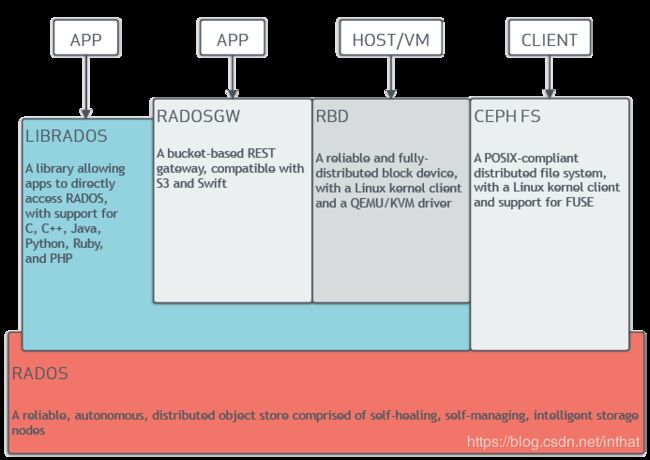
RADOS
全称Reliable Autonomic Distributed Object Store,即可靠的、自动化的、分布式对象存储系统。RADOS是Ceph集群的精华,用户实现数据分配、Failover等集群操作。 -
Librados
Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。 -
Crush
Crush算法是Ceph的两大创新之一,通过Crush算法的寻址操作,Ceph得以摒弃了传统的集中式存储元数据寻址方案。而Crush算法在一致性哈希基础上很好的考虑了容灾域的隔离,使得Ceph能够实现各类负载的副本放置规则,例如跨机房、机架感知等。同时,Crush算法有相当强大的扩展性,理论上可以支持数千个存储节点。 -
Pool
Pool是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略,支持两种类型:副本(replicated)和 纠删码( Erasure Code); -
PG( placement group)
PG( placement group)是一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略,简单点说就是相同PG内的对象都会放到相同的硬盘上,PG是 ceph的逻辑概念,服务端数据均衡和恢复的最小粒度就是PG,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据; -
Object
简单来说块存储读写快,不利于共享,文件存储读写慢,利于共享。能否弄一个读写快,利于共享的出来呢。于是就有了对象存储。最底层的存储单元,包含元数据和原始数据。
五、Ceph核心组件
- OSD
OSD是负责物理存储的进程,一般配置成和磁盘一一对应,一块磁盘启动一个OSD进程。主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查,负责响应客户端请求返回具体数据的进程等。
这是Ceph集群中存储实际用户数据的惟一组件,通常,一个OSD守护进程绑定到集群中的一个物理磁盘。因此,通常来说,Ceph集群中物理磁盘的总数与在每个物理磁盘上存储用户数据的OSD守护进程的总数相同。
- PG
ceph中引入了PG(placement group)的概念,PG是一个虚拟的概念而已,并不对应什么实体。ceph先将object映射成PG,然后从PG映射成OSD。
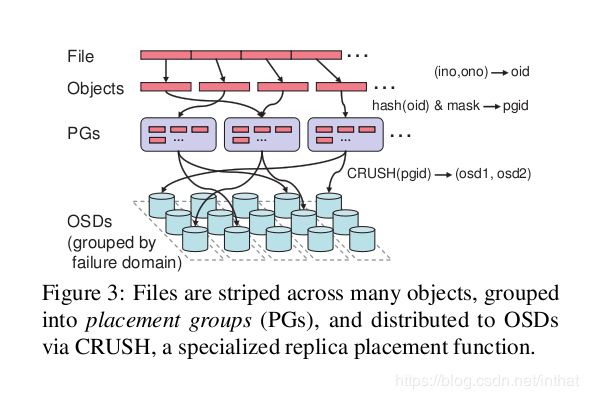
Pool、PG和OSD的关系:
一个Pool里有很多PG;
一个PG里包含一堆对象,一个对象只能属于一个PG;
PG有主从之分,一个PG分布在不同的OSD上(针对三副本类型);
-
Monitor监控
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。负责监控整个Ceph集群运行的Map视图(如OSD Map、Monitor Map、PG Map和CRUSH Map),维护集群的健康状态,维护展示集群状态的各种图表,管理集群客户端认证与授权; -
MDS
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。负责保存文件系统的元数据,管理目录结构。对象存储和块设备存储不需要元数据服务; 如果不使用CephFS可以不安装。 -
Mgr
ceph 官方开发了 ceph-mgr,主要目标实现 ceph 集群的管理,为外界提供统一的入口。例如cephmetrics、zabbix、calamari、prometheus。
Ceph manager守护进程(Ceph -mgr)是在Kraken版本中引入的,它与monitor守护进程一起运行,为外部监视和管理系统提供额外的监视和接口。
-
RGW
RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。 -
CephFS
eph文件系统提供了一个符合posix标准的文件系统,它使用Ceph存储集群在文件系统上存储用户数据。与RBD和RGW一样,CephFS服务也作为librados的本机接口实现。
六、Ceph三种存储类型
1. 块存储(RBD)
-
优点:
- 通过Raid与LVM等手段,对数据提供了保护;
- 多块廉价的硬盘组合起来,提高容量;
- 多块磁盘组合出来的逻辑盘,提升读写效率;
-
缺点:
- 采用SAN架构组网时,光纤交换机,造价成本高;
- 主机之间无法共享数据;
-
使用场景
- docker容器、虚拟机磁盘存储分配;
- 日志存储;
- 文件存储;
典型设备:磁盘阵列,硬盘。主要是将裸磁盘空间映射给主机使用的。
总结: 一个Linux内核级的块设备,允许用户像任何其他Linux块设备一样访问Ceph。
2. 文件存储(CephFS)
-
优点:
- 造价低,随便一台机器就可以了;
- 方便文件共享;
-
缺点:
- 读写速率低;
- 传输速率慢;
-
使用场景
- 日志存储;
- FTP、NFS;
- 其它有目录结构的文件存储
典型设备:FTP、NFS服务器。为了克服块存储文件无法共享的问题,所以有了文件存储。在服务器上架设FTP与NFS服务,就是文件存储。
总结: 这是一个POSIX兼容的文件系统,可以在任何Linux发行版上运行,操作系统可直接访问Ceph存储。
3. 对象存储(Object)(适合更新变动较少的数据)
-
优点:
- 具备块存储的读写高速;
- 具备文件存储的共享等特性;
-
使用场景
- 图片存储;
- 视频存储;
典型设备:内置大容量硬盘的分布式服务器(swift, s3)。多台服务器内置大容量硬盘,安装上对象存储管理软件,对外提供读写访问功能。
七、Ceph和Swift、HDFS对比
ceph这款云存储技术怎么样?和swift、hdfs相比如何
参考URL:https://www.zhihu.com/question/21718731
Swift还是Ceph?哪个对象存储更好呢?
参考URL: http://www.dostor.com/p/48838.html
Ceph与Swift
Ceph用C++编写而Swift用Python编写,性能上应当是Ceph占优。但是与Ceph不同,Swift专注于对象存储,作为OpenStack组件之一经过大量生产实践的验证,与OpenStack结合很好,目前不少人使用Ceph为OpenStack提供块存储,但仍旧使用Swift提供对象存储。数据一致性决定了两者对应两类应用场景。Ceph是始终跨集群强一致性,Swift数据是最终一致的,同步一致数据需要时间。
总结:因为Ceph可以提供多种方式来访问对象存储,所以比Swift更有可用性,扩展性更好。数据一致性决定了两者对应两类应用场景。
Ceph与HDFS
Ceph对比HDFS优势在于易扩展,无单点。HDFS是专门为Hadoop这样的云计算而生,在离线批量处理大数据上有先天的优势,而Ceph是一个通用的实时存储系统。虽然Hadoop可以利用Ceph作为存储后端,但执行计算任务上性能还是略逊于HDFS。
八、体系结构
官网参考: http://docs.ceph.org.cn/architecture/
Ceph 存储集群包含两种类型的守护进程:
Ceph 监视器
Ceph OSD 守护进程
Ceph OSD 守护进程检查自身状态、以及其它 OSD 的状态,并报告给监视器们。
存储集群的客户端和各个 Ceph OSD 守护进程使用 CRUSH 算法高效地计算数据位置,而不是依赖于一个中心化的查询表。
- 数据的存储
Ceph 存储集群从 Ceph 客户端接收数据——不管是来自 Ceph 块设备、 Ceph 对象存储、 Ceph 文件系统、还是基于 librados 的自定义实现——并存储为对象。每个对象是文件系统中的一个文件,它们存储在对象存储设备上。由 Ceph OSD 守护进程处理存储设备上的读/写操作。
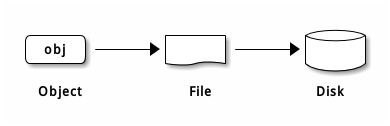
Ceph OSD 在扁平的命名空间内把所有数据存储为对象(也就是没有目录层次)。对象包含一个标识符、二进制数据、和由名字/值对组成的元数据,元数据语义完全取决于 Ceph 客户端。例如, CephFS 用元数据存储文件属性,如文件所有者、创建日期、最后修改日期等等。

Note:一个对象 ID 不止在本地唯一 ,它在整个集群内都是唯一的。
- 伸缩性和高可用性
在传统架构里,客户端与一个中心化的组件通信(如网关、中间件、 API 、前端等等),它作为一个复杂子系统的唯一入口,它引入单故障点的同时,也限制了性能和伸缩性(就是说如果中心化组件挂了,整个系统就挂了)。
Ceph 消除了集中网关,允许客户端直接和 Ceph OSD 守护进程通讯。 Ceph OSD 守护进程自动在其它 Ceph 节点上创建对象副本来确保数据安全和高可用性;为保证高可用性,监视器也实现了集群化。为消除中心节点, Ceph 使用了 CRUSH 算法。
Ceph 用CRUSH 算法 、集群感知性和智能 OSD 守护进程来扩展和维护高可靠性。 Ceph 的关键设计是自治,自修复、智能的 OSD 守护进程。